一种Git仓库文件注解系统的可视化漂移算法的制作方法
本发明属于互联网和软件工程领域,涉及一种Git仓库文件注解系统的可视化漂移算法。
背景技术:
Git是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。Git是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件。每一个Git克隆都是一个完整的文件库,含有全部历史记录和修订追踪能力。其最大特色就是“分支”及“合并”操作快速、简便;支持离线工作,Git是整个项目范围的原子提交,而且Git中的每个工作树都包含一个具有完整项目历史的仓库。
Git保留了每次代码演化的全部历史记录,方便我们回退到历史版本查看我们需要的内容。虽然代码中已经有了功能注释和逻辑注释,但是在团队协作开发过程中,负责人在审核提交的代码的时候,可能需要在不改变源代码的情况下对部分代码添加一些注解,同时,开发者也可以对代码添加一些注解,这些注解可以包括大量文字的知识点解析、伪算法讲解和图片,还可以跨越多个文件的多处代码进行整合注解等。一方面可以作为审核人员的审核笔记,便于今后查阅,另一方面也可以作为提交者和审核者之间的一种交流方式,审核者提问,提交者修改或者回答,最后还可以作为其他用户快速熟悉代码功能逻辑的一个重要途径,可以防止开发人员流动过大,交接不方便和减少新加入的开发人员的阅读和学习时间的问题。目前,比较流行的GitHub或者GitLab代码托管平台本身没有提供这种注解内容多维度、多视角和可视化的功能,无法满足使用者的需求,因此亟需开发一种基于Git仓库的多维度、多视角和可视化注解系统来解决上述问题。
技术实现要素:
本发明的目的是通过设计并实现一种Git仓库文件注解系统的可视化漂移算法,该算法主要是将Git仓库中正在可视化的文件对应的历史版本文件中添加的注解在该文件中的相等代码处可视化,同时可以达到工程项目的性能要求。
为实现上述目的,本发明采用的技术方案为一种Git仓库文件注解系统的可视化漂移算法,包括以下步骤:
S1:获取带有注解的历史版本文件
从存储历史版本文件注解的数据库获取该版本文件对应的历史版本文件的行记录;
S2:转换文件内容格式
将最新版本文件和历史版本文件中的每一行数据转换为哈希字符;
S3:文件对比分析
对比分析新版本文件和历史版本文件中代码块之间的关系,标记新版本文件中的代码块对应历史版本文件中的代码块是添加、删除或者是相等;
S4:统计相等代码块的行号对应关系
对相等标记代码块进行分析,将历史版本文件中的行号与新版本文件中的行号一一对应,最终获取到所有历史版本文件中的注解在新版文件本中的对应位置;
S5:可视化历史版本注解代码
把注解内容在新版本文件行列号位置处进行标识,当点击该标识时可视化该注解内容。
进一步,步骤S1中,获取带有注解的历史版本文件,具体为:
首先查找数据库并获取该文件对应的所有带有注解的历史版本文件记录,找到每条记录中的项目版本号,然后查找Git仓库,获取项目版本号对应的文件。最终,将会获取到可视化文件对应的所有带有注解的历史版本文件。
进一步,步骤S2中,转换文件内容格式,具体为:
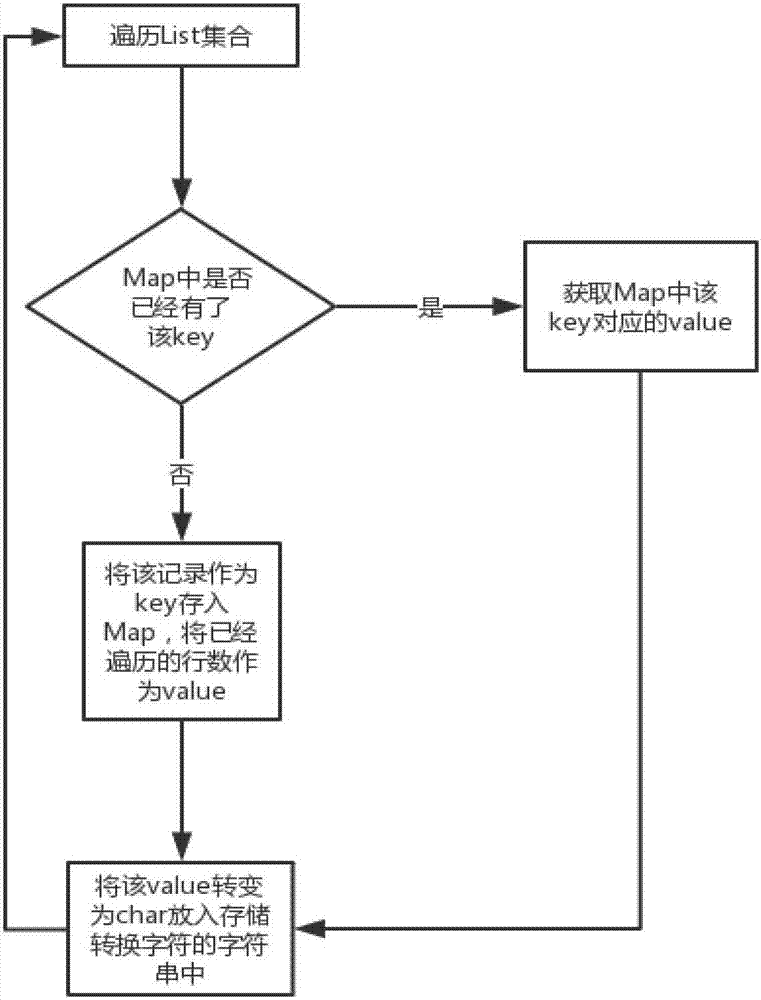
1)首先获取整个文件内容,然后将其遍历,使用List集合的方式存储每一行,最终将文件转换为List集合;
2)遍历List集合,将List集合中的记录作为Map集合的key,将已经遍历的行数作为key对应的value。如果Map集合已经有key对应遍历的行记录,则获取该key对应的value,然后把该value转换为char类型字符放入存储转换后字符的字符容串;如果Map集合中没有key对应遍历的行记录,则进行步骤3操作,否则继续遍历List集合;
3)将步骤2遍历的行记录放入Map集合,该行记录作为Map集合的key,已经遍历的行数作为该key对应的value;同时把该value转换为char类型字符放入存储转换后字符的字符串;继续执行步骤2,遍历List集合。
进一步,步骤S3中,文件对比分析,具体为:
1)首先比较两个文件的哈希字符串是否完全相等,如果是,则直接返回整个哈希字符串作为一个相等代码块,否则进行下一步;
2)判断两个文件的哈希字符串中是否有共有前缀字符串,如果有,则记录结束位置;
3)判断两个文件的哈希字符串中是否有共有后缀字符串,如果有,则记录起始位置;
4)如果两个文件的哈希字符串中有相等前缀或者相等后缀字符串,则截取他们,标记为相等代码块;如果没有相等前缀字符串,则对字符串进行遍历,找到两个字符串相同的部分,将历史版本文件没有的字符串,标记为插入,将新版本文件中没有的字符串标记为删除代码块;截取已经标记的字符串,剩余的部分循环执行步骤2、步骤3和步骤4,直到新文件循环遍历结束。
进一步,步骤S4中,统计相等代码块的行号对应关系,具体为:
基于步骤S3取得的对比分析的两个文件代码之间的关系,接下来统计两个文件之间相等代码块行号对应关系,
首先对步骤S3标记的代码块集合进行遍历,如果是相等标记,则对该标记进行循环,存储新版本文件行号与历史版本文件行号之间的对应关系;如果是插入标记,则将新版本文件行号记录加上插入标记的行数,作为存储下面相等代码块行号之间对应关系的新版本文件的起始行号;如果是删除标记,则将历史版本文件行号记录加上删除标记的行数,同样是作为存储下面相等代码块行号之间对应关系的历史版本文件的起始行号。遍历结束后,将得历史版本文件行号与新版本文件行号之间的对应关系。
进一步,步骤S5中,可视化历史版本文件注解,具体为:通过步骤S4获取到历史版本文件行号与新版本文件行号之间的对应关系后,使用步骤S1中从数据库获取到的注解代码的行列号记录查找该对应关系,找到历史版本文件注解的行号,然后将该行号作为步骤S4获取的对应关系的key,通过hash的key和value对应关系找到该key对应的value,该value即为新版本文件中注解的代码位置。通过上述步骤,即可获取到所有历史版本文件的注解在新版本文件中的位置对应关系,最后在该位置处显示带有注解的标识,当用户点击该标识时,可视化该位置的注解内容。
与现有技术相比,本发明具有以下有益的技术效果:
1,本发明可获取到所有历史版本文件的注解在新版本文件中的位置对应关系,在该位置处显示带有注解的标识,当用户点击该标识时,可视化该位置的注解内容。
2,本发明是将Git仓库中正在可视化的文件对应的历史版本文件中添加的注解在该文件中的相等代码处可视化,同时可以达到工程项目的性能要求,提供了一种基于Git仓库的多维度、多视角和可视化注解系统。
附图说明
图1为一种Git仓库文件注解系统的可视化漂移算法的步骤流程图;
图2为文件对比分析步骤流程图;
图3为统计相等代码块的行号对应关系步骤流程图;
具体实施方式
下面结合附图对本发明作进一步详细说明。如图1的步骤流程图所示,包含以下步骤:
步骤1:获取带有注解的历史版本记录
首先查找存储注解代码与注解内容之间一致性关系的数据库记录,获取该版本文件对应的所有带有注解的历史版本文件的注解记录;然后查找Git仓库,通过获取的注解记录中的仓库版本号,即可获取所有带有注解的历史版本文件。
步骤2:转换文件内容格式
1)首先获取整个文件内容,然后将其遍历,使用List集合的方式存储每一行,最终将文件转换为List集合;
2)遍历List集合,将List集合中的记录作为Map集合的key,将已经遍历的行数作为key对应的value。如果Map集合已经有key对应遍历的行记录,则获取该key对应的value,然后把该value转换为char类型字符放入存储转换后字符的字符串;如果Map集合中没有key对应遍历的行记录,则进行3)操作,否则继续遍历List集合;
3)将步骤2)遍历的行记录放入Map集合,该行记录作为Map集合的key,已经遍历的行数作为该key对应的value;同时把该value转换为char类型字符放入存储转换后字符的字符串;继续执行步骤2),遍历List集合。
转换文件内容格式具体算法的一个示例性程序的代码如下:
步骤3:文件对比分析,如图2所示:
1)首先比较两个文件的哈希字符串是否完全相等,如果是,则直接返回整个文件的哈希字符串作为一个相等代码块,否则进行下一步;
2)判断两个文件的哈希字符串中是否有共有前缀字符串,如果有,则记录结束位置;
3)判断两个文件的哈希字符串中是否有共有后缀字符串,如果有,则记录起始位置;
4)如果两个文件的哈希字符串中有相等前缀或者相等后缀字符串,则截取他们,标记为相等代码块;如果没有相等前缀字符串,则对字符串进行遍历,找到两个字符串相同的部分,将历史版本文件中没有的字符串,标记为插入代码块,将新版本文件中没有的字符串标记为删除代码块;截取已经标记的字符串,剩余的部分循环执行步骤2)、步骤3)和步骤4),直到新文件循环遍历结束。
前缀字符串算法步骤的一个示例性程序的代码具体如下:
后缀字符串算法步骤的一个示例性程序的代码如下:
步骤4:统计相等代码块的行号对应关系
首先对步骤3标记的代码块集合进行遍历,如果是相等标记,则对该标记代码块进行循环,存储新版本文件行号与历史版本文件行号之间的对应关系;如果是插入标记,则将新版本文件行号记录加上插入标记代码块的行数,作为存储下面相等代码块行号之间对应关系的新版本文件的起始行号;如果是删除标记,则将历史版本文件行号记录加上删除标记代码块的行数,同样是作为存储下面相等代码块行号之间对应关系的历史版本文件的起始行号。遍历结束后,将得历史版本文件行号与新版本文件行号之间的对应关系。
统计相等代码块的行号对应关系具体步骤,如图3所示,具体如下:
步骤5:可视化历史版本文件注解
通过步骤4获取到历史版本文件行号与新版本文件行号之间的对应关系后,使用步骤1中从数据库获取到的注解代码的行列号记录查找该对应关系,找到历史版本文件注解的行号,然后将该行号作为步骤4获取的对应关系的key,通过hash的key和value对应关系找到该key对应的value,该value即为新版本文件中注解的代码位置。通过上述步骤,即可获取到所有历史版本文件的注解在新版本文件中的位置对应关系,最后在该位置处显示带有注解的标识,当用户点击该标识时,可视化该位置的注解内容。
本发明不限于上述实例,一切采用等同替换或等效替换形成的技术方案均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!