GPU流域径流模拟分布式调度系统及方法与流程
本发明涉及河流流域径流的数据仿真处理领域,尤其涉及一种通用计算支持下的流域径流的模拟分布式调度方法及调度系统。
背景技术:
我国是世界上洪水灾害最频繁且严重的国家之一,暴雨洪涝灾害的快速模拟和评估具有十分重要的意义。水文模型是暴雨风险模拟的基础,国内外已经提出了很多成熟的水文模型,其中不乏有水箱模型、SWMM和PRMS等集总式水文模型,也有TOPMODEL、SHE和SWAT等半分布式或分布式模型。分布式水文模型将水动力学引入到实际汇流模拟中,能研究流域出水口或流域各地点的径流汇流,因此在水文模拟的精度上,相较于集总式水文模型有了进一步的提升。但多数分布式水文模型计算量较大,主要运行在CPU平台上,其计算效率成为进一步应用的瓶颈。
GPU应用于水文数值模拟的研究,国外起步较早,吉田圭介等利用GPGPU技术对自然河流的洪水淹没过程进行了数值模拟,其计算过程中考虑了河床的变化、地表植被的变化和河流水体边际的变化,并与CPU计算的结果进行了对比,获得了较好的加速效果;Vacondio R等使用了极限的有限体积离散技术,并利用CUDA通用计算框架精准且快速的模拟了洪水过程,经过严格的测试,其与实际过程相差较小,获得了较好的模拟效果;Dullo T等利用NVIDIA通用计算框架(CUDA)对美国密西比州Taum Sauk水坝进行了溃坝洪水演进数值模拟,其分别使用了单个GPU和多个GPU两种方式进行了模拟,单个GPU获得了较好的加速效果,多个GPU计算目前正处于研究阶段。国内方面,尹灵芝等基于元胞自动机(CA)演进模型,以CUDA为GPU计算框架,模拟了溃坝条件下的洪水演进模拟,其模拟效率与串行的CPU-CA模型相比获得了15.6倍的加速比;王金宏也进行了基于GPU-CA模型的洪水演进模拟,并以四川安县肖家桥堰塞湖为案例区域,进行了溃坝洪水演进模拟和分析实验,获得了较好的加速效果。
传统GPU通用计算的数据处理机制是将数据一次加载到显存中计算,当流域数据大于显存存储量时,读取和写入将十分困难。针对此问题,有学者探讨了大数据的分块加载和写入方法,以解决显存不足的问题。对于大范围、高精度的流域径流汇流的迭代计算,该方法将导致显存和内存大量数据频繁交换,降低了径流模拟效率。
技术实现要素:
为解决现有技术中的上述缺陷,并且为提高径流汇流模拟精度,本发明采用分布式水文模型。首先依据一定的空间分辨率将流域划分为面积大小相等的网格集合;在此基础上,将径流汇流过程划分为时间间隔相等的时间片。每一个时间片以网格为单元进行汇流计算。通过时间片的迭代,完成流域径流汇流的过程模拟。考虑到分布式水文模型计算量大,CPU计算性能低,引入通用计算以提高计算效率。
为解决单台计算机模拟大流域径流汇流时显存和内存大量数据频繁交换问题,提出通用计算与分布式计算相结合的思路。首先将流域数据分为单台计算机能够存储和处理的子块,然后通过网络送至服务器不同的计算机上进行通用计算。为减少服务器之间的大块数据交换,服务器接收到子块处理任务后,一直负责对该数据块的径流模拟迭代处理。
在径流模型中,每一个网格水流和水深计算均需要周围8邻域网格参与计算。为保证分块计算结果的正确性,子块在每一次迭代后,与相邻子块交换边缘数据,以保持相邻数据块在任意时间片上的数据一致性。当所有时间片迭代完成后,节点的分块计算结果下载到客户端拼接,得到最终的汇流计算结果。
具体而言,本发明提供了以下技术方案:
一方面,本发明提供了一种流域径流模拟分布式调度方法,该方法适用于包括服务器端、客户端的分布式系统上,所述服务器端包含若干个节点服务器,其特征在于,所述方法包括:
步骤1、将流域数据分为若干个子块,并将径流汇流计算过程分为时间间隔相等的时间片;
步骤2、将所述若干个子块分别发送至服务器上不同的计算机进行通用计算;
步骤3、所述服务器上不同的计算机在接收到一子块处理任务后,始终负责对该子块的径流模拟作迭代处理;在迭代处理中,子块在每一次迭代后,与相邻子块交换边缘数据;
其中负责一子块计算的所述计算机作为一个节点。
优选的,所述步骤1中,每个子块的数据量满足单台计算机能够存储和处理。
优选的,所述步骤3中的交换边缘数据,通过边缘数据更新实现,所述边缘数据更新指在每一帧径流汇流计算完成后,每一子块从相邻子块读取更新后的边缘数据。
优选的,所述边缘数据更新采用所述服务器上不同节点之间的数据交换方式;
所述服务器上不同节点之间的数据交换包括:每一个所述节点记录子块位置,并建立与相邻子块计算节点之间的网络连接;每一节点完成单帧径流汇流计算后,读取边缘数据,并将所述边缘数据发送至相邻子块的节点;当一节点接收到所有更新后的边缘数据后,进入下一时间片的径流汇流计算。
优选的,所述边缘数据更新采用客户端数据交换方式;所述客户端数据交换包括:将客户端作为边缘数据聚合中心,在各节点完成径流汇流计算后,读取边缘数据,一次性传输给客户端;客户端在接收到全部边缘数据后,将各节点所需的新的边缘数据一次性发送给对应节点。
优选的,所述边缘数据更新还包括显存和内存的边缘数据更新:当节点的子块数据计算完成后,将边缘数据从显存读回内存,并通过网络传输至客户端或相邻的子块所在的节点;
若通过网络直接传输至相邻的子块所在的节点,则当节点接收到新的边缘数据后,将其存储在内存,随后在将其更新至显存;此后,节点进行下一时间片的径流汇流计算;
若通过网络直接传输至客户端,则客户端负责将汇总后的边缘数据发送至各个相邻的子块所在的节点,则当节点接收到新的边缘数据后,将其存储在内存,随后在将其更新至显存;此后,节点进行下一时间片的径流汇流计算。
优选的,所述子块包括若干个网格单元,所述径流汇流计算以网格为单元进行,包括网格单元水量收支计算、网格单元受力计算。
优选的,所述网格单元水量收支计算包括:
在时间片上,计算任意网格单元c的水量收支,其中tn+1时刻的网格水深为:
其中,和分别为时间片上的降水量、下渗量、蒸发量、流入量和流出量;
网格的初始水速和终止水速满足:
其中,tn时刻的网格水深为网格单元b为网格单元c的相邻网格单元,为网格单元b水流流入网格单元c的速度分量,ΔL为网格单元b和网格单元c的中心距离,为流出量,Δt为汇流时间。
优选的,所述网格单元受力计算包括:
以中心网格和邻域网格水体高度差来模拟水体在重力和压力梯度的作用下产生的速度增量;
依据地表水流的河床摩擦力,确定水流速度衰减。
优选的,速度增量可用以下方式计算:
设网格c和邻域网格b的地形高度分别为Hc和Hb,则邻域网格相对于中心网格的水体高度差ΔWbc为:
其速度增量Δvbc在水平x和y方向的分量为:
其中,K为综合压力梯度、重力及相邻水团作用等因素的水力加速度常数,dx和dy为网格b和网格c在x和y方向的坐标之差。
优选的,依据地表水流的河床摩擦力,确定水流速度衰减可采用如下方式:设在单元网格上摩擦力作用的上界深度Wmax,下界深度为Wmin,衰减系数ε近似定义为:
其中,σ为摩擦比例常数,由具体流域特征确定。
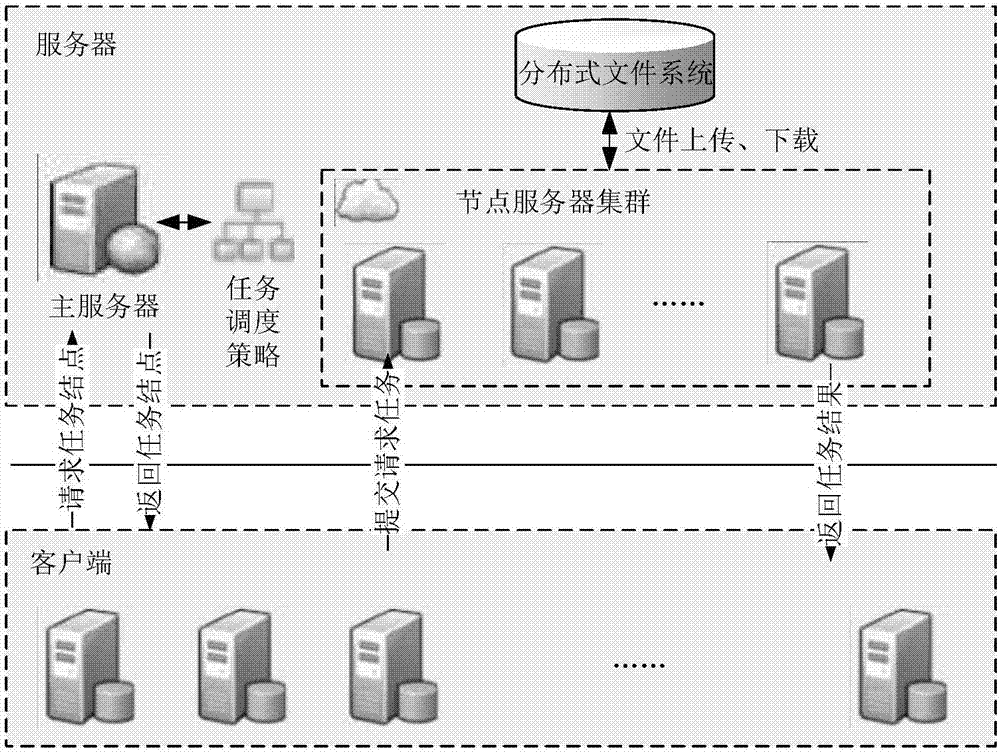
在本发明的另一方面,还提供了一种流域径流模拟分布式调度系统,所述系统包括:客户端、服务器端;
所述服务器端包括总服务器、节点服务器和分布式文件系统;
所述总服务器用于接收客户端的命令请求,并以分布式文件形式存储,同时管理流域数据;
所述节点服务器用于承担子块的径流汇流计算;所述子块由流域数据分割而成;
所述客户端将要计算的流域地形数据发送至分布式文件系统,并向总服务器发送径流模拟任务请求;并在全部径流汇流计算完成后,接收各节点服务器的计算结果,并拼合获得最终的汇流结果。
优选的,所述节点服务器在接收到一子块处理任务后,始终负责对该子块的径流模拟作迭代处理;在迭代处理中,子块在每一次迭代后,与相邻子块交换边缘数据。
优选的,所述总服务器在接收到客户端的请求后,向所述客户端返回所有可用节点服务器的信息,所述客户端可对所述可用节点服务器进行筛选。
优选的,所有参与计算的节点服务器在完成交换边缘数据之后,继续下一个时间片的迭代计算;所述时间片通过将径流汇流过程进行等时间间隔划分获得。
与现有技术相比,本发明技术方案具有以下优点:对于大范围、高精度的流域径流汇流的迭代计算,本发明将通用计算与分布式调度相结合,整合了服务器上通用计算资源,减少了显存和内存数据交换数据量,很好地解决了传统模型在计算量巨大和CPU性能瓶颈间的矛盾,也突破了GPU分块计算中显存和内存大量数据频繁交换的瓶颈,提高了径流汇流模拟的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1为本发明实施例的分布式调度示意图;
图2为本发明实施例的流域径流模拟的分布式框架;
图3为本发明实施例的分块内部像元与分块边缘像元示意图。
具体实施方式
下面结合附图对本发明实施例进行详细描述。应当明确,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本领域技术人员应当知晓,下述具体实施例或具体实施方式,是本发明为进一步解释具体的发明内容而列举的一系列优化的设置方式,而该些设置方式或实施例之间均是可以相互结合或者相互关联使用的。同时,下述的具体实施例或实施方式仅作为最优化的设置方式,而不作为限定本发明的保护范围的理解。
实施例1:
在一个具体的实施例中,本发明所采用的整体思路如下:为提高径流汇流模拟精度,本发明采用分布式水文模型。首先依据一定的空间分辨率将流域划分为面积大小相等的网格集合;在此基础上,将径流汇流过程划分为时间间隔相等的时间片。每一个时间片以网格为单元进行汇流计算。通过时间片的迭代,完成流域径流汇流的过程模拟。考虑到分布式水文模型计算量大,CPU计算性能低,引入通用计算以提高计算效率。
为解决单台计算机模拟大流域径流汇流时频繁的显存和内存数据交换问题,提出GPU计算与分布式计算相结合的思路。首先将流域数据分为单台计算机能够存储和处理的子块,然后通过网络送至服务器不同的计算机上进行通用计算。为减少服务器之间的大块数据交换,服务器接收到子块处理任务后,一直负责对该数据块的径流模拟迭代处理。
在径流模型中,每一个网格水流和水深计算均需要周围8邻域网格参与计算。为保证分块计算结果的正确性,子块在每一次迭代后,与相邻子块交换边缘数据,以保持相邻数据块在任意时间片上的数据一致性。当所有时间片迭代完成后,节点的分块计算结果下载到客户端拼接,得到最终的汇流计算结果。
在一个更为具体的实施方式中,本发明具体内容包括两个方面,分布式调度框架和分布式调度的边缘数据交换。
分布式调度框架
分布式调度框架分为客户端和服务器端,整体框架结构如图1所示。在应用于径流汇流计算时,该分布式框架可以具体调整为:服务器端由总服务器、节点服务器和分布式文件系统三部分组成,完整框架如图2所示。
总服务器负责接收客户端的命令请求,以分布式文件系统的形式存储管理流域数据。节点服务器承担子块的径流汇流计算。在分布式计算框架下,完整的大数据径流模拟流程如下:
首先,客户端将要计算的流域地形数据上传到分布式文件系统中,然后向总服务器发送径流模拟任务请求;总服务器返回所有可用节点服务器的信息后,客户端筛选出可用节点,并将任务提交给节点服务器;节点服务器根据客户端提交的任务计算某一子块的径流汇流;当节点计算完成后,与相关节点服务器交换边缘数据;所有节点服务器边缘交换完成后,继续下一个时间片的迭代计算,直至所有时间片计算完成;最后,客户端将节点计算结果下载后拼合得到最终汇流结果。
分布式调度的边缘数据交换
一、边缘数据交换的必要性
(1)分布式计算的分块方案
在流域汇流计算时,网格单元为基本的并行计算单元,其水深和流速预测值由它和相邻8领域网格的当前水深和流速计算得到。在通用计算中,纹理的一个像元为汇流计算的网格单元。为保证流域分块计算结果的正确性,每一个分块纹理需要在上、下、左、右四边多读取一行或一列网格像元。图3为分块内部像元和边缘像元示意图。假定分块大小为5行5列,则左上角第一块实际大小为6行6列。其中,右侧和下侧均从地形、水深或水速栅格文件中多读取一层边缘数据。在分块径流模拟时,实际计算的像元为内部像元,边缘像元仅用于其相邻的内部像元水深或水速计算。
(2)边缘数据交换的必要性
如果仅需对流域做一次全图计算,则直接读取节点的内部像元并在客户端拼接即可得到完整的流域模拟结果。但径流汇流是一个在时间上不断迭代的过程,上一时间片的水深和水速成为下一时间片水深和水速生成的依据。
在迭代计算情况下,每一个时间片分块计算完成后必须先交换边缘数据再执行下一时间片的汇流计算,否则不能得到正确的结果。这是因为,每一个分块只负责内部像元的计算,其边缘像元由相邻分块计算得到。
二、边缘数据更新策略
边缘数据更新是指在每一帧径流汇流计算完成后,每一分块从相邻块读取更新后的边缘数据。设分块编码为(x,y),则该分块需要从相邻分块(x-1,y)、(x,y-1)、(x+1,y)、(x,y+1)、(x-1,y-1)、(x+1,y-1)、(x-1,y+1)、(x+1,y+1)读取对应的边缘数据。边缘数据更新策略如表1所示。
表1
从表1可见,如果内部分块在四个方向上同时存在边缘数据,则需要从相邻的8个分块中读取边缘并更新。其中,上、下、左、右相邻分块读取一行或一列;其余相邻分块则需要读取一个像元。
虽然每一个时间片均要求交换边缘数据,但相对于单台计算机GPU分块策略交换全部分块数据而言,其数据交换量非常小。以分块大小为4096*4096为例,并假定四个边缘均存在边缘更新,其数据交换量仅为分块全部数据量的1/1024。从理论上说,如果局域网网速较快,分布式径流模拟效率相对于单台计算机GPU分块,具有更好的性能。
三、分布式框架下的边缘数据更新
分布式计算旨在将大流域划分成多块数据,让计算机集群分而算之。通常情况下,客户端向服务器发送径流模拟请求任务,服务器计算完成后将结果返回给客户端汇总。在分布式径流模拟迭代计算场景中,边缘数据更新有两个关键环节。其一,下一帧径流模拟计算时,边缘数据需要从相邻块数据块读取,而相邻块的计算在不同的节点服务器上,因而相邻块之间的边缘交换转变为不同计算节点之间数据变换;其二,节点的计算在显卡中完成,节点内部显存和内存的边缘数据交换是边缘数据更新的另一个环节。
(1)计算节点的边缘数据交换
计算节点的边缘数据交换,可以尝试两种不同的方式来实现:
A、节点为中心的数据交换方案
在该方案中,每一个节点不仅记录分块位置,还建立了相邻分块的网络连接。节点完成单帧径流汇流后,按表1所示分别读取各边缘,并将边缘数据发送给相邻分块的计算节点。每一个节点接受到所有边缘的更新数据后,进入下一个时间片的汇流计算。
节点为中心的数据交换方案,优点在于每一个节点单帧计算网络流量与分块大小有关,与流域大小无关,缺点是该方式的网络交换次数较多。
B、客户端为中心的数据交换方案
客户端为中心的数据交换,将客户端作为边缘数据聚合中心。节点完成径流汇流后,直接读取四个边缘的行列数据,一次性传输给客户端。客户端接受到所有节点边缘数据后,将各节点所需的新边缘数据一次性发送给节点服务器。
客户端为中心的数据交换方案在一个时间片的径流汇流过程中,需要的网络通讯总次数等于分块数的2倍,相对于第一种方案,减少了总的网络通讯次数,但该方案的客户端网络传输压力较大。
原则上,两种交换方式均能够适用于本申请的技术方案之中,可通过不同的需要进行选择,或者采用两种方案相结合的方式来应用。
(2)显存和内存的边缘数据读取和更新
数据节点通过内存的方式在网络上交换边缘数据。当节点的分块数据计算完成后,将边缘数据从显存读回内存,并通过网络传输到相邻计算节点或客户端;当节点接收到新边缘数据后,数据存储在内存,将其更新到显存后才能进行一个时间片的径流汇流。
性能测试
为了验证通用计算框架下流域径流模拟分布式调度方法的效率,在局域网环境下(5M/s)进行测试。测试时选择8台配置相近的计算机,其中使用INTEL的酷睿系列CPU和NVIDIA的GTX系列GPU。选取两种规模的流域,其大小分别为3225*5325(小流域)、6450*10646(大流域)。在分块策略中,2节点和4节点分块数为4,8节点分块数为8。迭代次数分别为100、200、400次情况下的累积耗时。测试结果见表2所示。
表2
从表2可见,分布式/GPU方法随着在节点数量为4时计算效率最高,是单机分块计算效率的4倍以上。这是因为,当节点数量不足时,节点同时执行多个分块的径流汇流,未能充分体现任务的并行性;当节点数量过多,分块划分更细时,需要交换的边缘数据量也在不断增大,从而导致性能下降。因此,分布式径流汇流最佳分块策略是将流域划分为单台计算机能接受的最大分块尺寸并交于相等节点计算,每一个节点只负责其中一个分块的计算。
从流域规模上分析,分布式调度不适合小范围流域径流模拟。主要原因在于,小范围径流模拟在单台计算下足以完成,而在分布式框架下,额外增加了网络通信、网络传输的时间。当计算量超过单台计算机时,分布式/GPU方法不仅能计算大范围流域径流模拟,而且随着数据量的增大,计算效率还有一定的提升。
综上所述,通用计算框架下径流模拟分布式调度方法很好地解决了大流域的径流汇流通用计算问题,对于流域实时径流汇流模拟具有重要的应用价值。
实施例2:
本实施例为一优选的实施方式,即为进一步提高径流汇流模拟计算中,采用分布式方式进行数据处理的计算效率及精度,将流域数据进一步进行并行化的处理。具体可采用如下的优选实施方式:
为提高径流汇流模拟精度,采用分布式水文模型。首先依据一定的空间分辨率将流域划分为面积大小相等的网格集合;在此基础上,将径流汇流过程划分为时间间隔相等的时间片。每一个时间片以网格为单元进行汇流计算。通过时间片的迭代,完成流域径流汇流的过程模拟。
考虑到分布式水文模型计算量大,CPU计算性能低,引入通用计算以提高计算效率。通用计算支持下的径流汇流模拟要求在一个时间片上各网格单元的径流汇流结果对其他网格单元没有影响,即网格单元的径流汇流计算的可并行性。为达到该要求,汇流模拟分两步进行,即水量收支和受力计算。每一步均以网格为单元设计算法。
(1)网格单元水量收支的并行化设计
设任意网格单元c,时间片起始时间为tn,终止时间为tn+1,汇流时间为:
At=tn+1-tn (1)
在时间片上,首先计算网格单元的水量收支。设tn时刻的网格水深为时间片上的降水量、下渗量、蒸发量、流入量和流出量分别为和依据水量平衡原理,tn+1时刻的网格水深为:
在栅格模式下,和仅考虑与周围的8邻域网格单元的水量交换。设网格单元c的邻域像元为b,为网格b水流流入网格c的速度分量,ΔL为网格b和网格c的中心距离,则流入量为:
设为网格c水流流入网格b的速度分量,则流出量为:
网格单元与8邻域水量交换过程中,满足动量守恒定律。设和分别表示网格c初始水速和终止水速,则有:
(2)网格单元受力计算的并行化设计
网格单元的水体受到多种内外力的影响。水流随速度的迁移过程中,由于水压不同产生水流内部的压力梯度力;由于地表水流在坡面上或河床上流动,地表径流除受到重力作用外,还存在地表摩擦力、相邻水团的作用力等。
以中心网格和邻域网格水体高度差来模拟水体在重力和压力梯度的作用下产生的速度增量。设网格c和邻域网格b的地形高度分别为HC和Hb,则邻域网格相对于中心网格的水体高度差ΔWbc为:
其速度增量Δvbc在水平x和y方向的分量为:
其中,K为综合压力梯度、重力及相邻水团作用等因素的水力加速度常数,dx和dy为网格b和网格c在x和y方向的坐标之差。
地表水流由于受到河床摩擦力的影响,使水流速度发生衰减。设在单元网格上摩擦力作用的上界深度Wmax,下界深度为Wmin,衰减系数ε近似定义为:
其中,σ为摩擦比例常数,由具体流域特征确定。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!