一种基于深度学习的表情分类及微表情检测的方法与流程
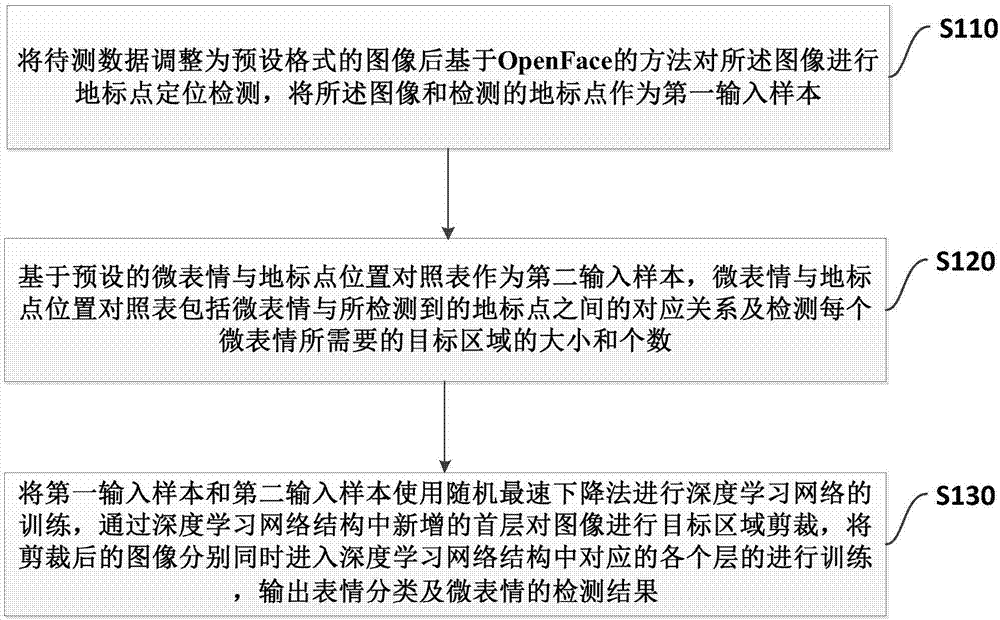
本发明涉及的是一种基于深度学习的表情分类及微表情检测的方法,属于计算机视觉
技术领域:
。
背景技术:
:人们一直在进行针对人脸表情的研究,当前最基础的表情方面的研究为表情分类,将表情分为开心,惊讶,恐惧,伤心,厌恶,愤怒,无表情,这是最基本的一种分类方法。但实际上人的表情远非以上7种表情所能涵盖,更多细微的表情反映出人更多的内心活动,心理学家paulekman和研究伙伴wallacev.friesen做了深入研究创造了面部行为编码系统facs,根据人脸解剖学的特点,根据人脸肌肉的动作,对人脸面部变化划分成了相互独立有相互联系的动作单元au(actionunit),本专利所述微表情采取此定义,即本专利所描述的微表情检测方法是针对au单元的检测方法。paulekman和wallacev.friesen在1978年首发论文《facialactioncodingsystem:atechniqueforthemeasurementoffacialmovement》对facs进行了最初的定义,之后与2002年,paulekman、wallacev.friesen和josephc.hager发表论文《facialactioncodingsystem:themanualoncdrom》对facs进行了一次改进,形成了现在人们使用的面部行为编码系统。在深度学习未得到较广泛应用以前,受制于计算能力,人们更多情况下采用提取人工制造特征的方式进行表情和微表情检测,且此种检测实际上靠分类任务完成,比如提取图像的hog(histogramoforientedgratitude)特征或者cedd(colorandedgedirectivitydescriptor)特征,之后将提取到的特征进行级联或者特征选择、pca(principalcomponentanalysis)降维、级联svm(supportvectormachine)的方式进行表情或微表情有还是无的分类。这种方式所采用的人工特征,在制作的过程中,为了达到比较好的效果,多半伴随着结构复杂、计算量大的特点,并且很多无法有效区分噪声信息和有用信息,在提升抗噪声性的同时将部分有用信息也同时滤除,鲁棒性不强。近年来,在并行计算技术得到发展以后,计算机硬件随之对并行进行的大计算量有了保障,得意于此,深度学习(deeplearning)得到了比较大的发展。深度学习网络(deeplearningnetwork)在计算机视觉的分类、检测、分割等任务上取得了比较大的效果提升。在微表情au检测上,图像方面的深度学习网络——卷积神经网络(convolutionalnerualnetwork,简称cnn)具有特征提取和输出预测结果的功能,卷积神经网络一般由卷积层(convolutionallayer)、激活函数、池化层(poolinglayer)、全连接层(fullyconnectedlayer)、损失层(losslayer)等组成,卷积神经网络的每一层都可以看作是一种特征,名字叫做特征图(featuremap)。对于表情和微表情的检测,现有深度学习技术经过了几个变迁,首先是包含人脸的整张图片输入包含卷积层、池化层、激活函数、全连接层和损失层的卷积神经网络,得到当前图片人脸所表现的表情属于哪一类和包含哪一个微表情的结果。2016年,赵凯莉在《deepregionandmulti-labellearningforfacialactionunitdetection》中提出了对人脸进行区块划分、分块卷积之后再合并的方法,提升了微表情检测的准确率。2017年,weili、farnazabtahi和zhigangzhu在《actionunitdetectionwithregionadaptationmulti-labelinglearningandoptimaltemperalfusing》中提出了根据au单元和人脸区域相对应的位置关系的特性,有目的地提取vgg16网络的conv12(convolutionallayer12,即第12个卷积层)中对应于au单元区域的部分,并采用长短期记忆网络(longshot-termmemory,简称lstm)来将时序信息加入到模型训练的方法,进一步提升了au检测的准确率。当上述方法实际上存在弊端,由于卷积神经网络池化层降采样的作用,高层特征存在感受野(receptivefiled),上述方法所提取conv12层中数据所对应的区域相对于原始输入图片人脸上au的位置并不能完全重合,这会带入噪声并对模型的最终准确率产生负向影响。技术实现要素:针对上述缺陷,本发明提供了一种基于深度学习的表情分类及微表情检测的方法,解决了已有的人工特征方法或者深度学习方法准确率不高的技术问题。本发明基于深度学习,提出了新的深度学习模型,提高了微表情分类和微表情检测的准确率。为达到上述目的,本发明通过以下技术方案来具体实现:本发明提供了一种基于深度学习的表情分类及微表情检测的方法,该方法包括:将待测数据调整为预设格式的图像后基于openface的方法对所述图像进行地标点定位检测,将所述图像和检测的地标点作为第一输入样本;基于预设的微表情与地标点位置对照表作为第二输入样本,微表情与地标点位置对照表包括微表情与所检测到的地标点之间的对应关系及检测每个微表情所需要的目标区域的大小和个数;将第一输入样本和第二输入样本使用随机最速下降法进行深度学习网络的训练,通过深度学习网络结构中新增的首层对图像进行目标区域剪裁,将剪裁后的图像分别同时进入深度学习网络结构中对应的各个层的进行训练,输出表情分类及微表情的检测结果。进一步的,将待测数据调整为预设格式的图像包括:待测数据为图像或视频;若待测数据为视频,将视频拆分为单帧图像。进一步的,基于openface的方法对所述图像进行地标点定位检测,包括:基于openface的方法对图像进行预设尺寸缩放,对缩放后的图像进行面部位置上地标点的检测,地标点以预设符号分隔,通过有序浮点数数组的方式存储。进一步的,深度学习网络结构依次包括:感兴趣区域层和子网络结构;所述子网络结构包括至少一个第一子网络结构和通过拼接层连接的第二子网络结构;所述第一子网络结构包括顺序连接的卷积层、激活层、批量标准化层和池化层共四层的重复以及全连接层、激活层和丢弃层共三层的重复,第二子网络结构包括全连接层、激活层和丢弃层共三层的重复。进一步的,通过深度学习网络结构中新增的首层对图像进行目标区域剪裁的步骤包括:感兴趣区域层基于第二输入样本对第一输入样本中的图像进行目标区域剪裁,得到各个微表情对应的子区域,并将数据输入子网络结构。进一步的,第一子网络结构运行的步骤包括:卷积层对感兴趣区域层输入的图像进行二维卷积运算,将输出的卷积层提取特征数据输入激活层;激活层对卷积层提取特征数据线性激活;线性激活后的激活数据输入批量标准化层;批量标准化层对当前批次的激活数据进行标准化后输入池化层;池化层通过最大值池化对数据降采样,将数据维度压缩降低后,将卷积层、激活层、批量标准化层和池化层运行的步骤按照预设次数重复;通过全连接层将重复完成的数据输入至激活层;激活层对数据线性激活;线性激活后的激活数据输入丢弃层;丢弃层以一定概率将本层中的部分神经元从深度学习网络中丢弃,将全连接层、激活层和丢弃层运行的步骤按照预设次数重复。进一步的,激活层对卷积层输出的特征图进行一次滤波。进一步的,批量标准化层对当前批次的数据进行标准化的步骤包括:当前批次图像共包含batch张图像,图像均包含n个通道,图像像素大小为h×w,设定缩放因子γ,设定平移因子β,设定近0常数ε,设定动量参数m,输入为x,其含义为当前批次本层输入图像的像素值,共有n(n=h×w)个像素,xi,i∈[1,n]表示第i个像素的像素输入值,输出为y,其含义为当前批次本层输出图像的像素值,yi,i∈[1,n]表示第i个像素的输出值,为计算yi,i∈[1,n]过程中的中间变量。s1:计算当前批次n个通道batch张图像的像素均值,得到长度为1×n维的均值向量μ。s2:计算当前批次n个通道batch张图像的像素方差,得到长度为1×n维的方差向量σ。s3:对输入数据进行归一化得到批量标准化的输出结果:进一步的,第二子网络结构的运行步骤包括:通过拼接层将所有第一子网络结构中的数据按照顺序拼接起来;通过全连接层的每一个神经元与拼接层的每一个神经元相连,将数据输入至激活层;激活层对数据线性激活;线性激活后的激活数据输入丢弃层;丢弃层以一定概率将本层中的部分神经元从深度学习网络中丢弃,将全连接层、激活层和丢弃层运行的步骤按照预设次数重复;通过第二子网络结构得到表情分类及微表情的检测结果。进一步的,还包括时序信息模块,用于通过第二子网络结构中第二次重复得到的数据作为输入数据,训练长短时记忆网络,得到表情分类及微表情的检测结果。本发明的有益效果是:通过本发明提供的技术方案,建立新的深度学习层,感兴趣区域层,并建立了新的深度学习网络结构,提取图片的多个指定区域作为感兴趣区域进行有目的性的学习,目的区域的个数和大小可根据需求自由设置,消除了无关区域带来的干扰,同时对于视频或者连续帧形式的图片引入了时序信息提高准确率,增强鲁棒性。附图说明图1所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的实施例一流程图。图2a所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的待测数据调整为预设格式的图像示意图;图2b为检测出地标点的图像示意图;图2c为根据微表情和地标点的位置所选定的目标区域示意图。图3所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的带有部分地标点标号标注的图像示意图。图4所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的深度学习网络结构示意图。图5所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的长短时记忆网络结构示意图。图6所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的长短时记忆网络中采用的街区单元结构示意图。图7所示为本发明提供的一种基于深度学习的表情分类及微表情检测的方法的最终检测结果输出示意图。具体实施方式下面对本发明的技术方案进行具体阐述,需要指出的是,本发明的技术方案不限于实施例所述的实施方式,本领域的技术人员参考和借鉴本发明技术方案的内容,在本发明的基础上进行的改进和设计,应属于本发明的保护范围。实施例一如图1所示,本发明实施例一提供了一种基于深度学习的表情分类及微表情检测的方法,该方法包括步骤s110-步骤s130:在步骤s110中,将待测数据调整为预设格式的图像后基于openface的方法对所述图像进行地标点定位检测,将所述图像和检测的地标点作为第一输入样本。在步骤s120中,基于预设的微表情与地标点位置对照表作为第二输入样本,微表情与地标点位置对照表包括微表情与所检测到的地标点之间的对应关系及检测每个微表情所需要的目标区域的大小和个数。微表情与地标点位置对照表指定两组参数:第一组为微表情与所检测到的地标点之间的对应关系,第二组为检测每个微表情所需要的目标区域的大小和个数,且个数以m标记,第二组参数所指定的个数m可由第一组参数运算得出,仅作为辅助信息。这两组参数作为超参数(超参数指深度学习模型训练之前人工指定的参数,不需要机器通过训练更新)存在,与相应的深度学习模型相对应。图2c所展示的黑色的框,即为根据微表情和地标点的位置所选定的目标区域,且根据从左到右、从上到下的顺序,所展示的5个框代表的是不同微表情对应的面部区域,且由于检测不同微表情所需要处理区域的大小可能不同,所以第二组参数所设定的目标区域大小也可能相互有所不同。具体实例如表1。表1微表情/项目对应的地标点大小个数备注au121,2248×482内眉毛上扬au92864×641皱起鼻肌表1中第一行为针对au1所设定的两组参数:第一组参数为第一行第二列,显示au1与地标点21号、22号两个点相关;第一行第三列指定检测au1所设定的目标区域大小,为48×48像素点,且规定目标区域以第一行第二列所指定的地标点在图像中的坐标点为中心;第一行第三列指定的目标区域的个数即为第一行第二列中相对应的地标点的个数,由于人的面部内眉毛上扬涉及两条眉毛,所以综合其位置设定au1对应的地标点个数为2个。第二行与第一行同理,由于人的面部皱起鼻肌仅涉及鼻子,所以综合其位置设定au9对应的地标点个数为1个,其他各个au不再赘述。微表情与地标点位置对照模块所有参数的学习依据以下步骤进行:输入:一个批次的训练数据,该数据包含batch张图像,输入所有共n个au矩形区域的中心点,即指定以哪个地标点为矩形中心,输入第n个au的第i个矩形框的初始矩形框大小为,输入第n个au的第i个矩形框的最大矩形框大小,输入学习率γ,输入最大迭代次数m,定义深度学习网络输出的损失函数值为δ(损失函数值为所有预测值与实际值差值的平方和),定义深度学习网络预测结果的平均精确率为map,定义深度学习网络训练停止损失函数值为ε,当前训练au标号为i。输出:所有共n个au对应矩形框的最佳大小。将以上参数输入如图4所示的深度学习网络开始迭代:step1:对第i个au的第j个矩形框,分别记为au-i和au-i-j,进入step2。step2:使用a×a大小的矩形框进行训练,当δ<ε或达到最大迭代次数时停止,进入step3。step3:使用step1训练完成的深度学习网络对au-1和au1-1进行map的计算并记录,进入step4。step4:a←a*γ,进入step5step5:若a>b,当前au的最佳区域大小已经寻找完成,i←i+1,若i≤n,进入step1,迭代计算下一个au的最佳区域大小;若i>n,所有au最佳区域大小已经寻找完成,结束。在步骤s130中,将第一输入样本和第二输入样本使用随机最速下降法进行深度学习网络的训练,通过深度学习网络结构中新增的首层对图像进行目标区域剪裁,将剪裁后的图像分别同时进入深度学习网络结构中对应的各个层的进行训练,输出表情分类及微表情的检测结果。随机最速下降法(简称sgd,全称stochasticgradientdescent),sgd算法将所有训练数据分批次输入深度学习网络进行训练,每个批次包含的图片个数为batch个(batch为正整数,一般去8、16、32等4的倍数)。对单张静态图片、视频或连续帧形式的图片等解决表情分类准确率不高、微表情检测准确率不高的问题,本发明采用面部行为编码系统(facs,facialactioncodingsystem)所定义的动作单元(au,actionunit)为微表情,其他类似标准下定义的微表情应有相类似的检测结果。本实施例中,首先对人脸进行脸的轮廓、眉毛、鼻子、嘴巴等地标点(英文为landmark,指根据人脸建模,对人脸轮廓、鼻子、眼睛、眉毛、嘴巴等地点进行定位并给出相应坐标点,本文所采用的地标点在人脸上共分布有68个)的定位,之后根据au和这些地标点之间的空间位置关系,指定输入卷积神经网络的多个子区域和大小,排除au区域以外的信息,有目的地进行网络训练,本发明新建了感兴趣区域层,构建了新的深度学习网络结构,提升了表情检测和微表情检测的准确率和鲁棒性。进一步的,将待测数据调整为预设格式的图像包括:待测数据为图像或视频;若待测数据为视频,将视频拆分为单帧图像。进一步的,基于openface的方法对所述图像进行地标点定位检测,包括:基于openface的方法对图像进行预设尺寸缩放,对缩放后的图像进行面部位置上地标点的检测,地标点以预设符号分隔,通过有序浮点数数组的方式存储。优选的,对输入的目标图像进行尺寸缩放,统一将图像缩放至234×234像素大小,并进行人脸轮廓、眉毛、鼻子、嘴巴等面部位置上地标点的检测,模块输出当前帧地标点的检测结果,图2a为原始输入图像即单帧图像,人脸轮廓、眉毛、鼻子、嘴唇等位置所标注的白点共有68个,即为输入预处理模块所检测到的地标点,图2b为检测出地标点的图像,图3为带有部分地标点标号标注的图像。地标点检测方法为现有方法,采用基于openface的方法进行检测。本模块所检测到的地标点以“,”分隔、有序浮点数数组的方式存储,如:a1,a2,b1,b2,…,a68,b68;其含义为所检测到的第1个地标点在图像上的横坐标位置,第1个地标点在图像上的纵坐标的位置,以此类推。进一步的,深度学习网络结构依次包括:感兴趣区域层和子网络结构;所述子网络结构包括至少一个第一子网络结构和通过拼接层连接的第二子网络结构;所述第一子网络结构包括顺序连接的卷积层、激活层、批量标准化层和池化层共四层的重复以及全连接层、激活层和丢弃层共三层的重复,第二子网络结构包括全连接层、激活层和丢弃层共三层的重复。进一步的,通过深度学习网络结构中新增的首层对图像进行目标区域剪裁的步骤包括:感兴趣区域层基于第二输入样本对第一输入样本中的图像进行目标区域剪裁,得到各个微表情对应的子区域,并将数据输入子网络结构。进一步的,第一子网络结构运行的步骤包括:卷积层对感兴趣区域层输入的图像进行二维卷积运算,将输出的卷积层提取特征数据输入激活层。由于卷积层的子区域图像比较小,且小卷积核更能刻画细节,本发明采用3×3、步长(对应英文为stride)为1的卷积核(即为长和宽都为3,共包含9个元素的卷积核),卷积对应英文为convolutional,“卷积层p_q”所代表的含义为网络第p个卷积层针对第q个子区域的卷积核,卷积层完成对图像的二维卷积运算,图像经过卷积层处理后,输出为该卷积层提取的特征,深度学习网络每一层都可以看做是特征提取器,每一层的输出都是图像的一种特征,且每一层输出的特征名字统称为特征图,对应英文featuremap。激活层对卷积层提取特征数据线性激活;线性激活后的激活数据输入批量标准化层。激活层选取不同的激活函数,常见的激活函数包括relu函数(relu为线性整流函数rectifiedlinearunit的缩写)、sigmoid函数等。批量标准化层对当前批次的激活数据进行标准化后输入池化层;批量标准化层(英文简称为batch_norm,全称为batchnormalization)对当前批次的数据进行标准化,预防出现深度学习网络参数出现极端引起梯度消失从而不收敛的情况。使用批量标准化能有效提升训练速度和提高准确率,批量标准化层完成。池化层通过最大值池化对数据降采样,将数据维度压缩降低后,将卷积层、激活层、批量标准化层和池化层运行的步骤按照预设次数重复。池化层分为最大值池化(对应英文简称为max_pool,全称为maxpooling)、平均值池化(对应英文简称为mean_pool,全称为meanpooling)等,本专利采用最大值池化,即当前范围内的数据,只选择最大的那一项作为输出,经过池化层后数据维度得到压缩降低。通过全连接层将重复完成的数据输入至激活层。全连接层(英文简称为fc,英文全称为fullyconnected)的每一个神经元和上一层的所有神经元都相连。激活层对数据线性激活;线性激活后的激活数据输入丢弃层;丢弃层以一定概率将本层中的部分神经元从深度学习网络中丢弃,将全连接层、激活层和丢弃层运行的步骤按照预设次数重复。丢弃层(对应英文dropout)以一定概率将本层单元从深度学习网络中丢弃,模型中使用丢弃层能有效降低模型过拟合,比同时训练了多个深度学习网络。进一步的,激活层对卷积层输出的特征图进行一次滤波。进一步的,批量标准化层对当前批次的数据进行标准化的步骤包括:当前批次图像共包含batch张图像,图像均包含n个通道,图像像素大小为h×w,设定缩放因子γ,设定平移因子β,设定近0常数ε,设定动量参数m,输入为x,其含义为当前批次本层输入图像的像素值,共有n(n=h×w)个像素,xi,i∈[1,n]表示第i个像素的像素输入值,输出为y,其含义为当前批次本层输出图像的像素值,yi,i∈[1,n]表示第i个像素的输出值,为计算yi,i∈[1,n]过程中的中间变量。s1:计算当前批次n个通道batch张图像的像素均值,得到长度为1×n维的均值向量μ。s2:计算当前批次n个通道batch张图像的像素方差,得到长度为1×n维的方差向量σ。s3:对输入数据进行归一化得到批量标准化的输出结果:进一步的,第二子网络结构的运行步骤包括:通过拼接层将所有第一子网络结构中的数据按照顺序拼接起来。拼接层(英文全称为concat)将上一层所有全连接层的数据按照顺序拼接起来,拼接后的数据长度为上一层所有全连接层数据的长度之和。通过全连接层的每一个神经元与拼接层的每一个神经元相连,将数据输入至激活层;激活层对数据线性激活;线性激活后的激活数据输入丢弃层;丢弃层以一定概率将本层中的部分神经元从深度学习网络中丢弃,将全连接层、激活层和丢弃层运行的步骤按照预设次数重复;通过第二子网络结构得到表情分类及微表情的检测结果。本发明中第二子网络结构根据需要可进行表情检测和微表情检测两种用途。若为检测k(k为表情种类个数,如上述定义的7,或其他标准定义的表情种类个数)种表情进行分类,可将最后一层的全连接层的神经元个数设为k;若为检测l(l为上述facs标准下与面部相关的微表情种类,本专利共l≤59,具体种类见表2)种微表情,则可将最后一层的全连接层的神经元个数设为l。表2进一步的,还包括时序信息模块,用于通过第二子网络结构中第二次重复得到的数据作为输入数据,训练长短时记忆网络,得到表情分类及微表情的检测结果。时序信息模块结构如图5所示,为一个长短期记忆网络(lstm,lonogshot-termmemory),其输入为第二子网络结构(三层重复下)的倒数第二个全连接层,所采用lstm网络包含2个lstm层,分别为长短期记忆网络第一层和长短期记忆网络第二层,数据输入长度为7,即所输入视频序列前后帧的记忆长度为7。tn(n=1,2,...,7)代表tn时刻,xn(n=1,2,...,7)表示在tn时刻的输入数据,hn(n=1,2,...,7)表示长短期记忆网络第一层的第n个block的输出值,h`n(n=1,2,...,7)表示长短期记忆网络第二层的第n个block的输出值。拼接层与子网络结构的拼接层作用相同,将7个时间点的输出拼接起来形成一个向量。表情/微表情标签模块为输出模块,输出各个表情/微表情的预测值。由于lstm网络的记忆长度为7,则每个lstm层包含7个街区单元(block),街区单元结构如图6。图6中当前时刻细胞参数模块和前一时刻细胞参数模块分别存储当前时刻细胞参数和前一时刻细胞参数,细胞参数是指描述长时和短时记忆的细胞状态向量(cellstatevector),该向量存储lstm网络的记忆参数,前一时刻细胞参数模块存储的前一时刻细胞参数以细胞状态向量ct-1标识,当前时刻细胞参数模块存储的当前时刻细胞参数以细胞状态向量ct标识;前一时刻街区单元输出模块存储前一时刻街区单元的输出ht-1,当前时刻街区单元输出模块存储当前时刻街区单元的输出,以ht标识;当前时刻输入模块存储当前时刻lstm网络的输入,以xt标识。在每一个时间点,一个街区单元采取前一时刻街区单元的输出ht-1、当前时刻lstm网络的输入xt和前一时刻细胞状态向量ct-1,生成当前时刻细胞状态向量ct;之后根据当前时刻细胞状态向量ct、当前时刻lstm网络的输入xt、前一时刻细胞状态向量ct-1和前一时刻街区单元输出ht-1生成当前时刻街区单元输出ht。同时,前一时刻细胞参数模块和当前时刻细胞参数模块通过丢弃旧信息和获取新信息得到更新。街区单元对lstm网络的输入进行一代处理(一代处理指街区单元通过当前时刻输入模块、前一时刻细胞参数模块、前一时刻街区单元输出模块接收输入,处理,通过当前时刻街区单元输出模块产生当前时刻街区单元输出和通过当前时刻细胞参数模块更新当前时刻细胞参数的过程),会经过三个步骤,通过三个门来完成:ct遗忘门,ct更新门和ht更新门,且ct更新门包含输入门和候选门两个子门(门即为一组计算公式)。ct遗忘门根据前一时刻街区单元输出ht-1和当前时刻输入xt来决定从上一时刻细胞状态向量中应该保留和丢弃哪些参数,此步通过构造遗忘向量ft完成,遗忘向量ft的构造如下:ft=σ(wf·[ht-1,xt]+bf)其中wf和bf是ct遗忘门参数,[]表示将ht-1和xt两个向量拼接在一起组成新的向量(下同),·为矩阵乘法(下同),σ为sigmoid函数(下同)。ct更新门使用新的信息更新细胞状态向量ct,该参数由三个元素组成:前一时刻细胞状态向量ct-1,当前时刻输入xt和前一时刻街区单眼输出ht-1。ct更新门更新ct的构造如公式:其中*为哈达玛积(hadamardproduct),it由xt和ht-1根据如下公式生成:it=σ(wi·[ht-1,xt]+bi)wi和bi是输入门参数。是为生成最终细胞状态向量和输出而创造的候选细胞状态向量,通过如下公式构造:wc和bc是候选门参数,其中的tanh为双曲正切函数。最终,使用ht更新门,根据更新后的当前时刻细胞状态向量ct,当前时刻输入xt和前一时刻街区单元输出ht-1生成当前时刻街区单元输出ht,公式如下:ht=σ(wo·[ht-1,xt]+bo)·tanh(ct)wo和bo是输出门(即ht更新门)参数。同时,此代计算通过当前时刻街区单元输出模块得到的前时刻街区单元输出ht和通过当前时刻细胞参数模块得到的当前时刻细胞参数ct,分别通过前一时刻街区单元输出模块和前一时刻细胞参数模块传递给下一代处理。本专利可分别进行k种表情和l种微表情的检测,其中k和l的定义与上同。本专利最终检测结果输出如图7,以图2a为输入,输出分为表情分类输出和au估计两部分,表情分类输出对当前图片属于哪一类表情分别给出概率估计,微表情估计输出对各个微表情是否存在给出估计,1表示存在,0表示不存在。迁移学习,本专利所提出的深度学习模型,可迁移到其他标准下定义的表情识别和微表情识别以及其他分类、检测任务中。若有其他标准定义的表情识别,根据相应种类修改表情种类个数k,并在特征提取网络或时序网络的最后一层进行相应修改;若有其他标准的微表情定义,根据相应种类和定义,修改微表情与地标点对照表的超参数和微表情个数l,并在特征提取网络或时序网络的最后一层进行相应修改。本发明的有益效果是:通过本发明提供的技术方案,建立新的深度学习层,感兴趣区域层,并建立了新的深度学习网络结构,将图片按照需求裁剪成多个子图片,之后将这些子图片输入深度学习网络进行学习的技术方案,将提取图片的多个指定区域作为感兴趣区域进行有目的性的学习,目的区域的个数和大小可根据需求自由设置,消除了无关区域带来的干扰,同时对于视频或者连续帧形式的图片引入了时序信息提高准确率,增强鲁棒性。以上公开的仅为本发明的几个具体实施例,但是,本发明并非局限于上述实施例,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1