一种基于时频局部能量的特征点的音频检索方法和系统与流程
本发明属于计算机应用领域,涉及一种基于时频局部能量的特征点的音频检索方法和系统。
背景技术:
随着互联网的飞速发展,特别是多媒体技术和网络技术的发展,互联网信息呈现爆炸式地增长。根据数据公司IDC统计,近年来全球的数据量每年增加超过50%,并且增长速度仍在加快,预计到2025年内互联网数据量会超过40ZB。其中音频数据占有很大的一部分,如何能够快速、有效地在现有的互联网海量音频信息中检索到用户需要的内容,是很急迫需要解决的问题。
传统的音频信息检索技术需要对音频信息进行人工标注,但人工标注不仅会造成标注信息的错误,这样就会对音频检索造成错误,而且在面对海量的互联网音频信息,也会消耗大量的人力物力资源,所以传统的基于文本的音频信息检索无法满足人们对音频检索的需求。也就是说,如果用户听到一段很熟悉的音频,想通过录制几秒钟的片段来查询整段音频的信息,目前在技术上仍然存在较大的实现难度。
基于音频的样例检索,指的是用户输入从原始音频截取的片段或者通过麦克风重新录制一段音频片段,这些片段中可能含有各种噪声,系统能正确返回音频片段的相关信息。
目前互联网上的音频信息检索主要是基于文本搜索的,是通过匹配音频相关标注文字的信息而返回给用户结果。而人工标注不仅会造成标注信息的错误,这样就会对音频检索造成错误,而且在面对海量的互联网音频信息,也会消耗大量的人力物力资源,是不可取的方法。要想对录制的音频片段进行搜索,就涉及到基于内容的样例音频检索。而现有的音频检索技术尚不能满足人们的需求。而互联网上的音频信息主要包括语音、音乐等,基于音乐的样例检索技术已经发展比较成熟,有许多商用的系统,比如Shazam、网易云音乐的听歌识曲等,但基于语音的样例检索技术还在处于发展阶段,有一些音频检索系统,但现有的语音检索的系统主要基于语音识别技术,在安静的环境下基本上达到了很好的检索效果,但是其处理速度依然有限,其算法的复杂程度在处理海量语音数据的时候依然比较困难,并且需要大量的人工标注,而基于样例的音乐检索系统中,其理论的处理速度比基于语音识别的系统要快的多,使得其有可能处理海量的互联网音频数据。而且现在的音乐和语音检索使用的是两套算法两套系统,使用起来不是很方便,如果对于语音的检索取得较好的效果,那么使得语音检索和音乐检索能够在同一个系统中得到应用,而不需要两套系统两套算法。
基于音频的样例检索,通常可以分为两个子问题:(1)把查询的音频片段转为具有代表性的特征序列组成音频指纹(音频指纹是指能代表一段音频并能构建索引的特征序列);(2)在库中搜索与音频指纹最相似的候选片段。比较经典的音乐检索方法是英国的shazam公司,提取频谱峰值信息,然后将特征点组成特征点对,把特征点对作为该片段的音频指纹,搜索时候建立哈希索引实现快速搜索。此方法的特点是不需要保留频谱的全局信息,特征具有代表性,在海量的数据库中有比较快的检索速度,缺点是鲁棒性还需要加强,在很强的噪音下查询的精确率会下降很多。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于时频局部能量的特征点的音频检索方法和系统,通过录制的原始音频片段(或者从原始片段中截取的音频片段)搜索到整个音频的完整信息,有效解决音乐、语音需要两套算法两套系统的问题,在对于海量音频数据库,有效提高音频检索的检索正确率、检索效率以及抗噪声性能。
为达到上述目的,本发明提供如下技术方案:
一种基于时频局部能量的特征点的音频检索方法,该方法对于音频数据库中的每一首音频,先进行重采样、预加重和加窗处理的预处理,然后再提取时域局部能量很突出的点作为特征点,用特征点匹配成音频指纹,利用音频指纹构建数据库索引;对于样例查询的音频片段,也是先进行重采样、预加重和加窗处理的预处理,然后再提取时域局部能量很突出的点作为特征点,用特征点匹配成音频指纹;在线的音频指纹在数据库索引中进行候选查询,找出候选的音频,然后对候选的所有音频进行相似度计算;对得出的所有相似度进行排序,输出相似度最高的音频以及音频的信息;
具体包括以下步骤:
S1:基于语谱图的矩形局部能量比值特征,提取音频数据库稳定的特征点;
S2:根据音频数据库稳定的特征点匹配成特征点对,即音频指纹;音频指纹对比单个的特征点对,具有信息的区分性,减少信息之间的碰撞;
S3:构造哈希索引表,把得到的音频指纹通过指纹哈希函数转换成哈希索引表的关键字,通过哈希索引把关键字存于哈希索引对应的内存之中;键为关键字,值为音频指纹所在音频文件名以及在音频文件中的位置;
S4:基于语谱图的矩形局部能量比值特征,提取用户输入样例音频片段的频谱特征点;
S5:根据样例音频片段的频谱特征点匹配成特征点对,即音频指纹;
S6:把所有得到的音频指纹通过哈希索引表,进行音频指纹的匹配;
S7:返回给用户目的音频的具体信息。
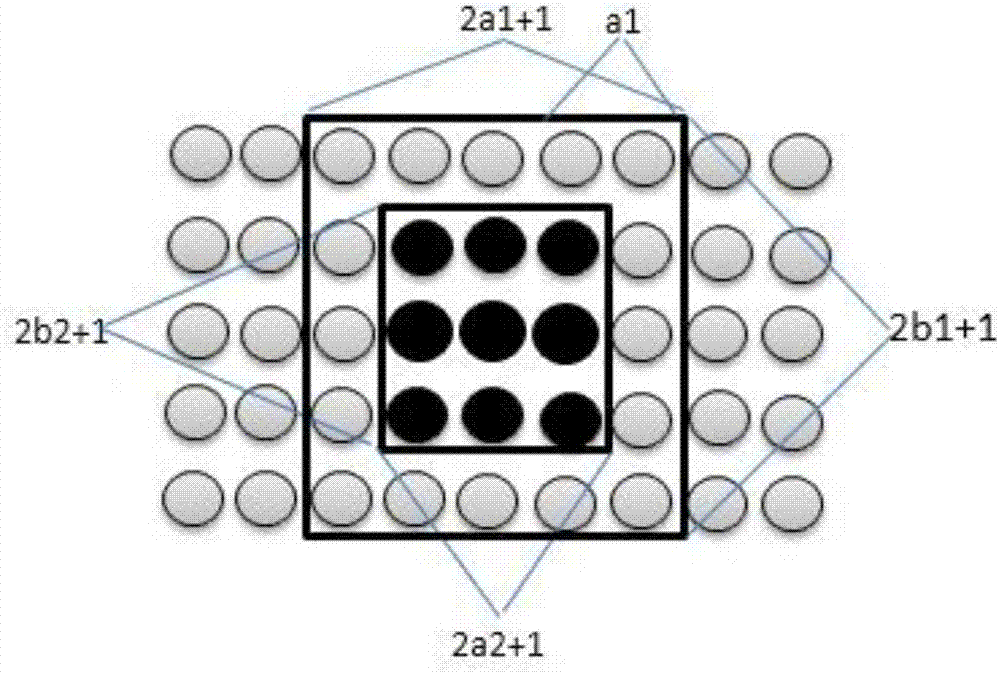
进一步,所述语谱图的矩形局部能量比值为Er,即以一个点为中心,其坐标值看作(k,k),设置大小两个矩形区域,大小分别为(a1,b1)和(a2,b2),用大矩形区域内点的能量值之和除以小矩形区域内点的能量值之和,得到的比值是能量比值Er;当一个点的Er大于等于某一阈值时,则认为该点是特征点;提取的坐标点为特征点的公式为:Er≥T0;T0为阈值。
一种基于时频局部能量的特征点的音频检索系统,包括离线音频数据库处理模块和在线检索模块;
所述离线音频数据库处理模块包括:音频数据单元101、音频指纹提取单元102和哈希索引库103,用于实现:
(1)基于语谱图的矩形局部能量比值的特征,提取音频数据库稳定的特征点;
(2)根据音频数据库稳定的特征点匹配成特征点对,即音频指纹;音频指纹对比单个的特征点对,具有信息的区分性,减少信息之间的碰撞;
(3)构造哈希索引表,把得到的音频指纹通过指纹哈希函数转换成哈希索引表的关键字,通过哈希索引把关键字存于哈希索引对应的内存之中;键为关键字,值为音频指纹所在音频文件名以及在音频文件中的位置;
所述在线检索模块包括:样例音频片段单元104、音频指纹单元105,哈希索引表匹配查找单元106和命中的第一个结果返回单元107,用于实现:
(1)基于语谱图的矩形局部能量比值特征,提取用户输入样例音频片段的频谱特征点;
(2)根据样例音频片段的频谱特征点匹配成特征点对,即音频指纹;
(3)把所有得到的音频指纹通过哈希索引表,进行音频指纹的匹配;
(4)返回给用户目的音频的具体信息。
用户通过移动设备输入从原始音频截取的片段或者通过其他形式重新录制一段音频片段,这些片段中含有噪声,移动设备把接收到的音频片段上传后台服务器,服务器对音频片段进行音频指纹提取,然后离线与已经构造好的哈希索引表中的指纹进行匹配,得到一个目的音频以及音频的信息,服务器把得到的音频信息传给移动设备,显示给用户。
本发明的有益效果在于:
(1)本发明可以让音乐、语音等海量的数据集成在一个数据库中,只需要一套系统就能检索出用户所需要的音频信息,而不是把音乐、语音分开来进行检索。
(2)本发明和现有的shazam系统相比,有更好的鲁棒性,在噪声情况下有更好的检索准确率。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明系统框图;
图2为基于时频域内局部能量最突出的点的特征提取图;
图3为检索方法流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
本系统由两个部分组成,分别是离线构造音频指纹索引库和在线检索出目的音频。
为了实现上述发明目的,一种基于语谱图的矩形特征点的音频检索方法,其在线检索模块包含的步骤:
(1)提取用户输入样例音频片段的频谱特征,其特征是基于语谱图的矩形局部能量比值的特征;
(2)根据特征点匹配成特征点对,称为音频指纹。音频指纹对比单个的特征点对,具有信息的区分性,减少了信息之间的碰撞;
(3)把所有得到的音频指纹通过哈希索引表,进行音频指纹的匹配;
(4)返回给用户目的音频的具体信息。
其中,离线音频数据库处理模块包含以下几个步骤:
(1)对音频数据库提取稳定的特征点,其特征是基于语谱图的矩形局部能量比值的特征;
(2)根据特征点匹配成特征点对,也就是音频指纹;
(3)构造哈希索引表,把得到的音频指纹通过指纹哈希函数转换成哈希索引表的关键字,通过哈希索引把关键字存于哈希索引对应的内存之中。键为关键字,值为音频指纹所在音频文件名以及在音频文件中的位置。
用户通过移动设备输入从原始音频截取的片段或者通过其他形式重新录制一段音频片段,这些片段中可能含有各种噪声,移动设备把接收到的音频片段上传后台服务器,服务器对音频片段进行指纹提取,然后离线与已经构造好的哈希索引表中的指纹进行匹配,匹配会得到一个目的音频以及音频的信息,服务器把得到的音频信息传给移动设备,显示给用户。
本发明所提供的基于语谱图的矩形特征点的音频检索方法,在提取特征点的过程中使用了局部能量最优点作为特征点,更具有代表性,有更好的鲁棒性,在噪声情况下有更好的检索准确率。用本发明的方法,对于1000小时的音频数据库(其中包含700小时的歌曲,100小时的CCTV电视节目,200小时的电视剧),当样例片段为原始音频中截取的10s片段时,可以达到97%的检索准确率。
实施例:
如图1所示,为本发明的实施例的系统框架图,包括离线音频数据库处理模块和在线检索模块。离线音频数据库处理模块包括:对于数据库中的音频数据单元(单元101),基于语谱图的矩形特征提取,形成音频指纹提取(单元102),然后使用音频指纹构建哈希索引库(单元103)。在线处理模块包含:对于输入的样例音频片段(单元104),提取基于语谱图的矩阵局部能量最大值的特征点,组成音频指纹(单元105),然后和离线构建的哈希索引表进行匹配查找(单元106),最后返回命中的第一个结果给用户(单元107)。
结合图2、图3,说明本发明实施例中所提供的基于语谱图的矩阵局部能量最大值的特征点的音频检索方法:
在基于样例的音频检索中,都是先对音频数据经过处理,提取音频特征。目前最常见的音频数据都是PCM编码的WAVE格式波形文件,其他格式一般都很容易通过软件转换为WAVE格式波形文件。因此,本实施例中,音频库和用户录制片段均采用WAVE格式波形文件。
这种提取的音频特征要具有代表性,能唯一代表这段音频,并且抗噪性能要强,当有环境噪声时,特征仍然保持不变或者较小的变化。Shazam的原始算法提取特征点是基于频域的能量峰值点。它首先是使用傅里叶变换的方法把音频信号的时域转换成频域,对于频域中能量值大小,以每一帧为单位提取峰值能量特征点的。首先设置一个能量阈值,每一帧中的能量大于阈值的点保存下来,把这些点进行大小排序,取前五个能量最大点为这一帧的峰值能量点。
但是Shazam原始算法是考虑每一帧的峰值点,没有考虑如何选取局部能量最突出的特征点。而有些点的能量在这一帧上不是最突出的,不能作为特征点,但是在一定的区域内是能量最突出的点。本发明所用的的特征提取算法是基于时频域内能量最突出的点作为特征点的。
如图2所示,水平方向代表帧的个数,竖直方向代表频域变换范围,本文采用的音频是16K采样,每一帧是32ms,那么每一帧有512个点。对于每一个点,都可以计算它的能量比值Er。
公式(1)描述的计算方法是:以一个点为中心,其坐标值看作(k,k),设置大小两个矩形区域(大小矩形区域可随实际情况变化,阈值随矩形大小的变化而变化),大小分别为(a1,b1)和(a2,b2)。如图2,用大矩形区域内点的能量值之和除以小矩形区域内点的能量值之和,得到的比值是能量比值Er。当Er大于等于某一阈值时,认为该点是特征点。提取的坐标点为特征点的公式如下:
Er≥T0 (2)
根据上述公式(1)(2),把时频域类最突出的点作为特征点。这样提取出的特征点,具有比原来更高的检索准确率,在噪声情况下更具有鲁棒性。
利用图3所示的检索方法流程图,形象的说明本方法的检索过程。本方法主要包括左半部分的离线建立数据库索引过程和右半部分的在线查询过程。整体流程,主要包括两个部分:(1)建立离线数据库索引;(2)在线样例片段的检索。具体描述如下:
(1)离线建立数据库索引:对于数据库中的每一首音频(模块201),先进行重采样、预加重和加窗处理等预处理(模块202),然后再提取时域局部能量很突出的点作为特征点,(模块203),用提取的特征点匹配成音频指纹(模块204),利用音频指纹构建数据库索引(模块205)。
(3)在线样例片段的检索:
步骤1:样例音频片段(模块206),先进行重采样、预加重和加窗处理等预处理(模块207),然后再提取时域局部能量很突出的点作为特征点(模块208),用提取出来的特征点匹配成音频指纹(模块209)。
步骤2:在线的音频指纹(模块209)在数据库索引(模块205)中进行候选查询,找出候选的音频,然后对候选的所有音频进行相似度计算(模块211)。
步骤3:得出的所有相似度进行排序(模块212),输出相似度最高的音频以及音频的信息。
为了验证此方法的有效性,本发明人以1000小时的音频为例,包含700小时的歌曲,100小时的CCTV电视节目,200小时的电视剧。其中100小时CCTV电视节目、200小时电视剧均切割为5分钟时长的音频。测试数据时从1000小时的音频库中随机抽选的1000首音频片段,然后随机截取长度为10秒的音频片段,并截取10秒片段的前5秒、6秒、8秒共四种不同时长的片段为做测试音频1;并在嘈杂的室外环境对测试音频片段1进测重新的录制,作为测试音频2,测试结果如下:
表1测试音频1的测试结果
表2测试音频2的测试结果
从表1和表2可以看出来,以10秒的片段为基准,本方法在毫秒级别内达到了令人满意的检索准确率,并且在相当嘈杂的室外环境下,也有比较好的检索准确率和检索速度。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!