一种基于MPI并行化的参考点k近邻分类方法与流程
本发明属于数据分类领域,涉及一种基于MPI并行化的参考点k近邻分类方法。
背景技术:
分类是数据挖掘领域的一项重要技术,其目的是根据数据集的特点构造一个分类模型(亦称作分类函数、分类器),该模型能把未知类别的样本映射到给定类别中的某一个或若干个。k近邻算法最初由Cover和Hart于1968年提出,是一种非参数的分类技术,具有鲁棒性、概念清晰、易于实现等优点,并对未知和非正态分布可取得较高的分类准确率。
传统的k近邻算法时间复杂度较高,目前很多学者进行研究后提出了许多的改进算法,这些算法可概括为两大类:
一类是基于树型结构存储与计算的算法,主要包括基于ball树、kd树、PAT、LB树等k近邻算法。这类算法存在的缺点是:随着数据集维度的增加,这些树结构的算法的性能逐渐变差,理由是高维度的数据集会增加树结构的复杂性,从而导致建立树结构、搜索近邻结点和计算距离所耗费的时间增加。另外,由于不同数据集对应的树结构复杂性有所不同,所以这些树结构算法的性能是不稳定的,即在不同数据集之间所表现出来的性能有时会差异较大。
另一类是加速K近邻搜索的算法。主要是从以下几方面改进:(1)减少训练集和优化搜索K近邻;(2)改进相似度度量;(3)优化判决策略。目前存在的不足是计算复杂度较高或者分类精度不高。
随着大数据时代到来,科学研究与各行各业积累了海量的数据资源,为了分析与利用这些数据资源,必须采用有效的数据挖掘技术。kNN算法是一种常用的数据挖掘算法,但其时间复杂度较高、分类速度慢。消息传递接口(Message Passing Interface,MPI)是一种高性能、并行编程工具,同兼顾高性能、可移植性等特点,已经成为消息传递并行编程模式的工业标准,可使用集群或超级计算机并借助MPI编程来解决大规模、高维度数据的k近邻分类问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于MPI并行化的参考点k近邻分类方法,借助参考点来加速k近邻的查找并将使用MPI技术实现并行化,从而加快大规模、高维度数据的分类速度。
为达到上述目的,本发明提供如下技术方案:
一种基于MPI并行化的参考点k近邻分类方法,包括以下步骤:
S1:基于参考点的k近邻算法利用样本点到若干参考点的距离来度量彼此间的位置差异,定义位置差异因子(Location Difference based Factor,LDBF),设样本点X属于n维空间Rn,设第i个样本则两个样本xi和yi之间的LDBF定义为:
计算训练样本到参考点的相似度,并产生有序的相似度序列;
S2:根据测试样本与参考点的相似度从有序序列中搜索训练集中近似近邻样本;
S3:从搜索到的近似近邻样本中计算与测试样本的确切相似度,从而找到k个近邻样本并判断类别。
进一步,所述基于参考点的k近邻算法具体为:
S101:给定数据集D属于d维空间Rd,任取一样本点A∈D,k是要查找的近邻数,参考点Oi的第i个维度的值为1,其他维度的值为0;参考点数N=logd,ε=logn,其中d为训练集的维度,n为训练集的容量;
S102:对数据集合归一化并计算所有样本点相对于第i个参考点的LDBFi,其中1≦i≦N;
S103:根据LDBFi对所有样本点进行排序;
S104:第i个有序序列产生一个以A为中心的子序列,子序列的长度为2k*ε;N个子序列构成一个大的子序列,长度为N*2*k*ε;
S105:在大的子序列中计算所有点到A点的欧式距离,k个最小欧式距离所对应的样本点即是A的k近邻样本;
S106:A的预测标签即为k近邻中出现最多的标签;
S107:若所有样本点的近邻都被查找到,则终止算法;否则更新样本点,并转到步骤S106。
进一步,所述步骤S2-S3具体为:首先将训练数据集均匀分配到每个处理器,即每个进程拥有的训练集Ti约为原始的1/p,并将待分类样本ci逐个传递给各个进程,同时进程根据本地训练集对传给它的样本搜索本地k近邻Ni,并将Ni和前一个进程传给它的k近邻N′i+1综合比较,从而获得近似k近邻N′i,并传递给下一个进程;最后一个进程p-1将前一个进程传给它的k近邻与计算获得的本地k近邻进行比较和选择,最终获得准确k近邻并进行分类。
本发明的有益效果在于:
(1)解决了大量数据和高维数据分类速度慢的问题;
(2)利用分布式集群或超算平台解决了大量训练数据集与待分类数据集的存储问题;
(3)获得了较高的分类精度。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为流水线模型;
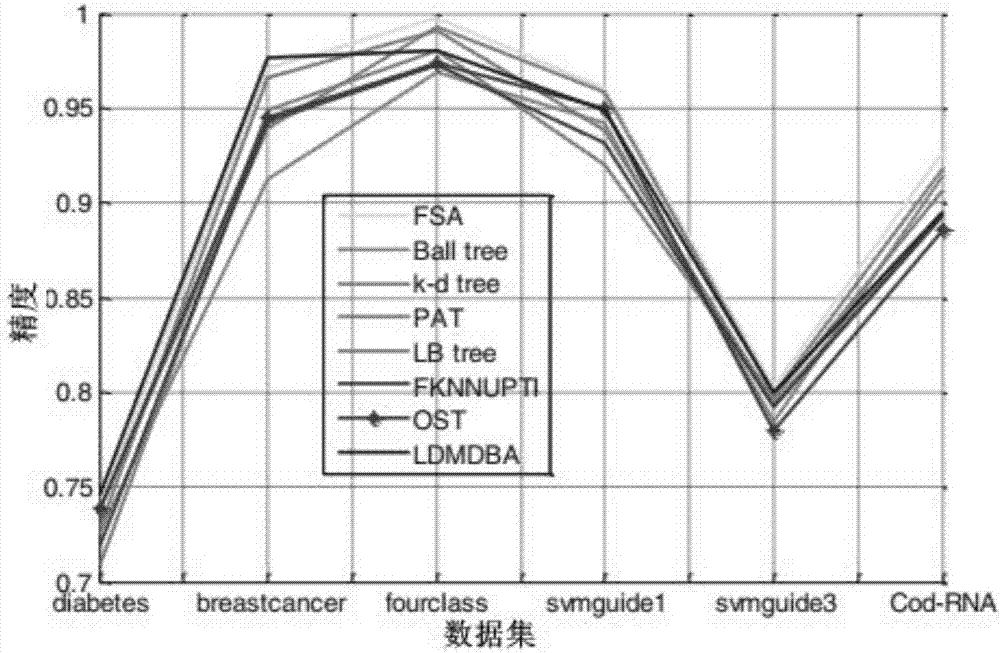
图2为基于参考点k近邻算法(LDMDBA)与现有k近邻算法的精度对比;
图3为基于参考点k近邻算法(LDMDBA)与现有k近邻算法的时间对比;
图4为基于MPI并行化的参考点k近邻方法(LDMDBA并行)与现有k近邻算法并行化(FSA并行)的时间对比;
图5为基于MPI并行化的参考点k近邻方法(LDMDBA并行)与现有k近邻算法并行化(FSA并行)的加速比对比。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
基于参考点的k近邻算法利用样本点到若干参考点的距离来度量彼此间的位置差异,其思想是设置若干参考点,计算训练样本到参考点的相似度并产生有序的相似度序列,再根据测试样本与参考点的相似度从有序序列中搜索训练集中近似近邻样本,并从这些近似近邻样本中计算与测试样本的确切相似度,从而找到k个近邻样本并判断类别。其核心策略是借助参考点以大幅度降低搜索训练集样本的范围。
定义位置差异因子(Location Difference based Factor,LDBF)。假设样本点X属于n维空间Rn,设第i个样本则两个样本xi和yi之间的LDBF定义为:
基于参考点的k近邻算法步骤描述如下:
S101:给定数据集D属于d维空间Rd,任取一样本点A∈D,k是要查找的近邻数,参考点Oi的第i个维度的值为1,其他维度的值为0;参考点数N=logd,ε=logn,其中d为训练集的维度,n为训练集的容量;
S102:对数据集合归一化并计算所有样本点相对于第i个参考点的LDBFi,其中1≦i≦N;
S103:根据LDBFi对所有样本点进行排序;
S104:第i个有序序列产生一个以A为中心的子序列,子序列的长度为2k*ε;N个子序列构成一个大的子序列,长度为N*2*k*ε;
S105:在大的子序列中计算所有点到A点的欧式距离,k个最小欧式距离所对应的样本点即是A的k近邻样本;
S106:A的预测标签即为k近邻中出现最多的标签;
S107:若所有样本点的近邻都被查找到,则终止算法;否则更新样本点,并转到步骤S106。
基于MPI并行化的参考点k近邻分类方法采用流水线模型,如图1所示,首先将训练数据集均匀分配到每个处理器,即每个进程拥有的训练集Ti约为原始的1/p,并将待分类样本ci逐个传递给各个进程,同时进程根据本地训练集对传给它的样本搜索本地k近邻Ni,并将Ni和前一个进程传给它的k近邻N′i+1综合比较,从而获得近似k近邻N′i,并将之传递给下一个进程。最后一个进程p-1将前一个进程传给它的k近邻与计算获得的本地k近邻进行比较和选择,最终获得准确k近邻并进行分类。
算法的伪代码:
1.均衡划分训练集给各个进程;
2.WhileTrue:
If进程0:
(1)读取待分类数据,并发送给进程1;
(2)利用本地训练集查找k近邻;
(3)发送k近邻给进程1
Else:
(1)接收前一个进程发来的待分类数据
(2)利用前一个进程发来的近邻并结合本地训练集查找的k近邻,获得本地k近邻;
(3)If最后一个进程:
根据本地k近邻对待分类数据进行分类;
Else:
发送该待分类数据与k近邻给下一个进程
图2为基于参考点k近邻算法(LDMDBA)与现有k近邻算法的精度对比;x轴为6个数据集,y轴为相应分类精度;图3为基于参考点k近邻算法(LDMDBA)与现有k近邻算法的时间对比;x轴为k近邻的值,y轴为相应分类时间(单位:毫秒);图4为基于MPI并行化的参考点k近邻方法(LDMDBA并行)与现有k近邻算法并行化(FSA并行)的时间对比;x轴为核心数,y轴为相应分类时间(单位:秒);图5为基于MPI并行化的参考点k近邻方法(LDMDBA并行)与现有k近邻算法并行化(FSA并行)的加速比对比;x轴为核心数,y轴为相应的加速比。
1)负载均衡
将训练集均匀分配到处理上可以平衡各处理器的计算负载。可以对训练集进行按块数据分解,即将训练集数组中的连续行组成块进行划分。假设n为训练集数组的行数,p为进程序号,则进程i控制的第一个元素是:故划分给每个进程的训练集数组的行数为:
2)利用虚拟进程拓扑构造流水线型
MPI系统在启动时会自动创建线性排列的进程,但是有时不能充分地反映进程间在逻辑上的通信模型。本发明采用笛卡尔拓扑创建流水线型的逻辑进程排列,可使程序设计简化和容易理解,同时这样的逻辑拓扑还可以辅助运行时系统,将进程映射到实际的硬件结构上,为在相近的物理拓扑上的高效实现提供支持。
通过MPI_Cart_create调用,创建非周期性的一维网格通信域,获得的拓扑坐标相邻关系为:MPI_PROC_NULL,0,1,...,p-1,MPI_PROC_NULL。然后调用MPI_Cart_shift在定义的一维网格上平移而获得前后相邻进程的标识,从而使前后进程间数据传递得到简化。
3)利用非阻塞通信提高效率
通常阻塞式发送与接收操作可能会限制并行程序的性能,由于通信往往耗费较高的时间成本,在阻塞通信未结束时处理机的等待会浪费计算资源,这可通过使计算与通信重叠来解决。非阻塞通信主要用于计算和通信重叠,因此在通信过程中发送和接收操作可交给特定通信硬件完成,同时处理机可进行计算操作,从而提高整个程序的执行效率。
前一个进程可通过非阻塞标准发送MPI_Isend给后一个进程发送数据,从而使通信操作与利用本地训练集查找k近邻的计算操作相重叠。同理利用MPI_Irecv可使得接收操作与计算操作重叠。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!