一种手写体藏文字丁识别方法与流程
本发明属于文字模式识别技术领域,涉及一种手写体藏文字丁识别方法,可用于对移动终端输入的手写体藏文字丁进行识别。
背景技术
藏语历史悠久,国内使用人口约为800万,目前英语与汉语识别技术已经成熟,并且广泛地应用在各领域,而藏语的识别技术还处于起步阶段,成果相对较少。伴随着各种移动设备的普及,手写输入成为人机交互的一种重要方式,藏语手写识别不仅具有重要的社会意义,还有广阔的市场前景。
藏语结构可分为两个部分:辅音字母和元音字母,这些字母按照藏语结构特点分别出现在藏语音节字的不同位置并进行叠加,字母之间的纵向叠加组成藏文字丁,字丁的横向叠加组成完整的藏文音节字。与藏文的字母和音节字相比,选取藏文字丁为识别对象的原因主要有以下几点:(1)字母之间相互粘连紧密,界定藏文字母十分困难。(2)藏文音节数量过于庞大,不但会对识别造成很大困扰,而且对于数据的采集,以现有条件来看也极为困难。(3)字丁在结构上是相互独立的,且参照《信息技术藏文编码字符集扩充集a》的编制说明:“在国际标准框架下制定藏文大字符集编码国家标准,定义垂直预组合的藏文字符,应作为我国藏文信息处理发展的策略”,因此选用藏文字丁作为识别单位是合理且便于实现国际化的。
目前,手写体藏文字丁的识别方法主要可分为基于脱机特征的识别方法和基于联机特征的识别方法。其中,基于脱机特征的识别方法处理的是由笔画轨迹点序列映射而成的二维图像,该方法对于手写输入经常出现的连笔、断笔和手写笔顺不同等问题有较好的鲁棒性,但是对于相似形如
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种手写体藏文字丁识别方法,以提高手写体藏文字丁的识别率。
为实现上述目的,本发明采取的技术方案包括以下步骤:
(1)建立藏文字丁字典:
确定待采集藏文字丁的类别和类别数量n,并对确定的藏文字丁类别从0到n-1编码,得到n个带有编码的藏文字丁组成的藏文字丁字典,n≥2;
(2)建立手写体藏文字丁样本库:
(2a)在移动终端平台上采集m套手写体藏文字丁样本,每套样本包含藏文字丁字典中的所有类别,得到m×n个手写体藏文字丁样本;
(2b)对各手写体藏文字丁样本分别进行倾斜校正、平滑、归一化、插点和重采样,以去除采集过程中附加的噪声,得到由m×n个不含噪声的手写体藏文字丁样本组成的手写体藏文字丁样本库,其中,所述手写体藏文字丁样本为一系列按时序采样的笔画坐标轨迹,m≥2;
(3)获取手写体藏文字丁样本库各样本的联机特征:
根据不含噪声的藏文字丁样本的笔画坐标轨迹,计算每个藏文字丁样本在八个方向上的方向线素,得到m×n个藏文字丁样本的联机特征,其中,每个藏文字丁样本在八个方向上的方向线素,是指每个藏文字丁样本在平面直角坐标系中以x轴正方向为起点,逆时针方向旋转,每隔45度所指方向上的方向线素;
(4)获取手写体藏文字丁样本库各样本的脱机特征:
将每个不含噪声的藏文字丁样本的笔画坐标轨迹映射为二维图像,并对每个二维图像进行gabor滤波,得到m×n个藏文字丁样本的脱机特征;
(5)获取不含噪声的藏文字丁样本的特征向量:
对每个藏文字丁样本的联机特征与脱机特征进行串行融合,得到m×n个藏文字丁样本的特征向量;
(6)获取训练样本集和待识别样本:
从手写体藏文字丁样本库中随机选取m-1套藏文字丁样本,并将(m-1)×n个藏文字丁样本作为训练样本集,剩余的n个藏文字丁样本作为待识别样本;
(7)获取藏文字丁样本的特征模板:
计算训练样本集中同一类别藏文字丁样本对应的特征向量的平均值,得到n个藏文字丁样本的特征模板;
(8)对待识别样本中的藏文字丁样本进行分类:
将待识别样本中n个藏文字丁样本对应的特征向量与每个藏文字丁样本的特征模板分别进行匹配,并参照藏文字丁字典,将匹配度最高的特征模板所属类别的编码对应的藏文字丁作为识别结果。
本发明与现有技术相比,具有如下优点:
本发明由于对待识别样本中的藏文字丁样本进行分类时,是通过对每个藏文字丁样本的联机特征与脱机特征进行串行融合,并将融合后的特征向量与藏文字丁样本的特征模板进行匹配实现的,避免了现有技术提取单一特征得到的特征向量中包含藏文字丁信息不全面的缺陷,有效地提高了手写体藏文字丁的识别率,且识别的鲁棒性好。
附图说明
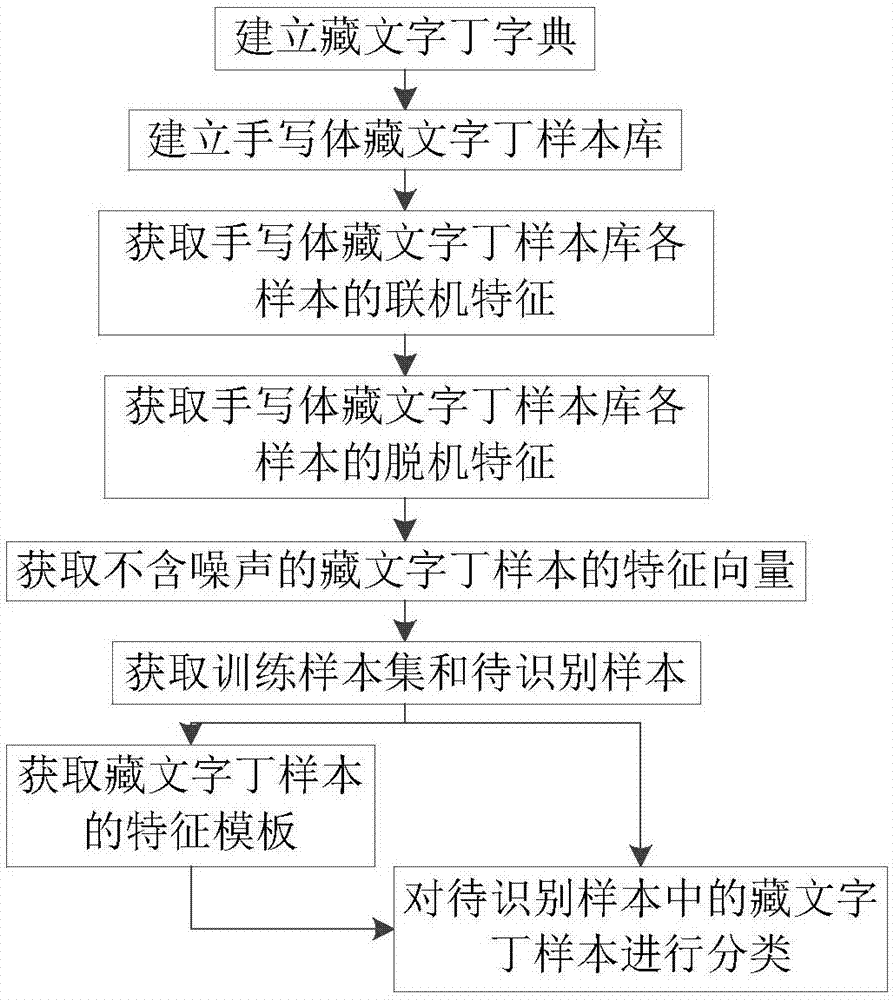
图1为本发明的实现流程图;
图2为藏文各部分组成结构示意图;
图3为本发明对手写体藏文字丁样本进行倾斜校正、平滑、归一化、插点和重采样的实现流程图;
图4为本发明手写体藏文字丁样本在八个方向的方向线素及方向线素的向量分解示意图。
具体实施方式
下面结合附图和具体实施例,对本发明作进一步的详细描述。
参照图1,本发明包括以下步骤:
步骤1,建立藏文字丁字典。
藏文的组成结构可分为字母、字丁和音节字,如图2所示,字母间的垂直叠置形成藏文字丁,字丁间的水平叠置形成藏文音节字。根据我国先后颁布的《藏文编码字符集基本集》、《藏文编码字符集扩充集a》和《藏文编码字符集扩充集b》的国家标准,藏文字丁的数量一共是有7433个,数量庞大,但绝大多数是梵音藏文字丁。本发明选取了《藏文编码字符集基本集》和《藏文编码字符集扩充集a》中的663个藏文字丁,这些数量的字丁通过排列组合就已经能覆盖90%以上的藏文。将这663个字丁从0到662编码,建立藏文字丁字典。
步骤2,建立手写体藏文字丁样本库。
步骤2a)在移动终端平台上采集不同人手写的藏文字丁数据,本发明共采集了30个藏族同胞手写的藏文字丁,每人写2遍,共写了60套,因此共采集有663×60=39780个手写数据样本。
步骤2b)对每个样本的笔画坐标轨迹进行倾斜校正、平滑、归一化、插点和重采样,其具体的实现流程如图3所示:
步骤2b1)对手写体藏文字丁样本进行裁剪处理。由于书写人员在采集软件的书写框内书写时没有规定固定的位置和大小,为了减少样本间的差异,可以先对样本进行裁剪。首先找到字丁样本的最小外接框,然后只保留外接框以内的部分,将不包含字丁信息的空白部分去除。
步骤2b2)对裁剪后的藏文字丁进行基于水平投影的倾斜校正处理。在采集手写字丁的时候,受习惯和环境等因素影响,难免会出现字体倾斜的情况,对样本间字丁笔画的横向和纵向分布产生不同程度的影响,从而影响字丁的识别。倾斜矫正时将藏文字丁进行旋转,旋转步长为1°,旋转范围为-15°到15°。对每次旋转得到的新的字丁数据进行水平投影,得到在当前矫正角度下水平方向上的笔画点个数,如果当前矫正角度的个数大于前面矫正角度的个数,则更新最佳角度为当前矫正角度。
步骤2b3)对倾斜校正后的藏文字丁进行多点加权平滑处理,考虑前后5个点(当前点和其前后各两点),权值的分配参考与当前点距离的远近。
步骤2b4)将平滑后的藏文字丁进行线性归一化处理。线性归一化的作用是消除手写体样本之间由于大小不同带来的误差,其具体方法是对藏文字丁在水平和垂直两方向上进行线性缩放,使得归一化后的图像大小为512×512。
步骤2b5)将线性归一化处理后的藏文字丁进行非线性归一化处理。非线性归一化的作用是调整笔画密度和重心位置,使得偏长或偏短、较粗或较细的笔画更加均匀,具体方法是计算水平和垂直两个方向上的点密度,均衡轨迹点的密度分布。
步骤2b6)将非线性归一化后的藏文字丁进行相邻点间插点处理,调整相邻轨迹点的间距。具体的方法是在每个笔画内点列的相邻点间插入新点列使笔画连接起来,近似的认为在每两个点之间为直线连接,通过计算斜率对直线方程进行插点操作。
步骤2b7)将插点处理后的藏文字丁进行3点重采样处理。重采样也可以减少手写输入藏文字丁时产生的抖动噪声,在一定程度上达到平滑手写轨迹曲线的目的,重采样的过程也会删掉一些造成冗余的数据点。其方法是在插入新的点列后形成的连续的点列中进行每隔3点采样,均衡笔画轨迹的密度。
步骤3,获取手写体藏文字丁样本库各样本的联机特征。提取预处理后藏文字丁样本的方向线素特征,并将方向线素特征作为手写体藏文字丁样本的联机特征。
提取方向线素特征的方法是计算采样坐标点在八个方向上的方向线素,参照图4(a),是8方向划分示意图,对采样点pi的方向向量做垂直投影,其映射到最近邻的两个标准方向上,如(b)所示,投影分量分别记为
上式中,pi-1(xi-1,yi-1)为点pi的前一个相邻点,pi+1(xi+1,yi+1)为点pi的后一个相邻点。从式中可以看出,当pi为笔画的起始点时,该点的方向向量
步骤4,获取手写体藏文字丁样本库各样本的脱机特征。将训练样本的笔画坐标轨迹映射为二维图像,提取预处理后藏文字丁样本的gabor特征,作为手写体藏文字丁样本的脱机特征。
藏语手写字丁图像为i(x,y),对其进行gabor特征提取,就是将i(x,y)的每个像素与gabor函数进行卷积运算i(x,y)×ψ(x,y,ω,θ),运算结果就是gabor特征。其中:
式中x和y分别是藏语手写字丁的位置坐标,ω和θ分别是正弦波的中心频率和方向,xp与yp分别为xp=xcosθ+ysinθ,yp=-xsinθ+ycosθ,φ是倍频程的带宽,σ是高斯包络函数在x轴与y轴上的均方差。
步骤5,获取不含噪声的藏文字丁样本的特征向量。对每一个手写体藏文字丁样本的方向线素特征和gabor特征进行串行融合,串行融合时的表达式为:
d=λa×dα+λb×dβ
式中d是融合特征,dα是联机特征,dβ是脱机特征,λa和λb分别是联机和脱机特征的加权系数,代表两种特征在识别中的重要性比例。
步骤6,获取训练样本集和待识别样本。在60套手写体藏文字丁样本库中取出59套作为训练样本集,每套训练样本集中都有663个手写体藏文字丁样本。剩余的1套藏文字丁样本作为待识别样本,用于后续的分类识别。
步骤7,获取藏文字丁样本的特征模板。对训练样本集中同一类别藏文字丁样本对应的特征向量求平均值,得到n个藏文字丁样本的特征模板。
步骤8,对待识别样本中的藏文字丁样本进行分类。将待识别样本中n个藏文字丁样本对应的特征向量与每个藏文字丁样本的特征模板进分别行匹配,采用欧式距离分类器,欧式距离的计算公式为::
其中,p为特征向量的维数,xi是待识别藏文字丁样本的第i维特征向量的值,yi为某类藏文字丁样本第i维特征模板的值。
然后参照藏文字丁字典,将距离最小的特征模板所属类别的编码对应的藏文字丁作为识别结果。
- 还没有人留言评论。精彩留言会获得点赞!