一种基于变速学习深度自编码网络的人脸识别方法与流程
本发明属于深度神经网络的模式识别领域,具体涉及一种变速学习深度自编码网络对人脸图像的识别模型。该模型充分利用了深度自编码网络发现数据本质特征的能力,同时加快了特征学习速度和网络的收敛速度,提高了人脸识别性能。
背景技术
人脸识别是当下计算机视觉领域热门研究方向,也是模式识别应用涉及的主要内容。深度自编码网络能够模拟人类神经元活动原理,自主地学习出人脸图像内在不同层次的特征,使人脸识别摆脱了使用传统手工提取特征复杂而低效的困扰。在识别模型中,良好的特征能准确地提取到有利于解决问题的信息,因此特征学习是模式识别领域的重点方向,并具有广泛的应用价值。然而,在深度自编码网络的特征学习中,目前是使用单一固定的学习率来控制学习进度。学习率取值过大时,网络可能过调甚至发散,学习率取过小时,网络收敛很慢,这导致网络学到的特征较差,模型识别结果不佳。而且,网络中不同的特征在训练过程中对学习率的要求是不同的。通常,学习率是由大量试凑实验后根据经验所得,这类方法耗时费力,且得到的学习率是面向整个网络而不是各个特征,因此效率不高。因此有必要提出一种新的技术方案来解决上述问题。
技术实现要素:
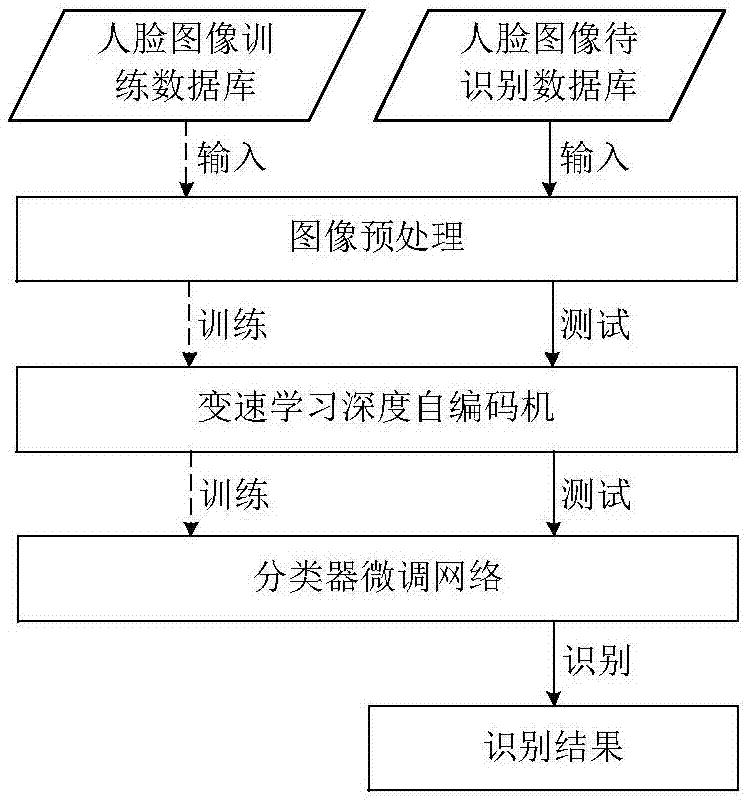
本发明提出一种基于变速学习深度自编码网络的人脸识别方法。该模型首先进行人脸数据预处理;其次通过可变速学习策略指导逐层预训练。最后,在网络顶层添加分类器,进行微调优化得到基于深度自编码网络的识别模型,将待识别人脸图像输入模型进行识别。
本发明的技术方案:
一种基于变速学习的深度自编码网络模型的人脸识别方法,包括以下步骤:
1)将训练数据集输入识别模型进行数据预处理;
2)将预处理后的数据输入可变速学习的深度自编码网络进行逐层预训练;
2-1)使用小批量梯度下降算法训练深度自编码网络,首先训练第一层网络,初始化学习阶段数设为1;
2-2)对输入层数据进行编码得到隐含层数据,再将隐含层数据解码得到输出层数据,分别计算输出层数据和输入层数据间的重构误差信息和网络参数更新信息;
2-3)统计网络的重构误差信息,量化局部变速系数和总体变速系数;
2-4)统计网络的参数更新信息,量化相关变速系数;
2-5)将局部变速系数、总体变速系数和相关变速系数相乘,得到最终变速系数;
2-6)将初始学习率与步骤2-5)的最终变速系数相乘,获得下一阶段的学习率向量,每个隐含层特征节点有与之对应更新的学习率且其学习过程相互独立;下一阶段的网络参数将在各节点对应的学习率指导下完成更新;
2-7)当前学习阶段数自加1,判断当前阶段数是否小于预设学习阶段总数,满足则跳转至步骤2-2),否则表示当前层训练完毕,跳转至步骤2-8);
2-8)上一个自编码网络的隐含层输出作为下一个自编码网络的隐含层的输入,同样使用小批量梯度下降法,以重构误差最小化为目标进行阶段化训练;训练中参数更新所使用的学习率同样通过2-2)至步骤2-7)的变速学习策略进行更新;直至完成深度自编码网络各层预训练为止;
3)对各层已完成预训练的深度自编码网络进行全网微调;
3-1)将预处理后的人脸图像数据输入步骤2)训练好的深度自编码网络,进行逐层特征提取,网络最后一层上添加分类器,通过反向传播算法对深度自编码网络进行参数优化;
3-2)当完成全网络微调后,即可获得基于变速学习的深度自编码网络模型;
4)将预处理后的待识别的人脸图像输入微调后的深度自编码网络模型中,得到对应的识别结果。
所述步骤1)中的数据预处理首先通过lbp方法初步提取人脸的纹理特征,然后将图像数据归一化至区间[0,1]。
所述步骤2-3)具体为:
a1)基于步骤2-2)得到的重构误差信息,分别计算得到当前阶段块级平均误差cme、当前阶段批次级测试误差cte、总体块级平均误差gme和总体批次级测试平均误差gte,计算方法分别为:
其中,lrepochs为该学习阶段中的训练批次数,mse(t)(j)指第t个学习阶段的第j批次训练误差;
其中,te(t)(j)指第t个学习阶段的第j批次整体训练误差,表示当某一学习阶段的某批次完成参数更新后当即对该批次进行一次前馈计算,获取该批次所有数据块更新后网络的整体训练误差;
a2)从局部和整体角度通过步骤a1)得到的四个参量计算当前效应ceffect和总体效应geffect,计算方法分别为:
a3)根据步骤a1)和步骤a2)得到的ceffect、geffect和cte,判断当前变速方向和总体变速方向,具体判断方式为:
其中,cte(t)和cte(t-1)分别表示第t阶段和第t-1阶段的当前批次级测试误差,gte(t)和gte(t-1)分别表示第t阶段和第t-1阶段的总体批次级测试平均误差;
a4)基于步骤a3)得出的变速方向,通过ceffect和geffect及其各自历史效应的最大最小值计算局部变速系数clrcc和总体变速系数glrcc;
当变速方向是加速时,局部变速系数clrcc和总体变速系数glrcc的计算方式分别为:
当变速方向是减速时,局部变速系数clrcc和总体变速系数glrcc的计算方式分别为:
其中,max(ceffect)和min(ceffect)分别为ceffect的历史最大值和最小值,max(geffect)和min(geffect)分别为geffect的历史最大值和最小值。
所述步骤2-4)具体为:
b1)基于步骤2-2)得到的参数更新信息,计算学习阶段内连接各隐含层节点的参数更新变化量δθ,所述的参数包括权重和偏置;
上式中,dθ(t)(j)为第t个学习阶段中第j个批次训练时的参数更新值;
b2)用ppmcc度量网络各阶段间隐含层节点权值更新量之间的强弱关系和变化趋势,计算得出每个节点对应的相关性系数r;
上式中,δθi(t)和δθi(t-1)分别表示与当前层第i个节点相连的所有权值参数在第t个阶段和第t-1个阶段上的权值更新量,
b3)将步骤b2)得到的相关性系数r统一映射至区间[0,2],得到相关变速系数rlrcc,
其中,min(r(t)和max(r(t)分别为第t阶段相关性系数中的最小值和最大值。
所述步骤2-5)中的最终变速系数lrcc计算公式为:
lrcc(t)=clrcc(t)*glrcc(t)*rlrcc(t)。
所述步骤2-6)中学习率向量的计算公式为:lr(t)=lrcc(t)*lr,其中,为lr(t)第t阶段的学习率,lr为网络初始学习率;对应的第t阶段网络参数更新公式为:
本发明的有益效果:本发明用于解决当前定值型学习率导致的网络收敛速度慢,训练低效的问题。本发明提出的基于变速学习的深度自编码网络人脸识别模型,从训练误差趋势和参数更新相关性两个不同的角度方面较全面的评估当前学习率下网络的训练质量,在误差稳步下降的同时加速训练,增强特征学习能力,并进一步提高识别性能。
附图说明
图1为本发明基于可变速学习的深度自编码网络人脸识别模型图;
图2为本发明中基于训练误差趋势分析及量化变速系数流程图;
图3为本发明中基于参数更新相关性示意图;
图4为本发明中基于参数更新相关性量化变速系数流程图;
图5为本发明模型进行人脸识别结果展示图
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
本发明对英国剑桥大桥olivetti实验室提供的(olivettiresearchlaboratory,orl)人脸数据库进行识别,orl人脸库包含一系列人脸图像,共有40个不同年龄、不同性别和不同种族的对象。每个人10幅图像共计400幅灰度图像组成,图像背景为黑色。其中人脸部分表情和细节均有变化,例如笑与不笑、眼睛睁着或闭着,戴或不戴眼镜等,人脸姿态也有变化,其深度旋转和平面旋转可达20度,人脸尺寸也有10%的变化,因此该数据库具有一定的挑战性。识别过程针对每个人选择其一张人脸图像,因此待识别人脸共40张,其余人脸图像作为训练图像供模型训练,实验中分别对40个人物对象设定了名字,以便观察识别效果。本识别模型中网络具体参数依次为,网络结构[944-100-100-40],初始学习率0.1,迭代次数100,分块批次大小1,阶段训练批次数5.
本发明分类模型包含图像数据预处理部分、深度自编码网络变速学习部分和图像识别部分三个方面。
1)图像数据预处理。训练数据库输入模型,首先通过lbp方法初步提取人脸纹理特征,将图像由二维矩阵数据展开至一维向量。其次,将图像像素点取值由[0,255]归一化为[0,1];
2)深度自编码网络变速学习部分。本识别模型中构建了一个四层的深度自编码网络,其中包含两个隐含层。深度自编码网络训练包括预训练和微调,首先进行逐层预训练,其基本步骤为:
2-1)使用小批量梯度下降算法训练深度自编码网络,首先训练网络的第一层,初始化设置学习阶段数为1;
2-2)对输入层数据进行编码得到隐含层数据,再将隐含层数据解码得到输出层数据,分别计算输出层数据和输入层数据间的重构误差信息和网络参数更新信息;
2-3)统计网络的重构误差信息,量化局部变速系数和总体变速系数;
a1)基于步骤2-2)得到的误差信息,分别计算得到当前阶段块级平均误差(cme)、当前阶段批次级测试误差(cte)以及总体块级平均误差(gme)、总体批次级测试平均误差(gte)。其对应的计算方法为
上式中,lrepochs为该学习阶段中的训练批次数,mse(t)(j)指第t个学习阶段的第j批次训练误差;
上式中,te(t)(j)指第t个学习阶段的第j批次整体训练误差,表示当某一学习阶段的某批次完成参数更新后当即对该批次进行一次前馈计算,获取该批次所有数据块更新后网络的整体训练误差;
上式中,gme和gte分别取自于各个阶段性计算得到的cme和cte,用于获得网络全阶段训练情况;
a2)从局部和整体角度通过步骤a1)得到的四个参量计算效应因子,分别是当前效应ceffect和总体效应geffect.其计算方式分别为:
a3)根据步骤a1)和步骤a2)得到的ceffect、geffect和cte的结果,判断当前变速方向和总体变速方向,具体判断方式为
其中,cte(t)和cte(t-1)分别表示第t阶段和第t-1阶段的当前批次级测试误差,gte(t)和gte(t-1)分别表示第t阶段和第t-1阶段的总体批次级测试平均误差;
a4)基于步骤a3)得出的变速方向,通过ceffect和geffect及其各自历史效应的最大最小值计算局部变速系数clrcc和总体变速系数glrcc;
当变速方向是加速时,局部变速系数clrcc和总体变速系数glrcc的计算方式分别为:
当变速方向是减速时,局部变速系数clrcc和总体变速系数glrcc的计算方式分别为:
其中,max(ceffect)和min(ceffect)分别为ceffect的历史最大值和最小值,max(geffect)和min(geffect)分别为geffect的历史最大值和最小值;
2-4)统计网络的参数更新信息,量化相关变速系数;
b1)基于2-2)得到的参数更新信息,计算学习阶段内连接各隐含层节点的参数更新量δθ.其计算方式为:
上式中,dθ(t)(j)为第t个学习阶段中第j个批次训练时的参数更新值;
b2)用ppmcc度量网络各阶段间隐含层节点权值更新量之间的强弱关系和变化趋势,计算得出每个节点对应的相关性系数r。计算方法为:
上式中,δθi(t)和δθi(t-1)分别表示与当前层第i个节点相连的所有权值参数在第t个阶段和第t-1个阶段上的更新量。
b3)将步骤b2)得到的相关性系数r统一映射至[0,2],得到相关变速系数rlrcc.其映射方式为
其中,min(r(t)和max(r(t)分别为第t阶段相关性系数中的最小值和最大值;
2-5)将步骤a4和步骤b3得出的三组相关变速系数相乘,得到最终的变速系数lrcc;
lrcc(t)=clrcc(t)*glrcc(t)*rlrcc(t)
2-6)将初始学习率与步骤2-5)的最终变速系数相乘,获得下一阶段的学习率向量lr,每个隐含层特征节点有与之对应更新的学习率且其学习过程相互独立。下一阶段的网络参数将在各节点对应的学习率指导下完成更新;
lr(t)=lrcc(t)*lr
对应的第t阶段网络参数更新公式为
上式中,θ表示网络中的参数,包括权重和偏置。
2-7)当前学习阶段数自加1,判断当前阶段数是否不大于预设学习阶段总数,如满足,则跳转至步骤2-2),否则表示当前层训练完毕。跳转至步骤2-8);
2-8)上一个自编码网络的隐含层输出作为下一个自编码网络的隐含层的输入,同样使用小批量梯度下降法,以重构误差最小化为目标对下一个自编码网络进行阶段化训练。训练中参数更新所使用的学习率同样通过步骤2-2)至步骤2-7)的变速学习策略进行更新;直至完成深度自编码网络各层预训练为止;
3)对于各层已完成参数初始化的深度自编码网络进行微调优化,其基本步骤为
3-1)将预处理后的人脸图像数据输入可变速学习的深度自编码网络,在网络最后一层上添加线性分类器,使用反向传播算法基于识别误差对深度自编码网络进行全网络参数优化。
3-2)当完成全网络微调后,即可获得基于深度自编码网络的最佳识别模型;
4)将预处理后的待识别人脸图像输入该模型,模型输出对应的识别结果,如图5所示,随机选择10个对象的人脸输入模型,模型识别出每个人脸对应的人物对象,将该人物名字输出,并将人脸库中该名字下的另一幅人脸图像进行显示来验证识别结果,不难发现,面对姿势变换,五官调整,脸部缩放等情况都能准确识别。最后将所有图像输入模型,并统计识别率。此实施例模型识别准确率达100%。
- 还没有人留言评论。精彩留言会获得点赞!