一种基于知识图谱的影视择优推荐系统和方法与流程
本发明涉及一种基于知识图谱的影视择优推荐系统及方法,特别涉及一种基于突出权重的影视择优推荐方法。
背景技术:
影视节目是供人们在紧张学习工作之余的文化休闲娱乐产品,在社会生活中占据着越来越重要的地位。为了争夺这一市场,各种影视节目层出不穷,数目繁多。这一方面给观众带来巨大的困扰,另一方面也给影视节目运营服务商也带来了巨大的挑战。为了让已有的影视产生最大化的带来效益,各影视公司都在影视播放过程中不同程度的引入了影片推荐功能,以最大程度的吸引观众,提升观看量。遗憾的是,现有的推荐方法通常是基于内容或关联规则,这就造成推荐效果有限、热门项目被过度推荐不足等情况。针对目前存在的这些问题,一些学者将注意力转移到海量数据展示直观、关联查询效率高、知识推理逻辑能力强、搜索引擎语义理解准确性强等优势的知识图谱技术上,希望结合知识图谱的现有优势,达到对影视推荐效果的提升。从已经开展的特定垂直领域知识图谱应用效果看,知识图谱在推荐系统上已经被证明是极有价值的,如在医疗领域,通过构建医疗知识图谱,能帮助医生快速查找合适的诊断方案;在金融领域,通过构建金融知识图谱,能够让系统智能定位风险账号;在公共安全领域,通过构建公安知识图谱,能够协助警务人员快速锁定犯罪嫌疑人……遗憾的是在影视领域,基于知识图谱的影视个性化推荐的相关研究相对比较有限。目前基于知识图谱的知识推理的方法主要可分为基于逻辑的推理与基于图的推理两种类型。在基于图的推理方法中,一些典型的算法有path-constraintrandomwalk,pathranking等。然而最著名的却是taherh.haveliwala设计的personalrank算法,主要是利用了关系路径中的蕴涵信息,通过图中两个实体间的多步路径来预测它们之间的语义关系。即从源节点开始,在图上根据路径建模算法进行游走,如果能够达到目标节点,则推测源节点和目标节点间存在关系。该方法在时间复杂度上存在明显的缺陷,每次为每个用户推荐时,都需要在整个用户物品的二分图上进行迭代,直到整个图上每个节点收敛。这一过程时间复杂度非常高,无法达到实时推荐。
技术实现要素:
本发明的目的是针对目前现有的一些技术存在算法时间复杂度高、热门项目过度推荐、冷门项目推荐受限、数据稀疏和冷启动的不足而提出的一种基于知识图谱的影视择优推荐系统及方法,通过用户的搜索电影名称传入本发明推荐系统并从推荐系统通过本发明方法得到用户可能感兴趣的其他相关影视内容的结果,从而提高影视资源的利用率和降低用户的流失率,使现有影视资源最大化,具有实际的商业价值。
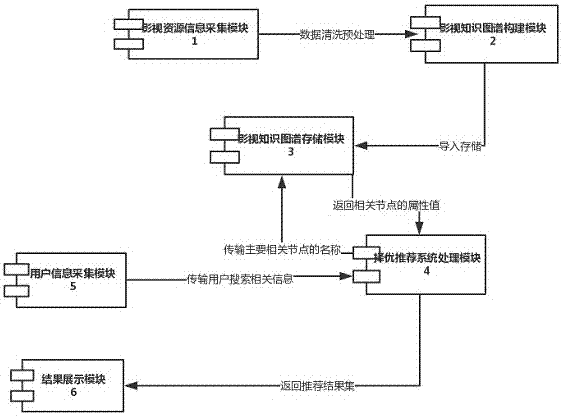
为了达到上述目的本发明的技术方案如下:一种基于知识图谱的影视择优推荐系统包括影视资源信息采集模块(1)、影视知识图谱构建模块(2)、影视知识图谱存储模块(3)、择优推荐系统处理模块(4)、用户信息采集模块(5)、结果展示模块(6),其特征在于:所述影视资源信息采集模块(1)经影视知识图谱构建模块(2)连接影视知识图谱存储模块(3),一个择优推荐系统处理模块(4)连接所述影视知识图谱存储模块(3),一个用户信息采集模块(5)和一个结果展示模块(6);所述影视资源信息采集模块(1)将从互联网网页上采集到的资源进行数据清洗传输到影视知识图谱构建模块(2),该模块(2)利用已经处理完的数据进行相关处理获得知识图谱的元素,再利用存储模块(3)进行知识图谱的存储与表示,从而真正构建了一个知识图谱;该知识图谱随时动态更新网上的相关影视资源信息,为精准推荐奠定基础;用户信息采集模块(5)是用来采集用户的搜索观看记录,然后将用户的相关观看信息传入择优推荐系统处理模块(4),通过该模块(4)的方法得到一个结果集并传入到结果展示模块(6),该模块(6)将推荐的结果列表展示给用户,让用户自行点击。
一种基于知识图谱的影视择优推荐方法,采用根据权利要求所述的基于知识图谱的影视择优推荐系统进行操作,其特征在于操作步骤如下:
1)影视资源信息采集模块(1)是利用爬虫技术从互联网的各大影视网站上爬取相关的影视信息,进行非结构化文本信息的处理,数据的清洗过程包含对获取到的数据源进行分词,标注命名实体以及语料格式转换;
2)影视知识图谱构建模块(2)是利用影视资源信息采集模块(1)数据清洗后得到的数据进行实体识别和实体关系抽取两个功能,该模块是基于人工规则和聚类算法混搭的技术,基于人工规则获取到实体名称,基于聚类算法获取到实体关系模式;
3)影视知识图谱存储模块(3)是将影视知识图谱构建模块(2)获取到的实体和实体关系导入图数据库neo4j中进行存储和真正地建构展示,图数据库中的边和点即代表知识图谱的实体间关系和实体名称;
4)以上模块(1)、(2)、(3)是为了随时更新知识图谱的影视知识,为后续精准推送奠定了基础。用户信息采集模块(5)是采用json形式传回后台解析用户的相关搜索观看记录,从中解析出用户看的电影名称、参演人名、导演、编剧等信息;并将这些信息传输给择优推荐系统处理模块(4)。
5)择优推荐系统处理模块(4)根据用户采集模块(5)得到的信息,从知识图谱中查询出所有符合传入实体名称和实体关系的所有相关影视节目节点,并利用基于知识图谱的择优推荐进行处理得到结果集,并将结果集传输给推荐结果展示模块(6);
6)推荐结果展示模块(6)主要是根据择优推荐系统处理模块(4)得到的数据从后台以json形式传给前端解析并以列表形式展示给用户,供用户随意选择。
基于知识图谱的影视择优推荐方法主要包含以下几个步骤:
5-1)用户输入的电影名称,影视知识图谱存储模块利用知识图谱的强大关联查询能力搜索出该部电影的所有现有知识图谱中相关相同的电影、演员、导演、编剧、剧情等的节点信息。同时判断用户搜索的电影是否含有同系列属性电影这个属性,如果有,放在推荐列表最前面。
5-2)再利用知识图谱将5-1)中已经遍历出的相关节点再一次遍历,查询到与这些相关节点相关的电影名称节点。
5-3)将5-2)得到的电影名称节点遍历,得到每一部电影中的导演、演员、编剧、剧情等相关因素内容节点。然后得到这些节点的影响指标属性值,例如人气排行榜、用户评分数、用户浏览量、用户评论数等。通过属性值的等级判定得到每个影响指标的权重比值,再判断是否有突出档级,如果有,则在权重比值的基础上增加相应地突出权重值。通过计算得到因素内容节点的热度值。
5-4)判断热度值的等级得到每个因素内容节点的权重值,在判断是否有突出档级,如果有,则在权重比值的基础上增加相应地突出权重值。再通过计算得到电影的播放评分值。
5-5)对5-4)计算出来的播放评分进行排序择优推荐,取出前topn名推荐给用户观看。如果播放评分低于某个值,也不进行推荐。
以上的步骤描述中,电影播放评分的计算公式如下所示:
αij为第j部电影中第i个影响因子的权重值,cij为第j部电影中第i个影响因子的档级,
μij是指第j部电影中第i个影响因子的突出权重值,cij是指第j部电影中第i个影响因子热度值aij的档位等级,
与现有技术相比,本发明具有如下显而易见的突出实质性特点和显著优点:本发明利用知识图谱的强大关联查询能力,在命中率有保证地基础上,克服了时间复杂度高,推荐覆盖率低的问题,使得同一资源情况下,收益能够达到最大化,具有实际的商业价值。
附图说明
图1是本发明的系统结构框图
图2是本发明方法的主程序框图
图3、4、5是本发明设计的实验方案在命中率、推荐覆盖率、时间性能指标上与其他算法的效果对比图
具体实施方式
以下结合附图详述本发明的优选实施例:实施例一:参见图1,本基于知识图谱的影视择优推荐系统包括影视资源信息采集模块(1)、影视知识图谱构建模块(2)、影视知识图谱存储模块(3)、择优推荐系统处理模块(4)、用户信息采集模块(5)、结果展示模块(6),其特征在于:所述影视资源信息采集模块(1)经影视知识图谱构建模块(2)连接影视知识图谱存储模块(3),一个择优推荐系统处理模块(4)连接所述影视知识图谱存储模块(3),一个用户信息采集模块(5)和一个结果展示模块(6);所述影视资源信息采集模块(1)将从互联网网页上采集到的资源进行数据清洗传输到影视知识图谱构建模块(2),该模块(2)利用已经处理完的数据进行相关处理获得知识图谱的元素,再利用存储模块(3)进行知识图谱的存储与表示,从而真正构建了一个知识图谱;该知识图谱随时动态更新网上的相关影视资源信息,为精准推荐奠定基础;用户信息采集模块(5)是用来采集用户的搜索观看记录,然后将用户的相关观看信息传入择优推荐系统处理模块(4),通过该模块(4)的方法得到一个结果集并传入到结果展示模块(6),该模块(6)将推荐的结果列表展示给用户,让用户自行点击。
实施例二:参见图2,本基于知识图谱的影视择优推荐方法,采用上述系统进行操作,主要包含以下几个步骤:
1)影视资源信息采集实例是利用爬虫技术从互联网的各大影视网站上爬取相关的影视信息,进行非结构化文本信息的处理,数据的清洗过程包含对获取到的数据源进行分词,标注命名实体以及语料格式转换。
2)影视知识图谱构建实例是利用影视资源信息采集模块数据清洗后得到的数据进行实体识别和实体关系抽取两个功能,该模块是基于人工规则和聚类算法混搭的技术,基于人工规则获取到实体名称,基于聚类算法获取到实体关系模式。
3)影视知识图谱存储实例是将影视知识图谱构建模块获取到的实体和实体关系导入图数据库neo4j中进行存储和真正地建构展示。图数据库中的边和点即代表知识图谱的实体间关系和实体名称。
4)以上实例是为了可以随时更新知识图谱的影视知识,为后续精准推送奠定了基础。用户信息采集实例是采用json形式传回后台解析用户的相关搜索观看记录,从中解析出用户看的电影名称、参演人名、导演、编剧等信息。并将这些信息传输给择优推荐系统处理模块。
5)择优推荐系统处理实例根据用户采集模块得到的信息,从知识图谱中查询出所有符合传入实体名称和实体关系的所有相关影视节目节点,并利用基于知识图谱的择优推荐方法进行处理得到结果集,并将结果集传输给推荐结果展示模块。
6)推荐结果展示实例主要是根据择优推荐系统处理模块得到的数据从后台以json形式传给前端解析并以列表形式展示给用户,供用户随意选择。
如上所述的基于知识图谱的影视择优推荐方法主要包含以下几个步骤:
5-1)用户输入的电影名称name,影视知识图谱存储实例利用知识图谱的强大关联查询能力搜索出该部电影的所有现有知识图谱中相关相同的电影、演员、导演、编剧、剧情等的节点信息并用iterable<node>存储节点。同时判断用户搜索的电影是否含有同系列属性电影series_video这个属性,如果有,放在推荐列表最前面。
5-2)再利用知识图谱将5-1)中已经遍历出的相关节点再一次遍历,查询到与这些相关节点相关的电影名称节点。
5-3)将5-2)得到的电影名称节点遍历,得到每一部电影中的导演、演员、编剧、剧情等相关因素内容节点。然后得到这些节点的影响指标属性值,例如人气排行榜(rankhot)、用户评分数(scorehot)、用户浏览量(scanhot)、用户评论数(peoplehot)等属性值。通过属性值的等级判定根据公式(2)得到每个影响指标的权重比值,再判断是否有突出档级,如果有,根据公式(3)则在权重比值的基础上增加相应地突出权重值。通过公式(1)计算得到因素内容节点的热度值。
5-4)根据公式(2)判断热度值的等级得到每个因素内容节点的权重值,在判断是否有突出档级,如果有,根据公式(3)则在权重比值的基础上增加相应地突出权重值。再通过公式(1)计算得到电影的播放评分值。
5-5)对5-4)计算出来的播放评分进行排序择优推荐,取出前topn名推荐给用户观看。如果播放评分低于某个值,也不进行推荐。
例如从知识图谱中取出了一部电影的相关信息,这部剧情电影的名称是孟买日记,他的编剧和导演都是基兰·拉奥,参演演员是阿米尔·汗。假设用户此时输入的电影名称就是孟买日记,所以根据输入的电影名称搜寻到基兰·拉奥编导过的其他电影,以及阿米尔·汗演过的其他电影,还有同属于剧情的其他电影,然后通过计算获取到的相关电影节点播放评分,取出前几名的播放评分推荐给用户。为了验证此模型的有效性和实时性,此次实验地全部过程都将用户评分数、人气排名书、用户浏览量、用户参与评论数等影响指标影响指标的最高档位级别定为10档,将演员、编剧、导演、剧情等影响因子的热度值的最高档位级别也定为10档,将持有突出权重的指定的档位等级标准线定为8档级,将常数c定为11。
通过设计3组实验方案分别与同类的算法personalrank在相同的数据集上进行推荐命中率、推荐覆盖率、时间性能3个评价指标的对比。具体的实验技术方案如下:
方案一:本发明提出的算法和其他算法关于推荐命中率hit_rate的对比。
方案二:本发明提出的算法和其他算法关于推荐覆盖率hit_c的对比。
方案三:本发明提出的算法和其它算法关于推荐时间性能hit_time的对比。
实验方案的结果记录如下表格1、表格2、表格3所示
表1方案一的实验结果记录
表2方案二的实验结果记录
表3方案三的实验结果记录
以上所述方法,基于任意一部电影的推荐结果,可以随机选取电影,并且其他同类算法计算的迭代次数是20次。但该评价指标会有一个最终上限,但其推荐命中率或者推荐覆盖率不能低于当前已投入影视应用的实际推荐效率。由模拟实验表明,该推荐策略是切实可行的。
- 还没有人留言评论。精彩留言会获得点赞!