基于多模态交互的虚拟偶像演绎数据处理方法及系统与流程
本申请涉及人工智能技术领域,特别涉及基于多模态交互的虚拟偶像演绎数据处理方法及系统、虚拟偶像、成像设备及计算机可读存储介质。
背景技术:
随着科学技术的不断发展,机器人的发展也由工业领域,逐渐扩展到了医疗、保健、家庭、娱乐以及服务行业等领域。人们对机器人的智能要求不断的提高以便其更好地为人类服务。
机器人包括具备实体的实体机器人和搭载在硬件设备上的虚拟机器人。现有技术中的虚拟机器人只能通过对其编程,完成部分预设动作,智能程度较低。
当前,虚拟机器人的多模态交互及技能输出不具备实时性,以及演绎数据与技能内容不具备对应性,并且虚拟机器人也无法实现逼真、流畅、拟人的效果,人机交互效果差。
技术实现要素:
有鉴于此,本申请提供基于多模态交互的虚拟偶像演绎数据处理方法及系统、虚拟偶像、成像设备及计算机可读存储介质,以解决现有技术中存在的技术缺陷。
本申请实施例公开了一种基于多模态交互的虚拟偶像演绎数据处理方法,所述虚拟偶像在移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,所述方法包括:
判断当前虚拟偶像是否处于技能输出状态;
若是,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像展示。
可选地,所述多模态输出数据中的演绎数据由所述虚拟偶像展示包括:
基于所述多模态输出数据,所述虚拟偶像输出肢体动作、与情感信息匹配的口型和/或面部表情。
可选地,所述方法还包括:
所述移动设备根据当前所述多模态输出数据,控制所述成像设备输出所述虚拟偶像演绎及配合所述虚拟偶像演绎的组件功能开启信号。
可选地,所述方法还包括:
获取当前虚拟偶像的情感数据,当所述虚拟偶像处于技能输出状态时,匹配所述情感数据输出多模态输出数据。
可选地,当所述演绎数据为舞蹈数据时,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据的步骤包括:
实时获取舞蹈配乐;
提取所述舞蹈配乐的声学特征;
将所述声学特征输入到预先建立的深度学习模型中,输出与所述声学特征匹配的舞蹈动作。
可选地,所述深度学习模型通过如下步骤进行构建:
采集带有声乐特征的舞蹈以及舞蹈配乐;
将所述带有声乐特征的舞蹈的动作与所述舞蹈配乐的声学特征进行匹配,生成训练数据样本;
根据所述训练数据样本训练所述深度学习模型得到最终的深度学习模型。
另一方面,本申请还提供了一种基于多模态交互的虚拟偶像演绎数据处理系统,包括移动设备、成像设备和云端服务器,所述虚拟偶像在所述移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,其中:
所述云端服务器判断当前虚拟偶像是否处于技能输出状态;
若是,根据所述移动设备获取的当前技能数据以及所述技能对应的内容参数,由所述云端服务器决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像通过所述成像设备展示。
另一方面,本申请还提供了一种虚拟偶像,所述虚拟偶像在移动设备运行,所述虚拟偶像执行如上所述基于多模态交互的虚拟偶像演绎数据处理方法的步骤。
另一方面,本申请还提供了一种成像设备,所述虚拟偶像在移动设备运行并由所述成像设备投影呈现。
另一方面,本申请还提供了一种计算机可读存储介质,其存储有计算机程序,该程序被处理器执行时实现如上所述基于多模态交互的虚拟偶像演绎数据处理方法的步骤。
本申请提供的基于多模态交互的虚拟偶像演绎数据处理方法及系统、虚拟偶像、成像设备及计算机可读存储介质,其中,所述方法包括获取多模态输入数据,将所述多模态输入数据输入预先建立的深度学习模型中进行匹配,得到多模态输出数据,输出所述多模态输出数据,并由所述虚拟偶像演绎;从而实现在当前虚拟偶像演绎技能开启的情况下,通过云端服务器解析技能数据,并决策多模态输出数据。所述多模态输出数据由所述虚拟偶像通过成像设备进行展示,使得所述虚拟偶像的演绎具备实时性,以及演绎数据与技能内容具备对应性,用户也可以享受个性化流畅体验,人机交互效果好。
附图说明
图1为本申请一实施例提供的一种计算设备的结构框图;
图2为本申请一实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法的流程图;
图3为本申请一实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法的流程图;
图4为本申请一实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法的流程图;
图5为本申请一实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法的流程图;
图6为本申请一实施例提供的构建深度学习模型的流程图;
图7为本申请一实施例提供的成像设备结构示意图。
具体实施方式
在下面的描述中阐述了很多具体细节以便于充分理解本申请。但是本申请能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本申请内涵的情况下做类似推广,因此本申请不受下面公开的具体实施的限制。
本申请提供了基于多模态交互的虚拟偶像演绎数据处理方法及系统、虚拟偶像、成像设备及计算机可读存储介质,在下面的实施例中逐一进行详细说明。
参见图1,本申请一实施例提供的基于多模态交互的虚拟偶像演绎数据处理系统结构示意图,实现在当前虚拟偶像演绎技能开启的情况下,决策所述多模态输出数据并由所述虚拟偶像通过成像设备进行展示,通过所述云端服务器进行解析技能数据,并决策多模态输出数据,使得所述虚拟偶像的演绎具备实时性,以及演绎数据与技能内容具备对应性,用户也可以享受个性化流畅体验,人机交互效果好。
作为示例地,基于多模态交互的虚拟偶像演绎数据处理系统包括移动设备101、成像设备102和云端服务器106。所述移动设备101与所述成像设备102物理位置参照对齐,以及实现所述移动设备101与所述成像设备102的信号互联。
所述移动设备101可以将运行在自身的虚拟偶像投射在所述成像设备102上进行显示,所述成像设备102可以为全息投影设备,并且所述移动设备101可以与所述云端服务器106连接,使得运行在所述移动设备101上的虚拟偶像在所述成像设备102上呈现多模态人机交互的效果。
所述移动设备101可以包括:通信模块103、中央处理单元104和人机交互输入输出模块105;
其中,所述人机交互输入输出模块105,其用于获取多模态数据以及输出虚拟偶像执行参数,多模态数据包括来自周围环境的数据及与用户进行交互的多模态输入数据;
所述通信模块103,其用于调用所述云端服务器106的能力接口并接收通过所述云端服务器106的能力接口解析所述多模态输入数据以决策出多模态输出数据;
所述中央处理单元104,用于利用所述多模态输出数据计算与所述多模态输出数据相对应的应答数据。
所述云端服务器106具备多模态数据解析模块,用于对所述移动设备101发送的多模态数据进行解析,并决策多模态输出数据。
所述成像设备102,其用于在预设显示区域内显示具有特定形象的虚拟偶像。
如图1所示,多模态数据解析过程中各个能力接口分别调用对应的逻辑处理。以下为各个接口的说明:
语义理解接口107,其接收从所述通信模块103转发的特定语音指令,对其进行语音识别以及基于大量语料的自然语言处理。
视觉识别接口108,可以针对人体、人脸、场景依据计算机视觉算法、深度学习算法等进行视频内容检测、识别、跟踪等。即根据预定的算法对图像进行识别,给出定量的检测结果。具备图像预处理功能、特征提取功能、决策功能和应用功能;
其中,所述图像预处理功能可以是对获取的视觉采集数据进行基本处理,包括颜色空间转换、边缘提取、图像变换和图像阈值化;所述特征提取功能可以提取出图像中目标的肤色、颜色、纹理、运动和坐标等特征信息;所述应用功能实现人脸检测、人物肢体识别、运动检测等功能。
情感计算接口110,其接收从所述通信模块103转发的多模态数据,利用情感计算逻辑(可以是情感识别技术)来计算用户当前的情感状态。情感识别技术是情感计算的一个重要组成部分,情感识别研究的内容包括面部表情、语音、行为、文本和生理信号识别等方面,通过以上内容可以判断用户的情感状态。情感识别技术可以仅通过视觉情感识别技术来监控用户的情感状态,也可以采用视觉情感识别技术和声音情感识别技术结合的方式来监控用户的情感状态,且并不局限于此。在本实施例中,优选采用二者结合的方式来监控情感。
情感计算接口110是在进行视觉情感识别时,通过使用图像采集设备收集人类面部表情图像,而后转换成可分析数据,再利用图像处理等技术进行表情情感分析。理解面部表情,通常需要对表情的微妙变化进行检测,比如脸颊肌肉、嘴部的变化以及挑眉等。
认知计算接口109,其接收从所述通信模块103转发的多模态数据,所述认知计算接口109用以处理多模态数据进行数据采集、识别和学习,以获取用户画像、知识图谱等,以对多模态输出数据进行合理决策。
上述为本申请实施例的基于多模态交互的虚拟偶像演绎数据处理系统的一种示意性的技术方案。为了便于本领域技术人员理解本申请的技术方案,下述通过多个实施例对本申请提供的基于多模态交互的虚拟偶像演绎数据处理方法及系统、虚拟偶像、成像设备及计算机可读存储介质,进行进一步的说明。
本申请中,移动设备与成像设备物理位置参照对齐,以实现所述移动设备与所述成像设备的信号互联。
所述移动设备可以将运行在自身的虚拟偶像投射在所述成像设备上进行显示,所述成像设备可以为全息投影设备,并且所述移动设备可以与云端服务器连接而使得所述虚拟偶像具备多模态人机交互,具备自然语言理解、视觉感知、触摸感知、语言语音输出、情感表情动作输出等artificialintelligence(ai)的能力。
所述虚拟偶像可以以3d虚拟形象通过所述成像设备进行显示,具备特定形象特征,并且可以为所述虚拟偶像配置社会属性、人格属性和人物技能等。
具体来说,所述社会属性可以包括:外貌、姓名、服饰、装饰、性别、籍贯、年龄、家庭关系、职业、职位、宗教信仰、感情状态、学历等属性;所述人格属性可以包括:性格、气质等属性;所述人物技能可以包括:唱歌、跳舞、讲故事、培训等专业技能,并且人物技能展示不限于肢体、表情、头部和/或嘴部的技能展示。
在本申请中,虚拟偶像的社会属性、人格属性和人物技能等可以使得多模态交互的解析技能数据,并决策多模态输出数据,所述多模态输出数据更倾向或更为适合该虚拟偶像。
同时所述虚拟偶像还可以配合移动设备投射到成像设备上,并根据所述成像设备展示的场景进行演绎,例如唱歌、跳舞等。
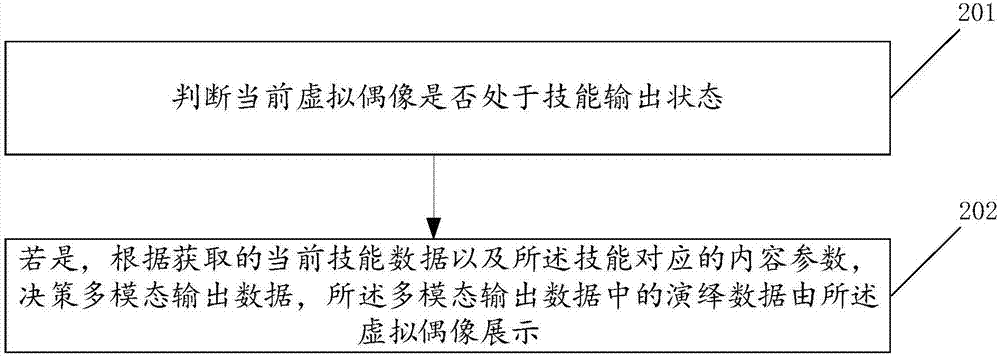
参见图2,本申请一实施例提供了一种基于多模态交互的虚拟偶像演绎数据处理方法,所述虚拟偶像在移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,所述方法包括步骤201至步骤202。
步骤201:判断当前虚拟偶像是否处于技能输出状态。
本申请实施例中,所述技能可以包括唱歌、跳舞等,所述技能输出状态可以包括正在唱歌、正在跳舞等;并且所述虚拟偶像在移动设备运行并由成像设备投影呈现,可以根据移动设备或成像设备判断当前虚拟偶像的技能输出状态,例如可以判断出当前虚拟偶像正在唱歌或正在跳舞等技能输出状态。
本申请实施例中,所述移动设备可以为智能手机、笔记本电脑、平板电脑、掌上电脑及其他移动终端等计算设备,所述计算设备还可以是移动式或静止式的服务器,所述移动设备是所述虚拟偶像与用户及环境进行交互的主要媒介。
所述成像设备可以为全息投影设备,全息投影设备可以提供基本的投影成像的载体支撑,并可以将所述移动设备屏幕上显示的画面或者文字等内容进行显示,并且所述成像设备也可以采集关于视觉、红外和/或蓝牙等信号,以辅助所述移动设备进行交互。
所述移动设备对所述成像设备的显示功能进行控制,其中包括对场景附属物的显示进行控制,例如控制场景中的花草树木等、对灯光、特效、粒子或射线的显示,其中所述灯光、所述特效、所述粒子和所述射线可以由所述成像设备进行显示。
本申请实施例中,当移动设备或者成像设备的相对位置发生改变时,移动设备可调整运行在其的虚拟偶像的状态,所述状态包括但不限于休息状态、活跃状态、倾听状态等。
其中,所述休息状态:指的是虚拟偶像处于静止状态或无交互状态;所述活跃状态,指的是虚拟偶像处于多模态交互状态,且可进行作品演绎及技能输出;所述倾听状态:指的是虚拟偶像的语音输入接口打开,可接收用户及环境输入的语音信号。
步骤202:若是,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像展示。
本申请实施例中,若当前虚拟偶像处于技能输出状态,可以使用云端服务器获取当前虚拟偶像的技能数据,和所述技能对应的内容参数,决策多模态输出数据。
例如,当前虚拟偶像处于已开启技能输出的状态,利用云端服务器对当前虚拟偶像的技能进行获取,如虚拟偶像的技能为歌伴舞,所对应的内容参数则为:唱歌的歌曲内容,根据获取到的上述信息可以确定多模态输出数据为:歌曲的音乐旋律、歌曲的texttospeech(tts)、歌曲节奏韵律,及与该歌曲匹配的舞蹈。
所述多模态输出数据可以包括演绎数据和语音数据等,本申请主要以演绎数据为例进行说明,例如所述多模态输出数据为:唱歌和跳与该歌曲匹配的舞蹈时,所述演绎数据为:可显示于所述成像设备的多模态输出数据,如舞蹈动作、肢体伴随歌曲节奏韵律的变化、音乐旋律及歌曲tts对应的情感在虚拟偶像面部的情感表现。
本申请实施例中,还可以在云端服务器预先建立深度学习模型,所述深度学习模型可以为循环神经网络(rnn,recurrentneuralnetworks),将获取到的当前技能数据以及所述技能对应的内容参数输入所述深度学习模型中,可以直接得出多模态输出数据,例如获取到的当前技能数据为:跳舞,所述技能对应的内容参数为:孔雀舞的舞蹈动作,将该技能数据和技能对应的内容参数输入所述深度学习模型中,直接得出:跳孔雀舞的下一个舞蹈动作a,然后根据当前得出的“跳孔雀舞的下一个舞蹈动作a”再准确得出与当前动作a对应的“跳孔雀舞的下一个舞蹈动作b”,如此循环,生成孔雀舞的全部舞蹈动作,然后由所述虚拟偶像进行演绎并通过成像设备进行展示。
可选地,获取当前虚拟偶像的情感数据(情感数据的来源包括:用户情感输入、技能内容对应情感数据),当所述虚拟偶像处于技能输出状态时,匹配所述情感数据输出多模态输出数据。
例如,所述当前虚拟偶像的情感数据为高兴,并且所述虚拟偶像处于正在唱歌的技能输出状态时,匹配所述情感数据输出的多模态输出数据可以包括唱歌以及跳与该歌曲相匹配的舞蹈,若所述当前虚拟偶像的情感数据为难过时,当所述虚拟偶像处于正在唱歌的技能输出状态时,匹配所述情感数据输出的多模态输出数据可能仅仅为唱歌。
本申请实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法,可以在当前虚拟偶像演绎技能开启的情况下,通过所述云端服务器进行解析技能数据,并决策多模态输出数据。所述多模态输出数据并由所述虚拟偶像通过成像设备进行展示,使得所述虚拟偶像的演绎具备实时性,以及演绎数据与技能内容具备对应性,用户也可以享受个性化流畅体验,人机交互效果好。
参见图3,本申请一实施例提供了一种基于多模态交互的虚拟偶像演绎数据处理方法,所述虚拟偶像在移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,所述方法包括步骤301至步骤303。
步骤301:判断当前虚拟偶像是否处于技能输出状态。
本申请实施例中,所述技能可以为唱歌,所述技能输出状态可以为正在唱歌。
步骤302:若是,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像展示。
本申请实施例中,可以由云端服务器对技能输出状态进行分析,然后根据分析结果获取的当前技能数据以及所述技能对应的内容参数,例如云端服务器对当前虚拟偶像的技能输出状态进行分析之后确定当前所述虚拟偶像的技能输出状态为:正在唱歌,则根据正在唱歌的技能输出状态获取到所述虚拟偶像当前技能数据为唱歌,以及所述技能对应的内容参数为歌词“梁祝的:彩蝶双双久徘徊”,将该技能数据和所述技能对应的内容参数输入到预先建立的深度学习模型中,得出所述多模态输出数据:唱梁祝这首歌曲和跳与该歌曲匹配的舞蹈,所述多模态输出数据中的演绎数据为:跳与梁祝这首歌曲匹配的舞蹈,然后由所述虚拟偶像演绎该舞蹈并通过成像设备进行展示。
步骤303:基于所述多模态输出数据,所述虚拟偶像输出肢体动作、与情感信息匹配的口型和/或面部表情。
本申请实施例中,当所述虚拟偶像展示所述多模态输出数据中的演绎数据时,还会基于所述多模态输出数据,还会配合输出肢体动作、与情感信息匹配的口型和/或面部表情等。
所述多模态输出数据中的演绎数据为歌伴舞时,所述虚拟偶像的肢体(如双臂、手指、双腿等)会跟着歌曲中音乐的节奏、歌词的内容、歌词剧情的发展起伏变化,做出对应的动作,所述虚拟偶像的口型也会根据歌曲曲调、歌词和该歌曲对应的情感作出对应的变化,并且所述虚拟偶像的五官(如眼睛、眉毛等)以及面部表情(如皮肤褶皱等)也会根据解析的歌曲和舞蹈中的情感数据进行变化。
例如,所述多模态输出数据中的演绎数据为:跳与梁祝这首歌曲匹配的舞蹈时,当所述虚拟偶像跳与梁祝这首歌曲匹配的舞蹈时,则可以通过算法判断梁祝这首歌曲中所包含的情感和状态,经过识别,可以判断出梁祝这首歌曲的情感倾向为负向,情感类别为难过,需要表现的动作类型为:不舍,当云端服务器将理解到的信息发送给移动设备之后,运行在移动设备的虚拟偶像就能知道在跳与梁祝这首歌曲匹配的舞蹈时需要做出不舍的动作,并且口型为半张,眼神为悲伤态。
本申请实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法,使得虚拟偶像在演绎过程中增加肢体动作、与情感信息匹配的口型和/或面部表情等,使得所述虚拟偶像的呈现更加拟人化,并且采用这种多模态交互也更加增多了趣味性。
参见图4,本申请一实施例提供了一种基于多模态交互的虚拟偶像演绎数据处理方法,所述虚拟偶像在移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,所述方法包括步骤401至步骤403。
步骤401:判断当前虚拟偶像是否处于技能输出状态。
所述技能输出状态开启可通过用户的语音输入、视觉手势输入、触摸感知输入或实体按钮输入等开启方式,使得虚拟偶像开启自唱、跳舞、歌伴舞或诗朗诵等技能。
步骤402:若是,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像展示。
本申请实施例中,可以由云端服务器对技能输出状态进行分析,然后根据分析结果获取的当前技能数据以及所述技能对应的内容参数,例如云端服务器对当前虚拟偶像的技能输出状态进行分析之后确定当前所述虚拟偶像的技能输出状态为:正在听音乐,则根据正在听音乐的技能输出状态获取到所述虚拟偶像当前技能数据为听音乐,以及所述技能对应的内容参数为听拉丁舞的配乐,将该技能数据和所述技能对应的内容参数输入到预先建立的深度学习模型中,得出所述多模态输出数据:听拉丁舞的配乐并跳拉丁舞,所述多模态输出数据中的演绎数据为:跳拉丁舞,然后由所述虚拟偶像演绎该舞蹈并通过成像设备进行展示。
步骤403:所述移动设备根据当前所述多模态输出数据,控制所述成像设备输出所述虚拟偶像演绎及配合所述虚拟偶像演绎的组件功能开启信号。
本申请实施例中,当所述虚拟偶像的技能开启时,移动设备可依据当前的场景选择无线网络连接到成像设备,并控制成像设备开启灯光、变化灯光颜色或开启点阵灯光等。
例如,当前所述虚拟偶像正在跳拉丁舞时,移动设备可依据当前的场景选择无线网络连接到成像设备,并控制成像设备开启金色和红色的灯光,变化金红的灯光颜色,开启点阵灯光,配合所述虚拟偶像,呈现的效果更加真实。
本申请实施例提供的基于多模态交互的虚拟偶像演绎数据处理方法,在所述虚拟偶像进行舞蹈演绎的同时可以根据演绎的舞蹈配合自动生成匹配的舞台灯光和舞台效果,给用户呈现更好的视觉体验。
参见图5,当演绎数据为舞蹈数据时,根据获取的当前技能数据以及所述技能对应的内容参数,决策多模态输出数据中的演绎数据的步骤包括:
步骤501:实时获取舞蹈配乐。
本申请实施例中,首先判断当前虚拟偶像是处于技能输出状态,并可以根据该舞蹈配乐确定所述虚拟偶像的技能数据为舞蹈配乐输出,所述技能对应的内容参数为该舞蹈配乐的每一句歌词或每一节曲谱。
步骤502:提取所述舞蹈配乐的声学特征。
本申请实施例中,提取该舞蹈配乐的每一句歌词或每一节曲谱的声学特征,所述声学特征可以是曲调、曲意或节拍等。
步骤503:将所述声学特征输入到预先建立的深度学习模型中,输出与所述声学特征匹配的舞蹈动作。
本申请实施例中,输出与所述声学特征匹配的舞蹈动作即为多模态输出数据中的演绎数据。
本申请实施例中,首先获取前一时刻虚拟偶像的舞蹈动作(如预备动作等),再获取当前所述虚拟偶像的舞蹈配乐,然后提取所述舞蹈配乐的声学特征,根据所述声学特征和前一时刻虚拟偶像的舞蹈动作生成匹配的当前时刻的舞蹈动作,如此循环,生成一系列舞蹈动作,然后由虚拟偶像通过全息投影设备进行演绎。
本申请实施例中,也可以获取前一时刻虚拟偶像的舞蹈动作生成当前时刻的舞蹈动作,如此循环,生成一系列舞蹈动作;若同时获取前一时刻虚拟偶像的舞蹈动作和当前所述虚拟偶像的舞蹈配乐时,所述虚拟偶像会自动选择最为合适的当前舞蹈动作,或者所述虚拟偶像会将根据所述前一时刻虚拟偶像的舞蹈动作生成的当前舞蹈动作和根据舞蹈配乐生成的当前舞蹈动作进行结合,生成新的当前时刻舞蹈动作,所述虚拟偶像可实现自动学习舞蹈动作并且有很好的自创性。
本申请实施例中,所述深度学习模型通过步骤601至步骤603进行构建。
步骤601:采集带有声乐特征的舞蹈以及舞蹈配乐。
本申请实施例中,通过移动设备采集带有声乐特征的舞蹈以及舞蹈配乐。
步骤602:将所述带有声乐特征的舞蹈的动作与所述舞蹈配乐的声学特征进行匹配,生成训练数据样本。
本申请实施例中,将所述带有声乐特征的舞蹈的每一个动作与所述舞蹈配乐的每一个声学特征进行匹配,生成训练样本。
步骤603:根据所述训练数据样本训练所述深度学习模型得到最终的深度学习模型。
本申请实施例提供的一种虚拟形象表现方法,实现所述多模态输入数据可以根据预先训练得到的深度学习模型直接得到所述多模态输出数据,通过所述云端服务器进行解析技能数据,并决策多模态输出数据,使得所述虚拟形象的演绎具备实时性,以及演绎数据与技能内容具备对应性,用户也可以享受个性化流畅体验,人机交互效果好。
本申请一实施例还提供一种基于多模态交互的虚拟偶像演绎数据处理系统,包括移动设备、成像设备和云端服务器,所述虚拟偶像在所述移动设备运行并由成像设备投影呈现,且所述虚拟偶像具备预设形象特征和预设属性,其中:
所述云端服务器判断当前虚拟偶像是否处于技能输出状态;
若是,根据所述移动设备获取的当前技能数据以及所述技能对应的内容参数,由所述云端服务器决策多模态输出数据,所述多模态输出数据中的演绎数据由所述虚拟偶像通过所述成像设备展示。
上述为本实施例的基于多模态交互的虚拟偶像演绎数据处理系统的示意性方案。需要说明的是,该基于多模态交互的虚拟偶像演绎数据处理系统的技术方案与上述的基于多模态交互的虚拟偶像演绎数据处理方法的技术方案属于同一构思,基于多模态交互的虚拟偶像演绎数据处理系统的技术方案未详细描述的细节内容,均可以参见上述基于多模态交互的虚拟偶像演绎数据处理方法的技术方案的描述。
本申请一实施例还提供了一种虚拟偶像,所述虚拟偶像在移动设备运行,所述虚拟偶像执行如上所述基于多模态交互的虚拟偶像演绎数据处理方法的步骤。
参见图7,本申请一实施例还提供了一种成像设备,所述虚拟偶像在移动设备701运行并由所述成像设备702投影呈现。
本申请一实施例还提供一种计算机可读存储介质,其存储有计算机程序,该程序被处理器执行时实现如前所述基于多模态交互的虚拟偶像演绎数据处理方法的步骤。
上述为本实施例的一种计算机可读存储介质的示意性方案。需要说明的是,该存储介质的技术方案与上述的基于多模态交互的虚拟偶像演绎数据处理方法的技术方案属于同一构思,存储介质的技术方案未详细描述的细节内容,均可以参见上述基于多模态交互的虚拟偶像演绎数据处理方法的技术方案的描述。
所述计算机指令包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或系统、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
需要说明的是,对于前述的各方法实施例,为了简便描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本申请并不受所描述的动作顺序的限制,因为依据本申请,某些步骤可以采用其它顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定都是本申请所必须的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
以上公开的本申请优选实施例只是用于帮助阐述本申请。可选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本申请的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本申请。本申请仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!