在数据库表、文本文件和数据馈送中对文本和指纹识别进行加盐的制作方法
本发明的领域是对数据集的数据和指纹识别进行加盐以确定数据是否被不当地复制或使用。加盐是将独特数据(盐)插入数据子集,使得在数据被泄漏的情况下,被包含在该数据子集中的数据可被标识回数据所有者的机制。指纹识别是从数据集产生短得多的集合的过程,尽管如此,它的指纹仍标识原始数据集。
背景技术:
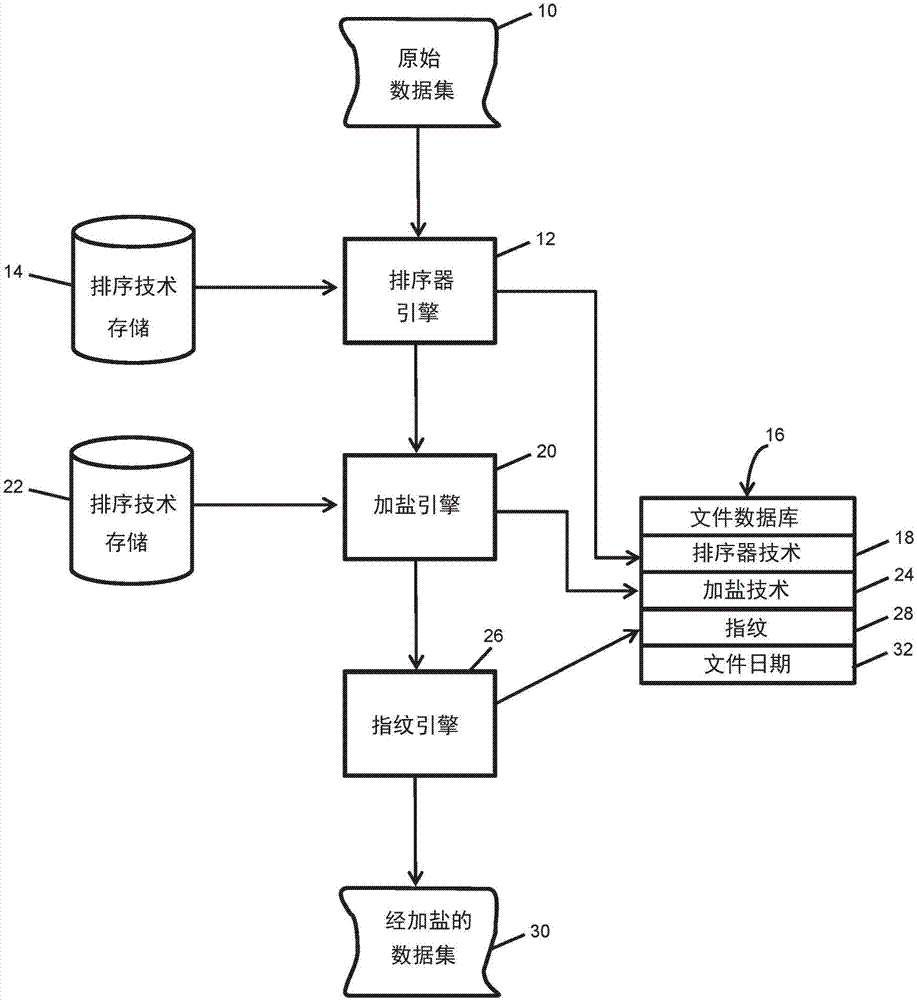
:数据泄漏可被定义为除所有者或授权用户以外的某个人对数据的偷用。估计每年全球数据泄漏的财务影响达数亿美元,并因此代表了数据服务行业中一个非常重要的问题。试图防止数据泄漏的解决方案已经存在一段时间了。这些解决方案防止数据泄漏到组织的防火墙之外,或在数据离开防火墙并在开放网络上“走钢丝”般移动时对其进行加密。还存在一旦图形、视频、音频、或文档(即文本或pdf)数据实际以明文暴露在防火墙外则声明该数据的所有权的解决方案;各组织使用这些众所周知的“数字水印”解决方案以保护其数据免遭滥用。(术语“水印”借用于印刷媒体,其中水印由印刷文档上的印记图像或图案组成以验证真实性,而数字水印是出于相同目的嵌入数字文件中的一种标记。)水印允许数据所有者追讨无授权使用的赔偿,因为他们可在法庭上将水印用作所有权和版权侵权的证据。与此同时,这种法律救济措施的存在阻碍了个人或团体希望获得并随后免费使用此受版权保护的材料。遗憾的是,无论在使用时以明文还是密文传输,文本和数据库文件的数据泄漏仍然是未解决的问题。消费者数据的所有者(“数据所有者”)经常将其数据给予、租赁、或贩售给被受信仅以合法方式、遵守合同要求或数据处理规定(诸如金融服务中的b条例或地方、州或联邦政府制定的隐私法)使用该数据的个人或组织(“受信任的第三方”或“ttp”)。此数据通常作为一系列数据库表(例如.sql格式)、文本文件(例如.csv、.txt、.xls、.doc和.rtp格式)、或作为实时数据馈送(例如,xml或json)传送。尽管如此,经常发生数据所有者的数据泄漏(被泄漏的文件在本文被定义为“被泄漏的子集”)到那些没有正当许可甚至非法地故意或无意使用该数据的其他人(“不良行为者”)的手中。这可能因为以下原因而发生,例如,ttp故意发布数据并且其本身就是不良行为者;ttp的员工故意或意外地发布数据;或数据所有者本身的员工故意或无意地泄露数据。数据库、文本文件或实时数据馈送(例如,xml或json)的水印提出了独特的挑战。图像、视频或音频文件密集且高度结构化。在这些文件中嵌入少量数据作为水印而不降级文件的信息内容或用户体验是容易的,因为这些类型的文件是抗噪声的。抗噪声文件是一种可在不降级结果数据的情况下添加少量噪声(诸如水印)的文件;例如,可通过改变少量数据比特或改变相邻帧的顺序将水印添加到视频文件中,而观看者不会注意到该变化。以此同时,这种类型数据的高度结构化特性使得不良行为者很难移除水印。相比之下,数据库、文本文件或实时数据馈送(例如,xml或json)相对轻质,并因此不能容忍噪声的引入。例如,更改姓名或地址中的单个字符都可能会导致该记录中的数据无效。这种类型的数据的结构可能容易地以使得水印易碎、易于检测、并因此容易使试图确定数据被不当使用的那方无法识别的方式(例如,重排序、追加行、删除行)被操纵。例如,数据表内的各元素可被更改;数据可与来自其他数据源的数据合并;并且数据可被划分为子集和/或以其他方式重排和操纵以避免检测。因此,对于想要声明数据库或文本文件(或其json或xml等价物)的所有权和/或检测对泄漏数据负责的机构的数据所有者而言存在重大障碍。数据所有者也不能通过法律行动容易地追讨收入损失,因为其缺少符合适用证据标准的不法行为的证据。此外,当前用于检测数据泄漏的方法主要通过手动操作,且因此是耗时、劳动密集、昂贵、且容易出错的。因此,对这些类型的文件加水印或“加盐”的经改进的系统和方法将是非常有益的。技术实现要素:本发明涉及一种用于对数据库表、文本文件、数据馈送(例如,xml或json)等类似数据进行加盐(或应用水印)的方法。在本发明的某些实现中,首先根据数据集中的一个或多个字段来重新排序(resort)数据集。加盐配方(recipe)(其可从一组可用的加盐配方中选择)被应用于经排序的数据。数据的指纹然后在排序和加盐之后被捕捉。数据然后在被发送到ttp之前被恢复到其原始顺序。因为数据所有者为每个文件保留,并且在一些实现中为文件的每个版本保留关于排序技术、加盐技术和指纹的信息,所以数据所有者可从经加盐的文件重建未经加盐的文件。此外,被泄漏的子集中包含的数据,即使被改变,也可被数据所有者标识为已经被给予特定接收方和接收方接收到的特定文件。从获取自第三方的野生文件中标识特定的被泄漏的子集和不良行为者的过程被称为罪责分配(guiltassignment)。罪责分配允许数据所有者基于数据的加盐建立强有力的证据案例,通过该证据案例可起诉不良行为者。加盐很难被不良行为者检测到,并因此不良行为者很难或不可能移除加盐,即使不良行为者知道数据已经或可能已经被加盐。加盐因此降低了潜在的不良行为者一开始就真正不当使用其获得的数据的可能性,因为潜在的不良行为者知道此类不当使用会被检测到并导致法律行动。本发明的这些和其他特征、目标及优点将通过结合如以下描述的附图考虑以下对优先实施例和所附权利要求书的详细描述而变得更好理解。附图说明图1例示了根据本发明的实施例的将盐添加到新文件或数据馈送的处理。图2例示了根据本发明的实施例的分析未知来源的文件或数据馈送是否存在盐的处理。图3例示了根据本发明的实施例的加盐系统的基础设施和架构。具体实施方式在本发明被更详细描述之前,应理解,本发明不限于所描述的特定实施例和实现,并且在描述特定实施例和实现时使用的术语仅用于描述那些特定实施例和实现的目的,而不旨在进行限制,因为本发明的范围将仅通过权利要求书来限制。为了开始讨论本发明的某些实现,相关联的技术陈述的精确定义如下。设d是数据库,包括但不限于公司c所拥有的平面文件或数据馈送。d由关系形式的元组或结构化文本(例如,.csv、xml、json或sql数据)组成。设si是来自d的元组的子集。设m是生成w的独特的方法,w是d或比d小得多的si的表示。目标然后为生成w使得:1.w包含针对给定m的“水印”(即,m不能针对两个不同的d或si生成相同的w)。2.使用统计置信度,w可确定代理人a1相较于其他代理人a2、a3、……an而言是分配或改变d或s1的不良行为者,代理人a2、a3、……an接收d的副本或与s1部分重叠的不同的si。3.w将足够牢靠以满足证据标准,以便证明d’(d的第二副本或子集)是在未经c同意的情况下创建的。这意味着假阴性(在d’合法时将其标识为是非法的)或假阳性(在d’非法时将其标识为是合法的)的概率必须小。4.在为特定ai生成d或si时,w必须不会导致丢失来自d或si的信息。5.如果m将w嵌在d中,则恢复w是不可行的。也就是说,当且仅当d’和d,或者分别取自d和d’的精确复制s和s’相等时,才可在不知道d的情况下从d’获得w。6.创建w的过程必须足够牢靠,以在不会生成假阴性的情况下处理d和d’之间的元组的显著差异(例如,额外的空格、数据重新排序、元组删除、元组相加)。7.m必须考虑到来自c的di被定期更新成dj,并允许将di与dj进行区分的能力。8.m必须是利用容易获得的计算设备在计算上可行的。9.当d或si变为d’或si’时,m无需精确地标识对d或si所作出的变化,尽管对d’或si’的详细检查可以而且应该为作为ai的不良行为者状态的指示的w提供支持证据。通过实现满足这些要求的本文所描述的加盐方法,数据所有者可更频繁地将野生文件中的数据标识为源自他们自己的数据集,并甚至标识数据最初被发送给了哪个ttp。这是通过分析野生文件中的某些数据元素以确定标识符(“盐”)是否可被发现来完成的,该标识符是接收方所独有的并被巧妙地嵌入在野生文件中的一些数量的数据所源自的被泄漏的数据集中。在没有预先知道加盐机制的情况下就无法检测到该盐,因为对于未经训练的眼睛而言它是不可见的。如上文所描述的系统的工作和输出可通过图1来例示,其示出了根据系统的某些实现对文件进行加盐的方法。假设,在第一示例中,原始数据集10包含以下元素,如表1所示(实际数据集可能要大得多,但出于示例的目的,示出了非常小的数据集):#列a列b列c列d列e列f列g列h1晴朗d很大6970周一红tx橘子2下雨g大2211周二黄tx苹果3多云h中等209周三绿tx葡萄4刮风e小2301周四蓝tx柠檬5无风m很小708周五白tx青柠表1文件标识符与文件相关联,以便将其与数据所有者创建的其他文件进行区分。在各种实现中,文件标识符可以是任何字母数字和/或其他字符的字符串。在第一步骤中,信息在排序器引擎12处被排序。排序技术可以是任何所需的排序方法。可从存储在与排序器引擎12通信的排序技术存储14处的多种可能的排序技术中选择排序技术。排序技术然后被键入文件并与针对排序器技术存储18处的该文件的文件标识符一起被存储在文件数据库16中。在某些实施例中,特定排序算法到任何给定数据集的分配可以是随机的。排序算法可以是多级排序,即,按一个字段排序作为主要排序,并然后按第二字段排序作为辅助排序,以此类推至所需的多个级。给出的用于例示的示例中,数据首先按列h排序,然后按列e排序,然后按列d排序。表2提供了将此特定排序应用于表1的数据的结果:#列a列b列c列d列e列f列g列h2下雨g大2211周二黄tx苹果3多云h中等209周三绿tx葡萄4刮风e小2301周四蓝tx柠檬5无风m很小708周五白tx青柠1晴朗d很大6970周一红tx橘子表2在第二步骤中,加盐配方被加盐引擎20应用于经排序的数据。加盐配方至少部分地基于文件中记录的顺序,并因此先前的排序步骤被捆绑到加盐步骤的结果。特定配方可从被存储在加盐技术存储22处的任何数量的潜在配方中选择,并且与排序技术类似,在某些实施例中可被随机选择。加盐配方也被键入文件,该文件在加盐技术24处被存储在文件数据库16中。在此特定示例中,加盐技术是对于以数字“2”开始的列d的每第二和第三实例,将列c中的单词缩写。将此加盐配方应用于表2的经排序的数据,结果在下表3中被示出:#列a列b列c列d列e列f列g列h2下雨gl2211周二黄tx苹果3多云hm209周三绿tx葡萄4刮风es2301周四蓝tx柠檬5无风m很小708周五白tx青柠1晴朗d很大6970周一红tx橘子表3在第三步骤中,经加盐的数据集的“指纹”被指纹引擎26捕捉。请注意,指纹可以是数据中的任何单个列或一组两个或更多个列。如果多于一个列被使用,则各列不必相邻。指纹不一定限于包含包括经加盐的数据的列,也不一定需要捕捉文件的整个深度(即,列中的每个数据项)。指纹识别配方,如排序技术和加盐配方,也在指纹技术28处被键入文件数据库16的文件。在被捕捉的指纹是来自上文示例的列c的情况下,指纹将在下表4中被示出:指纹lms很小很大表4因为特定的排序技术,加盐配方和指纹识别配方被各自键入文件,所以数据提供者可然后应用反向过程(即,在应用排序器引擎12之前将文件恢复到其原始顺序)以创建经完成的经加盐的文件来作为可被分发给ttp的经加盐的数据集30。经完成的数据文件中的结果是经加盐的数据文件,其中该加盐被伪装成来自其他方。此特定示例的结果在下表5中被示出:#列a列b列c列d列e列f列g列h1晴朗d很大6970周一红tx橘子2下雨gl2211周二黄tx苹果3多云hm209周三绿tx葡萄4刮风es2301周四蓝tx柠檬5无风m很小708周五白tx青柠表5在某些实施例中,发送给其他客户或稍后发送给同一客户的相同的数据集的后续发行,将会经历各种排序技术、加盐配方和指纹识别配方的不同组合。每个此类实例在主数据库或各数据库中被维护作为单独的文件数据库16。任选地,文件日期32也可被包括在一些或全部文件数据库16中,作为经加盐的文件的特定实例的附加标识信息。现在参考图2,可根据某些实现描述当“在野生”发现可疑文件作为野生文件数据集32时被应用以确定提供者是否真的是文件的来源,并在是的情况下确定该文件何时被创建的过程。使用一种可能的排序技术,再次使用排序器引擎12对文件进行排序,并然后使用加盐引擎20和指纹引擎26对文件进行检查以检测盐(即,文件“dna”)和指纹签名。如果未检测到盐和/或指纹,则使用下一种可能的排序技术执行排序,并以迭代方式重复该过程。针对每种排序技术,参考每种加盐技术和指纹中的一者或两者重复该过程。该过程继续直到在匹配引擎34处检测到盐和/或指纹,或者所有可能性都已穷尽。在前一种情况下,接着可以知道提供者是数据的来源,并且创建盐被检测到36的输出。但在后一种情况下,可以知道提供者不是数据的来源,导致输出盐未被检测到38。即使文件已经以某种方式被改变,如上文所解释的,很明显,对于大文件而言,此方法仍然将会产生数据被盗的可能性,因为恢复经加盐的数据的“碎屑”是可能的。可在匹配引擎34处基于在数据中找到的此类碎屑的数量来确定得分,从而导出滥用提供者的数据的置信度因子。在任何情况下,文件数据库16中的信息(包括文件标识符),可被用于标识野生文件从其中被部分或全部地导出的特定数据文件。除了本文描述的特定实例之外的各种加盐方法可被用于各替换实施例中。在用于消费者或涉及邮寄地址的某些实现中,加盐方法可能符合编码准确性支持系统(cass)标准。cass使美国邮政服务(usps)能够评估纠正和匹配街道地址的系统的准确性。cass认证被提供给希望usps评估其地址匹配系统的质量,并改进其邮递区号+4、载波路由和五位数字编码的准确性的所有的邮寄者、服务机构和供应商。符合cass的系统将纠正和标准化地址,并还将会添加缺失的地址信息(诸如邮递区号、城市和州)以确保地址是完整的。此外,经cass认证的系统还执行递送点验证以验证地址是否为可递送地址。现在参考图3,现在可描述用于实现上述处理的计算机网络系统的物理结构。网络50(诸如因特网)被用于访问系统。虚拟专用网络(vpn)52可被用于提供进入到“dmz”区域中的安全连接,即,在进入系统防火墙之前,对外部文件或数据馈送进行检疫隔离的区域。使用安全文件传输协议(sftp)系统,文件可被传输到sftp外部负载平衡器54;ftp是一种众所周知的网络协议,用于在计算机网络上在客户端和服务器之间传输计算机文件。此外,数据馈送被用于通过私有协议或标准协议(http,https等)借助于api或使用自定义或标准端口不断地将数据流传输到系统中。ui/app外部负载平衡器56可被用于接收由计算机应用发送的文件,并且ap外部负载平衡器58可被用于接收根据应用编程接口(api)发送的文件或数据馈送,这是开发允许在应用软件之间的通信的子程序定义、协议和工具的众所周知的概念。系统的负载平衡器可确保系统中的各个服务器不会因文件或数据馈送请求而过载。现在移动到系统的前端层,与其自己的sftp服务器可恢复存储62相关联的sftp服务器60在通过ftp发送的文件从dmz区域传到之后接收该文件。同样地,ui/app内部负载平衡器64在文件离开dmz区域之后从ui/app外部负载平衡器56接收文件,并将它们传递给一个或多个ui/app虚拟机(vm)66(图3中示出了两个ui/app虚拟机)。移动到服务区域,这些子系统将数据传递给api内部负载平衡器70,该api内部负载平衡器将信息传递给一个或多个apivm72(同样,图3中例示了两个apivm)。在系统后端,来自apivm72的数据将数据传递到处理集群和数据存储82,该处理集群和数据存储82被配置为将数据存储在一个或多个多租户数据存储84中,每个多租户数据存储84都与一个数据存储可恢复存储区域86相关联(图3中例示了其中三组)。存储在多租户数据存储84中的数据的示例包括文件数据库16、排序技术存储14、和加盐技术存储22。可以看出,所描述的本发明的实现产生了用于确定给定数据文件或馈送的接收方而不会使该接收方意识到或破坏数据的可用性的独特方法。此外,该系统是可扩展的,能够在流通的一组潜在的数百万的野生文件中标识文件或数据馈送及其接收方的独特性,同时还为系统摄取的数据提供安全性。为了实用,商业级水印系统必须能够每天处理数百个文件,这意味着整个处理基础设施必须是可延伸的和可扩展的。在这个大数据时代,要处理的数据文件或馈送的大小范围很大,大小从几兆字节到几太字节不等,这些文件或馈送流入系统的方式可能非常难以预测。为了构建可扩展的系统,必须建立预测模型以估计在任何给定时间的最大处理要求,以确保系统大小被调整成能够处理该难以预测性。根据本文描述的实现的加盐系统具有对数据文件、数据库表和无限大小的数据馈送进行加盐的能力。然而,处理速度也很重要,因为客户不能等待数天或数周以在文件被递送之前进行加水印。他们可能每天(并可能甚至更快)都会发布对其基础数据的更新。系统必须能够在生成下一文件的周期内对文件加水印,否则系统将出现瓶颈且文件将落入队列中,这将导致整个业务模型崩溃。在基线(baseline)发布中检测水印的处理时间是几秒钟。计算功率在大多数情况下被降低,因为不需要解析整个文件并然后将野生文件与主数据库相匹配以确定野生文件是否被盗用,除非在最坏的情形下。此外,搜索空间被进一步减少,从而改进了处理时间,因为与特定接收方相关的被检测到的水印仅需要与存储在数据库中的接收方的文件相匹配。但是,请注意,可能需要解析整个野生文件以确保它没有用被发送给多个接收方的数据所水印。无论如何,不需要人类交互和检查作为使用此系统的盐检测的一部分。因此,实现了进一步的时间和成本节省并且减少了错误。几乎全部关于数据水印的研究都是基于针对一个或两个数据所有者和一个或两个不良行为者进行测试的算法。在恢复具有完全未知来源的文件的情况下,商业级系统必须能够为众多客户和未知数量的不良行为者生成、存储和检索水印。例如,考虑商业水印公司具有5000个需要为其提供水印文件的客户。在此示例中,水印公司对来自第三方的文件进行检索,该第三方想要验证该文件不包含被盗数据。为了确定这一点,水印公司必须对照每个公司的水印测试该文件,直到其找到匹配为止。在最坏的情况下,其在测试5000次之后仍没有找到匹配,在这种情况下,可作出的独特声明是该数据并非被盗自该系统中5000个所有者中的任何一个。根据某些实施例,该系统对客户的数量没有限制,并且该系统能够支持在水印中表示的无限数量的接收方。本文描述的系统和方法是一种牢靠的机制,该机制仅需要很少的时间来证明数据所有权,而非需要解析并处理数百万条记录。在大数据提供者的示例中,典型文件包含数亿条记录。由于通过这种机制施加的盐是不可见的,因此在缺乏任何在被任何企业认为是实用和可用的时限内可将信号从噪声中提取出来的先进的信号处理机制的情况下,手动的盐标识是不切实际和不可能的。除非以其他方式说明,否则本文中所使用的所有技术和科学术语具有如本发明所属的本领域的普通技术人员共同理解的相同含义。虽然类似于或等同于本文所描述的方法或材料的任何方法和材料可在实践或测试本发明时使用,本文中描述了有限数目的示例性的方法和/或材料。本领域的那些技术人员将领会,更多的修改是可能的,而不背离本文中的发明概念。本文中使用的所有术语应当以与上下文一致的尽可能最宽的方式来解释。当本文中使用编组时,该组中的所有个体成员以及该组中所有可能的组合和子组合均旨在被个体地包括。当在此说明范围时,该范围旨在包括该范围内的所有子区域和单个点。本文中引用的所有参考都被通过援引纳入在此到不存在与本说明书的公开不一致的程度。本发明已参考某些优选和替换实施例来描述,这些实施例旨在仅为示例性的而非旨在限制如所附权利要求书中阐述的本发明的整个范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1