矢量处理单元的制作方法
本说明书涉及本地化矢量处理单元,其可用于执行与一般能够被称为矢量的二维数据阵列相关联的各种计算。
背景技术:
矢量处理单元能够用于与深度神经网络(“DNN”)层的技术领域例如数值模拟、图形处理、游戏控制台设计、超级计算和机器学习计算相关联的计算。
一般而言,神经网络是机器学习模型,其使用一个或多个模型层来为接收到的输入生成输出,例如分类。具有多个层的神经网络能够用于通过处理经过所述神经网络的每一个层的输入来计算推理。
技术实现要素:
与传统矢量处理单元(VPU)的特征相比,本说明书描述了VPU,其被配置为将计算划分为:a)示例单指令多数据(SIMD)VPU,其具有增加的灵活性、增加的存储器带宽要求和相当低的计算密度;b)矩阵单元(MXU),其具有较低的灵活性、低存储器带宽要求和高计算密度;以及c)低存储器带宽的交叉通道单元(XU),其用于执行某些可能不适合所述SIMD范式、而且也可能不具有MXU计算操作的计算密度的操作。一般而言,至少a)和b)的计算特征之间的反差相对于现行/传统的SIMD处理器提供了增强的SIMD处理器设计架构。在一些实施方式中,所描述的VPU是示例Von-Neumann SIMD VPU。
本实用新型的一个方面涉及一种矢量处理单元,其包含:一个或多个处理器单元,每个处理器单元被配置为执行与多维数据阵列的矢量化计算相关联的算术运算;和与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器,其中所述矢量存储器包括被配置为存储由所述一个或多个处理器单元中的每一个使用以执行所述算术运算的数据的存储体;其中所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于各个处理器单元相对于彼此的放置以及基于所述矢量存储器相对于每个处理器单元的放置,以高带宽来交换数据通信。
本实用新型的另一个方面涉及一种具有矢量处理单元的计算系统,所述计算系统包含:一个或多个处理器单元,每个处理器单元包括被配置为执行多个算术运算的第一算术逻辑单元;与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器,所述矢量存储器包括存储体,所述存储体被配置为存储由所述一个或多个处理器单元中的每一个使用以执行所述算术运算的数据;和矩阵运算单元,被配置为接收来自特定处理器单元的至少两个操作数,所述至少两个操作数被所述矩阵运算单元使用以执行与矢量化计算相关联的操作;其中所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于至少一个处理器单元和所述矢量存储器之间的第一距离,以第一带宽来交换数据通信;其中所述矢量处理单元和所述矩阵运算单元耦合,使得能够基于至少一个处理器单元和所述矩阵运算单元之间的第二距离,以第二带宽来交换数据通信;以及其中所述第一距离小于所述第二距离,并且所述第一带宽大于所述第二带宽。
此外,一般而言,本说明书中描述的主题的一个创新方面能够体现在矢量处理单元中,所述矢量处理单元包括:一个或多个处理器单元,其每个被配置为执行与多维数据阵列的矢量化计算相关联的算术运算;以及与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器。所述矢量存储器包括被配置为存储由所述一个或多个处理器单元中的每一个使用以执行所述算术运算的数据的存储体。所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于各个处理器单元相对于彼此的放置以及基于所述矢量存储器相对于每个处理器单元的放置,以高带宽来交换数据通信。
在一些实施方式中,所述矢量处理单元耦合到矩阵运算单元,所述矩阵运算单元被配置为从特定处理器单元接收至少两个操作数,所述至少两个操作数被所述矩阵运算单元用于执行与所述多维数据阵列的矢量化计算相关联的操作。在一些实施方式中,所述矢量处理单元还包括耦合到所述特定处理器单元的第一数据串行器,所述第一数据串行器被配置为将与由所述特定处理器单元提供并由所述矩阵运算单元接收的一个或多个操作数相对应的输出数据串行化。在一些实施方式中,所述矢量处理单元还包括耦合到所述特定处理器单元的第二数据串行器,所述第二数据串行器被配置为将由所述特定处理器单元提供并由所述矩阵运算单元、交叉通道(cross-lane)单元、或归约和置换单元中的至少一个接收的输出数据串行化。
在一些实施方式中,所述一个或多个处理器单元中的每一个包括多个处理资源,并且所述多个处理资源包括第一算术逻辑单元、第二算术逻辑单元、多维寄存器或功能处理器单元中的至少一个。在一些实施方式中,所述矢量存储器被配置为将与特定存储体相关联的数据加载到相应的处理器单元,并且其中所述数据由所述相应的处理器单元的特定资源使用。在一些实施方式中,所述矢量处理单元还包括在所述一个或多个处理器单元和所述矢量存储器中间的纵横(crossbar)连接器,所述纵横连接器被配置为将与矢量存储体相关联的数据提供给特定处理器单元的所述多个处理资源中的特定资源。
在一些实施方式中,所述矢量处理单元还包括与特定处理器单元的资源进行数据通信的随机数发生器,所述随机数发生器被配置为周期性地生成数字,所述数字能够用作由所述特定处理器单元执行的至少一个操作的操作数。在一些实施方式中,所述矢量处理单元提供主处理通道并包括多个处理器单元,所述多个处理器单元每个分别在所述矢量处理单元内形成处理器子通道。在一些实施方式中,每一个处理器子通道基于每次访问被动态配置,以访问所述矢量存储器的特定存储体来检索用于执行与所述多维数据阵列的矢量化计算相关联的一个或多个算术运算的数据。
本说明书中描述的主题的另一个创新方面能够体现在具有矢量处理单元的计算系统中,所述计算系统包括:处理器单元,其每个包括被配置为执行多个算术运算的第一算术逻辑单元;与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器,所述矢量存储器包括存储体,所述存储体被配置为存储由所述一个或多个处理器单元中的每一个用于执行所述算术运算的数据;和矩阵运算单元,其被配置为接收来自特定处理器单元的至少两个操作数,所述至少两个操作数被所述矩阵运算单元使用以执行与矢量化计算相关联的操作。
所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于至少一个处理器单元和所述矢量存储器之间的第一距离以第一带宽来交换数据通信。所述矢量处理单元和所述矩阵运算单元耦合,使得能够基于至少一个处理器单元和所述矩阵运算单元之间的第二距离以第二带宽交换数据通信。所述第一距离小于所述第二距离,并且所述第一带宽大于所述第二带宽。
在一些实施方式中,所述计算系统还包括耦合到所述特定处理器单元的第一数据串行器,所述第一数据串行器被配置为将与由所述特定处理器单元提供并由所述矩阵运算单元接收的一个或多个操作数相对应的输出数据串行化。在一些实施方式中,所述计算系统还包括耦合到所述特定处理器单元的第二数据串行器,所述第二数据串行器被配置为将由所述特定处理器单元提供并由所述矩阵运算单元、交叉通道单元、或归约和置换单元中的至少一个接收的输出数据串行化。在一些实施方式中,所述一个或多个处理器单元中的每一个还包括多个处理资源,所述多个处理资源包含第二算术逻辑单元、多维寄存器或功能处理器单元中的至少一个。
在一些实施方式中,所述矢量存储器被配置为将与特定存储体相关联的数据加载到相应的处理器单元,并且其中所述数据由所述相应的处理器单元的特定资源使用。在一些实施方式中,所述计算系统还包括在所述一个或多个处理器单元和所述矢量存储器中间的纵横连接器,所述纵横连接器被配置为将与矢量存储体相关联的数据提供给特定处理器单元的所述多个处理资源中的特定资源。在一些实施方式中,所述计算系统还包括与特定处理器单元的资源进行数据通信的随机数发生器,所述随机数发生器被配置为周期性地生成数字,所述数字能用作由所述特定处理器单元执行的至少一个操作的操作数。在一些实施方式中,所述计算系统还包括在所述矢量存储器和所述矩阵运算单元之间延伸的数据路径,所述数据路径使得能够进行在所述矢量存储器和至少所述矩阵运算单元之间发生的与直接存储器存取操作相关联的数据通信。
本说明书中描述的主题的另一个创新方面能够体现在具有矢量处理单元的计算系统中的计算机实现的方法中。所述方法包括:由矢量存储器提供用于执行一个或多个算术运算的数据,所述矢量存储器包括用于存储相应的数据集的存储体;由一个或多个处理器单元接收来自所述矢量存储器的特定存储体的数据,所述数据被所述一个或多个处理器单元使用以执行与矢量化计算相关联的一个或多个算术运算;以及由矩阵运算单元接收来自特定处理器单元的至少两个操作数,所述至少两个操作数被所述矩阵运算单元使用以执行与矢量化计算相关联的操作。所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得基于至少一个处理器单元和所述矢量存储器之间的第一距离以第一带宽发生数据通信。所述矢量处理单元和所述矩阵运算单元耦合,使得基于至少一个处理器单元和所述矩阵运算单元之间的第二距离以第二带宽发生数据通信。所述第一距离小于所述第二距离,并且所述第一带宽大于所述第二带宽。
本说明书中描述的主题能够在特定实施例中实现,以实现以下优点中的一个或多个。使用包括高度本地化的数据存储和计算资源的矢量处理单元相对于现行的矢量处理器,能够提供增加的数据吞吐量。所描述的矢量存储器和矢量处理单元架构能够实现与示例矩阵-矢量处理器的矢量元素相关联的本地化的高带宽数据处理和算术运算。因此,基于使用以紧耦合布置设置在电路芯片内的矢量处理资源,能够提高和加速与矢量算术运算相关联的计算效率。
这方面和其他方面的其它实施方式包括对应的系统、装置和计算机程序,其被配置为执行在计算机存储设备上编码的方法的动作。一个或多个计算机的系统能够依靠安装在所述系统上的软件、固件、硬件或它们的组合来如此配置,使得在操作中引起所述系统执行所述动作。一个或多个计算机程序能够依靠具有指令来如此配置,使得当由数据处理装置执行所述指令时,引起所述装置执行所述动作。
本说明书中描述的主题的一个或多个实施方式的细节在下面的附图和描述中阐述。从所述描述、附图和权利要求书中,所述主题的其他潜在的特征、方面和优点将变得显而易见。
附图说明
图1示出了包括一个或多个矢量处理单元和多个计算资源的示例计算系统的框图。
图2示出了示例矢量处理单元的硬件结构的框图。
图3示出了包括乘法累加阵列和多个计算资源的示例计算系统的框图。
图4是用于执行矢量计算的过程的示例流程图。
在各个附图中相似的参考数字和名称表示相似的元素。
具体实施方式
本说明书中描述的主题一般涉及包括高度本地化的数据处理和计算资源的矢量处理单元(VPU),所述数据处理和计算资源被配置为相对于现行的矢量处理器提供增加的数据吞吐量。所描述的VPU包括支持与示例矩阵-矢量处理器的矢量元素相关联的本地化高带宽数据处理和算术运算的架构。
具体而言,本说明书描述了一种计算系统,其包括VPU的计算资源,所述VPU能够以紧耦合布置设置在集成电路芯片的预定区域内。所述预定区域能够分割成多个VPU通道,并且每一个通道能够包括多个本地化和不同的计算资源。在每一个VPU通道内,所述资源包括矢量存储器结构,所述矢量存储器结构能够包括多个存储体,所述存储体每个具有多个存储器地址位置。所述资源还能够包括多个矢量处理单元或VPU子通道,所述VPU子通道每个包括多个不同的计算资产/资源。
每一个VPU子通道能够包括被配置为存储多个矢量元素的多维数据/文件寄存器,以及被配置为对可从所述数据寄存器访问并存储在其内的所述矢量元素执行算术运算的至少一个算术逻辑单元(ALU)。所述计算系统还能够包括至少一个矩阵处理单元,其从相应的VPU子通道接收串行化的数据。一般而言,所述矩阵处理单元能够用于执行与例如神经网络推理工作负载相关联的非本地、低带宽和高时延的计算。
对于所描述的计算系统,所述矢量处理功能的高度本地化性质提供了在所述矢量存储器和多个VPU子通道之间、在相应的VPU子通道之间、以及在数据寄存器和所述ALU之间的高带宽和低时延数据交换。这些资源的基本上相邻的接近性使得数据处理操作能够以充分的灵活性并且在超过现有矢量处理器的期望性能和数据吞吐率下在VPU通道内发生。
举例而言,本说明书中描述的计算系统能够通过在多个矩阵-矢量处理器上分配矢量化计算来执行神经网络层的计算。在神经网络层内执行的计算过程可以包括将包括输入激活的输入张量与包括权重的参数张量相乘。张量是一种多维的几何对象,并且示例多维几何对象包括矩阵和数据阵列。
一般而言,在本说明书中可以参考与神经网络相关联的计算来说明所描述的VPU的一个或多个功能。然而,所描述的VPU不应限于机器学习或神经网络计算。相反,所描述的VPU能够用于与实现矢量处理器来达到期望的技术目标的各种技术领域相关联的计算。
此外,在一些实施方式中,大型的计算集能够被分开处理,使能够划分出第一子集的计算以在单独的VPU通道内处理,而第二子集的计算能够在示例矩阵处理单元内处理。因此,本说明书描述了能够实现两种数据连接性(例如,本地VPU通道连接性和非本地矩阵单元连接性)的数据流架构,以实现与这两种形式的数据处理相关联的优点。
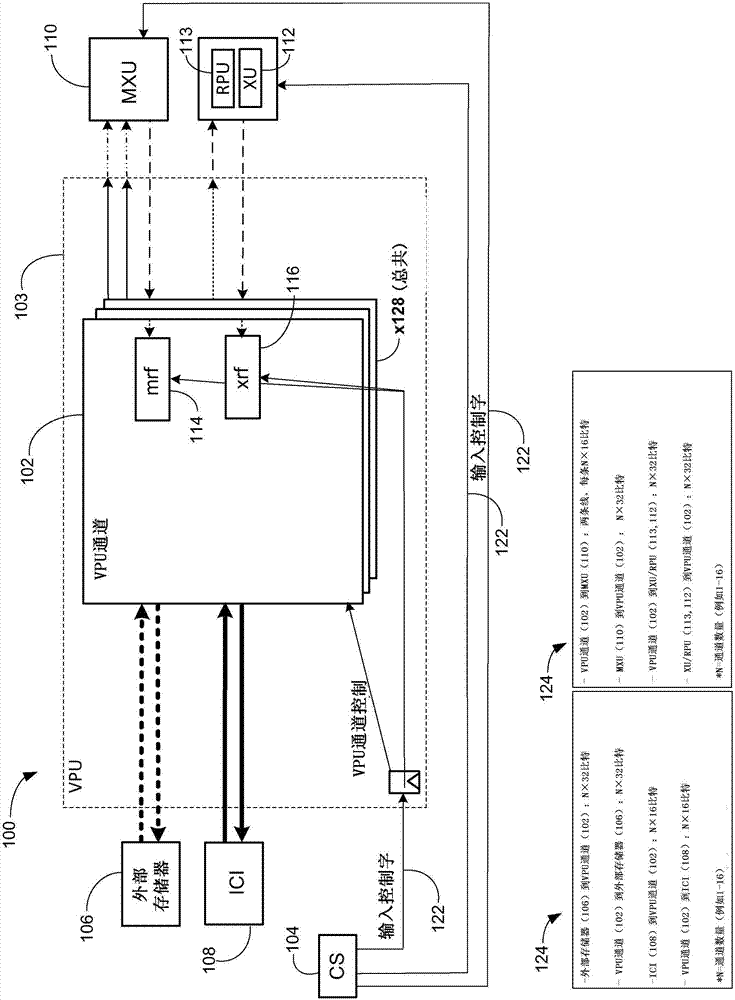
图1示出了包括一个或多个矢量处理单元和多个计算资源的示例计算系统100的框图。计算系统100(系统100)是示例数据处理系统,其用于执行与多层DNN的推理工作负载相关联的张量或矢量化计算。系统100一般包括矢量处理单元(VPU)通道102、核心序列发生器104、外部存储器(Ext.Mem.)106和芯片间互连(ICI)108。
如在本文中使用,通道通常对应于示例集成电路芯片中能够包括VPU的计算/数据处理资源的区域、区段或部分。同样地,如在本文中使用,子通道通常对应于示例集成电路芯片中能够包括VPU的计算/数据处理资源的通道的子区域、子区段或子部分。
系统100能够包括设置在集成电路(IC)芯片103上的多个VPU通道102。在一些实施方式中,IC芯片103能够对应于较大IC芯片的一部分或区段,所述较大IC芯片在相邻的芯片区段中包括图1中所描绘的其它电路组件/计算资源。而在其他实施方式中,IC芯片103能够对应于单个IC芯片,在所述单个芯片内通常不包括图1中描绘的其他电路组件/计算资源。
正如所示,所述其他组件/计算资源能够包括位于由IC芯片103的虚线包围的区域之外的参考特征(即,外部存储器106、ICI 108、MXU 110、XU 112、RPU 113)。在一些实施方式中,多个VPU通道102形成所描述的VPU,并且所述VPU能够通过由MXU 110、XU 112或RPU 113中的至少一个提供的功能来增强。例如,128个VPU通道102能够形成示例描述的VPU。在一些情况下,少于128个VPU通道102、或者多于128个VPU通道102能够形成示例描述的VPU。
如下面更详细讨论的,每一个VPU通道102能够包括具有多个存储体的矢量存储器(图2中的vmem 204),所述存储体具有用于存储与矢量的元素相关联的数据的地址位置。所述矢量存储器提供片上矢量存储器,其可被能够设置在IC芯片103内的所述多个VPU通道102的相应矢量处理单元访问。一般而言,外部存储器106和ICI 108每个与个体vmem 204(下面描述)交换数据通信,所述个体vmem 204每个与相应的VPU通道102相关联。所述数据通信通常能够包括,例如,将矢量元素数据写入特定VPU通道102的vmem或从特定VPU通道102的vmem读取数据。
如同所示,在一些实施方式中,IC芯片103能够是在系统100内提供矢量处理能力的单VPU通道配置。在一些实施方式中,相对于所述单VPU通道配置,系统100还能够包括多VPU通道配置,其具有总共128个VPU通道102,其在系统100内提供甚至更多的矢量处理能力。所述128个VPU通道配置在下面参考图2更详细地论述。
外部存储器106是由系统100用于向与VPU通道102的相应矢量处理单元相关联的矢量存储器提供和/或交换高带宽数据的示例存储器结构。一般而言,外部存储器106能够是远程或非本地存储器资源,其被配置为执行各种直接存储器访问(DMA)操作以访问、读取、写入或以其他方式存储和检索与系统100内的矢量存储体的地址位置相关联的数据。外部存储器106能够被描述为被配置为与系统100的片上矢量存储体(例如,vmem 204)交换数据通信的片外存储器。例如,参考图1,外部存储器106能够设置在IC芯片103外部的位置,并因此相对于设置在IC芯片103内的计算资源能够是远程的或非本地的。
在一些实施方式中,系统100能够包括嵌入式处理设备(下面论述),其执行基于软件的编程指令(例如,可从指令存储器访问)以例如将数据块从外部存储器106移动到vmem 204。此外,由所述嵌入式处理器执行所述编程的指令能够引起外部存储器106发起数据传输,以将数据元素加载和存储在可由VPU通道102的相应矢量处理单元访问的矢量存储器内。所存储的数据元素能够对应于可由特定的矢量处理单元访问的寄存器数据来实例化矢量元素,以为执行一个或多个矢量算术运算作准备。
在一些实施方式中,系统100的vmem 100、外部存储器106和其他相关存储器设备能够每个包括一个或多个非暂时性机器可读存储介质。所述非暂时性机器可读存储介质能够包括固态存储器、磁盘(内部硬盘或可移动磁盘)、光盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(例如,EPROM、EEPROM或闪速存储器)、或能够存储信息的任何其他有形介质。系统100还能够包括能够由专用逻辑电路补充或并入专用逻辑电路的一个或多个处理器和存储器。
ICI 108提供了能够管理和/或监视多个互连的数据通信路径的示例资源,所述数据通信路径耦合了系统100内不同的计算/数据处理资源。在一些实施方式中,ICI 108通常能包括使数据能够在非本地/芯片外设备和片上/本地计算资源之间流动的数据通信路径。此外,ICI 108通常也能包括使数据能够在IC芯片103内设置的各种片上或本地计算资源之间流动的通信路径。
系统100内耦合各种资源的所述多个通信路径能够每个被配置为具有不同或重叠的带宽或吞吐量数据率。如在本文中使用,在计算系统的上下文中,术语带宽和术语吞吐量一般对应于数据传输的速率,例如比特率或数据量。在一些实施方式中,比特率能够以例如每秒的比特/字节数、每时钟周期的比特/字节数测量,而数据量能够对应于移动通过系统100的多个通道的数据以比特/字数计的一般宽度(例如,2个通道×16比特)。
系统100还能够包括矩阵单元(MXU)110、交叉通道单元(XU)112、归约和置换单元(RPU)113、矩阵返回元件(mrf)114、交叉通道返回元件(xrf)116、以及输入控制122。一般而言,输入控制122能够是由非本地控制设备(例如核心序列发生器104)使用的常规控制线,以提供一个或多个控制信号,使得MXU 110、XU 112、RPU 113、mrf 114、xrf 116或PRNG 118中的至少一个来执行期望的功能。在一些实施方式中,核心序列发生器104经由输入控制122将多个控制信号提供给VPU通道102的组件,从而控制整个VPU通道102的功能。
虽然在图1的示例中描述了,但下面参考图2的实施方式更详细地论述mrf 114、xrf 116和PRNG 118以及它们相应的功能。类似地,下面参考图2和图3的实施方式更详细地论述MXU 110、XU 112和RPU 113。
图1包括数据列表124(在图2中也显示为特征224),其指示与“N”个通道数的特定数据路径相关联的数据吞吐量的相对大小,例如以比特计,其中N能够在例如1到16个通道变化/在该范围内。如图1和图2所示,能够使用不同的虚线特征来描述数据线,以指示特定的通道/数据路径能够具有不同的个体吞吐量(以比特/字节计)属性。注意,数据列表124和224不包括在系统100中,而是为了清楚起见和为了指示耦合不同计算资源的特定数据路径的吞吐量而在图1和2中显示。
图2示出了图1系统的示例矢量处理单元的硬件结构的框图。计算系统200(系统200)一般包括多个矢量处理单元202、矢量存储器(vmem)204、寄存器文件206、处理单元互连207、第一算术逻辑单元(ALU)208a、第二ALU 208b、专用单元210、第一纵横连接器(crossbar)212a和第二纵横连接器212b。在图2的实施方式中,矢量处理单元202被描绘为VPU通道202的子通道。在一些实施方式中,能够设置在单个VPU通道202内多个(x8)矢量处理单元202。
在一些实施方式中,系统100的一个或多个电路部分能够设置在IC芯片103的预定区域内。如上所述,系统100能够包括设置在IC芯片103上的多个VPU通道102。在一些实施方式中,IC芯片103能够被分割成包括子区段的部分或区段,子区段在子区段内设置了某些计算资源。因此,在图2的示例中,单个VPU通道102能够包括设置在IC芯片部分203上的多个VPU子通道(即,矢量处理单元)202,IC芯片部分203对应于较大的IC芯片103的子部分/子区段。
一般而言,VPU通道102的处理器单元202能够每个包括多个处理资源,并且每一个处理器单元202能够被配置为执行与多维数据阵列的矢量化计算相关联的算术运算(经由ALU)。如所示,每一个矢量处理单元或子通道102包括寄存器文件206、ALU 208a和ALU 208b以及专用单元210。设置在IC芯片部分203内的计算资源能够紧耦合在一起,并且因此在IC芯片部分203内基本上彼此相邻地设置。这些处理资源的基本上相邻的接近性使得能够以足够的灵活性以及在高带宽或数据吞吐率下在VPU通道102中发生数据操作。
在一些实施方式中,“紧耦合”能够对应于组件/计算资源和数据传输带宽之间的布线,二者都符合将组件/资源在例如彼此100微米内连接。在其他实施方式中,“耦合”而不是“紧耦合”能够对应于组件/资源和数据传输带宽之间的布线,其每个符合将组件在例如彼此200微米-10毫米内连接。
在替选实施方式中,系统100、200的组件或计算资源能够参考总芯片尺寸(例如,芯片103的尺寸或芯片部分203的尺寸)的特定比率来紧耦合或耦合。例如,“紧耦合”能够对应于在总芯片边缘尺寸的最多5%内连接的组件,而“耦合”能够对应于更远的、例如直到总芯片边缘尺寸的50%的组件。
在一些实施方式中,所描述的计算系统100的VPU的创新特征包括VPU通道102中的组件和/或计算资源,其每个在彼此特定或阈值的距离内,使得数据(例如,一个或多个32位字)能够容易地在单个时钟周期(即,线延迟)中穿越该距离。在一些实施方式中,所描述的VPU的这些创新特征直接对应于至少所述VPU通道102的组件相对于彼此的紧耦合布置。
在一些实施方式中,在子通道102的不同紧耦合资源之间提供数据流路径的导体(即,导线)能够长度相当短然而导体总数或在总线能够是一组导线的时候总线宽度大。较大的总线宽度(与传统IC总线宽度相比)使数据能够高带宽传输,对应于大量的操作。所述多个操作的高带宽属性使数据能够以低时延遍历矢量处理单元102的本地化资源。如在本文中使用,高带宽和低时延对应于与多个16位到32位字(即,高带宽)在单个时钟周期内(即,低时延)从一个计算资源移动到另一个计算资源相关联的数百(或在一些实施方式中数千)操作。系统200的高带宽、低时延属性在本文中后面更详细地描述。
一般而言,与相应的VPU通道102相关联的个体vmems 204每个被配置为与外部存储器106交换数据通信。所述数据通信通常能够包括,例如,外部存储器106向相应VPU通道102的vmems 204写入/从相应VPU通道102的vmems 204读取矢量元素数据。Vmem 204与每一个处理器单元202以及它们相应的多个处理资源(例如,ALU 208a/208b)进行数据通信。Vmem 204能够包括多个存储体,所述存储体在相应的地址位置处存储由每一个处理器单元202使用的数据以实例化由ALU 208a/208b访问的矢量(经由寄存器206)来执行一个或多个算术运算。
在一些实施方式中,VPU通道102能够包括在vmem 204和系统200中的一个或多个位置处设置的松耦合存储器之间延伸的数据路径。所述松耦合存储器能够包括片外存储器、不需要紧耦合或高带宽的片上存储器、来自其它处理单元例如所述互连上的其他VPU的存储器、或者向或从相连的主计算机传输的数据。在一些实施方式中,DMA传输能够通过本地(例如,来自CS单元104)或远程(例如,通过主计算机)的控制信号来启动。在一些实施方式中,数据通信通过ICI网络108遍历所述数据路径,而在其他实施方式中,所述数据通信能够经过处理器单元202遍历所述数据路径。在一些实施方式中,所述DMA路径也能够以与向和从MXU 110延伸的数据路径所使用的相同的机制被串行化/解串行化。
系统200通常提供紧耦合的数据路径的二维(2-D)阵列,使得系统100能够每时钟周期执行数千个数据操作。所述二维对应于总共128个通道(例如128个VPU通道102)乘每通道8个子通道。VPU通道102能够被描述为包括多个(例如,x8)处理器单元(即,子通道)的处理单元,所述处理器单元通常每个与多个(例如,x8)存储体中的一个耦合。所述系统200的数据路径的2D阵列能够具有空间特性,由此能够在分开的硬件结构上耦合和实现特定的数据路径。
在一些实施方式中,对于VPU通道102的所述8个不同的矢量处理单元202(即,x8维),当所述8个矢量处理单元202与系统200的其他资源例如MXU 110、XU 112和RPU 113(下面论述)交换数据通信时,能够通过解串行器222a/b对该单个通道102的数据操作进行串行化和解串行化。例如,特定的矢量处理操作能够包括VPU通道102向MXU 110发送多个(x8)32位字。因此,单个通道102中的所述8个矢量处理单元202中的每一个能够向MXU 110发送从其本地寄存器206可访问的32位字。
在一些实施方式中,所述32位字能够以串行化方式作为16位舍入浮点数以每时钟周期一个字(16比特/时钟周期)的示例数据速率发送。所述矢量处理操作还能够包括所述MXU110向所述8个矢量处理单元202中的每一个提供由所述MXU执行的乘法操作的结果。所述结果能够由VPU通道102接收并且在单个处理器时钟周期中同时存储(即,解串行化)在所述8个子通道202的相应的寄存器206内(256比特/时钟周期)。
纵横连接器212a提供从vmem 204到至少一个处理器单元202的数据路径,并且包括在某些数据传输操作期间遍历所述数据路径的32位字。同样地,纵横连接器212b提供从至少一个处理器单元202到vmem 204的数据路径,并且包括在某些数据传输操作期间遍历所述数据路径的32位字。在一些实施方式中,vmem 204与特定VPU子通道202之间的接口是加载类型的指令。例如,特定操作指令(例如,来自指令存储器)能够为每一个子通道202指定子通道将访问的特定存储体,以提取矢量相关的数据用于加载到本地寄存器206。在一些实施方式中,每一个处理器单元202能够基于每次访问进行动态配置,以访问vmem 204的特定存储体来检索矢量数据。
在一些实施方式中,经由纵横连接器212a/b的数据传输发生在系统200内的上述数据路径2-D阵列的x8维中。纵横连接器212a/b实现所述128个通道的每一个通道内每一个个体子通道202(x8)和vmem204的每一个个体存储体(x8)之间的完全连接性。一般而言,因为vmem 204被设置在IC芯片部分203内与相应的处理器单元202相当紧密地接近,所以纵横连接器212a/b能够经由导线来实现,所述导线长度相当短,然而总线宽度(或线数)相当大,以促进处理器单元202和vmem 204之间的高数据吞吐量。在一些实施方式中,vmem 204能够执行广播功能以向多个矢量处理单元202提供特定的一组矢量数据。
如上所述,每一个矢量处理单元202能够包括被配置为存储多个矢量元素的多维数据/文件寄存器206。因此,寄存器206能够是固定长度存储单元,其存储对应于单个矢量的数据。具体而言,寄存器206能够使用由处理器单元202(从vmem 204)接收的数据来填充具有多个矢量元素的特定矢量寄存器。在一些实施方式中,寄存器206使用从vmem 204的特定存储体接收的数据填充最多32个通常能表示为V0-V31的矢量寄存器。更具体而言,每一个矢量寄存器能够包括多个32位字。如在本文中使用,矢量通常能够对应于同某些类型的数据例如整数或浮点数相对应的二进制值的阵列(线性或非线性)。
所述32位数据能够对应于一个或多个ALU操作数。在一些实施方式中,每一个矢量处理单元202访问vmem 204的特定存储体以加载它自己的本地寄存器文件206来执行它自己的本地处理。在示例过程中,系统200的一个或多个矢量处理单元202能够被配置为执行用于示例算术运算的指令(例如,代码序列)。子通道互连207能用于在系统200的至少两个不同的矢量处理单元之间移动数据。
所述算术运算能够包括两个寄存器加载操作、加法操作和存储操作。在一些实施方式中,响应于系统200从示例更高级别的控制器设备接收到某些控制信号,能够从指令存储器(未显示)取出用于操作的指令并在本地解码。关于所述操作,第一加载序列能够包括系统200将来自vmem 204的示例存储器地址0x00F100的矢量数据加载到矢量处理单元202的至少一个矢量寄存器(V0)。类似地,第二加载序列能够包括系统200将来自vmem 204的示例存储器地址0x00F200的矢量数据加载到矢量处理单元202的至少一个其它矢量寄存器(V1)。
在硬件布局方面,在一些实施方式中,vmem 204能够被划分为128个通道,每通道8个存储体,每一个存储体具有多个地址位置。因此,在所述操作的加载序列期间,系统100、200内的示例寄存器将从vmem 204接收矢量数据。在一些实施方式中,并且如上所指出,示例矢量处理单元能够包括多个VPU通道102。因此,在一个或多个VPU通道102上的各个寄存器206能够协作,以形成跨越128个通道乘8个子通道202维的矢量寄存器。
在所述128维中,单个VPU通道102能够从它相应的vmem 204加载。更具体地,在所述子通道维数(x8)中,每一个子通道202能够从vmem 204的8个存储体中的特定存储体来加载它的矢量寄存器。在一些实施方式中,也能够执行迈进(strided)存储器访问操作。关于所述操作,所述第一加载序列的完成导致矢量数据被加载到矢量寄存器V0中,使得所述寄存器将包括128×8个值。为了清楚起见,在一些实施方式中,VPU通道102的矢量寄存器的全维数能够是128个通道x 8个子通道x 32个寄存器x 32位。因此,128×8对应于子通道总数,而32×32对应于每一个子通道的矢量寄存器位数。
所述第二加载序列的完成导致矢量数据被加载到矢量寄存器V1中,使得所述寄存器也将包括128x 8个值。接下来,能够执行经由ALU 208a或208b之一的加法指令,其包括将V0(128×8个值)与V1(128×8个值)相加。在一些实施方式中,能够在执行存储操作之后对所总和的矢量数据执行示例置换操作(以对所述数据进行排序、再排列或定序)以将所述数据存储在示例矢量寄存器V3中。此外,如下面所论述的,能够执行置换操作以在至少两个不同的VPU通道102之间移动数据。
IC芯片部分203内的本地化资源的高带宽、低时延属性能够参考后面的示例来表征。一般而言,系统200的所述128×8维在示例VPU内创建1024个潜在数据路径。这些数据路径对应于vmem 204的在单个通道(VPU通道102)中的所述8个存储体,其沿着8个个体通道(经由纵横连接器212a/b)向在VPU通道202内所述8个个体子通道中的每一个提供8个单独的32位字。更具体地,在128个通道上复制这8个个体通道,以便创建所述1024个潜在的数据路径。
当各个32位字遍历IC芯片区段203中的第一资源和IC芯片区段203中的第二资源之间的路径时,所述1024个数据路径能够对应于1024个操作。此外,包含ALU 208a、208b创建了附加的1024个潜在数据路径,其对应于能够在IC芯片203内的多个资源上发生至少2048个操作。因此,IC芯片部分203中的所述资源的紧耦合、高度本地化、高带宽的属性使得至少2048个操作能够在单个时钟周期内发生。此外,取决于对所述字执行的操作的类型,在单个时钟周期中同时发生的这2048个操作中的每一个都能够包括遍历特定数据路径的32位字(例如,矢量或操作数)。
在一些实施方式中,并且为了扩展上述示例,在由系统200执行的单个时钟周期中,以下中的一项或更多项能够发生在单个VPU通道102内:1)8个矢量从vmem 204移动到8个子通道202;2)两个矢量操作数从寄存器206移动到ALU 208a、208b;3)两个结果矢量从ALU 208a、208b移动到寄存器206;4)8个矢量操作数从相应的子通道202移动到串行器214或216(在下文描述);5)8个结果矢量从mrf 114或xrf 116移动(在下文描述);以及6)8个结果矢量从所述8个子通道移动到XU/RPU串行器218(在下文描述)。前述的示例操作列举仅仅表示系统200的紧耦合本地化资源的高带宽属性。
专用单元210提供附加的本地处理能力,在一些实施方式中,其能够与由相应的子通道202的ALU 208a/208b提供的功能同义。在一些实施方式中,专用单元210能够被描述为功能处理器单元。例如,专用单元210能够被设计成处理和评估与本地寄存器206中存储的矢量数据的算术运算相关联的一元超越函数。因此,对应于例如指数函数或对数函数的某些复杂算术运算能够由专用单元210执行。
如上所述,所描述的系统100、200的技术特征在于每一个子通道202充分地物理靠近在一起(即非常紧地耦合),使得由ALU 208a和208b执行的高带宽算术运算二者在单个处理器时钟周期期间同时发生。在一些实施方式中,某些复杂算术运算可能需要附加的/多个时钟周期来完成。因此,系统200可能够采用专用单元210来分离某些复杂的多周期操作以备特殊处理。
PRNG 118能够是被配置为产生伪随机数的共享资源,所述伪随机数能够在由各个子通道202的ALU 208a/208b执行的矢量算术运算期间由多个子通道202上的寄存器206使用。一般而言,PRNG 118能够从矢量处理单元202接收至少一个控制信号,以将示例数字发生器电路初始化为初始状态。PRNG 118后来能够从该初始状态演变以周期性地产生随机数,所述随机数能被特定的矢量处理单元202用来完成与矢量运算相关联的某个操作。
一般而言,每一个矢量处理单元202通常将执行对于PRNG 118的读取操作。间或地,特定的子通道可以向PRNG 118提供控制信号来执行写入序列,以例如引起某个数值再现性操作。某些再现性操作能被用于实现特定的数值技术,所述技术适用于涉及神经网络推理工作负载的计算。此外,在矢量化计算期间,系统200通过注入随机噪声来稍微失真与计算相关联的数值舍入操作从而产生一个或多个数值的某些较窄表示,能是有益的。还有,在一些实施方式中,PRNG 118能够提供用于在子通道202内发生的数据处理的操作数的另一个源。
系统200还包括第一数据串行器214、第二数据串行器216、XU/RPU串行器218和数据解串行器222a/b,它们每个与特定处理器单元202耦合。一般而言,数据串行器214、216被配置为将矢量输出数据串行化,所述矢量输出数据能够包括由特定处理器单元202提供并由MXU 110接收的至少两个操作数。如所显示的,所述串行化的矢量数据能够经由数据路径220a/b提供给MXU 110,使得第一操作数能够经由第一数据路径220a提供以及第二操作数能够经由第二数据路径220b提供。在一些实施方式中,数据串行器214和216能够被配置为起移位寄存器的作用,在多个时钟周期(高时延)内顺序地移出操作数数据。
一般而言,数据串行器214和216能够使相应的子通道202在昂贵的互连线上时间分割多路传输串行化的矢量输出数据。所述高价互连线将数据路径220a/b/c提供给对所接收的串行化矢量数据执行某些乘法操作的远程非本地协处理资源。如上所述,对于图2的实施方式,远程非本地协处理资源能够对应于IC芯片区段203外部的资源(例如,MXU 110、XU 112和RPU 113)。这些资源通常经由数据路径220a/b/c接收低带宽(例如,单个32位操作数)、高时延(在多个时钟周期内)矢量数据。
关于数据移动和数据量,128个通道(即,VPU通道102)中的每一个能够具有8个每个32位宽的数据字或操作数。所述8个数据字能够对应于VPU通道102内的8个子通道中的每一个。系统200能够被配置为将所述8个数据字加载到例如数据串行器214、216或218中。所述8个数据字然后能够在8个处理器时钟周期的时间段内移出到MXU 110、XU 112或RPU 113中的一个。与IC芯片区段203的紧耦合本地化资源之间较短、较宽的高带宽数据路径相反,MXU 110、XU112和RPU 113每个相对于与相应子通道202的资源的单元接近度而言相当远并且非本地。
因此,在并入系统100和200的示例VPU中,在每个时钟周期,所述VPU能够执行指令以进行利用和/或移动1024个每个32位宽的字的操作。当集体形成所述1024个字的矢量数据部分到达和/或通过单个数据串行器214、216时,所述数据然后通过每时钟周期仅操作或移出128个字的数据路径220a/b前进。因此,所述数据串行器214、216能够被配置为仅串行化在x8维中的数据,使得在x128维中每一个VPU通道102上仍有并行度。
例如,数据串行器214、216能够在功能上彼此独立,因此,在第一时钟周期(例如,周期N)中,系统200能够引起全部1024个字(对于全部128个通道,每通道8个字,每一个子通道1个)被加载到例如用于特定矢量处理单元202的第一数据串行器214的存储器位置。系统200然后能执行一个或多个指令,以引起所述128个通道上的每一个第一数据串行器214的内容经由相应的数据路径220a以每时钟周期16比特的带宽向MXU 110移出。在一些实施方式中,由串行器214接收的32位字能够作为16位舍入浮点数以串行化方式发送。
此外,为了清楚起见,虽然提供给MXU 110、XU 112和RPU 113的所述32位操作数在本文中被描述为“字”,但所述操作数通常能够对应于数字(例如,浮点)并且所述描述符“字”仅用于指示能够由示例处理器核心的硬件设备作为单元来处理的一段固定大小的二进制数据。
再次参考示例数据流序列,在第二时钟周期(例如,周期N+1)中,系统200能够引起另外的1024个字(对于全部128个通道,每通道8个字,每一个子通道1个)被加载到例如用于同一矢量处理单元202的第二数据串行器216的存储器位置。系统200然后能执行一个或多个指令,以引起所述128个通道上的每一个第二数据串行器216的内容经由相应的数据路径220b以每时钟周期16比特的带宽向例如MXU 110移出。因此,从数据串行器214、216延伸的数据路径220a/b能够彼此并行使用。
在一些实施方式中,这种示例数据流序列能够在多个数据周期(例如,周期N+2、周期N+3等)上继续向MXU 110加载几个矩阵乘操作数集合。当被加载时,与例如矢量化计算相关联的大量矩阵乘操作能够由MXU 110处理,以计算示例推理工作负载。所述矩阵乘法的结果能够由例如mrf 114的存储器单元接收并存储在其内,用于被特定VPU通道102内的特定子通道202接收。Mrf 114包括先进先出(FIFO)功能,并且能够被配置为保存/存储与较长时延操作相关联的返回数据(乘法结果)。存储在mrf 114的存储器内的所述返回数据能够用单独的较短时延指令写回到矢量寄存器206。
所述矩阵乘结果能够以每时钟周期32比特的吞吐量在从MXU110到mrf 114的串行化数据流中移动。在一些实施方式中,所述矩阵乘法的结果在第一时间段被接收,并且在由解串行器222a解串后存储在mrf 114内,用于在时间迟于第一时间段的第二时间段被子通道202接收。在一些实施方式中,第二时间段对应于范围能够从1个时钟周期发生到128个时钟周期发生的时间点。
例如,在第一处理器时钟周期,mrf 114能够在第一时间段接收矩阵乘结果,并将所述结果存储在mrf 114的存储器地址内。在系统200已执行另外的100个处理器时钟周期以执行其他矢量处理操作之后,系统200然后能执行指令以弹出(pop)mrf 114并在100个时钟周期以后的第二时间段接收结果数据。如上所述,mrf 114执行先进先出数据流序列,使得首先被接收的矩阵乘结果首先被写入寄存器206的特定矢量寄存器。
关于归约和置换操作,RPU 113能够包括sigma单元和置换单元。在一些实施方式中,由sigma单元处理的计算的结果被提供给所述置换单元。所述sigma单元或所述置换单元可以被禁用,使得数据通过特定单元不改变。一般而言,所述sigma单元在单条数据线上执行顺序归约。所述归约能够包括总和和各种类型的比较操作。
响应于接收输入数据,所述置换单元能够部分基于命令/控制矢量来执行全通用纵横连接器操作,所述命令/控制矢量是来自所述输入数据的利用比特的集。对于归约操作,由RPU 113使用的数据能够是32位浮点(FP)格式;而对于置换操作,能使用各种数据类型/格式,包括FP、整数和地址。在一些实施方式中,RPU113向XU112提供任何接收的数据、从XU112接收结果数据、和执行一个或多个混合(muxing)操作以生成具有多个结果数据的不同输出流。
在一些实施方式中,置换操作能够由RPU 113执行,以在至少两个不同的VPU通道102之间移动数据。一般而言,所述置换指令引起128×8个数据值从相应的寄存器206移动到子通道XU/RPU串行器218。具体而言,在执行所述操作期间,32位矢量结果数据以x8维被串行化。因此,在128个通道(VPU通道102)的每一个内,与8个子通道相对应的8个矢量结果字能够在8个处理器时钟周期的时间段内从第一VPU通道102移动到第二VPU通道102。
所述矢量数据能够跨越两个通道以每时钟周期32比特的吞吐量,沿着数据路径220c在从XU/RPU串行器218到XU/RPU 112、113的串行化数据流中移动。对于接收交叉通道矢量数据的特定VPU通道102,xrf 116能够包括例如被配置为存储在特定VPU通道102处接收到的交叉通道矢量结果数据的存储器。在一些实施方式中,矢量数据能够在第一时间段被接收并且在被解串行器222b解串行化之后存储在xrf 116内,用于在晚于第一时间段的第二时间段由子通道202接收。
在一些实施方式中,第二时间段对应于范围能从发生1个时钟周期到发生128个时钟周期的时间点。例如,在第一处理器时钟周期,xrf 116能够在第一时间段接收来自第一VPU通道102的矢量数据,并将所述结果存储在xrf 116的存储器地址内。在系统200已执行另外100个处理器时钟周期以执行其他矢量处理操作之后,系统200然后能执行指令以弹出xrf 116并在100个时钟周期以后的第二时间段接收矢量数据。一般而言,类似于mrf 114,xrf 116也实现先入先出的数据流序列,使得首先接收到的矢量首先被写入寄存器206的特定矢量寄存器。
图3示出了包括乘法累加阵列和多个计算资源的图1示例计算系统的框图。如所示,系统300通常能够包括以上参考图1和图2所论述的组件中的一个或多个。系统300还能够包括嵌入式协处理器302。一般而言,处理器302能够被配置为执行基于软件的编程指令以将数据块从外部存储器106移动到多个vmems 204。此外,所述指令的执行能够引起外部存储器106发起数据传输来加载和存储vmem 204内的数据元素。
图3包括数据映射304,其指示与特定流路径的数据吞吐量相关联的相对大小,例如以比特计。如图所示,数据映射304包括各种图例,其对应于某些计算资源之间的给定路径的单独吞吐量(以比特计)。注意,数据映射304不包括在系统300中,而是为了清楚起见和为了指示耦合不同计算资源的特定数据路径的吞吐量而在图3中显示。
一般而言,图3的示例提供了系统200的资源的另一种表示。例如,系统300包括两个VPU通道102,其对应于上面讨论的128个个体通道中的两个。同样地,对于每个通道102,系统300还包括两个子通道202,其对应于上面论述的8个个体子通道中的两个。系统300还包括8个个体通道306,其提供vmem 204的8个存储体与相应的8个子通道202之间的数据流路径(经由纵横连接器212)。
如上所述,并且如数据映射304所示,8个32位矢量字能够在单个处理器时钟周期期间从vmem 204移动到所述8个个体子通道。如所示,在一些实施方式中,vmem 204能够是静态随机存取存储器(SRAM),并且子通道202能够被描述为单输入多数据处理单元。系统300还包括以上参考图2所论述的MXU 110和交叉通道(XU)单元112的另一种表示。
一般而言,MXU 110对应于具有128×128维的乘法累加运算符,并且因此被配置为接收许多的矢量-矩阵乘法操作数集。如上所述,一旦加载了足量的矢量操作数,MXU 110就能够处理与矢量化计算相关联的大量矩阵乘法操作,来计算示例推理工作负载。
如所示,每个子通道202包括朝向(向外)XU 112的数据流路径以及从(向内)XU 112朝向子通道202的数据流路径。这两个不同的流路径对应于XU的使矢量数据能够在至少两个不同的VPU通道102之间移动的功能。因此,每一个VPU通道102通常将包括朝向XU 112的向外矢量数据流路径以对应于来自第一VPU通道102的矢量数据移动到第二VPU通道102的情况。同样地,每一个VPU通道102通常将包括来自XU 112的向内矢量数据流路径以来对应于来自第一VPU通道102的矢量数据被第二VPU通道102接收的情况。
图4是利用图1和图2的计算系统执行矢量计算的过程的示例流程图。因此,过程400能够使用系统100和200的上述计算资源来实现。
过程400在框402处开始并且矢量存储器(vmem 204)提供用于执行一个或多个算术运算的数据。如上所述,vmem 204能够包括用于存储相应的矢量数据集的多个存储体。所述矢量数据被提供给VPU通道102的一个或多个处理器单元202。在框404处,至少一个处理器单元202接收由vmem 204提供的所述矢量数据。所接收的数据能够对应于特定的存储体,并且进一步能够是由处理器单元202从所述存储体的特定地址位置访问的矢量数据。由处理器单元202接收的数据被寄存器206用来实例化具有多个矢量元素的特定矢量寄存器。
在框406处,基于处理器单元202和vmem 204紧耦合,以特定带宽(第一带宽)交换所述vmem 204与至少一个处理器单元202之间的数据通信。在一些实施方式中,对于某些操作,数据能够在将通道204和处理器单元202的寄存器206互连的8个通道中的一个或多个上,以每时钟周期256比特(8通道x32比特)的示例带宽或数据速率移动。一般而言,在给定的时钟周期期间能够发生多个操作,并且所述操作的数量能够在每时钟周期1024-2048个操作的范围内(例如,高带宽操作)。
在一些实施方式中,当处理器单元202和vmem 204之间的特定距离(例如,第一距离)在0.001-100微米的范围内时,所述两个计算资源是紧耦合的。例如,当第一距离在0.001微米与.1微米之间、0.01微米与10微米之间或.1微米与100微米之间时,处理器单元202与vmem 202能够是紧耦合的。同样地,当所述处理器单元202的多个处理资源(例如,寄存器文件206、ALU 208a/b和专用单元210)之间的特定距离也在.001-100微米的范围内时,所述多个资源能够是相对于彼此紧耦合的。以上参考处理器单元202和vmem 204提供的示例距离也能适用于矢量处理单元202的多个资源之间的距离。
在框408处,所接收的数据能够被处理器单元202的ALU 208a或ALU 208b使用、访问或修改,以执行与用于计算推理工作负载的矢量化计算相关联的一个或多个算术运算。在过程400的框410处,基于处理器单元202和MXU 110是耦合而不是紧耦合,以特定带宽(第二带宽)交换至少一个处理器单元202与MXU 110之间的数据通信。
在一些实施方式中,对于某些操作,数据能够在将单个处理器单元202的与MXU 110互连的2条数据线中的至少一条上,以每时钟周期32比特(2条线x16-比特)的示例带宽或数据速率移动。通常,能够在给定的时钟周期期间发生在本地和非本地资源之间(例如子通道202到MXU或XU)的多个操作,并且操作的数量能够在每时钟周期10-12个操作的范围内(例如,低带宽操作)。
在一些实施方式中,当处理器单元202和vmem 204之间的特定距离(例如,第二距离)在200微米-10毫米(mm)的示例范围内时,所述两个计算资源是耦合的。例如,当第二距离在200微米与1mm之间、在500微米与2mm之间、或在1mm与10mm之间时,处理器单元202与MXU 110能够是耦合的。同样地,当处理器单元202与XU 112(或RPU113)之间的特定距离也在200微米-10mm的范围内时,处理器单元202与XU 112(或RPU113)能够是耦合而不是紧耦合的。
以上参考处理器单元202和MXU 110提供的示例距离也能适用于矢量处理单元202和XU 112(或RPU 113)之间的距离。在一些实施方式中,所述第二距离能超过10mm,但是能够小于示例计算机系统的印刷电路板的分离IC之间的标准距离。
在框412处,MXU 110从至少一个处理器单元202接收至少两个操作数(各为32位宽)。一般而言,所述至少两个操作数被MXU 110用来执行与多维数据阵列的矢量化计算相关联的操作。如上所述,MXU110能够包括乘法累加运算符的阵列(MAC阵列310),其被配置为执行与矢量化计算相关联的数千个乘法和浮点操作以计算特定神经网络层的推理工作负载。
MAC阵列310能够被进一步配置为将计算结果提供回到vmem204以存储在特定存储体的地址位置中。在一些实施方式中,子通道202向XU 112提供本地矢量结果数据,使得结果能够在一个或多个其他VPU通道102之间共享。例如,来自第一VPU通道102的计算结果(输出)能被用作在另一个第二VPU通道102内发生的计算的输入。在一些实施方式中,所述第二VPU通道102能够被配置为执行与另一个神经网络层的推理工作负载相关联的矢量化计算。
本说明书中描述的主题和功能操作的实施例能够以数字电子电路、以有形体现的计算机软件或固件、以计算机硬件——包括本说明书中公开的结构以及它们的结构等同体、或以它们中一个或多个的组合实现。在本说明书中描述的主题的实施例能够实现为一个或多个计算机程序,即在有形非暂时性程序载体上编码并用于由数据处理装置执行或控制所述数据处理装置的操作的计算机程序指令的一个或多个模块。备选地,或附加地,所述程序指令能够在人工生成的传播信号例如机器生成的电、光或电磁信号上编码,所述信号的生成是为了编码信息以传输到合适的接收器装置供数据处理装置执行。所述计算机存储介质能够是机器可读存储设备、机器可读存储基板、随机或串行存取存储设备、或者它们中的一个或多个的组合。
本说明书中描述的过程和逻辑流能够由执行一个或多个计算机程序的一个或多个可编程计算机来进行,以通过操作输入数据和生成输出来执行功能。所述过程和逻辑流也能够由专用逻辑电路例如FPGA(现场可编程门阵列)、ASIC(专用集成电路)或GPGPU(通用图形处理单元)来执行,并且装置也能够实现为所述专用逻辑电路。
适合于执行计算机程序的计算机包括,例如,能够基于通用或专用微处理器或者两者,或者任何其他类型的中央处理单元。通常,中央处理单元将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是用于施行或执行指令的中央处理单元以及一个或多个用于存储指令和数据的存储设备。通常,计算机也将包括一个或多个用于存储数据的大容量存储设备,例如磁盘、磁光盘或光盘,或与之可操作地耦合以从其接收数据或向其传输数据,或两者。然而,计算机不需要具有这样的设备。
适合于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如EPROM、EEPROM和闪存设备;磁盘,例如内部硬盘或可移动磁盘。所述处理器和存储器能够由专用逻辑电路补充或者并入专用逻辑电路。
虽然本说明书包含许多具体的实施方式细节,但是这些不应该被解释为对任何实用新型的或可以要求保护的范围的限制,而是作为可能对特定实用新型的特定实施例具体的特征的描述。在本说明书中在分开的实施例的上下文中描述的某些特征也能够在单个实施例中组合实现。相反,在单个实施例的上下文中描述的各种特征也能够在多个实施例中分开地或以任何合适的子组合来实现。此外,虽然特征可以在上面描述为以某些组合起作用并且甚至最初是按照这样要求保护的,但是来自所要求保护的组合的一个或多个特征在一些情况下能够从该组合中摘除,并且所要求保护的组合可以涉及子组合或子组合的变体。
类似地,虽然在附图中以特定的顺序描述了操作,但是这不应该被理解为要求以所显示的特定顺序或相继顺序执行这样的操作,或者要执行所有示出的操作来达到期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分离不应当被理解为在所有实施例中都需要这样的分离,并且应该理解,所描述的程序组件和系统通常能够在单个软件产品中整合在一起或者分包成多个软件产品。
已经描述本主题的特定实施例。其他实施例在所附权利要求的范围内。例如,权利要求中所述的动作能够按不同的顺序执行并且仍然达到期望的结果。作为一个示例,附图中描绘的过程不一定需要所显示的特定顺序、或相继顺序,来达到期望的结果。在某些实施方式中,多任务和并行处理可能是有利的。
优选实施例:
实施例1a:
一种矢量处理单元,其包含:
一个或多个处理器单元,其每个被配置为执行与多维数据阵列的矢量化计算相关联的算术运算;和
与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器,其中所述矢量存储器包括被配置为存储由所述一个或多个处理器单元中的每一个使用以执行所述算术运算的数据的存储体;
其中所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于各个处理器单元相对于彼此的放置以及基于所述矢量存储器相对于每个处理器单元的放置,以高带宽来交换数据通信。
实施例1b:
实施例1a所述的矢量处理单元,其中紧耦合的特征在于以下实施例中的至少一个:
-一个或多个处理器单元和所述矢量存储器在IC芯片区段内物理上靠近,优选彼此相邻地布置;
-距离小于100微米、优选小于10微米、非常优选小于1微米;或者
-距离小于IC芯片总边缘尺寸的5%;
和/或其中高带宽的特征在于以下实施例中的至少一个:
-与多个16位至32位字相关联的数百或数千个操作;或者
-至少2048个操作,其优选在IC芯片内的多个资源上发生,非常优选包括32位字,
优选以低时延,非常优选每单个时钟周期有上述数量的操作。
实施例2:
实施例1a或1b所述的矢量处理单元,其中所述矢量处理单元被配置用于耦合到矩阵运算单元,所述矩阵运算单元被配置为从特定处理器单元接收至少两个操作数,所述至少两个操作数被所述矩阵运算单元用于执行与所述多维数据阵列的矢量化计算相关联的操作。
实施例3:
实施例2所述的矢量处理单元,其还包含耦合到所述特定处理器单元的第一数据串行器,所述第一数据串行器被配置为将与由所述特定处理器单元提供并由所述矩阵运算单元接收的一个或多个操作数相对应的输出数据串行化。
实施例4:
实施例2或3所述的矢量处理单元,其还包含耦合到所述特定处理器单元的第二数据串行器,所述第二数据串行器被配置为将由所述特定处理器单元提供并由以下至少一个接收的输出数据串行化:所述矩阵运算单元,交叉通道单元,或归约和置换单元。
实施例5:
实施例1a至4之一所述的矢量处理单元,其中所述一个或多个处理器单元中的每一个包含:
多个处理资源,所述多个处理资源包含第一算术逻辑单元、第二算术逻辑单元、多维寄存器或功能处理器单元中的至少一个。
实施例6:
实施例1a至5之一所述的矢量处理单元,其中所述矢量存储器被配置为将与特定存储体相关联的数据加载到相应的处理器单元,并且其中所述数据由所述相应的处理器单元的特定资源使用。
实施例7:
实施例1a至6之一所述的矢量处理单元,其还包含在所述一个或多个处理器单元和所述矢量存储器中间的纵横连接器,所述纵横连接器被配置为将与矢量存储体相关联的数据提供给特定处理器单元的多个处理资源中的特定资源。
实施例8:
实施例1a至7之一所述的矢量处理单元,其还包含与特定处理器单元的资源进行数据通信的随机数发生器,所述随机数发生器被配置为周期性地生成数字,所述数字能用作由所述特定处理器单元执行的至少一个操作的操作数。
实施例9:
实施例1a至8之一所述的矢量处理单元,其中所述矢量处理单元提供处理通道并包括多个处理器单元,所述多个处理器单元每个分别在所述矢量处理单元内形成处理器子通道。
实施例10:
实施例9所述的矢量处理单元,其中每一个处理器子通道基于每次访问被动态配置,以访问所述矢量存储器的特定存储体来检索用于执行与所述多维数据阵列的矢量化计算相关联的一个或多个算术运算的数据。
实施例11:
一种具有矢量处理单元的计算系统,所述系统包含:
一个或多个处理器单元,其每个包括被配置为执行多个算术运算的第一算术逻辑单元;
与所述一个或多个处理器单元中的每一个进行数据通信的矢量存储器,所述矢量存储器包括存储体,所述存储体被配置为存储由所述一个或多个处理器单元中的每一个用于执行所述算术运算的数据;和
矩阵运算单元,其被配置为接收来自特定处理器单元的至少两个操作数,所述至少两个操作数被所述矩阵运算单元用于执行与矢量化计算相关联的操作;
其中所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得能够基于至少一个处理器单元和所述矢量存储器之间的第一距离,以第一带宽来交换数据通信;
其中所述矢量处理单元和所述矩阵运算单元耦合,使得能够基于至少一个处理器单元和所述矩阵运算单元之间的第二距离,以第二带宽来交换数据通信;以及
其中所述第一距离小于所述第二距离,并且所述第一带宽大于所述第二带宽。
实施例12:
实施例11所述的计算系统,其还包含耦合到所述特定处理器单元的第一数据串行器,所述第一数据串行器被配置为将与由所述特定处理器单元提供并由所述矩阵运算单元接收的一个或多个操作数相对应的输出数据串行化。
实施例13:
实施例12所述的计算系统,其还包含耦合到所述特定处理器单元的第二数据串行器,所述第二数据串行器被配置为将由所述特定处理器单元提供并由以下至少一个接收的输出数据串行化:所述矩阵运算单元,交叉通道单元、或归约和置换单元。
实施例14:
实施例11至13之一所述的计算系统,其中所述一个或多个处理器单元中的每一个还包括多个处理资源,所述多个处理资源包含第二算术逻辑单元、多维寄存器或功能处理器单元中的至少一个。
实施例15:
实施例14所述的计算系统,其中所述矢量存储器被配置为将与特定存储体相关联的数据加载到相应的处理器单元,并且其中所述数据由所述相应的处理器单元的特定资源使用。
实施例16:
实施例14或15所述的计算系统,其还包含在所述一个或多个处理器单元和所述矢量存储器中间的纵横连接器,所述纵横连接器被配置为将与矢量存储体相关联的数据提供给特定处理器单元的所述多个处理资源中的特定资源。
实施例17:
实施例14至16之一所述的计算系统,其还包含与特定处理器单元的资源进行数据通信的随机数发生器,所述随机数发生器被配置为周期性地生成数字,所述数字能用作由所述特定处理器单元执行的至少一个操作的操作数。
实施例18:
实施例11至17之一所述的计算系统,其还包含在所述矢量存储器和所述矩阵运算单元之间延伸的数据路径,所述数据路径实现在所述矢量存储器和至少所述矩阵运算单元之间发生的与直接存储器存取操作相关联的数据通信。
实施例19:
一种在具有矢量处理单元的计算系统中的计算机实现的方法,所述方法包括:
由矢量存储器提供用于执行一个或多个算术运算的数据,所述矢量存储器包括用于存储相应的数据集的存储体;
由一个或多个处理器单元接收来自所述矢量存储器的特定存储体的数据,所述数据被所述一个或多个处理器单元用于执行与矢量化计算相关联的一个或多个算术运算;以及
由矩阵运算单元接收来自特定处理器单元的至少两个操作数,所述至少两个操作数被所述矩阵运算单元用于执行与矢量化计算相关联的操作;
其中所述一个或多个处理器单元和所述矢量存储器在所述矢量处理单元的区域内紧耦合,使得基于至少一个处理器单元和所述矢量存储器之间的第一距离以第一带宽发生数据通信;
其中所述矢量处理单元和所述矩阵运算单元耦合,使得基于至少一个处理器单元和所述矩阵运算单元之间的第二距离以第二带宽发生数据通信;以及
其中所述第一距离小于所述第二距离,并且所述第一带宽大于所述第二带宽。
实施例20:
实施例19所述的计算机实现的方法,其还包含:
由第一数据串行器或第二数据串行器中的一个将串行化的输入数据提供给以下中的至少一个:所述矩阵运算单元、交叉通道单元、或归约和置换单元,其中所述串行化输入数据包括多个操作数;并且
其中所述第一数据串行器和所述第二数据串行器设置在所述一个或多个处理器单元和以下至少一个的中间:所述矩阵运算单元,所述交叉通道单元,或所述归约和置换单元。
- 还没有人留言评论。精彩留言会获得点赞!