改进信息熵的制造过程多元质量诊断分类器的制作方法
本发明涉及机械产品加工制造过程质量诊断技术领域,具体涉及一种改进信息熵的制造过程多元质量诊断分类器。
背景技术:
现代制造过程是多变量高度相关的,对这类生产过程的过程监控称为多元质量控制(mqc)或者多元统计过程控制(mspc)。寻找失控原因的过程被称为mspc诊断或异常识别。主要有两类方法:一是统计分解技术;二是基于机器学习的技术。主流分解技术包括了主成分分析(pca),特征空间比较法,mty方法、步降方法、多向核主成分分析方法。然而,这些方法通常都包含了复杂统计过程,不利于应用。随着计算机技术的发展,机器学习成为这一领域的研究热点。人工神经网络(ann)和决策树(dt)算法已经被应用于mspc领域。由于产品质量在现代工业中的重要地位,统计过程控制(spc)在机械、纺织、电子产品、汽车灯离散制造业中取得了很大成功,并逐渐向造纸、炼油、化工、食品等间歇工业和连续制造业渗透。在实际的制造过程中,被加工零部件或产品往往具有多个质量特性,且这些质量特性之间存在一定的相关性,如何确定该过程的过程能力指数以及对过程质量进行诊断,是迫切需要解决的问题,该问题的研究不仅对多元制造过程能力分析研究具有重要的意义,而且对多元制造过程的质量进行监控和诊断均具有一定的理论意义和实用价值。基于上述需求,本发明提供了改进信息熵的制造过程多元质量诊断分类器。
技术实现要素:
针对多元控制图在多元过程监控和异常诊断中的不足,本发明提供了一种改进信息熵的制造过程多元质量诊断分类器。
为了解决上述问题,本发明是通过以下技术方案实现的:
步骤1:收集制造过程中质量特性的原始数据,并对该数据进行必要的整理、简化及计算。
步骤2:对关键工序的多元质量特性进行过程分析;
步骤3:把观测到的数据记录到己经画好控制限的控制图上,根据判稳规则判断过程是否出现异常现象;
步骤4:根据识别结果,改进信息熵方法查找出过程异常源所在;
步骤5:相关人员针对质量问题提出并实施改善的措施,解决过程异常情况;
步骤6:在改善实施后,维续使用控制图对过程质量进行验证确认,观测是否仍有异常,若有则返问至(3),若无则继续利用控制图对制造过程进行监控。
本发明有益效果是:
1、过程能力系数条件更严谨,判定状态更加准确。
2、算法复杂度低,处理的时间短,得到了较好的结果准确度。
3、为后续制造过程诊断技术奠定了较好的基础。
4、考虑了质量间的多元特性,算法适应性更强,更符合实际的应用。
5、参数因子处理的更加规范合理,得到的值更符合经验判定的结果。
6、考虑了误判因子、又结合主成分分析方法,结果准确度得到的进一步提升。
7、数据处理更完善,减低了误判的概率。
8、解决了数据的偏置、单位不统一的问题。
9,比支持向量机方法查出异常源的准确度更高,处理速度也比支持向量机更快。
附图说明
图1决策树的多元过程监控模型示意图
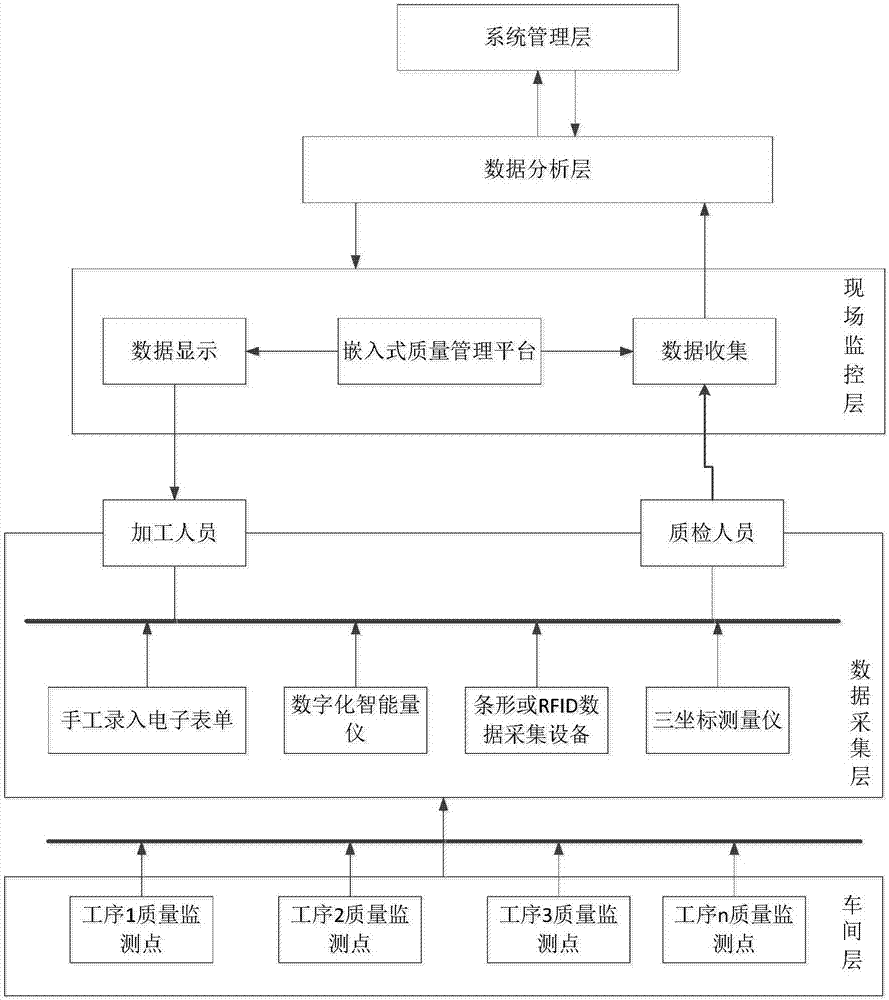
图2本发明车间数据采集方案图
图3二维过程修正的规格区域与实际分布区域示例图
具体实施方式
为了解决多元控制图在多元过程监控和异常诊断中的不足,结合图1-图3对本发明进行了详细说明,其具体实施步骤如下:
步骤1:收集制造过程中质量特性的原始数据,并对该数据进行必要的整理、简化及计算,其具体计算过程如下:
在生产过程中,当工序不存在系统性误差时,产品的质量特性值x符合正态分布;由于多元质量特性值得单位不统一,数值大小差距也较大,需对数据做进一步处理;
生产过程正常运行收集的数据矩阵为xn×m,n为样本的个数,m为样本质量属性个数。
上式xn×i为第n个样本第i种质量属性值,μi为第i种质量属性均值,σi第i种质量属性标准差。
对预处理后的数据x′n×i,进行比重计算如下:
假设m维正态分布nm(μ,∑),即xm~nm(μ,∑),其中μ为总体均值向量,∑为协方差矩阵,由于∑m×m为对称矩阵,因此存在对称矩阵p,使得
其中λ1,λ2,…,λm为协方差矩阵的特征值,其满足(λ1,λ2,…,λm)>0,即m维多元质量的权重分配可以表示为下式:
取前k个主元的累计贡献率达到80%以上,即贡献率为w:
则主元模型为
步骤2:对关键工序的多元质量特性进行过程分析,其具体计算过程如下:
这里主要对步骤1中e的计算和估计;
x∈n(μ,σ2),其中x是质量特性值,μ是总体均值,σ2是总体方差。当质量特性值服从正态分布时,其均值
p(μ-3σ<x<μ+3σ)=99.73%
即,无论μ和σ取何值,x落在之间的概率是99.73%,也就是说,落在这个分布范围之外的概率只有0.27%。
对于过程修正的规格区域是一个椭球体,其体积计算公式为:
ui、li分别为控制图上第i元质量因子的上下限。
多元过程在(1-α)置信度下实际分布区域的椭球体为:
|∑|为多元质量因子的协方差行列式。
设其修正系数为k;
ε=[(m1-μ1)2+(m2-μ2)2+…+(mt-μt)2]1/2
mi、μi分别为规格图、和实际过程的均值位置,ε为t维均值差值。
另一影响因子为
即
综上所述,表征过程能力函数如下:
为了完善上式的结果,这里整合下面的方法,具体过程如下:
错判误差的概率分为两类,一是受控状态判为失控状态,概率即为p1,二是失控状态判为受控状态,概率即为p2。
样本x,当处于受控状态时。设其分布为正态分布x∈n(μ,σ2);过程处于失控状态时,其分布发生了变化,变化后的分布函数为f(x)。
记控制图的上、下控制限分别为u、l;
p1=2(1-φ(λ))
p2=f(u)-f(l)
总误差概率为p1+p2
上式φ(λ)为标准正态分布的分布函数在点λ处的值,λ为控制图中实际参数,这个具体情况可以具体确定。
一元修正系数k′:
β1、β2分别为中心距离差值|λ-μ|、误判概率的权重分配值,这里β1+β2=1,(β1,β2)>0。
表征过程能力函数cp:
cp=min(cpu,cpl)
多元表征过程能力函数mc′p:
表征e
e=|mcp-mc′p|
根据x′主模型即可提取制造过程质量异常的主特征。
步骤3:把观测到的数据记录到己经画好控制限的控制图上,根据判稳规则判断过程是否出现异常现象,其具体描述如下:
如果过程处于非统计过程受控状态时用样本点建立的控制图控制后续的生产过程,不仅起不到良好的控制效果,反而会给企业带来错误的预报,给企业造成损失。
步骤4:根据识别结果,改进信息熵方法查找出过程异常源所在,其具体计算过程如下:
根据训练数据集确定属性的信息熵,每个质量属性都对应若干个分量;
这里质量属性的确定见下式:
s1到sm分别表示属性s分裂所形成的c个不同的样本属性值。λ为调节因子,a,b为属性信息的权重值,μl为类l均值,sil为类l对应的属性值。
再根据欧式距离确定异常源,具体如下:
d2(lsplit(s),cpe)=(lsplit(s)-cpe)2
d2(lsplit(s),cpe)≥min[(|cpu|-|cpe|),(|cpl|-|cpe|)]
上式d2(lsplit(s),cpe)为属性s与控制图理想控制线的欧式距离,cpe为控制图理想控制线。
d2(lsplit(s),cpe)越大,对应的质量属性越不稳定,超过阈值min,即引发警报,再通过上式确定异常分量,即异常源。
步骤5:相关人员针对质量问题提出并实施改善的措施,解决过程异常情况;
步骤6:在改善实施后,维续使用控制图对过程质量进行验证确认,观测是否仍有异常,若有则返问至(3),若无则继续利用控制图对制造过程进行监控。
- 还没有人留言评论。精彩留言会获得点赞!