一种基于数据划分的电力负荷曲线层次聚类方法与流程
本发明涉及电网领域,尤其是一种电力负荷曲线的聚类方法。
背景技术:
随着需求侧响应概念的提出,用户侧资源逐渐受到学术界和工业界的重视。用户侧负荷资源能否参与能源互联网供需调节,对整个电力系统的安全稳定运行有重要意义。电网中用户的细分,对制定精准的激励政策,以使用户侧资源参与到电网的供需调节中显得至关重要。负荷曲线作为电力用户最重要的特征,通过用户负荷曲线聚类分析,提取用户用电的负荷模式,对于深刻把握用户用电规律、评估用户需求响应潜力、指导电价制定和制定需求响应激励机制等具有重要意义。
由于需求侧响应概念在近几年才被提出,电力用户用电数据也在近几年逐渐丰富起来,因此,通过电力负荷曲线聚类,挖掘用户用电模式,成为很多学者研究的热点问题。研究伊始,关于负荷曲线聚类的研究都集中在用基本的聚类算法对其聚类,但随着数据规模的不断增大,仅仅用简单的聚类算法会导致聚类时间太长,聚类质量不高,而使得负荷曲线聚类问题成为难求解的问题;在近两年,有学者将两种基本聚类算法结合,来提高聚类质量,降低聚类时间,并且大多数将两种聚类算法相结合的研究都是将k-means算法与另一种算法相结合,但由于k-means算法初始聚类中心的随机性,导致聚类结果是不可重复、不稳定的,同时,两种聚类算法的结合也会增加时间成本;也有学者将降维技术应用到聚类算法中,但不管是利用那种降维技术都会减少原始数据中的部分信息,从而导致聚类的不准确性。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于数据划分的电力负荷曲线层次聚类方法。本发明基于聚类有效性评价函数dbi,针对更大规模的电力负荷曲线数据,运用基于数据划分的层次聚类算法对其聚类,同时运用设置阈值的方式进一步减少聚类时间;由于本发明运用的基本聚类算法是层次聚类算法,因此在对负荷曲线进行聚类之前,需进行数据的预处理,特别是离群值的处理。
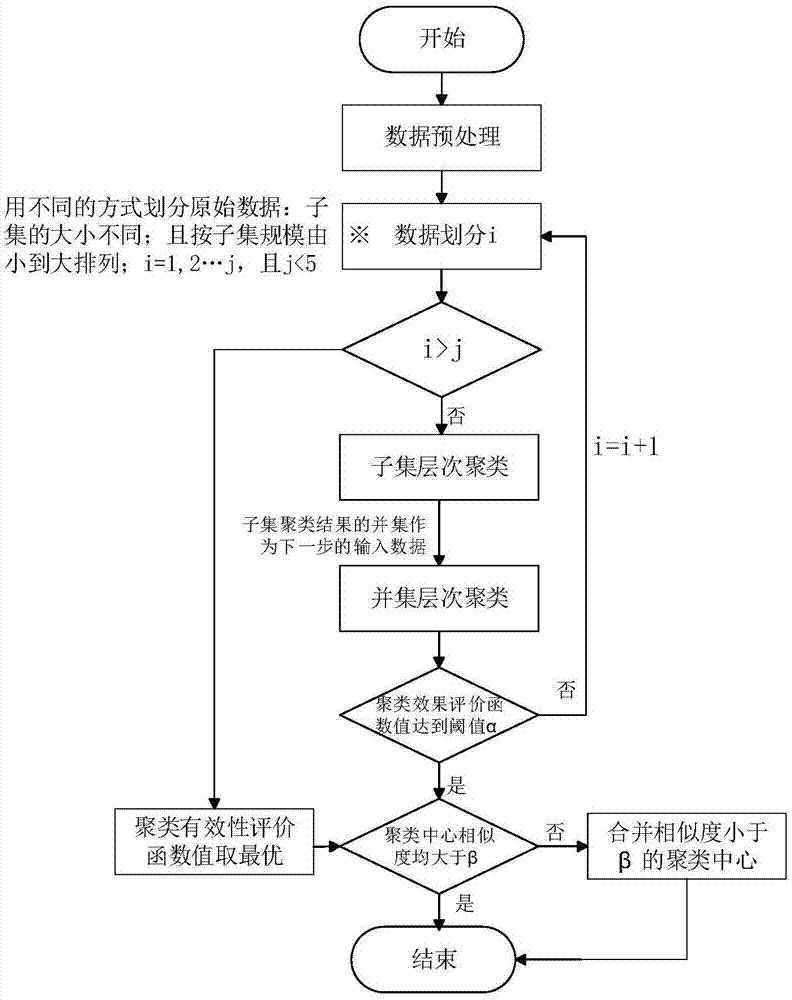
本发明解决其技术问题所采用的技术方案的详细步骤如下:
步骤1:进行数据预处理
假定每条负荷曲线有n个记录,先对原始负荷曲线做如下剔除处理:剔除存在负值记录的负荷曲线,剔除存在空值记录的负荷曲线,剔除n个记录中全部为0值的负荷曲线,经过三种剔除之后,剩余m条负荷曲线,计算每条负荷曲线到其他m-1条曲线的距离,计算公式如下:
其中,dx表示第x条负荷曲线与其他m-1条曲线的距离之和,fxj和fij分别表示第x条曲线和第i条曲线的第j个负荷记录,x,i=1,2,...,m,j=1,2,...,n,以所有m个距离值为输入数据,利用箱线图方法识别离群值;在箱线图中,用处于箱子上边缘和下边缘的曲线分别代替上边缘以上和下边缘以下的曲线,即获得离群值;
步骤2:数据划分
将m个负荷曲线集合划分为y种子集规模不同的集合群,按照子集的规模由小到大排序,依次为s1,s2,…sl,…sy;
步骤3:对sl中每个子集用havg层次聚类算法聚类,其中,l=1,…,y;将每个子集分别聚为2-8类,选择戴维森堡丁指数(davies-bouldinindex,dbi)最小的聚类结果作为该子集的聚类结果;
步骤4:求每个子集聚类中心的并集,并对该并集运用havg算法进行聚类;
步骤5:运用聚类效果评价函数dbi对步骤4的聚类效果进行评价,当dbi的值达到阈值α时,进入步骤6;若未达到该阈值,则重复步骤3,同时步骤3中的l加1,直至dbi的值达到阈值;当l=y,则将步骤2所得到的所有划分中dbi值最小的聚类结果作为步骤5的最终聚类结果,同时进入步骤6;
取dbi指数的最低值为γ,阈值α的取值范围为2γ>α>γ;
步骤6:合并步骤5得到的聚类结果中聚类中心距离小于阈值β的簇,以各聚类中心之间的距离作为箱线图的绘制数据绘制箱线图,β为箱线图的下边缘处的值,聚类中心的计算方式如下所示:
式(2)中,cw为第w个簇的聚类中心,v表示该簇所包含的曲线数量,xi为第w个簇中的第i条负荷曲线;
至此,得到了与步骤5不同的新的聚类结果;
步骤7:将步骤5和步骤6得到的聚类结果的dbi值进行比较,dbi值小的聚类结果作为最终的聚类结果。
步骤6中所述合并为在聚类结果中,簇l和簇h的聚类中心距离如小于阈值β,将簇l和簇h中的负荷曲线合并为一个新簇g,并更新聚类结果,即保留新簇g,删除簇l和簇h。
本发明的有益效果在于由于采用了将整体数据划分为若干子集再分别聚类的方法,将电力负荷曲线的聚类时间大幅度缩短,以900条数据为例,基于数据划分的层次聚类算法较传统层次聚类算法聚类时间降低了约79%;且多次实验表明,当以dbi指数评价聚类质量,基于数据划分的层次聚类算法总体上较传统层次聚类算法的聚类质量提高了约3%。
附图说明
图1是本发明基于数据划分的电力负荷曲线层次聚类算法流程图。
图2是本发明不同算法基于a、b两组数据的dbi指标和聚类数的关系示意图。
图3是本发明实施例中10523条工业电力用户负荷曲线聚类结果。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
随着电力负荷数据量和数据维度的增加,传统的聚类方法在聚类时间和聚类质量的均衡上已不能满足电力负荷曲线聚类的要求,因此,本发明旨在在不减少原始信息量的条件下,进一步降低聚类时间,同时满足聚类质量的要求。
如图1所示,本发明的详细步骤如下:
步骤1:进行数据预处理
假定每条负荷曲线有n个记录,对原始负荷曲线做如下剔除处理:剔除存在负值记录的负荷曲线;剔除存在空值记录的负荷曲线;剔除n个记录中全部为0值的负荷曲线,经过三种剔除之后,剩余m条负荷曲线,计算每条负荷曲线到其他m-1条曲线的距离,计算公式如下:
其中,dx表示第x条负荷曲线与其他m-1条曲线的距离之和,fxj和fij分别表示第x条曲线和第i条曲线的第j个负荷记录,x,i=1,2,...,m,j=1,2,...,n,以所有m个距离值为输入数据,利用箱线图方法识别离群值;在箱线图中,用处于箱子上边缘和下边缘的曲线分别代替上边缘以上和下边缘以下的曲线,即获得离群值;
在数据预处理时,不能进行归一化处理,否则不同负荷水平,相同负荷曲线形状的负荷曲线之间的差异将不再明显;
步骤2:数据划分
将m个负荷曲线集合划分为y种子集规模不同的集合群,基于时间因素的考虑,每个子集的数据量控制在200-500条,将所有数据划分为y种子集,按照子集的规模由小到大排序,依次为s1,s2,…sl,…sy;
该步骤的主要目的便是降低聚类时间,不管是划分子集,控制子集大小还是将子集按顺序排列,都是为了缩短聚类时间;
步骤3:对sl中每个子集用havg层次聚类算法聚类,其中,l=1,…,y;将每个子集分别聚为2-8类,选择戴维森堡丁指数(davies-bouldinindex,dbi)最小的聚类结果作为该子集的聚类结果;
步骤4:求每个子集聚类中心的并集,并对该并集运用havg算法进行聚类;
步骤5:运用聚类效果评价函数dbi对步骤4的聚类效果进行评价,当dbi的值达到阈值α时,进入步骤6;若未达到该阈值,则重复步骤3,同时步骤3中的l加1;当l=y,则将步骤2所得到的所有划分中dbi值最小的聚类结果作为步骤5的最终聚类结果,同时进入步骤6;
取dbi指数的最低值为γ,阈值α的取值范围为2γ>α>γ;
步骤6:合并步骤5得到的聚类结果中聚类中心距离小于阈值β的簇,以各聚类中心之间的距离作为箱线图的绘制数据绘制箱线图,β为箱线图的下边缘处的值,聚类中心的计算方式如下所示:
式(2)中,cw为第w个簇的聚类中心,v表示该簇所包含的曲线数量,xi为第w个簇中的第i条负荷曲线;
至此,得到了与步骤5不同的新的聚类结果;
该步骤是为了防止在实际应用中,可以被当做同一类进行分析的数据,被分成两类,从而加大在随后的实际情况分析中的工作量;
步骤7:将步骤5和步骤6得到的聚类结果的dbi值进行比较,dbi值小的聚类结果作为最终的聚类结果。
步骤6中所述合并步骤为:
在聚类结果中,簇l和簇h的聚类中心距离如小于阈值β,将簇l和簇h中的负荷曲线合并为一个新簇g,并更新聚类结果,即保留新簇g,删除簇l和簇h。
本实施例采用取自某生态城工业电力用户的10523条日负荷曲线(该数据集合为在初始数据集上剔除负值、零值和离群值的剩余数据),日负荷曲线的采集间隔时间为15min,每条数据共计96个数据点。在本部分实验中,α和β均取值分别为0.8和0.2,划分子集的大小分别为200、300、500,在最先运行的子集大小为200的划分中,dbi的值为0.7247<0.8,因此子集大小为300和500的划分均未运行,聚类时间为1065.6s,聚类结果如图2所示。
由图可知,该生态城有4条典型的日负荷曲线。其中两条日负荷曲线分别在不同负荷水平趋于平稳,一条曲线在一天当中的早上十点和晚上八点之间达到高峰,还有一条曲线在晚上十点和早上十点之间达到高峰。因此,可以针对该生态城中负荷有所波动的工业电力用户,为其制定相应的激励政策,使其参与到电网供需平衡的调节中。
如图2所示,该实验采用a和b两组数据,数据集a和b分别为两家不同工业用电单位一年(365天)中349天的日负荷曲线(剔除了因未采集到数据而全部显示为0的16天的数据),日负荷曲线的采集从当日00:00开始,间隔时间为15min,每条数据共计96个数据点。基于k-means、hmin、hmax、havg和hcen五种算法,对349条负荷曲线聚类分析。其中,由于k-means算法受初始聚类中心的影响较大,因此在本实验中,通过对k-means算法运行100次,取其最小值来确定它的聚类效果。基于dbi指标对五种算法进行评价,图2(a)和图2(b)分别是基于数据组a和b的实验结果。
根据簇之间邻近性的定义方式不同,凝聚层次聚类分为hmin、hmax、havg、hward和hcen。其中hmin定义簇的邻近度为不同簇的两个最近的数据之间的邻近度;hmax定义簇的邻近度为不同簇的两个最远的数据之间的邻近度;havg定义簇的邻近度为所有数据对邻近度的平均值;hward定义簇的邻近度为两个簇合并时导致的平方误差的增量;hcen定义簇的邻近度为两个簇的质心的邻近度。由于当两个数据之间的邻近度取它们之间距离的平方时,hward和havg两种方法非常相似,因此,在这里我们仅比较研究hmin、hmax、havg和hcen四种方法。而k-means算法是划分聚类算法的典型代表。
由图2可知,在这五种算法中,havg的聚类效果相对比较稳定,且质量较好,并且在以dbi为评价指标时,dbi的极小值点可以很容易找到,即聚类数量很容易确定,数据集(a)聚类数为3时聚类效果最好,数据集(b)聚类数为5时聚类效果最好;hmin算法的聚类效果最好,但其极值点不易找到,从而,聚类数不易确定;k-means算法和hmax算法的聚类质量相对较差。
表1基于数据划分的havg算法与传统算法的比较
在本部分的实验中,随机选择某生态城工业电力用户的900条数据开展实验。表1是运用传统havg算法、k-means算法和基于数据划分的havg算法分别聚类的聚类结果展示(标题为avg的行表示五次计算的均值)。在基于数据划分的层次聚类算法中,分别将900条数据平均划分为2、3、4个子集,每种划分得到的子集分别包含450、300、225条数据;运用基于数据划分的层次聚类算法进行聚类,由于这个新方法探索阶段的实验,因此没有运用阈值限制运行时间,而是将所有划分都运行之后才得出聚类结果。图3为本实施例中10523条工业电力用户负荷曲线聚类结果。
由表1可知,基于数据划分的havg算法相较于传统havg算法,运行时间大大减少,且dbi指标的值相差无几,甚至更好;havg算法和基于数据划分的havg算法相较于k-means算法运行时间较长,但dbi指标大幅度降低,同时,基于数据划分的havg算法的聚类时间在可接受范围内。
- 还没有人留言评论。精彩留言会获得点赞!