用于数据管理的系统和方法与流程
本申请主张2016年12月9日提交的PCT申请第PCT/CN2016/109258号、2016年12月9日提交PCT申请第PCT/CN2016/109257号、以及2017年9月1日提交的PCT申请第PCT/CN2017/100201号的优先权和权益,其全部内容通过引用而合并于此。
背景技术:
诸如卷积神经网络(CNN)之类的深度计算框架已经用于许多应用领域,包括模式识别、信号处理、时间序列分析等。CNN需要大量计算,其涉及在训练期间和在行业中部署训练好的网络时的通常大量的参数。CNN被部署在与现实世界交互的移动和嵌入式系统中。然而,需要如此大量计算和数据的CNN的效率可能受到功率(例如,电池)、存储器访问带宽、以及通信成本的限制。
通用处理器可以是可编程的以执行复杂的计算。然而,这样的处理器可能消耗更多的功率且以较低的速度执行操作。图形计算单元(GPU)可以被配置为比通用处理器运行得更快;然而可能需要更高的功耗。具有一种能够满足减少延迟和低功耗要求的方法和系统将是有益的。
技术实现要素:
提供了一种用于数据管理的系统和方法,以便减少存储器访问时间并提高计算效率。与CNN相关联的计算和存储器访问模式通常有助于优化的芯片设计。因此,该系统和方法可以包括在单个芯片上实现CNN的应用。数据管理可以包括将诸如神经网络参数和输入特征图之类的多个数据项相对于多个区域和多个切片排列在存储器中,并减少主存储器与具有RAM和能够执行并行操作的计算单元这样的芯片之间的流量。根据本申请的一个方面,提供了一种用于数据管理的系统。实践中,该方法包括:将多个数据项存储在存储器内的连续空间中;执行包含共同标识所述连续空间的地址和大小的指令以将所述多个数据项从主存储器传输到芯片上的随机存取存储器,并且所述芯片含有包括多个乘法器的计算单元;以及指示所述芯片上的所述计算单元执行如下:从所述RAM中提取所述多个数据项中的数个数据项;以及使用所述多个乘法器对所述数个数据项执行多个并行操作以产生输出数据。
在一些实施例中,该方法还包括:在将所述多个数据项存储到所述连续空间中之前确定所述主存储器中的地址和大小。在一些实施例中,所述方法还包括:发出指令,该指令允许计算单元获得关于所述多个数据项如何排列在所述连续空间中的信息。在一些情况下,所述方法还包括:接收有关神经网络的信息,其中,多个组对应于所述神经网络的多个层,所述多个数据项包括所述神经网络的参数,并且其中,所述多个并行操作对应于与所述多个层中的一个层相关联的乘法。在一些情况下,针对所述多个层中的一个层,关于所述神经网络的信息包括:过滤器的数量、通道的数量和过滤器大小的组合。在一些情况下,所述方法还可以包括:针对所述一个层,根据所述通道的数量确定切片的数量,且所述连续空间被划分为多个区域,每个区域是连续的;以及将多个区域中的一个区域内的部位划分为至少所述数量的切片,每个切片是连续的,且所述存储包括对被分到多个组中的一个组的数据项跨所述切片数量进行排列,使得存储在离所述数量的切片的各起始点有相同的偏移处的所有数据项都用于并行操作。在一些情况下,所述方法还可以包括:针对所述一个层,根据所述过滤器大小确定切片的数量,且所述连续空间被划分为多个区域,每个区域是连续的;以及将所述多个区域中的一个区域内的部位划分为至少所述数量的切片,每个切片是连续的,且所述存储包括对所述数据项跨所述切片数量进行排列,使得存储在离所述数量的切片的各起始点有相同的偏移处的所有数据项都用于并行操作。
在一些实施例中,用于存储数据的主存储器中的所述连续空间被划分为多个区域,每个区域是连续的,并且所述存储还包括将被分到所述多个组中的数个的数据项排列在相同区域中以减少连续空间中的未使用空间。在一些情况下,所述方法还包括:将所述多个区域中的一个区域内的部位划分为多个切片,每个切片是连续的,该部位被分配给分到所述一个组的所述数据项,所述存储还包括跨所述多个切片对被分到所述一个组的所述数据项进行排列,并且,所述指示包括:使用存储在离所述多个切片的各起始点有相同的偏移处的数个数据项来执行所述多个并行操作中的数个。在一些实施例中,具有与所述主存储器中的连续空间基本相同大小的所述RAM中的第二连续空间以与所述连续空间基本相同的方式被划分成多个区域和多个切片,并且,所述多个数据项以与所述连续空间中基本相同的方式排列在所述第二连续空间中;还包括:发出指令,该指令允许所述计算为所述多个组中的一个组获得关于分到所述一个组的数据项被存储其中的所述第二连续空间中的部位的起始点的信息、以及所述部位中多个切片中的每个切片的起始点的信息。
在本申请的另一方面,提供了一种用于排列数据以加速深度计算的系统。所述系统包括:一个或多个处理器;以及一个或多个存储器,其上存储有指令,当该指令被所述一个或多个处理器执行时使得一个或多个处理器执行:将多个数据项存储在主存储器内的连续空间中;发出指令以将所述多个数据项从所述主存储器传输到芯片上的随机存取存储器(RAM),其中,所述指令包含共同标识所述连续空间的地址和大小,并且其中,所述芯片含有包括多个乘法器的计算单元;以及指示所述芯片上的所述计算单元执行如下:从所述RAM中提取所述多个数据项中的数个数据项;和使用所述多个乘法器对所述数个数据项执行多个并行操作以产生输出数据。
另一方面,提供了一种数据管理方法。所述方法包括:利用一个或多个处理器,接收关于多个对象的数据,每个对象包含一组三维数组;将主存储器中的空间分配给所述多个对象,其中,所述空间包括多个区域;将所述多个区域中的一个区域内的部位指派给所述多个对象中的一个对象;基于所述一个对象中包含的所述组的大小和所述三维数组的尺寸,确定用于所述一个对象的切片的数量;针对所述一个对象将所述部位划分为至少所述切片的数量;以及将包含在所述一个对象中的所述三维数组中的数据项跨所述切片的数量进行存储,使得至少一个数据项存储在所述切片数量中的每个切片中。在一些实施例中,所述方法还包括:在将所述数值存储到所述部位中之前,确定所述空间的起始地址和大小。
在一些实施例中,所述方法还包括:发出指令以将所述主存储器中的所述空间的内容传输到芯片上的随机存取存储器(RAM)中的第二空间,其中,所述指令包括所述空间的起始地址和大小,并且其中,所述芯片含有包括多个乘法器的计算单元。在一些情况下,所述RAM中的所述第二空间具有与所述主存储器中的所述空间基本相同的大小,并且以与所述主存储器中的所述空间基本相同的方式划分为多个区域和多个切片,并且所述传输包括以与所述主存储器中的所述空间基本相同的方式排列在所述第二空间中的内容。在一些情况下,所述方法还包括:发出指令以:从离所述RAM中的多个预定地址的相同偏移处提取若干数据项;以及使用所述多个乘法器对所述若干数据项执行多个并行操作以产生输出数据。在一些情况下,所述多个预定地址是多个所述切片的起始。在一些情况下,所述多个对象对应于神经网络的多个层,并且每个三维数组对应于一过滤器。在一些情况下,所述方法还包括:将所述一个区域内的第二部位指派给所述多个对象中的第二对象。
在一个独立但相关的方面,提供了一种其上存储有指令的非瞬态计算机可读存储介质。当该指令被计算系统执行时使得所述计算系统执行排列数据的方法以加速深度计算,所述方法包括:利用一个或多个处理器,接收关于多个对象的数据,每个对象包含一组三维数组;将主存储器中的空间分配给所述多个对象,其中,所述空间包括多个区域;将所述多个区域中的一个区域内的部位指派给所述多个对象中的一个对象;基于所述一个对象中包含的所述组的大小和所述三维数组的尺寸,确定用于所述一个对象的切片的数量;针对所述一个对象将所述部位划分为至少所述切片的数量;以及将包含在所述一个对象中的所述三维数组中的数据项跨所述切片的数量进行存储,使得至少一个数据项存储在所述切片数量中的每个切片中。
在另一方面,提供了一种芯片上的集成电路。所述芯片上的集成电路包括:随机存取存储器(RAM),其被配置为在连续空间中存储数据项集合;计算单元,其包括被配置为响应于一个或多个指令执行并行操作的多个乘法器;以及多个多路复用器,其中,所述多个多路复用器的子集与所述多个乘法器(的输入引脚)连接,其中,多路复用器的所述子集被编程为使用离多个预定地址的一偏移来将所述数据项集合的子集传输到用于并行操作的所述多个乘法器。在一些情况下,所述方法中使用的所述芯片包括计算单元,其包括多个乘法器。
在一些实施例中,执行数轮并行操作以形成迭代过程,并且,当前轮中的并行操作产生在下一轮迭代过程中待处理的一组值。在一些实施例中,包含在芯片中的多路复用器的所述子集被配置为基于所述一个或多个指令中的一个指令接收第一组控制信号,并且其中,所述第一组控制信号确定用于将所述数据项子集传输到所述多个乘法器的多个预定路由中的一个。
在一些实施例中,所述计算单元还包括与所述多个乘法器连接的多个加法器。在一些情况下,所述计算单元还包括与所述多个加法器连接的第二多个加法器。在一些情况下,所述多个加法器是累加器。在一些情况下,所述计算单元还包括所述多个多路复用器的第二子集,其与所述多个加法器连接,并且其中,多路复用器的所述第二子集被配置为基于所述一个或多个指令中的一个指令接收第二组控制信号,并且其中,控制信号的第二子集确定用于在所述多个加法器中的一个或多个加法器中使能累加的多个预定选项中的一个。在一些情况下,所述多个多路复用器的第二子集被编程为接收由所述多个加法器产生的数据项并将它们传输到RAM,多路复用器的所述第二子集被配置为基于所述一个或多个指令中的一个指令接收第二组控制信号,并且,所述第二组控制信号确定用于将由所述多个加法器产生的数据项传输到RAM中的离第二多个预定地址的第二偏移的第二多个预定路由中的一个。在一些实施例中,所述计算单元还包括与所述多个加法器连接的多个修正器(rectifier)。在一些情况下,所述多个多路复用器的第二子集与所述多个修正器连接,多路复用器的所述第二子集被配置为基于所述一个或多个指令中的一个指令接收第二组控制信号,并且所述第二组控制信号确定用于使能所述多个修正器中的一个或多个的多个预定选项中的一个。在一些情况下,当所述第二组控制信号具有预定值时,所述多个修正器中的至少一个修正器总是被禁用或定期被禁用。在一些情况下,所述多个多路复用器的第二子集被编程为接收由所述多个修正器产生的数据项并将它们传输到RAM,并且多路复用器的所述第二子集被配置为基于所述一个或多个指令中的一个指令接收第二组控制信号,并且所述第二组控制信号还确定用于将由所述修正器产生的数据项传输到RAM中的离第二多个预定地址的第二偏移的第二多个预定路由中的一个。在一些情况下,所述RAM包括多个区域,并且所述第一组控制信号选择其中存储所述数据项子集的所述多个区域中的一个区域。在一些情况下,所述一个区域包括多个连续的、大小相等的切片,并且所述多个预定地址对应于所述多个切片的起始。在一些情况下,多路复用器的所述子集被配置为基于所述一个或多个指令中的一个指令接收第一组控制信号,并且所述第一组控制信号确定当前轮中的所述偏移的值。在一些情况下,所述当前轮中的所述偏移的值在下一轮中以固定量递增。
在一些实施例中,所述芯片还包括:功能单元,其用于扩展或收缩在所述当前一轮中产生的所述一组值。在一些实施例中,由所述芯片处理的该组数据项的子集对应于输入特征图的多个像素,并且其中,在芯片上的当前一轮中执行的并行操作对应于将卷积神经网络的一层中的所有通道的所有过滤器的一个参数应用于所述输入特征图的所述多个像素所需的所有乘法。在一些实施例中,所述多个乘法器的大小是2的幂,例如,128。在一些实施例中,还包括指令解码器,其用于解码所述一个或多个指令并产生控制信号。
应当理解,本申请的不同方面可以单独地、共同地、或彼此组合地加以理解。本文描述的本申请的各个方面可应用于下文所述的任何特定应用。
通过下面的详细描述,其中仅通过用于实施本申请的最佳实施例的说明而示出和描述了本申请的示例性实施例,本申请的其它方面和优点对于本领域技术人员来说将变得显而易见。如将认识到的,本申请能够具有其它和不同的实施例,且在不背离本公开的前提下,可以对其一些细节在多个显而易见的方面进行修改。因此,附图和说明书本质上应视为说明性的,而不是限制性的。
附图说明
本申请在所附权利要求中具体阐述了本申请的新颖特征。通过参考以下运用本申请原理的说明性实施例的详细描述,将获得对本申请的特征和优点的更好理解,附图中:
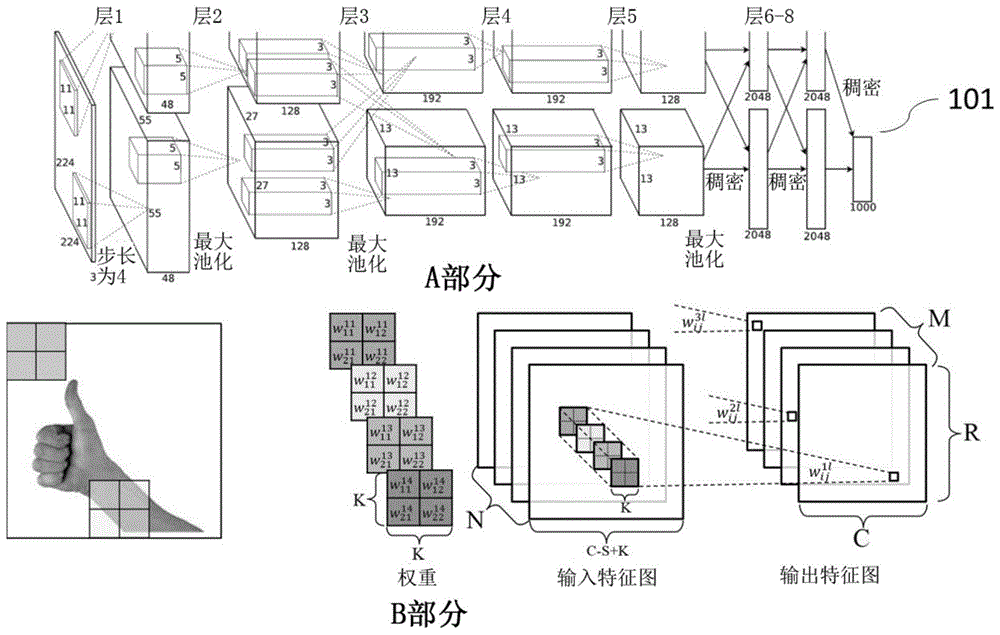
图1示出包括一个或多个卷积层、一个或多个池化层以及各种其它操作的典型CNN系统。
图2示出本文公开的用于应用CNN的系统的示例性架构。
图3示出系统的主存储器中的示例性数据组织。
图4示出根据本申请实施例的由系统的处理器执行的对用于卷积计算的CNN参数和输入特征进行设置的示例性方法的流程图。
图5示出系统的主存储器或芯片上的随机存取存储器(RAM)中的CNN参数的示例性排列。
图6示出存储到连续区域内的切片中的核参数的示例性排列。
图7示出存储到连续区域内的切片中的输入特征的示例性排列。
图8示出填充切片以容纳不同核大小和通道数量的示例。
图9示出根据本申请实施例的用于卷积计算的芯片的示例。
图10示出多路复用器有助于在芯片上的卷积计算中实现不同的存储器存取模式。
图11至图13示出可以适用于不同卷积层的示例性配置。
图14示出计算单元的示例性配置。
图15示出可以被配置为实现本申请中公开的任何计算系统的计算机系统。
具体实施方式
虽然本文已经示出和描述了本申请的优选实施例,但是对于本领域技术人员显而易见的是,这些实施例仅以示例的方式提供。在不脱离本申请的情况下,本领域技术人员将会想到许多变化、改变和替换。应该理解的是,本文所述的本申请实施例的各种替代方案可用于实施本申请。
提供了一种用于数据管理的系统和方法以便减少存储器存取时间并提高计算效率。本文描述的本申请的各个方面可应用于下文所述的任何特定应用。该方法和系统可以应用于卷积神经网络和其他深度学习应用。该方法和系统可以用于模型训练或应用。应当理解,本申请的不同方面可以单独地、共同地、或彼此组合地加以理解。
本文提供的系统和方法可以具有与现有技术相比更低的成本和功耗以及更高性能的优点。至少可以通过能够执行并行操作的计算单元来实现改进的计算性能。可以并行处理数据以进行高效计算。并行操作可以对应于卷积神经网络层中的数据处理,并以流水线方式馈送到下一层。可以使用少量指令来实现并行操作。这可以有利于节省存储器存储和提高计算效率。此外,该方法和系统在主存储器和实现并行操作的芯片之间提供高效的数据传输。可以通过稠密参数和输入数据打包来实现高效的数据传输。该数据排列还可以简化指令并减少存储器存取。并行操作可以包括CNN层中的操作,并且可以通过数据管理提供各层间的平滑数据流水线或无缝数据流。可以根据芯片上的多个计算电路内的一个或多个数据流配置来排列和存储数据。重新排列的数据可以提高计算性能并且允许计算电路的高效利用,从而可以实现芯片的简单性和紧凑性。
卷积神经网络(CNN)系统通常由不同类型的层组成:卷积、池化(pooling)、放大(upscaling)和全连接的神经元网络。在一些情况下,诸如修正线性单元(rectified linear unit)的激活函数可以用在一些层中。在CNN系统中,对于每种类型的操作可以有一个或多个层。CNN系统的输入数据可以是待分析的数据。图像数据可以是图像数据、音频、视频数据和各种其他数据。图像数据可以是图像数据、音频、视频数据和各种其他数据。图1示出了典型的CNN系统101(Krizhevsky,A.,Sutskever,I.,&Hinton,G.E.(2012),“利用深度卷积神经网络的Imagenet分类”,神经信息处理系统大会,1097-1105页),其包括一个或多个卷积层、一个或多个池化层以及各种其他操作。如图1的A部分所示,CNN系统可包括任意数量的层以及用于不同类型的操作的任意数量的层。卷积神经网络的最简单的架构以一输入层(例如,图像)开始,接着是一序列的卷积层和池化层,并以全连接层结束。在一些情况下,卷积层之后是一ReLU激活函数层。也可以使用其它激活函数,例如饱和双曲正切(saturating hyperbolic tangent)、恒等(identity)、二元步骤(binary step)、逻辑(logistic)、arcTan、softsign、参数化修正线性单元、指数线性单元、softPlus、弯曲恒等(bent identity)、softExponential、Sinusoid、Sinc、高斯、sigmoid函数等等。卷积、池化和ReLU层可以充当可学习特征抽取器,全连接层可以作为机器学习分类器。
在某些情况下,卷积层和全连接层可以包括参数或权重。这些参数或权重可以在训练阶段学习。可以用梯度下降来训练参数,使得CNN计算的分类分值与用于每个图像的训练集中的标签一致。参数可以从反向传播神经网络训练过程中获得,使用与生产或应用过程相同的硬件可执行或可不执行所述反向传播神经网络训练过程。
卷积层可包括一个或多个过滤器。当过滤器在输入数据中看到相同的特定结构时,这些过滤器可以激活。在一些情况下,输入数据可以是一幅或多幅图像,且在所述卷积层中,可以将一个或多个过滤器操作应用于所述图像的像素。卷积层可包括在图像空间上滑动的一组可学习过滤器,计算过滤器的条目(entry)与输入图像之间的点积。过滤器操作可以实施为一个核在整个图像上的卷积,如图1的B部分所示。在本申请中,过滤器和核可互换指代。核可包括一个或多个参数。过滤器操作的结果可跨各通道求和,以提供从卷积层到下一池化层的输出。卷积层可以执行高维卷积。这些过滤器应当延伸到输入图像的全深度。例如,如果我们想要将大小为5x5的过滤器应用于大小为32x32的彩色图像,则过滤器应具有深度3(5x5x3)以覆盖图像的所有三个颜色通道(红色,绿色,蓝色)。
在一些情况下,卷积层可以是深度上的可分离卷积。在这种情况下,可以将卷积层分解成深度上卷积和1x1逐点卷积以合并所述深度上卷积的输出。卷积层可以被拆分为用于过滤的层(即,深度上卷积层)和用于合并的层(即,逐点卷积层)。在一些情况下,在深度上卷积层中,可以将单个过滤器应用于每个输入通道,并且在逐点卷积层中,可以执行1x1卷积以组合所述深度上层的输出。在一些情况下,所述深度上卷积层和所述逐点卷积层均后随一个激活层。在一些情况下,当基于深度上可分离卷积建立CNN时,第一层仍然可以是全卷积。
提供给卷积层的输入数据可为一维、二维、三维、四维、五维、六维、七维和更多维。在一些实施例中,提供给诸如卷积层的输入层的输入数据可取决于数据特性。例如,如果输入数据是图像数据,则输入数据可以是三维的。如图1所示,输入数据可以是具有224x224x3的体积大小的图像,其表示三个通道的每个通道为224x224的像素平面。由一个层生成的输出特征图可被用作后续层的输入特征图。用于隐藏层的输入特征图(例如,输入数据)的大小可由包括前面层中的过滤器的数目和一个或多个超参数的若干因素来确定。卷积层在输入特征图上应用过滤器以抽取内嵌的视觉特征并生成输出特征图。在一些实施例中,参数的尺寸可以是四维的且输入/输出特征图可以是三维的。例如,每个特征图可以是三维的,其包括具有跨越多个通道的二维平面,且三维特征图通过卷积层中的一组三维过滤器对三维特征图进行处理。在一些情况下,可以具有相加到卷积结果的一维偏置项。例如,给定输入特征图平面的形状在跨C个通道上具有HxH的尺寸(即,宽度和高度),且N个滤波器的每个具有C个通道,过滤器平面尺寸为R x R(即,宽度和高度),卷积层的计算可被定义为:
0≤z<N,0≤u<M,0≤x,y<E,E=(H-R+U)/U
其中O、I、W和B分别表示输出特征图、输入特征图、过滤器和偏置项的矩阵。U表示步长大小。
每个卷积层可包括用于卷积操作的多个参数。在每个卷积层中可以包括一个或多个过滤器。每个过滤器可以包括一个或多个参数或权重。过滤器/核的大小以及过滤器/核的数量可共同确定每个卷积层所需的参数。例如,卷积层可包括四个核,每个核对于三个通道是2x2平面,由此得到的该层的权重的总数为4x2x2x3。在一些实施例中,参数还可以包括偏置项。
卷积层的输出体积的大小还可以取决于超参数。超参数还可控制卷积层的输出体积的大小。在一些情况下,超参数可以包括深度、步长和零填充。
输出体积的深度控制了连接到输入体积的相同区域的层中神经元的数量。所有这些神经元将学习针对输入中的不同特征而激活。例如,如果第一卷积层以原始图像为输入,则沿着深度维度的不同神经元可以在存在各种定向边缘或颜色斑点的情况下激活。
步长控制了如何分配围绕空间维度(宽度和高度)的深度列。当步长为1时,神经元的新的深度列将以只有一个空间单元间隔的方式分配给各空间位置。这导致在列之间的严重重叠的感受野,且还导致大的输出体积。相反,如果使用更高的步长,则感受野将较小重叠,且所得到的输出体积将在空间上具有较小的尺寸。
有时在输入体积的边界上以零填充输入是方便的。该零填充的大小是另一个超参数。零填充提供了对输出体积空间大小的控制。特别地,有时希望精确地保持输入体积的空间大小。
输出体积的空间大小可以作为输入体积大小W、卷积层神经元的核字段大小K、它们应用的步长S和零填充的量P的函数来计算。用于计算多少个神经元适于给定体积的公式由(W-K+2P)/S+1给出。如果上述公式给出的值不是整数,则步长设置不正确,且神经元不能以对称的方式平铺以在输入体积上适配。大体上,在步长为S=1时设置零填充为P=(K-1)/2可确保输入体积和输出体积在空间上具有相同的大小。在一些情况下,不需要用到前一层的所有神经元。
图1的B部分示出了卷积层的计算。卷积层接收N个特征图作为输入。每个输入特征图由具有K x K的核的移位窗口进行卷积以在一个输出特征图中生成一个像素。所述移位窗口的步长为S,其通常小于K。总共M个输出特征图将形成用于下一个卷积层的输入特征图的集合。
图1的A部分显示了CNN应用。该CNN由八层组成。前五层为卷积层,第6-8层构成全连接的人工神经网络。该算法接收来自原始256x256三通道RGB图像的三个224x224输入图像。输出向量的1000个元素表示1000种类别的可能性。如图1所示,层1接收三个224x224分辨率的输入特征图,和96个55x55分辨率的输出特征图。层1的输出被划分为两组,每个大小为48个特征图。层1的核大小为11x11,且滑动窗口以步长为四个像素在特征图上移位。后面的各层也具有类似的结构。其他层的卷积窗口的滑动步长为一个像素。
可以通过控制前一层中使用的过滤器的数量来控制特征图的数量。输入层中的特征图的数量可对应于通道(例如,R,G,B)的数量。过滤器可以包括一个或多个参数或权重。卷积层可包括多个滤波器。在一些情况下,过滤器的数量和滤波器的大小(即,参数的数量)可以选择为充分利用计算单元或根据硬件的计算能力进行选择。在一些情况下,可以选择过滤器的数量和各过滤器的大小以使得针对可变的输入数据可使用高效的硬件配置。
在一些实施例中,卷积层和/或全连接层可后随激活层,诸如修正线性单元(ReLU)。ReLU层可逐个元素应用激活函数,诸如阈值为0的max(0,x)。这可以使输入数据的体积保持不变。也可以使用其它激活函数,例如,饱和双曲正切、恒等、二元步骤、逻辑、arcTan、softsign、参数修正线性单元、指数线性单元、softiPlus、弯曲恒等、softExponential、Sinusoid、Sinc、高斯、sigmoid函数等等。在一些情况下,当CNN包括深度上可分离卷积时,深度上可分离卷积和逐点卷积层中的每一层可后随一个ReLU层。
在如图1的A部分所示的示例中,CNN系统可以包括数个卷积层和池化或子采样层。池化层可以是非线性下采样的形式。池化层可以执行下采样以将给定的特征图减少到缩减特征图的堆栈。所述池化层可以逐渐减少输入数据的空间大小以减少网络中的参数量和计算量,由此还控制过拟合。存在几种函数实现池化,诸如最大池化、平均池化、L2-范数池化。例如,在最大池化操作中,给定的特征图可以被划分为一组非重叠的矩形,对于每个这样的子区域,输出最大值。在另一示例中,在平均池化中,可以输出子区域的平均值。给定的特征图可以以任意尺寸进行划分。例如,可以使用大小为2x2的过滤器在每个深度切片上应用步长为2而进行池化。具有步长为2的大小为2x2的池化层将给定特征图缩减到其原始大小的1/4。
可以将池化层的输出馈送到全连接层以执行图案(pattern)检测。在一些情况下,过滤器可应用到输入特征图上,全连接层可以用于分类的目的。过滤器可以具有与输入特征图相同的大小。全连接层可以在其输入中应用一组权重或参数,并将结果累加作为全连接层的输出。在一些情况下,激活层可以紧接着全连接层之后并输出CNN系统的结果。例如,为了分类目的,输出数据可以是一个保持分类分值的向量。
计算架构可以是预先训练的卷积神经网络。CNN模型可以包括一个或多个卷积层。CNN模型可以包括一个至几百个卷积层。CNN模型可以包括一个或多个池化层。在一些情况下,池化层可以紧接在卷积层之后。在一些实施例中,ReLU激活操作与卷积操作相结合,使得卷积结果立即由激活函数来处理。在一些实施例中,在数据被送到全连接层之前,卷积和池化层可以多次应用于输入数据。全连接层可以输出最终输出值,对其测试以确定是否已经识别出图案。
提供了一种通过特定设计的集成电路借由改进的处理并行度和存储器访问来加速实现选择算法的系统。所述选择算法,诸如CNN应用,可包括大量的矩阵-矩阵乘法和/或矩阵-向量乘法。所述集成电路可包含存储器单元和计算单元,所述计算单元能够基于减少数量的控制信号来执行并行操作的多次迭代。在一些情况下,数据布置为零和/或以零填充,以使得数据的排列符合预定的硬件配置。该数据可以被设置为基于硬件电路的配置而与预定的数据流或数据路径一致。
在CNN系统中,涉及的数据包括CNN参数和输入/输出特征。如上描述的典型CNN系统可包括多通道卷积层、最大或平均池化层、修正线性单元(ReLU)、和全连接层。全连接和多通道卷积层都包含大量的数字权重或表示神经元之间的连接强度的参数。待加载到芯片上的集成电路的数据可由主处理器准备并存储在主存储器中,所述数据可以以批量的方式传输至芯片。
CNN的参数可包括用于卷积层的多个参数,包括但不限于权重或参数、偏置项、超参数,超参数例如为上文所述的填充、步长和深度。CNN参数还可以包括使用在诸如全连接层等其它类型的层中的参数。
这些参数可以被排列和分类为多个组。在一些实施例中,参数可以按层来分组。例如,CNN系统的不同层可对应于不同的参数组。每个层的参数可以是大维矩阵。一组参数可以存储在连续的空间中。包含在组中或对应于层的参数可以连续地存储在连续空间中。组中的参数可以根据在CNN的层中执行的功能或操作而部置。关于数据排列的细节将在后面描述。
输入数据可包括图像数据或采样语音信号。例如,图像数据可包括多个图像像素值。数据可以是各种数据类型,例如标量整数、标量浮点、压缩整数、压缩浮点、向量整数、向量浮点等。
图2示出本文公开的用于应用CNN的系统的示例性架构。该系统可以包括实现CNN系统的应用的集成电路210。该系统还可以包括主处理器201和用于排列和存储待由集成电路210处理的数据的主存储器203。集成电路可以包括:计算单元207,用于执行乘法、加法和其他相关操作;板上存储器单元209,用于存储诸如要提供给计算单元的参数、偏置项和输入数据之类的数据项集合;以及通信单元211,用于处理集成电路与主处理器201、各种其他功能电路之间的数据传输。在一些实施例中,集成电路210可以包括:随机存取存储器(RAM),其被配置为在连续空间中存储数据项集合;计算单元,其包括配置为执行由指令触发的并行操作的多个乘法器;以及与多个乘法器连接的一个或多个多路复用器,其中一个或多个多路复用器被编程为通过使用离多个预定地址的一偏移来产生待传输到多个乘法器以用于并行操作的数据项集合的子集。
该系统可用于数据管理和处理。待处理的数据可以由设备205捕获并传输到处理器201。例如,输入数据可以是由图像传感器205捕获的图像数据。由处理器接收的输入数据可以被排列和组织为与芯片210的硬件配置相一致。然后,所排列的输入数据可以存储在主存储器203中的连续空间中。包含用于CNN处理的多个核参数、偏置项和各种其他数据的一个或多个CNN模型可以存储在主存储器中。响应于由处理器210发出的数据传输指令,CNN模型数据和输入数据可以由批量存取模块211传输到芯片。CNN模型数据和输入数据可以使用或可以不使用相同的通信链路传输。CNN模型数据和输入数据可以传输到或可以不传输到相同的片上存储器。在某些情况下,CNN模型数据可以从主存储器传输到片上RAM209,而输入数据可以传输到芯片上的输入数据缓冲器。通常,输入数据和CNN模型数据都被传输并存储到片上RAM的连续区域中。数据可以在RAM和主存储器之间具有相同的存储布局。附加指令也传输到主存储器。指令可以由指令解码器213解码成控制信号,并用于控制芯片的计算单元207内以及计算单元和片上RAM之间的数据流和数据路径。可以从RAM提取输入数据、参数和偏置项并根据预定的数据路由或数据路径将其提供给芯片的计算单元。一个或多个多路复用器215可用于根据从指令解码的控制信号来控制数据路由或数据路径。可以将一层操作的输出结果馈回到计算单元,作为下一层操作的输入特征图。然后,可以通过批量存取模块将CNN系统的最终输出结果传输回主存储器。
集成电路210可以是任何合适的计算平台、微处理器或逻辑设备。集成电路可以集成到任何其他设备,诸如手持设备、平板电脑、笔记本电脑、片上系统设备、手机、互联网协议设备、数码相机、个人数字助理、以及诸如微控制器之类的嵌入式应用、数字信号处理器、片上系统、网络计算机、机顶盒、网络集线器、智能家电,或者可以执行本文别处描述的功能和操作的任何其他系统。
存储器单元209可以是板上集成电路。存储器单元可以是任何合适的RAM,包括静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、同步动态随机存取存储器(SDRAM)、双倍数据速率(DDR)、双倍数据速率同步动态随机存取存储器(DDRSDRAM)、DDR、DDR2、DDR3、T-RAM、Z-RAM等等。
计算单元207可以包括多个计算组件以执行CNN的不同层。在一些实施例中,多个计算组件可以适应CNN的不同层的要求。例如,多个计算组件可用于执行卷积层中的卷积运算、池化层的平均或最大运算、和/或全连接层中的点积运算。在一些情况下,可以通过多个计算电路之间的互连来控制计算单元的配置。
计算单元207可包括计算电路的阵列。计算电路可以包括算术逻辑单元(ALU)。ALU可以位于阵列中,阵列通过可以取决于数据流要求的网络而连接。在一些情况下,计算单元可以是诸如FPGA的细粒度空间架构的形式。也可以使用诸如专用集成电路(ASIC)之类的其他架构。在一些情况下,计算电路可包括多个乘法器。在一些情况下,计算电路可包括多个乘法器-累加器单元(MAC)。计算单元可以包括ALU数据路径,该数据路径能够执行乘法,接着执行加法/累加。在一些情况下,先进先出(FIFO)可用于控制进出计算单元的流量。计算单元可包括多个乘法器和累加器。例如,计算单元可以包括32,64,128,256,512和更多的乘法器。每个乘法器可以包括用于接收输入信号的值的第一输入和用于接收权重或核参数的第二输入。乘法器可以是执行整数或定点输入的乘法运算的硬件组件。乘法器可以是例如8位或16位定点乘法器。
累加器可以包括一个或多个加法器,用于将来自乘法器的输出的乘积求和。加法器可以是多输入加法器。例如,加法器可以是2-输入加法器、4-输入加法器、8-输入加法器。在一些情况下,加法器和乘法器的输入可以由一个或多个多路复用器选择性地控制。
一个或多个多路复用器215可以与多个乘法器和/或加法器连接。一个或多个多路复用器可以接收一组控制信号,以确定用于传输数据到多个乘法器的预定的多个路由中的一个。可以从用于多路复用器的各种命令中解码控制信号,命令包括来自图像缓冲器或来自RAM中前一层的输出的用于计算的输入源选择、RAM中的参数、偏置项、输入特征的选择等等。多路复用器还可以与一个或多个修正器连接,用于控制并入到卷积层中的修正器的使能。例如,多路复用器可以接收从激活函数使能指令中解码得出的控制信号以控制修正器。在一些情况下,还可以包括一个或多个多路复用器以用于将一层的计算结果输出到存储器。多路复用器可以采用一个数据输入和多个选择输入,并且它们具有若干个输出。它们根据选择输入的值将数据输入转发到其中一个输出。
每个多路复用器可以包括用于n个输入和对1个选择的输入进行输出的多个输入选择器引脚。多路复用器可以是n输入1输出(n-to-1)的任何大小,其中n可以是2,4,8,16,32等。在一些情况下,可以使用少量的大型多路复用器。在一些情况下,可以使用大量的小型多路复用器。在一些情况下,多路复用器可以链接在一起以构建大型多路复用器。
在一些实施例中,相同的计算单元可用于执行卷积、平均、最大值、或点积运算而无需改变组件配置和互连。在一些实施例中,不同的计算电路可以用于不同类型的层。例如,不同组的计算电路可以对应于卷积层、池化层和放大层。
集成电路还可以包括用于芯片上的各种内部通信以及外部存储器和芯片之间的通信的其他组件。组件可以包括用于输入或中间数据的有效重用的缓冲器。缓冲器的大小可以在任何范围内,诸如从100kB到500kB。
如上所述,输入到多路复用器的控制信号可以由一个或多个指令解码器213解码。指令解码器可以解码指令,并且生成一个或多个微操作、微代码入口点、微指令、用于多路复用器的控制信号、其他指令或其他控制信号的输出,其从原始指令中解码,或以其他方式反映原始指令,或者从原始指令导出。可以使用各种合适的机制来实现解码器。例如,可以使用查找表、硬件实现、可编程逻辑阵列(PLA)、微代码只读存储器(ROM)等来实现解码器。解码器可以耦合到一个或多个多路复用器并且通过FIFO连接到存储指令的主存储器。在一些情况下,解码器可以被配置为对存储在一个或多个指令寄存器中的指令进行解码。
集成电路还可以包括一个或多个寄存器。寄存器可以保存指令、存储地址、中断号或任何类型的数据(例如,比特序列或单个字符)。寄存器可以有不同的大小,例如,一个寄存器的长度可以是64位用于存放长指令,或者半寄存器用于存放较短指令。关于寄存器的细节将在后面讨论。
集成电路可以包括各种其他计算机架构以辅助与外部处理器或存储器的通信。通信模块可以包括用于指令和数据传输的合适的器件。可以采用各种器件进行通信,例如外围组件互连卡、包括但不限于PCI express,PCI-X,超传输(HyperTransport)的计算机总线等。集成电路通过数据总线(例如,AXI4lite总线)从主存储器203接收命令和参数,并通过FIFO接口与主存储器批量存取模块211通信。该主存储器批量存取模块可以通过数据总线对外部存储器进行存取。在一些情况下,可以在集成电路和外部处理器之间启用中断机制以提供准确的时间测量。在一些情况下,数据加载例程可以用直接存储器存取方法实现,以实现对主存储器的高带宽存取。要从主存储器加载到片上RAM的数据可以包括CNN模型中包含的各种数据,诸如核参数、偏置项等。数据可以预先排列并存储在存储器上的连续空间中。在一些情况下,可以在用于传输数据的指令中指定连续空间的地址和大小。数据可以直接加载到芯片上的RAM中。在一些情况下,利用直接存储器存取方法可以将数据直接写入片上RAM。
该系统可以包括集成电路外部的主处理器201。处理器可以被配置为在将数据加载到集成电路之前预处理或排列参数和/或输入数据。处理器可以将参数和/或输入数据排列成组。在一些情况下,这些组可以对应于CNN系统中的层。
处理器可以是诸如中央处理单元(CPU)、图形处理单元(GPU)、或通用处理单元之类的硬件处理器。处理器可以是任何合适的集成电路,例如计算平台或微处理器、逻辑设备等。尽管本公开对处理器进行了描述,但是其他类型的集成电路和逻辑器件也是适用的。数据排列和数据操作可适用于能够执行数据操作的任何处理器或机器。处理器或机器可以不受数据操作能力的限制。处理器或机器可以执行512位、256位、128位、64位、32位或16位数据操作。
在一些实施例中,处理器可以是计算机系统的处理单元。稍后将参考本文图15描述关于计算机系统的细节。
在一些情况下,处理器201可以耦合到用于接收输入数据的另一个设备或数据源。输入数据将由CNN系统进行分析。输入数据可以是图像、文本、音频等。输入数据可以从其他设备或系统获得。例如,输入数据可以是由成像设备205捕获的图像数据。由成像设备生成的图像数据可包括一个或多个图像,其可以是静态图像(例如,照片)、动态图像(例如,视频)或其合适的组合。图像数据可以是多色的(例如,RGB、CMYK、HSV)或单色的(例如、灰度、黑白、深色)。图像数据可以具有取决于图像帧分辨率的各种大小。图像帧分辨率可以由帧中的像素数量来定义。在示例中,图像分辨率可以大于或等于大约128x128像素、32x32像素、64x64像素、88x72像素、352x420像素、480x320像素、720x480像素、1280x720像素、1440x1080像素、1920x1080像素、2048x1080像素、3840x2160像素、4096x2160像素、7680x4320像素、或15360x8640像素。
在一些实施例中,处理器可以被配置为预处理输入数据和/或粗略地分析输入数据。在某些情况下,处理器可以重新处理输入数据以便节省存储空间。在一些情况下,处理器可以运行图像数据的粗略分析以获得初步信息,从而确定要用于CNN操作的参数。例如,当输入数据是图像时,图像可以例如被调整大小以与期望的数据大小相匹配。在一些情况下,图像可以被划分成段,然后在处理后合并回原始图像。在一些情况下,可以使用任何合适的缩小尺寸技术对图像进行缩小尺寸。在一些情况下,可以对图像进行分割。可以根据从图像中抽取的目标来分割图像。可以根据关注对象或目标图案对图像进行预分类。例如,可以检查图像以抽取诸如包含在图像中的汽车之类的特定目标。因此,处理器可以选择对应于车辆类型的CNN模型以进行进一步的CNN分析。各种图案识别或图案匹配技术可以用于诸如监督或无监督机器学习技术之类的预分类过程。
图3示出系统的主存储器300中的示例性数据组织。主存储器可以由处理器使用或耦接到处理器。主存储器可以是任何合适的存储器,包括静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、同步动态随机存取存储器(SDRAM)、双倍数据速率(DDR)、双倍数据速率同步动态随机存取存储器(DDRSDRAM)、DDR、DDR2、DDR3、T-RAM、Z-RAM等等。
主存储器可以存储各种指令、用于处理的数据,包括输入数据和要加载到CNN系统的参数。在一些情况下,主存储器还可以接收CNN系统的输出结果和/或在CNN操作期间生成的中间结果。该数据可以包括要使用CNN系统分析的输入数据。输入数据可以是图像、文本、音频等。输入数据可以从其他设备或系统获得。例如,输入数据可以是由成像器件捕获的图像数据。由成像器件生成的图像数据可包括一个或多个图像,其可以是静态图像(例如,照片)、动态图像(例如,视频)或其合适的组合。
图像可以在存储到输入缓冲器301中之前进行预处理。可以例如调整图像的大小以匹配期望的数据大小。在一些情况下,图像可以被划分成段,然后在处理后合并回原始图像。在一些情况下,可以使用任何合适的缩小尺寸技术对图像进行缩小尺寸。在一些情况下,可以对图像进行分区。可以根据从图像中抽取的目标来分割图像。可以根据关注对象或目标图案对图像进行预分类。例如,可以检查图像以抽取诸如包含在图像中的汽车之类的特定目标。因此,可以选择对应于车辆类型的CNN模型以进行进一步的CNN分析。各种图案识别或图案匹配技术可以用于诸如监督或无监督机器学习技术之类的预分类过程。在一些实施例中,主存储器包括空间索引302,其用于保存关于CNN模型的信息和主存储器的总体布局。在一些情况下,空间索引302的大小小于2MB。
如上所述,一旦识别出目标分类,就可以选择相应的CNN模型。一个或多个CNN模型可以存储在主存储器的静态空间305中。在一些实施例中,每个模型的网络参数和相应指令需要大约2MB,并且大约32MB被分配给静态空间305。在某些情况下,每个模型可能与数据项的一个类别或一个分类相关联。例如,与人相关联的模型可以包含要在CNN操作中使用的参数以对不同人的类型(例如,男性、女性、儿童、或成人)进行分类,而与车辆相关联的模型可以包含用于CNN系统的参数以对不同的车辆类型进行分类。可以预训练一个或多个模型。每个模型可以包括用于CNN系统的不同层的多个参数。如下文所述,可以以某种方式排列和分组多个参数,以减少主存储器和集成电路之间的流量。
如上所述,CNN模型中包括的数据可以从主存储器加载到片上RAM320。数据可以包括CNN模型中包含的各种数据,例如核参数、偏置项等。可以预先排列数据并将其存储在存储器内的连续空间中。在一些情况下,可以在用于传输数据的指令中指定连续空间的地址和大小。数据可以直接加载到芯片上的RAM中。在一些情况下,可以使用直接存储器存取方法将数据直接写入片上RAM。
在一些实施例中,在需要将数据从集成电路的SRAM传输或溢出到主存储器的情况下,主存储器还可以包括动态空间303。在一些情况下,为了存放临时数据和一些输出数据,动态空间303的大小约为6MB。溢出数据可以是在CNN操作期间生成的中间结果。CNN系统的最终输出也可以从集成电路传输到主存储器并存储在动态空间303中。在一些情况下,只有分类分值可以传输到主存储器。在一些情况下,每层的输出结果可以传输到主存储器。
主存储器可以包括用于存储指令307的空间。各种指令集可以通过集成电路的FIFO从主存储器加载到一个或多个缓冲器。这些指令可以对应于CNN系统中的不同级别操作。例如,指令可以包括与诸如层的类型(例如,卷积、池化、放大等)之类CNN的层相对应的高阶指令、与不同类型的操作(包括但不限于卷积、逐元素卷积、放大、返回、或矩阵/矩阵或向量/矩阵数据层级的池化)相对应的低阶指令、以及诸如主存储器和芯片上的SRAM之间的读/写、将数据从缓冲器提取到在芯片上的计算单元之类的各种数据传输指令。
指令可以具有各种类型,包括但不限于:计算、逻辑、控制和数据传输指令。不同指令的有效位数可能不同。指令长度可以固定也可以不固定。在一些情况下,为了存储器对齐和加载/存储/解码逻辑的设计简化,指令长度可以是固定的(例如,64位)。
指令可以包括矩阵指令,例如矩阵-矩阵乘法指令。指令可以指定输入特征图矩阵和参数矩阵的地址和大小。指令可用于调用卷积操作。指令可以包括矩阵-矩阵乘法和逐元素激活指令。该指令可用于指示卷积和ReLU激活。指令可以指定输入特征图矩阵、参数矩阵、和偏置项向量的地址和大小。指令可以包括用于池化操作的逻辑指令(例如,MAX比较功能单元)。例如,指令可以比较由卷积层生成的输出元素以在池化窗口中查找最大值。
如前所述,在卷积层中,如式中所示的卷积运算可以以高并行度运行。然而,大量的中间数据,即并行乘法器-累加器单元可以同时生成卷积结果的部分和,这将需要额外的存储并消耗额外的存储器读/写能量。幸运的是,由于卷积层中的权重共享属性,输入数据可以跨许多操作进行共享。例如,每个过滤器或核的参数可以在相同的输入特征图平面中重复使用若干次,并且每个输入特征图像素可以跨若干过滤器重复使用。因此,提供了一种用于排列输入数据和参数以减少中间结果的数量并增加共享参数或输入数据的重复使用的方法,进而减少计算单元和RAM之间的数据传输带宽,并且提高吞吐量和能量效率。数据管理可以允许在显著减少的存储器存取时间的同时执行的一个或多个计算层,并且在一些情况下,可以仅输出整个层的输出特征图并将其存储在存储器中。
图4示出根据本申请实施例的由系统的处理器执行的对用于卷积计算的CNN参数和输入特征进行设置的示例性方法400的流程图。方法400可以由处理逻辑执行,该处理逻辑可以包括硬件(例如,电路、专用逻辑、可编程逻辑、或微代码)、软件(例如,在处理装置、通用计算机系统、或专用机器上运行的指令)、固件、或其组合。在一些实施例中,方法400可以由处理器201相对于图2执行。
为了进行说明,方法400被描绘为一系列动作或操作。然而,根据本公开的动作可以以各种顺序和/或同时发生,并且也可以与本文未呈现和描述的其他动作以各种顺序和/或同时发生。另外,并非需要执行方法中描述的所有动作来实现该方法。本领域技术人员将理解和认识到,方法400可替代地通过状态图或事件表示为一系列相互关联的状态。
参考图4,集成电路或芯片可以耦接到主存储器,该主存储器包含由主处理器预先排列的数据和参数。芯片可以包括处理逻辑,该处理逻辑可以被配置为执行与CNN系统相关联的卷积运算、平均或最大池化操作、ReLU激活、或点积运算中的任何一个。在步骤401中,主处理器可以在耦接到处理器的存储器内存储一个或多个CNN模型。每个CNN模型可以包括核参数、偏置项、或超参数、以及用于CNN操作的其他数据(例如,层类型)。在一些情况下,CNN模型可以被预训练并存储在芯片外部的主存储器中。在一些情况下,CNN模型可以是要被训练的初始模型,该模型可以包括要被训练的参数和数据的初始值。主处理器可以排列与每个CNN模型相关联的参数,使得CNN模型的所有参数可以紧凑地存储在存储器内的连续空间中。在一些情况下,参数可以被分类成多个组,每个组与CNN中的卷积层相关联。层/组内的参数可以连续地排列和存储在连续空间中。用于存储在同一层内参数的连续空间可以通过地址和大小来标识。在一些情况下,地址可以是连续空间的起始地址。在一些情况下,地址可以是基于连续空间的起始地址的偏移。CNN模型可以包括一个或多个卷积层,从而包括一组或多组参数。用于参数存储的组间/层间顺序可以与用于CNN操作的顺序相同或不同。在一些情况下,与随后的卷积层相关联的参数可以用先前的层之前的地址存储。在一些实施例中,连续空间可以被划分为多个区域,并且每个区域可以是连续的。在一些情况下,每个区域可以被进一步划分成切片。每个切片可以是连续空间。有关数据排列的细节将在后文讨论。
在步骤403,主处理器可以接收输入值。输入值可以是诸如图像或语音信号、文本之类的输入数据,CNN系统将从中分析某些图案。输入数据可以是任何格式并且具有任何数据长度,例如8位、16位、32位或可以适合存储在数据存储器中的任何数量的位数。输入数据可以由主处理器处理以确定哪个CNN模型用于CNN操作。例如,当输入数据是图像数据时,可以使用任何合适的图像处理技术以从图像中抽取图案或目标,并根据抽取的信息(例如,车辆、动物、人类表达、手势等)来选择CNN模型。可以基于各种标准来选择CNN模型。例如,可以根据输入数据中包含的目标的分类或类别、输入数据(例如,音频、图像、文本等)的类型、以及输入数据的各种其他特征来选择CNN模型。在其他情况下,可以基于CNN分析的目标或CNN操作的性能要求(例如,计算速度、能力等)来选择CNN模型。
在步骤405,主处理器可以排列输入数据并将数据存储在主存储器上的空间中。存储在主存储器中的数据可以是原始数据或由主处理器重新排列的处理后的输入数据。例如,处理后的输入数据可以是尺寸缩小的图像数据或分段的图像数据。在一些情况下,可以根据所选的CNN模型来排列输入数据。在一些情况下,可以根据芯片的预定配置来排列输入数据,该预定配置确定CNN数据流或数据传输路由。在一些情况下,输入数据可以被排列和零填充,以符合用于CNN系统中的数据流或数据传输路由的芯片的预定配置。在一些情况下,输入数据可以被排列以存储在存储器内的连续空间中。可以通过地址和空间的大小来标识该连续空间。连续空间可包括多个连续的切片。输入数据的排列可以类似于参数的排列。
在步骤407,输入数据、各种CNN模型参数和相关数据可以从主存储器传输到芯片上的随机存取存储器(RAM)。待传输的数据可以包括排列的输入数据、参数和其他数据,诸如与所选CNN模型相关联的偏置项、指令集。可以将数据加载到片上RAM并以与存储在主存储器中的数据类似的方式存储。例如,仍然可以将参数和输入数据存储在连续的空间中,该空间可以由空间的地址和大小来标识。可以将连续空间划分成一个或多个连续的区域。可以将连续空间或区域划分为一个或多个连续的切片。可以根据连续区域的基地址和切片的大小通过偏移地址来标识切片。在一些情况下,切片的大小可以是根据层中参数的总大小和切片的总数而变化的。切片的总数可以是变量或固定数。在一些情况下,切片的总数和沿切片方向的单元的数量共同定义要由计算单元以批处理方式处理的数据块。在一些情况下,切片的大小可以是预定大小,而切片的总数可以是可变的。切片的大小可以在很宽的范围内变化,诸如从1字节到数千字节。例如,给定在三个通道中具有128×128像素的输入图像和在三个通道中具有16个5×5核的CNN的第一层,系统可以选择具有八个切片来存储输入图像。如此每个切片的大小可以是8192B(2的13次方)以适合输入图像中的所有特征。如下文中进一步讨论的那样,该大小还允许填充以便利用预定芯片布局中的一个。系统还可以选择具有八个用于存储CNN权重的切片,每个切片具有大约150B,以及四个用于存储CNN偏置项的切片。
在一些情况下,RAM中的连续空间可以具有与主存储器中的连续空间相同的大小。RAM中的连续空间可以从主存储器中的连续空间接收数据而无需改变数据的排列。在一些情况下,关于数据排列的信息也可以传输到RAM。这样的信息可以包括连续空间的地址和大小、连续区域的地址和大小、切片编号、切片索引、连续区域内的偏移等。该信息可以包含在指令中或者和从主存储器传输到芯片的数据在一起。
处理器发出指令(包括高阶功能调用)以将所选CNN应用于给定输入特征。如上所述,这些指令最初存储在存储器内的特定区域中。然后,可以经由集成电路的FIFO将与所选CNN相关联的指令集从主存储器传输到一个或多个缓冲器。这些指令可以对应于所选CNN模型中的不同级别操作。例如,指令可以包括与CNN的诸如层的类型(例如,卷积、池化、放大等)之类的层相对应的高阶指令、与不同类型的操作(包括但不限于卷积、逐元素卷积、放大、返回、或矩阵/矩阵或向量/矩阵数据层级的池化)相对应的低阶指令、诸如主存储器和芯片上的SRAM之间的读/写之类的各种外部数据传输指令、以及诸如将数据从缓冲器提取到在芯片上的计算单元之类的内部数据流指令。
可以响应于指令来执行数据传输。该指令可以从处理器发出。例如,数据传输可以由在处理器上运行的软件或应用程序控制。该指令可以至少包括对存储输入数据的连续空间进行共同标识的地址和大小,以及对存储CNN模型的参数的连续空间进行标识的地址和大小。例如,输入数据或参数的大小可以由数据传输指令中的数据宽度操作数来指定。在一些情况下,数据传输指令还可以包括组/层内的切片的偏移和切片的预定大小。该指令可以通过FIFO传输到集成电路并由解码器解码。然后,解码器产生的控制信号可以触发主存储器批量存取模块,以将数据从存储器加载到SRAM。
在步骤409,在完成所有CNN操作后,可以由芯片上的解码器生成中断控制信号,并将其传输到主存储器批量存取模块以触发将输出数据从RAM传输到主存储器。在一些情况下,CNN系统的输出结果可以是分类分值向量。输出结果可以经由耦合到主存储器的计算机系统/处理器存储和/或呈现给用户。分类结果可以以各种方式使用并应用于各种应用。例如,输出结果可以在显示设备上显示给用户或被用于产生控制信号或用于控制另一设备的指令。
如上所述,用于CNN的参数和各种其他数据(例如,偏置项)可以被排列以存储在主存储器和芯片上的RAM中。参数和各种其他数据(例如,偏置项)可以分类为多个组。可以将分组的参数存储在多个区域中,每个区域对应于一个组。可以根据CNN的不同层对CNN的各种数据进行分组。在一些实施例中,多个组可以对应于CNN的多个层。在一些情况下,一个组对应于诸如卷积层、全连接层之类的一个层。在一些情况下,一个组对应于两个或更多个层或不同的操作。例如,一个组可以对应于卷积层和池化层、卷积层和ReLU激活、卷积层和放大层、全连接层和ReLU激活层等等。
图5示出系统的主存储器或芯片上的随机存取存储器(RAM)中的CNN参数的示例性排列。图示的空间501可以是用于存储与CNN模型相关联的数据的连续空间。数据可以是要在CNN系统中使用的参数。数据还可以包括诸如用于CNN系统的偏置项之类的其他数据。CNN可以包括一个或多个卷积层。不同的卷积层可以具有或可以不具有不同数量的核、不同的核大小和不同数量的通道。应当注意的是,图中所示的参数是每层的核参数,但是连续空间也可以存储诸如每层的偏置项之类的其他数据。在一些情况下,所有数据都用作多个乘法器的输入。在一些情况下,一些数据用作多个乘法器的输入,而另一些数据则不。如图所示,这些参数将被并行地提供给多个乘法器。在该示例中,CNN可以包括五个卷积层。层0503可以是输入层。层0可以包括如在507中所示的4维参数。例如,层0中的参数可以具有对应于四个核的4×2×2×8的维度,每个核是跨三个通道的2×2平面。参数可以存储在存储器内的连续区503中。数据点序列KiRjSmCn表示包含在层0中的参数,其中i表示核的索引号(K),j和m表示在平面中的核的行(R)和列(S)中的索引,n表示通道(C)的索引。每个连续区域可以对应于与层相关联的多个参数。连续区域可以具有由层的参数总数确定的可变大小。或者,连续区域可以具有固定的大小,使得连续区域可以对齐。根据不同层的不同参数数量,连续区域可以被完全填充也可以不被完全填充。在一些情况下,连续空间可以被稠密打包以减少未使用的空间。例如,一小区域层5505可以与另一小区域层3共同存储,或者层1和层2被存储在一起,使得整个空间501可以是连续的且紧凑的。不同组的参数与连续区域的长度对齐,从而可以减少未使用的空间。连续空间可以指存储器上的空间,其没有减少的未使用的空间或有减少的未使用的空间。这种类型的数据排列提供了相对于固定区域大小的数据结构对齐并且节省用于数据存储的总存储空间。
可以根据关于CNN的信息来排列与层相关联的一组参数内的参数。关于CNN的信息可以包括例如过滤器/核的数量[K]、通道的数量[C]和过滤器大小[P]的不同组合。在一些实施例中,存储与层相关联的数据的连续区域内的空间可以被划分为若干切片。或者,通常可以基于核大小来确定切片的数量和每个切片的大小。可以使用各种其他方式基于沿不同维度应用卷积运算的顺序将区域划分为切片。切片中的参数的不同排列可以决定计算单元中的不同数据流。在一些实施例中,可以基于通道的数量来确定切片的数量和每个切片的大小。在一些情况下,可以基于通道维度中的大小和核的数量两者来确定切片的数量。如上所述,参数是高维的(诸如4维),包括核的数量、通道、平面大小。平面大小(即,核大小)可以取决于难以控制的输入数据中要分析的对象。设计具有固定带宽(即,切片数量)的数据块可能是有利的,该固定带宽与诸如通道数量和核数量之类的相对易于控制的维度相关联,同时独立于核大小。或者,当易于控制的维度是核大小时,也可以基于核大小确定切片的数量。在一些情况下,对于与K个核、C个通道、和每个核中的P个参数相对应的卷积层中的参数,可以通过K*(C/NR)来确定切片的数量,其中NR是数据块中的行数。在一些情况下,行数由处理器基于C、K、或M确定。可以基于提供给用于并行的卷积运算的多个乘法器的数据块的大小来确定切片的数量。在一些情况下,可以根据硬件配置来确定数据块的大小。例如,当数据块是4行数据块并且计算电路可占用128个输入值并且每个输入提供给4个乘法器时,切片的数量是128/4/4=8。以这种方式,对于每个时钟周期,在相同偏移处的所有切片中排列的数据将被同时读入到计算电路。图6示出存储在连续区域内的分配空间内的切片中的核参数的示例性排列。在一些情况下,切片的大小可以由核的大小确定。核大小/参数数量越大,切片大小越大。如图所示,卷积层可以包括四个核K0-K3,每个核可以包括2×2个参数(即,R0-R1,S0-S1),并且每个核具有八个通道C0-C7。用于存储参数的连续空间可以被划分成八个切片Ps1-8。在所描绘的示例中,指向四行的每一行偏移和每两列/切片可共同包括对应于跨八个通道中的过滤器中的2D平面的点(即,K0R0S0Ci)的参数。对应于点的切片数量可以由通道数量确定。例如,当存在四个通道时,1个切片可足够用于存储关于点的参数。在另一示例中,当存在16个通道时,可以使用四个切片来存储关于点的参数。
在一些实施例中,可以排列切片内的参数,使得存储在离若干切片的各起始点有相同的偏移处的所有数据项用于并行操作。以这种方式,可以通过切片的索引或切片的数量和偏移或行数来识别参数块。可以将参数块提供给多个乘法器以用于并行的卷积运算。参数块可以是包括一个或多个行和一个或多个切片的数据块。在一些情况下,数个行可以为查询提供数据块,并且这种多行数据块可以顺序到达,每次表示一个查询。例如,第一查询可以使得来自参数的前四行和所有八个切片到达多个乘法器,并且第二查询可以使得行5-8到达乘法器以进行处理。可以通过切片索引和偏移来标识每个参数。每个参数可以是任何大小,诸如8位、16位、32位等。在一些情况下,一些字节被组合以包含相同的数据参数。
输入数据或输入特征图可以以类似的方式存储在主存储器或片上RAM中。输入特征图可以存储在连续空间中。连续空间也可以被划分成多个切片。每个切片可以是连续空间。可以基于通道的数量来确定切片的数量。可以基于提供给用于并行卷积运算的多个乘法器的数据块的大小来确定切片的数量。在一些情况下,可以根据硬件配置来确定数据块的大小。例如,当数据块是4行数据块并且计算电路可以占用128个输入值并且每个输入提供给4个乘法器时,切片的数量是128/4/4=8。以这种方式,对于每个时钟周期,在相同偏移处的所有切片中排列的数据将被同时读入到计算电路。
在一些实施例中,用于输入特征的切片的数量取决于计算单元每个周期处理多少数据。通常,切片的数量是C*P/NR,其中NR是切片中的行数。此外,前一层应根据当前层对输入数据的要求在切片中生成输出数据。因此,当下一层具有K4C8P4配置时,当前层的输出可以写入八个切片,当下一个操作具有K1C16P8配置时,当前层的输出可以写入32个切片,并且如下文进一步讨论的那样,当下一个操作使用K8C16P1配置时,当前层的输出可以写入四个片。
图7示出存储在连续区域内的切片中的输入特征的示例性排列。如图所示,输入特征图可以是在跨八个通道C0-C7上的平面维度中的4×4(即,HxW)。用于存储参数的连续空间可以被划分成八个切片Is1-8。在所描绘的示例中,指向四行的每一行偏移和每两列/切片可共同存储对应于跨八个通道中的过滤器中的2D平面的点(即,H0W0Ci)的参数。对应于点的切片数量可以由通道数量确定。例如,当存在四个通道时,1个切片可足够用于存储关于点的参数。在另一示例中,当存在16个通道时,可以使用四个切片来存储关于点的参数。可以根据硬件特性使用任意数量的切片。
在一些实施例中,可以对切片内的输入特征图进行排列,使得存储在离若干个切片的各起始点有相同偏移处的所有数据项用于并行操作。以这种方式,一输入特征图数据块以切片的索引或切片的数量和偏移或行数进行标识。可以将输入特征图数据块提供给多个乘法器以进行并行卷积运算。输入特征图数据块可以是包括一个或多个行和一个或多个切片的数据块。在一些情况下,多行可以为查询提供数据块,并且这些多行数据块可以顺序到达,每次表示一个查询。例如,第一查询可以使得形成输入特征图的前四行和所有八个切片到达多个乘法器,并且第二查询可以使得行5-8到达乘法器以进行处理。可以通过切片索引和偏移来标识每个输入特征图数据。每个数据可以是任何大小,例如8位、16位、32位等。在一些情况下,一些字节被组合以包含相同的数据条目。
在上面示出的示例中,可以同时使用多个乘法器来处理预定数量的行和切片。待并行处理的行和切片的数量可以对应于数据存储的不同配置。在一些情况下,当数据以相同配置排列时,可以使用相同的计算电路和互连配置的组来执行卷积操作。例如,可以针对以下CNN配置优化芯片设计:K4C8P4、K1C16P8、和K8C16P1。在一些情况下,输入数据或参数数据可能没有与预定的数据存储配置对齐,而与通道或过滤器大小有关。在这种情况下,输入数据或参数数据可以用零填充,使得数据排列可以与芯片的预定配置对齐。图8示出填充切片以容纳不同大小和通道数量的核的示例。在上面描述的示例中,存储器存取查询可占用四行和八个数据切片。在输入数据是尺寸为128×128像素和三个通道的图像数据801的情况下,输入数据可以用一行零填充,使得原始尺寸为128×128×3的输入数据被转换为128×64×8,其与四行查询配置对齐。在参数来自K个核、每个核具有跨8个通道803大小为5x5(即,5x5x3)的示例中,可以排列和用零来填充参数,使得参数数据被转换为5x3x8以与4行查询配置对齐。应该注意的是,零可以放置在诸如行的顶部或底部之类的不同位置,或者放在第一列或最后一列,以便将核的大小完成为4的倍数或将通道的数量完成为4的倍数。如在另一个示例805中所示,来自K个核的参数的每个都具有跨三个通道的3×3参数(即,3x3x3)被用零填充,使得参数的排列被转换为3×2×8以与4行8切片查询对齐。
在另一方面,提供了一种片上集成电路,用于执行矩阵-矩阵和/或矩阵-向量乘法运算。图9示出根据本申请实施例的用于卷积计算的芯片的示例。芯片的计算单元可以响应于与CNN模型相关联的指令来执行多个并行操作。计算单元可以包括用于在CNN中执行操作的多个计算电路。计算单元可以包括多个乘法器和累加器,以利用卷积层中涉及的多个核来执行输入值的卷积。相同的计算单元可以用于不同的卷积层。数据路径可以由一个或多个多路复用器控制,以确定要获取并提供给计算单元的输入特征图和核。在一些情况下,ReLU激活操作可以包括在卷积层中。可以使用同一组计算电路来执行具有ReLU激活或不具有ReLU激活的卷积层。在一些情况下,可以执行卷积层和ReLU而不将中间结果存储到存储器。在一些情况下,可以通过指令启用或禁用激活函数。在一些实施例中,同一组计算电路可用于不同类型的层,包括卷积层、池化层、放大、ReLU或全连接层。在一些情况下,通过使用多路复用器不同的操作可以共享同一组计算电路以根据操作控制数据路径或数据流。在一些实施例中,可以针对不同层使用不同组的计算电路。例如,第一组计算电路可用于卷积层或卷积和ReLU,第二组计算电路可用于池化,第三组计算电路可用于全连接层。在一些情况下,可以确定不同组的计算电路来执行响应于指令/控制信号的不同操作。在针对CNN的不同层重复使用相同组的计算电路的情况下,可以重复操作,并且层的输出特征图可以作为计算单元的输入特征图被馈回。在不同组的计算电路被重复使用于CNN的不同层的情况下,来自对应于第一层的第一组计算电路的输出结果可以被接收作为对应于不同层的第二组计算电路的输入。例如,用于池化层的第二组计算电路可以接收来自于用于卷积和ReLU层的第一组计算电路的输出结果以执行池化操作,并且用于全连接层的第三组计算电路可以接收来自卷积或池化层的输出以执行点积或逐元素卷积。来自全连接层的结果可用于检测输入值中的图案。在计算精度或位深度方面,各种计算电路可以是可配置的,也可以不是可配置的。
可以将从每层生成的输出特征图存储在RAM中以用于下一层操作。输出特征图可以以与输入数据相同的方式排列。例如,输出特征图可以存储在划分为连续切片的连续空间中。在一些情况下,可以由一个或多个多路复用器控制将来自每一层的输出数据存储到RAM上的不同切片中。例如,指示切片索引的控制信号可用于选择连接到存储器内的对应切片的多路复用器的输出引脚。在一些情况下,用于存储先前层的输入/输出特征图的空间可以被重复使用以存储后来生成的结果。隐藏层的输出结果在该结果被用作CNN中的一层的输入后,可以存储也可以不存储该隐藏层的输出结果。在一些情况下,针对一个、两个、三个、四个、五个或更多个操作层,隐藏层的输出结果可以被存储,然后可以将用于存储结果的空间释放并将其重新用于以后的输出结果。
集成电路可以是任何合适的计算平台、微处理器或逻辑设备。集成电路可以集成到任何其他设备,例如手持设备、平板电脑、笔记本电脑、片上系统设备、手机、互联网协议设备、数码相机、个人数字助理、以及诸如微控制器之类的嵌入式设备、数字信号处理器、网络计算机、机顶盒、网络集线器、其他智能家电,或者可以执行本文别处描述的功能和操作的任何其他系统。芯片可以是与图2中描述的相同的集成电路210。
存储器单元901可以是板上集成电路。主存储器可用于存储用于CNN分析的数据、参数、和指令。在一些情况下,主存储器也可以接收和存储CNN的输出结果。存储器单元可以是任何合适的RAM,包括静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、同步动态随机存取存储器(SDRAM)、双倍数据速率(DDR)、双倍数据速率同步动态随机存取存储器(DDRSDRAM)、DDR、DDR2、DDR3、T-RAM、Z-RAM等等。
芯片可以包括与RAM进行数据通信的计算单元903。计算单元可以包括多个计算组件以执行CNN的不同层。在一些实施例中,多个计算组件可以适应CNN的不同层的要求。例如,多个计算组件可用于执行卷积层中的卷积运算、池化层的平均或最大运算、和/或全连接层中的点积运算。在一些情况下,可以通过多个计算电路之间的互连来控制计算单元的配置。
计算单元可包括计算电路的阵列。计算电路可以包括算术逻辑单元(ALU)。ALU可以位于阵列中,阵列通过可以取决于数据流要求的网络而连接。在一些情况下,计算单元可以是诸如FPGA的细粒度空间架构的形式。也可以使用诸如专用集成电路(ASIC)之类的其他架构。在一些情况下,计算电路可包括多个乘法器。在一些情况下,计算电路可包括多个乘法器-累加器单元(MAC)。计算单元可以包括ALU数据路径,该数据路径能够执行乘法,接着执行加法/累加。在一些情况下,先进先出(FIFO)可用于控制进出计算单元的流量。计算单元可包括多个乘法器和累加器。例如,计算单元可包括32、64、128、或512个乘法器。
每个乘法器可以包括用于接收输入信号的值的第一输入和用于接收权重或核参数的第二输入。乘法器可以是执行整数或定点输入的乘法运算的硬件组件。乘法器可以是例如8位或16位定点乘法器。累加器可以包括一个或多个加法器,用于将来自乘法器的输出的乘积求和。加法器可以是多个输入加法器。例如,加法器可以是4-输入加法器。
在一些实施例中,相同的计算单元可用于执行卷积、平均、最大值、或点积运算而无需改变组件配置和互连。在一些实施例中,不同的计算电路可以用于不同类型的层。例如,如图所示,计算单元可包括不同的功能单元。不同的功能单元可以包括至少一个卷积单元903-1、一个池化单元903-2、和一个放大单元903-3。在一些情况下,可以使用不同组的计算电路来实现每个功能单元。或者,两个或更多个功能单元共享同一组计算电路。
在一些情况下,修正器可以与卷积层组合,并且来自计算单元的输出结果可以是由激活函数处理的卷积结果。如本文别处所述,可以使用各种激活函数。在一些情况下,可以使用修正线性单元(ReLU)激活函数。ReLU层可以应用逐元素激活函数,例如为阈值为零的max(0,x)。该功能可以由诸如多路复用器之类的各种组件实现。例如,作为激活函数的修正线性单元,其可以使用2输入1输出的多路复用器实现,该多路复用器基于输入的符号位在原始值或零之间进行选择。
在一些情况下,计算单元还能够共同处理卷积层及池化层。池化操作通过从一组相邻输入中抽取最大/平均值来减少输入维度。池化可以是最大池化或平均池化。在最大池化操作中,输入特征图可以被分割为一组非重叠的矩形,并且对于每个这样的子区域输出最大值。在另一示例中,在平均池化中,可以输出子区域的平均值。可以按任何大小分割输入特征图。例如,可以用大小为2×2的过滤器在每个深度切片应用步长为2而应用池化。大小为2x2且步长为2的池化层将输入图像缩小到其原始大小的1/4。可以使用各种逻辑组件来实现池化操作。例如,MAX比较功能单元可以连接到输出卷积结果的累加器或修正器中的每一个,以用于根据池化窗口大小跨多个输出结果抽取最大值。在一些情况下,可以使用临时层来存储最大池化过程的中间结果。在另一示例中,来自卷积计算电路(即,加法器或ReLU)的输出可以是流水线到平均计算电路,而不使用用于中间输出的临时存储。以这种方式,卷积和平均池化层可以被构建为流水线。
在一些情况下,放大层也可以与卷积层一起操作。放大操作可以通过诸如插值的适当方法来增加特征图的分辨率。可以使用诸如加法器、累加器、比较器、内插器或平均器(average)等各种逻辑元件来实现放大操作。
可以使用相同的计算电路组或不同的计算电路组单独地或共同地执行各种操作卷积、池化、放大、ReLU激活。计算单元可以根据本公开提供的排列方式的输入特征图、参数和输出结果来执行各种组合。使用所提供的方法和系统,各种组合的操作可以需要减少的存储器存取或不使用存储器存取来存储中间结果。不同的操作可以以各种方式组合,例如卷积和ReLU的组合,卷积、ReLU和池化的组合,卷积、ReLU和放大的组合等等。
集成电路还可以包括用于芯片上的各种内部通信以及外部存储器和芯片之间的通信的其他组件。组件可以包括用于输入或中间数据的有效重用的缓冲器。在一些实施例中,调整大小缓冲器(ResizeBuffer)大约为24KB。通常,缓冲器的大小可以在任何范围内,诸如从100kB到500kB。
如上所述,输入到多路复用器的控制信号可以由一个或多个指令解码器905解码。指令解码器可以解码指令,并且作为输出,生成一个或多个微操作、微代码入口点、微指令、用于多路复用器的控制信号、其他指令或其他控制信号,其从原始指令中解码,或以其他方式反映原始指令,或者从原始指令导出。例如,CNN功能调用解码器可以将功能调用解码为微指令序列,并且CNN指令解码器可以将微指令序列解码为控制信号。可以使用各种合适的机制来实现解码器。例如,可以使用查找表、硬件实现、可编程逻辑阵列(PLA)、微代码只读存储器(ROM)等来实现解码器。解码器可以耦合到一个或多个多路复用器并且通过FIFO907连接到存储指令的主存储器。在一些情况下,解码器可以被配置为对存储在一个或多个指令寄存器中的指令进行解码。
集成电路还可以包括一个或多个寄存器909。寄存器可以存放指令、存储地址、中断号或任何类型的数据(例如,比特序列或单个字符)。例如,寄存器RO-R3用于CNN功能调用队列维护,其存储功能调用队列的开始、长度、头部和尾部,寄存器R4用于存放DDR主存储器存取的基地址。一些寄存器用于状态指示。例如,当完成CNN操作时,可以设置寄存器以指示CNN结果的状态已准备就绪。例如,寄存器R4和R5可用于存储指示CNN过程结束的中断号。R4和R5中的值可以由指令指定。
一些指令将寄存器指定为指令的一部分。例如,指令可以指定将两个定义的寄存器的内容相加然后放入指定的寄存器中。在另一示例中,可以对指令进行编码并从主存储器中取出。寄存器可以有不同的大小,例如,一个寄存器的长度可以是64位用于存放长指令,或者半寄存器用于存放较短指令。一个或多个寄存器可以包含多个索引寄存器,也称为地址寄存器或改型寄存器。集成电路中任何实体的有效地址包括基地址、索引地址、和相对地址,所有这些地址都可以存储在索引寄存器中。一个或多个寄存器可以包含移位寄存器,通常为级联触发器。一个或多个寄存器可以存储一个或多个不同的数据类型,诸如标量整数、标量浮点、填充整数、填充浮点、向量整数、向量浮点、状态(例如,指令指针,其是待执行的下一条指令的地址)等。
集成电路可以包括各种其他计算机组件,以便于与外部处理器或存储器的通信。通信模块(例如,主存储器批量存取模块901)可以包括用于指令和诸如双倍数据速率之类的数据传输的合适的装置。可以采用各种手段进行通信,例如外围组件互连卡、包括但不限于PCI express,PCI-X,超传输(HyperTransport)的计算机总线等。可以根据带宽的要求和集成电路的兼容性来选择合适的通信手段。例如,一个数据总线可以用于命令传输(例如,AXI4lite总线),一个不同的数据总线(例如,AXI4总线)可以用于数据传输,且CNN集成电路可以用作AXI4总线上的IP。集成电路通过数据总线(例如,AXI4lite总线)从主存储器920接收命令和参数,并通过FIFO接口与主存储器批量存取模块901通信。这个主存储器批量存取模块可以通过数据总线存取外部存储器。在一些情况下,在集成电路和外部处理器910之间可以启用中断机制以提供准确的时间测量。
集成电路包括一个或多个多路复用器。一个或多个多路复用器可以与多个乘法器和其他计算电路连接。多路复用器可以被配置为根据控制信号实现不同级别的功能。例如,第一级的多路复用器可以配置为选择RAM中的不同地址空间(包括特征、权重、偏置项、指令输出),第二级多路复用器用于确定来自RAM的哪个数据的地址空间(哪个连续区域、层的哪个空间、空间内的哪个切片等)将被映射到哪个MAC,第三级用于选择用于存储在RAM中的特定MAC结果,并且,第四级用于确定单个MAC的结果将被存储在地址空间内的哪个地方(哪个连续区域、层的哪个空间、空间内的哪个切片等)。每个多路复用器可以包括用于n个输入的多输入选择器引脚和对1个选择的输入进行输出。多路复用器可以是n输入1输出的任何大小,其中n可以是2,4,8,16,32等。在一些情况下,可以使用少量的大型多路复用器。在一些情况下,可以使用大量的小型多路复用器。在一些情况下,多路复用器可以链接在一起以构建大型多路复用器。
图10示出多路复用器有助于在芯片上的卷积计算中实现不同的存储器存取模式。一个或多个多路复用器1001可以接收一组控制信号1007,以选择用于将数据传输到多个乘法器中的一个的预定多个路由中的一个。可以从用于多路复用器的各种命令中解码控制信号。这些控制信号包括激活函数使能、以及用于计算的输入源选择(输入源来自图像缓冲器或来自前一层的输出)、参数选择、偏置项、输入特征图地址(即,切片索引、切片中的偏移)、参数大小或输入数据等的输出。在一个示例中,控制信号可以确定用于将参数集合的子集或输入特征图数据传输到多个乘法器的预定的多条路由中的一个。控制信号可以从数据传输指令或卷积运算指令中解码,该卷积运算指令包括诸如切片索引的数据地址、切片内的偏移、切片的数量或行数。
在一些情况下,多个乘法器和多个加法器/累加器之间的互连或数据传输路由可以由一个或多个多路复用器控制。例如,一个或多个多路复用器可以连接到乘法器的多个输入,以便选择提供给乘法器的数据。在一些情况下,一个或多个多路复用器可以连接到多个加法器或累加器,用于对由多个乘法器产生的乘积求和。一个或多个多路复用器可以接收用于确定数据传输路由的控制信号,该数据传输路由用于将多个乘法器产生的数据项传输到多个加法器中的一个或多个。在又一示例中,一个或多个修正器可以连接到多个累加器中的一个或多个输出以用于ReLU操作。一个或多个多路复用器可以连接到修正器,并且基于控制信号实现一个或多个修正器的启用或禁用。
如图所示,一个或多个多路复用器1001可以被配置为从片上RAM提取参数和输入特征图数据。在一些情况下,参数、偏置项和输入特征图可以存储在RAM1009、1011、1013内的分离的连续空间中。尽管存储器空间1009和1013被示为分离的,但是用于输入特征图的存储器空间1009可以被重复使用于输出特征图,反之亦然。在一些情况下,输入数据可以存储在缓冲器中,而参数和偏置项存储在RAM中。一个或多个多路复用器1001可以接收一组控制信号以确定获取参数、偏置项和/或输入数据/输入特征图的哪个地址空间。在一些实施例中,可以使用附加的多路复用器1001来进一步确定地址空间内的哪些数据应该被提供给计算单元1005内的哪个乘法器。附加多路复用器可以连接到多个乘法器。多路复用器可以直接连接到乘法器。
可以包括一个或多个多路复用器1003,用于确定如何将来自计算单元1005的输出特征图或输出结果存储在RAM1013中。多路复用器可以接收确定多个预定路由中的一个的控制信号,该预定路由用于将由修正器产生的数据项传输到RAM中的一个切片或者切片内的一个偏移。一个或多个多路复用器可以以类似于输入特征图的方式存储输出特征图,使得输出结果可以用作下一个CNN层的输入特征图。例如,多路复用器可以确定将在哪些RAM片中或在片内的哪个偏移处存储单个MAC的结果。在一些情况下,一个多路复用器1003可以采用一个数据输入和多个选择输入,并且它们具有对应于若干存储器地址(例如,切片索引或偏移)的若干输出。它们根据选择输入的值将数据输入转发到要存储的输出中的一个的位置。一个或多个多路复用器可以连接到多个累加器/加法器和/或多个修正器(取决于是否包括修正器)。
计算单元可以使用多个多路复用器、乘法器、加法器/累加器和/或诸如分路器或延迟元件的其他元件来实现。计算单元可以用各种配置来实现。各种计算电路可以以各种不同的方式互连。计算电路的配置有利于允许在适应不同输入数据/参数布局的同时高效利用多个计算电路。在一些情况下,配置可以允许计算单元通过充分利用乘法器来操作卷积,以便提高乘法运算的效率。在一些情况下,计算电路的配置与核大小无关。或者,计算电路的配置可以与其他参数维度无关。图11至图13示出可以适用于不同卷积层的示例性配置。在一些情况下,卷积层可包括深度上的可分离卷积层。卷积层可以是深度上卷积层或逐点卷积层。应当注意的是,乘法器和加法器的数量仅用于说明目的,可以在计算单元中使用任何数量的乘法器(例如,32、64、128、256、512等)和任何数量的加法器。
如图11所示,计算单元可以包括128个用于卷积运算的连接到多个加法器1103的乘法器1101。在一些情况下,多个加法器可以形成两级加法器网络。相同的计算单元配置可用于处理输入特征图和具有可变大小的参数,诸如不同数量的通道和/或不同的核大小。一个或多个多路复用器1111可以接收用于控制数据传输路由的控制信号。数据传输路由可以包括从片上RAM获取数据到计算单元。在一些情况下,数据传输路由还可以包括乘法器和加法器之间的互连。在每个周期中,计算单元能够并行处理多个输入值。在所描述的示例中,计算单元能够并行处理128个输入特征图数据和128个参数。128个乘法器可以被配置为并行执行乘法,并且多个累加器1103中的每一个可以对四个乘法器的输出进行求和并且累加一个或多个周期的部分求和结果。然后,累加的部分结果可以进一步由一个或多个累加器求和并累加,以产生卷积层的最终输出。在一些情况下,数据流不需要缓冲存储。在一些情况下,RAM上的缓冲器或存储器空间可以用于存储中间结果,并且可以减少存取存储器或缓冲器的数量。
在图11所示的示例中,输入特征图可以具有八个通道,如图6中进一步所示。在每个周期中,使用存储在四行和八个切片1107中的输入特征的一部分。一层的参数包括四个核,每个核在跨八个通道上具有2x2参数,如图7中进一步所示。在每个周期中,使用存储在四行和八个切片1109中的参数的一部分。在一些情况下,在每个周期中,使用跨所有过滤器的所有通道上的1个核点(point of a kernel),与输入特征图中的四个点相乘。可以获取1107中的输入特征和1109中的参数并将其提供给128个乘法器,每个参数被馈送到四个乘法器。每个乘法器可以包括用于接收输入数据的值的第一输入和用于接收核参数/权重的第二输入。乘法器可以执行整数或定点输入的乘法运算。例如,乘法器可以是8位定点乘法器。诸如加法器0之类的第一级加法器或累加器可用于对从乘法器1-4输出的乘积求和。加法器/累加器可以是4-输入加法器/累加器。
具体地,输入特征H0W0C0-7可以被提供给前八个乘法器中的每一个的第一输入,并且参数K0R0S0C0-7可以被提供给前八个乘法器的第二输入。加法器/累加器网络可以包括两个第一级加法器(例如,加法器0和加法器1),每个加法器用于对来自第一组乘法器和第二组乘法器的输出求和,以及第二级累加器1105(例如,加法器0′)用于对来自两个第一级加法器的输出求和。第二级累加器可以有多个输入。可以选择性地控制多个输入,使得相同的芯片布局可以适应不同的配置。例如,在所描述的示例中,输入特征图具有八个通道,四个输入中的两个被馈送零,用于对相邻的八个乘法器的乘积求和。通过对相邻的16个乘法器的乘积求和,相同的布局也可以用于16个通道的输入特征图。在一些情况下,加法器/累加器与乘法器并行运行,因此在第一个时钟周期后的加法器0′的结果是输入特征图的第一个点与跨八个通道的核的第一个点的卷积。在下一个时钟周期中,加法器0′的结果将是∑H0W1Ci*K0R0S1Ci,i=0-7。或者,加法器/累加器在随后的时钟周期中操作,因此可能需要三个时钟周期(例如,一个用于乘法,两个用于两级加法)来输出第一点的卷积。乘法的数量由核的大小决定。在该示例中,在至少四个周期之后,可以获得诸如输出特征图中的一个通道的一个点之类的卷积输出数据。类似地,第二组八个乘法器和两个第一级和第二级累加器可以用于生成诸如相对于第二核K2的输出特征图中的一个通道的一个点之类的第二卷积输出数据。输出数据点可以保存在临时存储器中,并且当对整个层进行计算时,可以将累加结果存储到RAM中原来存储输入特征图的空间中。在示例性配置中,两个第一级累加器和一个第二级累加器用于在至少四个时钟周期上对由八个乘法器产生的乘法结果求和以产生输出结果。时钟周期的数量可以由核参数的数量/核大小决定。在一些情况下,修正器可以连接到累加器的输出,以进一步激活输出特征。在这种情况下,ReLU操作可能需要附加的时钟周期。
在一些情况下,在完成一批输入特征图数据或数据块(例如,八个切片乘四行)的处理后,可以增加按数据块大小(例如,四行)的偏移,下一批数据会重复地被获取到计算单元,直到所有参数和输入特征图都被处理以用于一个操作层。在一些情况下,在处理数据块期间不需要临时存储器存取来存储中间结果。在一些情况下,中间结果可以生成并存储在临时存储器(例如,寄存器、芯片上缓冲器、主存储器上的缓冲器)中,以便在以后的时钟周期中进一步处理。在一些情况下,在处理一批输入数据之后,可以清除存储在一个或多个累加器中的数据。
在完成一层操作之后,可以将输入特征图数据和参数重新加载到空间1009和1011。例如,可以从存储CNN的连续空间加载参数,并且可以从存储来自前一层的输出数据的连续空间加载输入特征图。在完成一层操作之后,可以将一层的输出特征图存储在用于一个或多个操作层的RAM中,然后可以释放用于存储输出特征图的存储空间以供重复使用。
在一些情况下,在完成所有CNN操作后,可以由解码器生成中断控制信号,并将其传输到主存储器批量存取模块,以触发将输出数据从RAM传输到主存储器。在一些情况下,CNN系统的输出结果可以是分类分值向量。输出结果可以经由耦接到主存储器的计算机系统存储和/或呈现给用户。分类结果可以以各种方式使用并应用于各种应用。例如,输出结果可以在显示设备上显示给用户或用于产生控制信号或用于控制另一设备的指令。
在一些情况下,多路复用器可用于控制乘法器和加法器/累加器之间的数据流或数据路由。例如,相同的4-输入第二级累加器可以用于不同的硬件配置,并且在如图11所示的第一示例中,可以选择四个输入中的两个来对来自第一级累加器的结果求和。可以通过控制多路复用器的控制信号来实现对加法器/累加器的选择性输入。
输入特征图和参数可以具有可变的大小和维度。输入特征图和参数可以被排列成多个切片,其中用于输入特征图的切片的数量可以等于或不等于用于参数的切片的数量。在图12A中所示的另一示例中,相同的计算单元配置可以用于处理来自前一示例的具有不同通道数量的输入特征图和参数,并且相同的配置也适用于各种核大小或形状。在一些情况下,输入特征图可以具有大量的通道,并且核的数量可以很少。例如,输入特征图可以具有16个通道并且被排列成32个切片1207。输入特征图可以与包含跨16个通道的八个参数的一个核进行卷积。核形状可以是1x8、8x1、2x4或4x2。可以将参数排列至四个切片1209中。在一时钟周期中,可以获取输入特征图的四行和32个切片以及参数的四个切片并将其提供给128个乘法器,每个参数馈送到八个乘法器中(例如,乘法器0、16、32、48、64、80、96、112),并且每个输入值馈送到一个乘法器中。诸如加法器0之类的第一级加法器或累加器可用于对从乘法器1-4输出的乘积求和。加法器/累加器可以是4-输入加法器/累加器。乘法器、加法器以及乘法器与加法器之间的互连可以与图11中所示的相同。与前一示例类似,可以使用一个时钟周期来处理存储在数据块1207和1209中的输入特征图数据和参数数据。
具体地,可以将16个输入值H0W0C0-15提供给前16个乘法器的第一输入引脚,并且可以将16个参数K0R0S0C0-15提供给该16个乘法器的第二输入引脚。加法器/累加器网络可以包括四个第一级加法器(例如,加法器0和加法器1),每个加法器用于对来自四组乘法器的输出求和,以及第二级累加器1205(例如,加法器0′),用于对来自四个第一级加法器的输出求和。在第一个时钟周期后的加法器0′的结果是输入特征图的第一个点与跨16个通道的核的第一个点的卷积。在下一个时钟周期中,加法器0′的结果将是∑H0W1Ci*K0R0S1Ci,i=0-15。乘法的数量由核的大小决定。在所描述的示例中,因为核包含八个参数,所以诸如加法器0′之类的第二级加法器可以将对八个周期的来自加法器0和加法器1的结果累加以便输出卷积结果。卷积操作将应用于整个输入特征图。例如,在至少八个周期之后,可以从八个第二级加法器0′-7′获得八个卷积输出结果。输出数据点可以保存在临时存储器中,并且当完成对整个层进行计算时,可以将累加结果存储到RAM中原来存储输入特征图的空间中。在示例性配置中,四个第一级累加器和一个第二级累加器用于在至少八个时钟周期上对由16个乘法器产生的乘法结果求和,以在输出图中产生具有16个通道的点。用于产生一个输出结果的时钟周期的数量可以由核参数/核大小的数量决定。
在一些情况下,相同的配置可以适用于深度上卷积层。或者,配置的变化可以用于深度上卷积层。如上所述的深度上卷积层可以为每个输入通道产生卷积。在图12B所示的示例中,来自先前示例的计算单元配置的变化可以用于处理来自前一示例的具有相同通道数量的输入特征图和参数,并且相同的配置适用于各种核大小或形状。例如,输入特征图可以具有16个通道并且被排列成32个切片。输入特征图可以与含有用于每个通道的八个参数的一个核进行卷积。核形状可以是1x8、8x1、2x4或4x2。可以以与前一示例中所示相同的方式将参数排列成四个切片。在一时钟周期中,可以获取输入特征图的四行和32个切片以及参数的四个切片并将其提供给128个乘法器,每个参数馈送到八个乘法器中(例如,乘法器0、16、32、48、64、80、96、112),并且每个输入值馈送到一个乘法器中。诸如Accu21206之类的累加器可用于从乘法器2的输出的乘积求和。该配置可以包括128个累加器,每个累加器被配置为对来自乘法器的乘积求和。每个累加器产生的和结果是应用于输入特征图的通道的过滤器的卷积结果。
具体地说,一时钟周期后的Accu0的结果是输入特征图的第一通道与跨核的一行的核(即,第一核)的第一通道的卷积。在下一个时钟周期中,Accu0的结果将是∑H0W1C0*K0R1S1C0,i=0-15。乘法的数量由核的大小决定。在所描述的示例中,由于核包含八个参数,所以Accu0可以跨整个核来对8个周期进行求和以便输出卷积结果。卷积操作将应用于整个输入特征图。输出数据点可以保存在临时存储器中,并且当完成对整个层进行计算时,可以将累积结果存储到RAM中原来存储输入特征图的空间中。在示例性配置中,128个累加器用于对由16个乘法器产生的乘法结果求和,以在输出图中产生用于一个通道的点。用于产生一个输出结果的时钟周期的数量可以由核参数/核大小的数量决定。可以将深度上卷积层的输出提供给后面接有1×1逐点卷积层的ReLU层。
图13示出使用相同配置来执行输入特征图和核的另一布局的卷积的另一示例。在一些情况下,输入特征图的大小可以很小并且核的数量可以很大。输入特征图可以被排列并存储为四个切片。可以将参数排列至32个切片中。输入特征图可以具有16个通道并且被排列至四个切片中。输入特征图可以与7个核进行卷积,每个核包含跨16个通道的一个参数。可以将参数排列至四个切片中。在一时钟周期中,可以获取输入特征图的四行和四个切片以及参数的32个切片,并将其提供给128个乘法器,每个输入值馈送到8个乘法器中(例如,乘法器0、16、32、48、64、80、96、112),并且每个参数馈送到一个乘法器中。每个乘法器可以包括用于接收输入值的值的第一输入和用于接收核参数/权重的第二输入。乘法器可以执行整数或定点输入的乘法运算。例如,乘法器可以是8位定点乘法器。诸如加法器0之类的第一级加法器或累加器可用于对从乘法器1-4输出的乘积求和。加法器/累加器可以是4-输入加法器/累加器。乘法器、加法器以及乘法器与加法器之间的互连可以与图11和图12A中所示的相同。
具体地,可以将16个输入值H0W0C0-15提供给前16个乘法器中的每一个的第一输入引脚,并且可以将16个参数K0R0S0C0-15提供给该16个乘法器的第二输入引脚。加法器/累加器网络可以包括四个第一级加法器(例如,加法器0和加法器1),每个第一级加法器用于对来自四组乘法器的输出求和,以及第二级累加器(例如,加法器0′),用于对来自四个第一级加法器的输出求和。在第一个时钟周期后的加法器0′的结果是输入特征图的第一个点与跨16个通道的核的第一个点的卷积。在下一个时钟周期中,加法器0′的结果将是∑H0W1Ci*K0R0SlCi,i=0-15。乘法的数量由核的大小决定。在所描述的示例中,因为核仅包含一个参数,所以每个周期,诸如加法器0′之类的第二级加法器将输出卷积结果。卷积运算将应用于整个输入特征图直至结束。例如,在至少一个周期之后,可以从八个第二级加法器0′-7′获得八个卷积输出结果。输出数据点可以保存在临时存储器中,并且当完成对整个层进行计算时,可以将累加结果存储到RAM中原来存储输入特征图的空间中。在示例性配置中,四个第一级累加器和一个第二级累加器用于在至少一个时钟周期上对由16个乘法器产生的乘法结果求和,以在输出图中产生具有16个通道的点。用于产生一个输出结果的时钟周期的数量可以由核参数/核大小的数量决定。
在一些实施例中,可以仅使用一级加法器/累加器。作为如图14所示的配置的变化示例,计算单元可以包括32个累加器,每个累加器与没有第二级累加器的四个乘法器连接。每四个乘法器(例如,前四个乘法器)可用于执行输入特征图的2×2区域与核的乘法,并且乘积由乘法器/累加器(例如,加法器0)进行求和及累加。可能需要多个周期时钟来生成一个输出结果。可以由核的大小和通道的数量来确定周期的数量。例如,在所描述的示例中,由于核大小为4并且卷积被应用于八个通道,因此生成一个输出的时钟周期的总数为8个周期=2(跨八个通道的一个参数的周期)×4(参数)。可能需要至少八个周期来处理包含八个切片和八行的数据块中存储的输入特征图数据。应注意的是,如图14所示的配置可以与与图11的配置相同,也可以不同。在一些情况下,如图11中所使用的第二级累加器可以被一个或多个多路复用器禁用,使得两个配置相同。
在一些实施例中,32个四输入加法器接收128个乘法器的输出,然后另外16个双输入加法器接收32个四输入加法器的输出。然后将16个双输入加法器的输出存储到RAM中。这种布局能够满足CNN配置K4C8P4。对于CNN配置K1C16P8或K8C16P1,16个双输入加法器的16个输出进一步馈送到8个双输入加法器,8个双输入加法器的8个输出被存储到RAM中。
图15示出可以被配置为实现本申请中公开的任何计算系统的计算机系统1501。计算机系统1501可以包括移动电话、平板电脑、可穿戴设备、笔记本电脑、台式计算机、中央服务器等。
计算机系统1501包括中央处理单元(CPU,这里也指“处理器”和“计算机处理器”)1505,其可以是单核或多核处理器,或者是用于并行处理的多个处理器。CPU可以是如上所述的处理器。计算机系统1501还包括存储器或存储器位置1510(例如,随机存取存储器、只读存储器、闪存)、电子存储单元1515(例如,硬盘)、用于与一个或多个其他系统通信的通信接口1520(例如,网络适配器)、以及外围设备1525,例如高速缓存、其他存储器、数据存储和/或电子显示适配器。在一些情况下,通信接口可以允许计算机与诸如成像设备或音频设备的另一设备进行通信。计算机能够从耦接的设备接收输入数据以进行分析。存储器1510、存储单元1515、接口1520和外围设备1525通过诸如主板之类的通信总线(实线)与CPU1505进行通信。存储单元1515可以是用于存储数据的数据存储单元(或数据存储库)。计算机系统1501可以借助于通信接口1520可操作地耦接到计算机网络(“网络”)1530。网络1530可以是因特网、互联网和/或外联网,或者与因特网通信的内联网和/或外联网。在一些情况下,网络1530是电信和/或数据网络。网络1530可以包括一个或多个计算机服务器,其可以实现诸如云计算之类的分布式计算。在一些情况下,借助于计算机系统1501网络1530可以实现对等网络,其可以使耦接到计算机系统1501的设备能够起到客户端或服务器的作用。
CPU1505可以执行一系列机器可读指令,这些指令可以体现在程序或软件中。指令可以存储在诸如存储器1510之类的存储器位置中,指令可以指向到CPU1505,CPU1505随后可以编程或以其他方式配置CPU1505以实现本公开的方法。由CPU1505执行的操作的示例可以包括获取、解码、执行、和回写。
CPU1505可以是诸如集成电路之类的电路的一部分。系统1501的一个或多个其他组件可以包括在电路中。在一些情况下,该电路是专用集成电路(ASIC)。
存储单元1515可以存储诸如驱动程序、库、和保存的程序之类的文件。存储单元1515可以存储用户数据,例如用户偏好和用户程序。在一些情况下,计算机系统1501可以包括在计算机系统1501外部的一个或多个附加数据存储单元,例如位于通过内联网或因特网与计算机系统1501通信的远程服务器上。
计算机系统1501可以通过网络1530与一个或多个远程计算机系统通信。例如,计算机系统1501可以与用户的远程计算机系统通信。远程计算机系统的示例包括个人计算机、平板电脑或平板计算机、智能手机、个人数字助理等。用户可以经由网络1530接入计算机系统1501。
本文所描述的方法可以通过存储在计算机系统1501的诸如存储器1510或电子存储单元1515之类的电子存储位置上的机器(例如,计算机处理器)可执行代码来实现。机器可执行代码或机器可读代码可以以软件的形式提供。在使用期间,代码可以由处理器1505执行。在一些情况下,可以从存储单元1515提取代码并将其存储在存储器1510上以供处理器1505准备存取。在一些情况下,可以排除电子存储单元1515,并且将机器可执行指令存储在存储器1510中。
代码可以被预编译和配置以用于具有适于执行代码的处理器的机器,或者可以在运行时期间编译。代码可以用编程语言提供,可以选择该编程语言使代码能够以预编译或编译的方式执行。
本文提供的系统和方法的各方面,例如计算机系统1501,可以在编程中体现。该技术的各个方面可以被认为是“产品”或“制品”,其通常以机器(或处理器)可执行代码和/或在一种机器可读介质中承载或体现的相关数据的形式。机器可执行代码可以存储在诸如存储器(例如,只读存储器、随机存取存储器、闪存)或硬盘之类的电子存储单元上。“存储”型介质可以包括计算机、处理器之类、或其相关模块的有形存储器的任何一个或全部,上述相关模块诸如各种半导体存储器、磁带驱动器、磁盘驱动器等,其可以在任何时间为软件编程提供非瞬态存储器。全部或部分的软件有时可以通过因特网或各种其他电信网络进行通信。例如,这样的通信可以使软件从一个计算机或处理器加载到另一个计算机或处理器,例如,从管理服务器或主计算机加载到应用服务器的计算机平台。因此,可以承载软件元件的另一种类型的介质包括诸如跨本地设备之间的物理接口、通过有线和光学陆线网络以及通过各种空中链路进行使用的光波、电波和电磁波。承载这种波的诸如有线或无线链路、光链路之类的物理元件,也可以被认为是承载软件的介质。如本文所使用的,除非限于非瞬态的有形“存储”介质,诸如计算机或机器“可读介质”之类的术语是指参与向处理器提供指令以供执行的任何介质。
因此,诸如计算机可执行代码之类的机器可读介质可以采用许多形式,包括但不限于有形存储介质、载波介质或物理传输介质。非易失性存储介质包括例如光盘或磁盘,诸如任何计算机或诸如可用于实现附图中所示的数据库等的计算机类中的任何存储设备。易失性存储介质包括诸如此计算机平台的主存储器之类的动态存储器。有形传输介质包括同轴电缆;铜线和光纤,其包括在计算机系统内包括总线的导线。载波传输介质可以采用电信号或电磁信号的形式、或诸如在射频(RF)和红外(IR)数据通信期间生成的声波或光波的形式。因此,计算机可读介质的常见形式包括例如:软磁盘、软盘、硬盘、磁带、任何其他磁介质、CD-ROM、DVD或DVD-ROM、任何其他光学介质、穿孔卡纸磁带、具有孔图案的任何其他物理存储介质、RAM、ROM、PROM和EPROM、FLASH-EPROM、任何其他存储器芯片或盒式磁带、载波传输数据或指令、传输此类波载波的电缆或链路、或计算机可以从中读取编程代码和/或数据的任何其他介质。这些形式的计算机可读介质中的许多介质可以涉及将一个或多个指令的一个或多个序列传送到处理器以供执行。
计算机系统1501可以包括电子显示器1535或与电子显示器1535通信,电子显示器1535包括用于提供例如管理界面的用户界面1540。用户界面(UI)的示例包括但不限于图形用户界面(GUI)和基于网络的用户界面。
可以通过一种或多种算法来实现本公开的方法和系统。算法可以在由中央处理单元1505执行时通过软件实现。
虽然本文已经示出和描述了本申请的优选实施例,但是对于本领域技术人员显而易见的是,这些实施例仅以示例的方式提供。在不脱离本申请的情况下,本领域技术人员将想到许多变化、改变和替换。应该理解的是,本文所述的本申请实施例的各种替代方案可用于实施本申请。权利要求旨在界定本申请的范围,并且由此涵盖这些权利要求及其等同物范围内的方法和结构。
- 还没有人留言评论。精彩留言会获得点赞!