基于变分自编码器和密度峰值的混合属性数据聚类方法与流程
本发明涉及人工智能与数据挖掘的技术领域,特别是一种基于变分自编码器和密度峰值的混合属性数据聚类方法。
背景技术
聚类分析技术作为一种重要的无监督数据挖掘方法,它根据数据属性将样本划分成若干不同的簇,使得同一个簇内的样本具有较高的相似度,不同簇的样本差异性较大。k-means、dbscan、谱聚类等传统的聚类分析算法主要适用于仅含数值型属性的数据,不能直接对含有分类型属性的数据进行有效聚类。针对既有数值型属性又含有分类型属性的混合属性数据的聚类问题,不少学者已经得到了一些有意义的研究成果,其中1997年huang提出的k-prototype算法应用最为广泛,该算法是对数值型属性数据聚类的k-means算法和分类型属性数据聚类的k-modes算法的综合。虽然算法计算速度快,适合大规模混合属性数据的聚类,但是该算法对初始簇中心和离群点较敏感,并且主要适用于球形分布的数据集。2014年,rodriguez和laio提出的密度峰值聚类算法(densitypeakclustering,dpc),将具有局部密度大、且与局部密度更大的样本距离远的样本作为簇中心,然后按最近邻原则确定非簇中心样本所属的簇标号。该算法新颖直观,可以对任意形状分布的样本聚类,但是该算法需要计算任意两个样本之间的距离,计算复杂度高。2013年,kingma和welling将变分推理方法和神经网络结合提出了变分自编码器,dilokthanakul和mediano将高斯混合先验分布的变分自编码器应用于聚类分析。2017年,bai等研究了对原始数据先利用k-means进行快速预聚类,通过分析预聚类的结果,提出两种方法减少密度峰值聚类算法中一些不必要的距离计算,大大提高了算法的运行效率。但上述方法只适合数值型属性数据的聚类,不能直接应用于既有数值型属性又包含分类型属性的混合属性数据的聚类。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种基于变分自编码器和密度峰值的混合属性数据聚类方法,本发明克服了传统的混合属性数据聚类方法对离群点和初始簇中心选择的敏感性,使得聚类的结果更为稳定,本方法不仅适用于球形分布数据,对非球形分布数据的聚类也能取得理想的效果。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种基于变分自编码器和密度峰值的混合属性数据聚类方法,包括以下步骤:
步骤1、读取原始混合属性数据集;
步骤2、采用one-hot编码技术对原始混合属性数据集中每一个原始混合属性样本的分类型属性值进行编码,对原始混合属性数据集中每一个原始混合属性样本的数值型属性值进行归一化,构造标准化数据矩阵;
步骤3、采用t-sne算法对标准化数据矩阵进行降维处理,得到低维数据矩阵;
步骤4、构建并训练变分自编码器,得到每个低维样本的潜在特征,构造联合特征矩阵;
步骤5、基于联合特征矩阵,利用改进的密度峰值聚类算法进行聚类,从而得到联合特征矩阵对应的所有联合特征样本的聚类结果,该聚类结果也是与联合特征样本对应的原始混合属性样本的聚类结果;
所述步骤5中利用改进的密度峰值聚类算法进行聚类包括以下步骤:
(5-1)给定预聚类的类别数,利用模糊c-均值聚类算法对联合特征矩阵对应的联合特征样本进行预聚类,得到每个联合特征样本隶属于每个簇的隶属度,按最大隶属度原则,确定每个联合特征样本的簇标号,计算每个联合特征样本到各个簇中心的距离,以及每个簇的半径;
(5-2)根据每个簇的簇中心、簇半径及给定的截断距离,确定每个簇的近邻簇、过渡簇、外围簇,其中,若两个不同簇内的任意两个联合特征样本之间的距离均小于截断距离,则两个簇互为近邻簇;若两个不同簇内的任意两个联合特征样本之间的距离均大于截断距离,则两个簇互为外围簇;既不是近邻簇也不是外围簇的为过渡簇;
(5-3)确定每一个联合特征样本的近邻样本,统计近邻样本的总数即得该联合特征样本的局部密度,然后将联合特征样本按局部密度从大到小排序;
(5-4)计算每个联合特征样本到不低于其局部密度的所有联合特征样本之间的距离,取其最小值作为该联合特征样本的相对距离,其中按局部密度从大到小排序在第一位的联合特征样本的相对距离取其余联合特征样本相对距离的最大值;
(5-5)计算每个联合特征样本的局部密度与相对距离的乘积,作为该联合特征样本的综合度量值,将每个联合特征样本按综合度量值从大到小排序;
(5-6)根据给定的聚类数k,选取综合度量值最大的前k个联合特征样本作为簇中心,其余联合特征样本按离其最近的簇中心确定簇号,最近的簇中心对应的簇号作为该联合特征样本的簇号,从而得到所有联合特征样本的聚类结果,该聚类结果也是与联合特征样本对应的原始混合属性样本的聚类结果。
作为本发明所述的一种基于变分自编码器和密度峰值的混合属性数据聚类方法进一步优化方案,所述步骤2中构造标准化数据矩阵,具体如下:
(2-1)对原始混合属性数据集中每个原始混合属性样本的分类型属性值进行one-hot编码,编码后将每个分类型属性值转换成一个行向量;
(2-2)将原始混合属性数据集中每个原始混合属性样本的数值型属性值归一化,并将其和该原始混合属性样本的各分类型属性值编码后的向量串联起来,转置后构成该原始混合属性样本的标准化向量;
(2-3)依次将每一个原始混合属性样本的标准化向量作为矩阵的一列,得到的矩阵即为标准化数据矩阵。
作为本发明所述的一种基于变分自编码器和密度峰值的混合属性数据聚类方法进一步优化方案,所述步骤3的降维处理具体如下:
(3-1)根据标准化数据矩阵,用高斯分布构建高维空间高维样本之间的联合概率分布p,用来表示它们在高维空间的相似度;
(3-2)用t分布构建低维空间对应低维样本之间的联合概率分布q,用来表示它们在低维空间的相似度;
(3-3)使用梯度下降法优化p和q的相对熵,使其达到最小,得到最优困惑度值,从而利用该最优困惑度值计算出每个高维样本的低维表示,进而构造出低维数据矩阵。
作为本发明所述的一种基于变分自编码器和密度峰值的混合属性数据聚类方法进一步优化方案,所述步骤4中构造联合特征矩阵,包括以下步骤:
(4-1)给定编码层参数的初始值,将低维数据矩阵对应的低维样本输入变分自编码器的编码层,计算低维样本对应特征的均值向量和标准差向量;利用模特卡洛模拟法从服从标准正态分布的总体中抽取一个采样值,从而计算出低维样本对应的初始特征;
(4-2)将编码层得到的低维样本的初始特征输入变分自编码器解码层,得到对应的初始重构低维样本;利用使最大似然原则不断优化网络权值参数,利用最优网络权值参数计算出变分编码器中低维样本的特征;
(4-3)将所有低维样本的特征排成矩阵形式,从而构造出联合特征矩阵。
作为本发明所述的一种基于变分自编码器和密度峰值的混合属性数据聚类方法进一步优化方案,步骤(5-1)中每个簇的半径指簇内联合特征样本到簇中心的最大距离。
作为本发明所述的一种基于变分自编码器和密度峰值的混合属性数据聚类方法进一步优化方案,所述步骤(5-3)确定每一个联合特征样本的近邻样本包括以下步骤:
(5-3-1)每个联合特征样本所在簇的近邻簇内的所有联合特征样本均为该联合特征样本的近邻样本;
(5-3-2)每个联合特征样本所在簇的外围簇内的所有联合特征样本均不是该联合特征样本的近邻样本;
(5-3-3)每个联合特征样本所在簇的过渡簇内的联合特征样本是否为该联合特征样本的近邻样本按如下方法确定:
若该联合特征样本与过渡簇簇中心的距离小于截断距离与该联合特征样本所在簇簇半径的差,则对应过渡簇内的所有联合特征样本都是该联合特征样本的近邻样本;若该联合特征样本与过渡簇簇中心的距离不小于截断距离与该联合特征样本所在簇簇半径的和,则对应过渡簇内的所有联合特征样本都不是该联合特征样本的近邻样本;若以上条件都不满足,直接计算该联合特征样本和过渡簇内所有联合特征样本之间的距离,小于截断距离的联合特征样本是该联合特征样本的近邻样本;
(5-3-4)每个联合特征样本所在簇的其它联合特征样本是否为该联合特征样本的近邻样本按如下方法确定:
若该联合特征样本与所属簇的簇中心的距离小于截断距离与簇半径的差,则该簇内除该联合特征样本以外的其它所有联合特征样本都是该联合特征样本的近邻样本;若该联合特征样本与簇内的某个联合特征样本距离簇中心的距离之差大于截断距离,则对应联合特征样本不是该联合特征样本的近邻样本;若以上条件都不满足,直接计算该联合特征样本和簇内所有联合特征样本之间的距离,小于截断距离的联合特征样本是该联合特征样本的近邻样本。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明方法利用变分自编码器提取预处理后原始混合属性数据的特征,并利用改进的密度峰值算法进行聚类,克服了传统的混合属性数据聚类方法对离群点和初始簇中心选择的敏感性,使得聚类的结果更为稳定,本方法不仅适用于球形分布数据,对非球形分布数据的聚类也能取得理想的效果。
附图说明
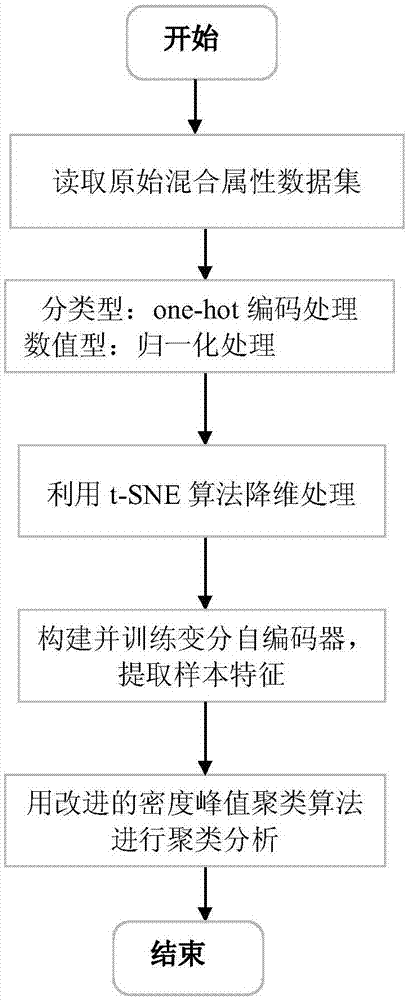
图1是本发明的总流程图。
图2是采用变分自编码器提取特征流程图。
图3是改进密度峰值聚类方法的流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明的基本思路:首先对原始混合属性数据进行编码、归一化、降维等预处理,消除冗余特征;接下来用变分自编码器提取潜在的特征,最后利用改进的密度峰值算法进行聚类,有助于提高聚类的效果。
技术方案描述如下:
(1)对原始混合属性数据集中每个原始混合属性样本的分类型属性值进行one-hot编码,编码后将每个分类型属性值转换成一个行向量;将原始混合属性数据集中每个原始混合属性样本的数值型属性值归一化,并将其和该原始混合属性样本各分类型属性值编码后的向量串联起来,转置后构成该原始混合属性样本的标准化向量;依次将每一个原始混合属性样本的标准化向量作为矩阵的一列,得到的矩阵即为标准化数据矩阵。
(2)根据标准化数据矩阵,用高斯分布构建高维空间高维样本之间的联合概率分布p,用来表示它们在高维空间的相似度;用t分布构建低维空间对应低维样本之间的联合概率分布q,用来表示它们在低维空间的相似度;使用梯度下降法优化p和q的相对熵(kl散度),使其达到最小,得到最优参数值,从而计算各个高维样本的低维表示,进而构造出低维数据矩阵。
(3)给定编码层参数的初始值,将低维数据矩阵对应的低维样本输入变分自编码器编码层,计算每一个低维样本对应特征的均值向量和标准差向量;利用模特卡洛模拟法从服从标准正态分布的总体中抽取一个采样值,从而计算出低维样本对应的初始特征;由编码层得到低维样本的初始特征,输入到变分自编码器解码层,得到初始重构低维样本;利用最大似然原则不断优化网络权值参数,利用最优网络权值参数计算出变分编码器中每个低维样本的潜在特征;将所有低维样本的潜在特征排成矩阵形式,从而构造出联合特征矩阵。
(4)图3是改进密度峰值聚类方法的流程图,根据给定预聚类的类别数,利用模糊c-均值聚类算法对联合特征矩阵对应的联合特征样本进行预聚类,得到每个联合特征样本隶属于每个簇的隶属度,按最大隶属度原则,确定每个联合特征样本的簇标号,计算每个联合特征样本到各个簇中心的距离,以及每个簇的半径(簇内联合特征样本到簇中心的最大距离);根据每个簇的簇中心、簇半径及给定的截断距离,确定每个簇的近邻簇、过渡簇、外围簇,其中,若两个不同簇内的任意两个联合特征样本之间的距离均小于截断距离,则两个簇互为近邻簇;若两个不同簇内的任意两个联合特征样本之间的距离均大于截断距离,则两个簇互为外围簇;既不是近邻簇也不是外围簇的为过渡簇;根据每个簇的簇中心、簇半径及其近邻簇、过渡簇、外围簇的情况,确定是否是近邻样本,统计每个联合特征样本的近邻样本总数即得该联合特征样本的局部密度,然后将联合特征样本按局部密度从大到小排序;计算每个联合特征样本到不低于其局部密度的所有联合特征样本之间的距离,取其最小值作为该联合特征样本的相对距离,其中局部密度最大联合特征样本的相对距离取其余联合特征样本相对距离的最大值;计算每个联合特征样本的局部密度与相对距离的乘积,作为该联合特征样本的综合度量值,将每个联合特征样本按综合度量值从大到小排序;根据给定的聚类数k,选取综合度量值最大的前k个联合特征样本作为簇中心,其余每个联合特征样本按距离它最近的簇中心确定簇号,最近的簇中心对应的簇号作为该联合特征样本的簇号,从而得到所有联合特征样本的聚类结果,也是与联合特征样本对应的原始混合属性样本的聚类结果。
西安电子科技大学在其申请的专利“基于稳健变分自编码器的雷达目标分类方法”(专利申请号:201710743598.7,公布号:cn107609579a)中公开了一种基于稳健变分自编码器的雷达目标分类方法,该发明与本发明的相同之处是都采用变分编码器提取数据的潜在特征,不同之处是“基于稳健变分自编码器的雷达目标分类方法”适用于有监督的分类问题,本发明用于无监督的聚类问题;温州职业技术学院在其申请的专利“一种基于密度峰值的混合属性数据聚类方法”(专利申请号:201710294126.8,公布号:cn107103336a)中公开了一种基于密度峰值的混合属性数据聚类方法,该发明与本发明的相同之处是均涉及混合属性数据的聚类方法,均用到了密度峰值聚类算法,不同之处是“一种基于密度峰值的混合属性数据聚类方法”需要利用原始数据计算每两个原始混合属性样本之间的混合距离,然后用密度峰值聚类算法进行聚类,算法复杂度高,聚类结果受定义的混合距离影响大,而本发明无需定义混合距离,直接对原始数据编码、归一化、降维处理,利用变分编码器提取数据的潜在特征,并用改进的密度峰值聚类算法进行聚类,减少了距离计算的复杂度,且聚类结果稳定。
如图1所示是本发明的总流程图,包括以下步骤:
1.读取原始混合属性数据集;
2.对原始混合属性数据集中每个原始混合属性样本的分类型属性值进行one-hot编码,数值型属性值进行归一化处理
(1)设原始混合属性数据集x={x1,x2,...xn},其中xi=[xri1,xri2,…,xrip,xci(p+1),xci(p+2),…,xcim]′表示第i个原始混合属性样本,i=1,2…n,n为原始混合属性样本的个数,[*]′中的′为向量的转置符号,即将行向量转置为列向量,p为原始混合属性样本中数值型属性的个数,m为原始混合属性样本中所有属性的个数,xriq为原始混合属性数据集中每一个原始混合属性样本的数值型属性值,q=1,2,…,p,上标为r的元素对应数据集的数值型属性值,上标为c的元素对应分类型属性值;对每一个分类型属性xcih,h=p+1,p+2,…,m,根据原始混合属性样本中该属性取不同属性值的个数确定编码的位数,用one-hot编码,使每个属性值对应编码的一位数字为1,其余位的数字均为0,编码后第i个样本的第h个分类型属性值xcih用行向量ycih代替。
(2)对原始混合属性数据集中每一个原始混合属性样本的数值型属性值xriq进行归一化,设第i个原始混合属性样本归一化后对应的各数值型属性值分别为yri1,yri2,…,yrip,将其和第i个原始混合属性样本各分类型属性值one-hot编码后的向量ycih(h=p+1,p+2,…,m)串联起来,构成该原始混合属性样本样本的标准化向量yi=[yri1,yri2,…,yrip,yci(p+1),yci(p+2),…,ycim]′;
(3)依次将每一个原始混合属性样本的标准化向量yi(i=1,2…n)作为矩阵的一列,得到的矩阵即为标准化数据矩阵y=[y1,y2,...,yn]。
3.利用t-sne算法进行降维处理
根据标准化数据矩阵y=[y1,y2,...,yn],对于其中任意两个高维样本yi和yj,用高斯分布构建它们在高维空间的联合概率分布
用来表示它们在高维空间的相似度,其中
用来表示它们在低维空间的相似度,其中dk和dl分别表示低维空间的第k和第l个低维样本;
根据标准化数据矩阵,用高斯分布构建高维空间高维样本之间的联合概率分布p,用来表示它们在高维空间的相似度;
用t分布构建低维空间对应低维样本之间的联合概率分布q,用来表示它们在低维空间的相似度;
使用梯度下降法优化p和q的相对熵c(kl散度),
使其达到最小,得到最优困惑度值,从而利用该最优困惑度值计算各个高维样本对应的低维表示d1,d2,...,dn,进而构造出低维数据矩阵d=[d1,d2,...,dn]。
4.构建并训练变分自编码器,构造联合特征矩阵;图2是采用变分自编码器提取特征流程图;
(1)给定参数初值,将上述低维矩阵d对应的第i个低维样本di输入到变分自编码器编码层,计算该低维样本对应特征的均值向量μi和标准差向量σi;利用模特卡洛模拟法从服从标准正态分布的总体中抽取一个采样值εi,从而计算出低维样本对应的初始特征vi=μi+εi×σi,i=1,2,...,n;
(2)将由编码层得到的第i个低维样本的初始特征vi输入变分自编码器解码层,得到对应的初始重构低维样本
(3)将所有低维样本的特征zi(i=1,2,…,n)排成矩阵,构造联合特征矩阵z=[z1,z2,...,zn]′。
5.利用改进的密度峰值聚类算法进行聚类包括以下步骤:
(1)给定预聚类的类别数k1(一般介于最终的聚类数和原始混合属性样本数之间),先利用模糊c-均值聚类算法对联合特征矩阵z对应的n个联合特征样本进行预聚类,得到每个联合特征样本隶属于每个簇的隶属度,按最大隶属度原则,确定每个联合特征样本的簇标号,计算每个联合特征样本到各个簇中心的距离,以及每个簇的半径rg(簇内联合特征样本到簇中心的最大距离),g=1,2,…,k1;
(2)根据给定的截断距离dc,对于任一联合特征样本zi(i=1,2,…,n),假设它的簇标号为g,对应的簇中心为cg,接下来确定zi的近邻样本:
i)近邻簇和外围簇内近邻样本的确定:zi所属簇的近邻簇内的所有联合特征样本均为zi的近邻样本,zi所属簇的外围簇内的所有联合特征样本均不是zi的近邻样本;
ii)所属簇内近邻样本的确定:
设d(zi,cg)表示zi和cg之间的距离,zt为第g个簇内的另一联合特征样本,d(zt,cg)表示zt和cg之间的距离,则有:
若d(zi,cg)<dc-rg,则第g个簇内除zi外的所有联合特征样本都是zi的近邻样本;
若︱d(zi,cg)-d(zt,cg)︱≥dc,则zt不是zi的近邻样本;
若以上两个条件均不满足,直接计算zi和zt之间的距离,若满足距离小于dc,则zt为zi的近邻样本;
iii)过渡簇内近邻样本的确定:
设zb为联合特征样本zi所在簇的过渡簇内的一个联合特征样本,对应簇标号为s,簇中心为cs,簇半径为rs,d(zi,cs)表示联合特征样本zi和过渡簇的簇中心cs之间的距离,则有:
若d(zi,cs)<dc-rg,则簇s内的所有联合特征样本都是zi的近邻样本;
若d(zi,cs)≥dc+rs或d(zi,cs)≥dc+rg,则簇s内的所有联合特征样本都不是zi的近邻样本;
若以上两个条件都不满足,直接计算zi和zb的距离,若满足距离小于dc,则zb为zi的近邻样本;
(3)统计联合特征样本zi的近邻样本的个数,即得到zi的局部密度ρi,i=1,2,…,n,并将所有联合特征样本的局部密度按从大到小排序;
(4)根据排序后的联合特征样本局部密度,计算联合特征样本zi与比其局部密度高的所有样本之间距离的最小值,即相对距离δi
其中i=1,2,…,n,dij表示第i个联合特征样本zi和第j个联合特征样本zj之间的距离;
(5)引入综合变量γi,表示第i个联合特征样本的局部密度ρi和相对距离δi的乘积,即γi=ρi×δi,i=1,2,…,n;
将联合特征样本的γi值按降序排列,根据给定的聚类数k,选取对应γi值最大的前k个联合特征样本作为簇中心,其余联合特征样本按最近邻簇中心对应的簇号作为该联合特征样本的簇号,从而得到联合特征矩阵对应的所有联合特征样本的聚类结果,该聚类结果也是与联合特征样本对应的原始混合属性样本的聚类结果。
- 还没有人留言评论。精彩留言会获得点赞!