基于信息增益与最大相关最小冗余二阶段特征选择方法与流程
本发明属于机器学习及自然语言处理领域,尤其是涉及一种基于信息增益与最大相关最小冗余二阶段特征选择方法。
背景技术
随着信息化时代的来临,能够获取到的信息数据量越来越大,特征维度也越来越高,尽管高维度能够让信息更加完整,但同时也增加了对分类器的要求,并且容易产生维度灾难的问题。文本的特征选取是从预处理过的文本中选择最具代表性的特征词集合,通过选择的特征子集达到降维的效果。传统的特征词选取的方法有信息增益(informationgain,ig),文本词频(documentfrequency,df),χ2统计量(chisquarestatistic,chi),词频-逆文本率(termfrequency-inversedocumentfrequency,tf-idf)等。这些传统的特征选取方法仅仅考虑了特征词与文本类别之间以及文本与文本之间的关系,没有考虑特征词之间的关系,特征词之间可能存在冗余,即需要对特征词进行二次提取,去掉冗余。文献[姚海明,王娜,齐妙,李研,改进的最大相关最小冗余特征选择方法研究,计算机工程与应用,2014,50(9):116-122.]通过最大相关最小冗余算法(minimumredundancymaximumrelevancy,mrmr)选择特征子集,并且利用t检验(t-test),χ2算法(chisquarestatistic)等作为特征子集的评价函数。文献[陈素萍,谢丽聪,一种文本特征选择方法的研究,计算机技术与发展,2009,19(2):112-115.]比较了信息增益、期望交叉熵(expectedcrossentropy,ece)、互信息(mutualinformation,mi)、χ2统计量以及mrmr算法,最终提出最大相关最小冗余mrmr模型的特征选择方法。该文献直接使用最大相关最小冗余mrmr算法进行特征子集的选择,虽然保证了特征子集语义的完整,但生成特征子集的计算代价较大。为了减小计算代价,文献[李军怀,付静飞,费蓉,王怀军,基于mrmr的文本分类特征选择方法,计算机科学,2016,43(10):225-228.]提出了提出了基于tf-idf与mrmr的二阶段特征选择方法。但文献[lbxu,jliu,wlzhou,qyan,adaptivena
技术实现要素:
本发明的目的在于为文本分类任务选取更加准确的特征集合,提出一种基于信息增益与最大相关最小冗余二阶段特征选择方法,实现特征词的准确选取,解决现有特征提取分类效果差、计算量大以及特征冗余等技术问题。
本发明是在传统信息增益算法的基础上增加第二阶段的最大相关最小冗余特征提取方法,并在其基础上增加类差分度思想,平衡传统的最大相关最小冗余方法在特征与类别以及特征与特征之间的比重,进而提升文本分类效果。本发明采用如下技术方案,一种基于信息增益与最大相关最小冗余二阶段特征选择方法,具体步骤如下:
1)利用信息增益算法初步选取特征词,得到特征词子集;
2)计算步骤1)得到的特征词与文本类别之间的互信息值;
3)计算特征词之间的互信息值;
4)计算特征词的类差分度;
5)计算特征词的类差分度差值;
6)将类差分度差值引入最大相关最小冗余mrmr算法进行二阶段特征词选取。
优选地,所述步骤1)利用信息增益算法初步选取特征词具体为:
特征词wi的信息增益ig(wi)计算如下:
其中,m表示文本类别总数,ct表示第t类文本,p(ct)表示ct类文本在总文本中出现的概率,p(wi)表示包含特征词wi的文本在总文本中出现的概率,p(ct|wi)表示文本包含特征词wi并且属于ct类的条件概率,
按信息增益从大到小选取信息增益最大的部分特征词,得到特征词子集。
优选地,所述步骤2)中计算步骤1)得到的特征词wi与文本类别集合c之间的互信息值,具体为:
特征词wi与文本类别集合c之间的互信息值i(wi;c)为
式中,m表示文本类别总数,ct表示第t类文本,p(wi,ct)表示ct类文本中包含特征词wi的概率;
优选地,所述步骤3)计算特征词之间的互信息值具体为:
特征词wi和特征词wj之间的互信息值i(wi;wj)为:
式中,p(wi,wj)表示同时包含特征词wi和特征词wj的文本在总文本中出现的概率,其中i≠j;
优选地,所述步骤4)计算特征词之间的类差分度具体为:
特征词wi的类差分度为:
式中,βt表示特征词wi在ct类中的类差分度;ac表示特征词wi的类间离散度;dct表示特征词wi在ct类中的类内耦合度;ft(wi)表示在ct类中包含特征词wi的文本数;
优选地,所述步骤5)计算类差分度差值具体为:
计算特征词wi的类差分度差值α:
式中,βmax1,βmax2分别表示特征词wi的类差分度最大值以及次大值,ac表示特征词wi的类间离散度,dcmin1,dcmin2分别表示特征词wi的类内耦合度最小值以及次小值,λ为常数。
优选地,所述步骤6)将类差分度差值引入最大相关最小冗余mrmr算法进行二阶段特征选取具体为:
选取第k个特征词的公式为:
式中,α表示特征词wi的类差分度差值;i(wi;c)表示特征词wi与文本类别集合c之间的互信息值;d1表示通过信息增益初步选取的特征词子集;sk-1表示二阶段特征已选择的特征词子集,其中k-1表示已选择的特征词个数;i(wi;wj)表示特征词wi和特征词wj之间的互信息值;
发明所达到的有益效果:本发明是一种基于信息增益与最大相关最小冗余二阶段特征选择方法,实现特征词的准确选取,解决现有特征提取分类效果差、计算量大以及特征冗余等技术问题。本发明通过信息增益选取一阶段特征集合,同时将类差分度思想引入最大相关最小冗余算法作为二阶段特征提取方法,进而提升特征集合选取的准确度;利用最大相关最小冗余算法对文本特征进行二阶段筛选,同时引入类差分度对最大相关最小冗余进行动态设置权重,继承了信息增益以及最大相关最小冗余算法的优点,提高了支持向量机分类器的性能;与仅使用信息增益以及未改进的最大相关最小冗余算法相比,本发明具有更好的鲁棒性,使其筛选的特征集合对类别集合中的类别都能保持良好的分类效果;在同等条件下,本发明筛选出的特征集合分类效果更好。
附图说明
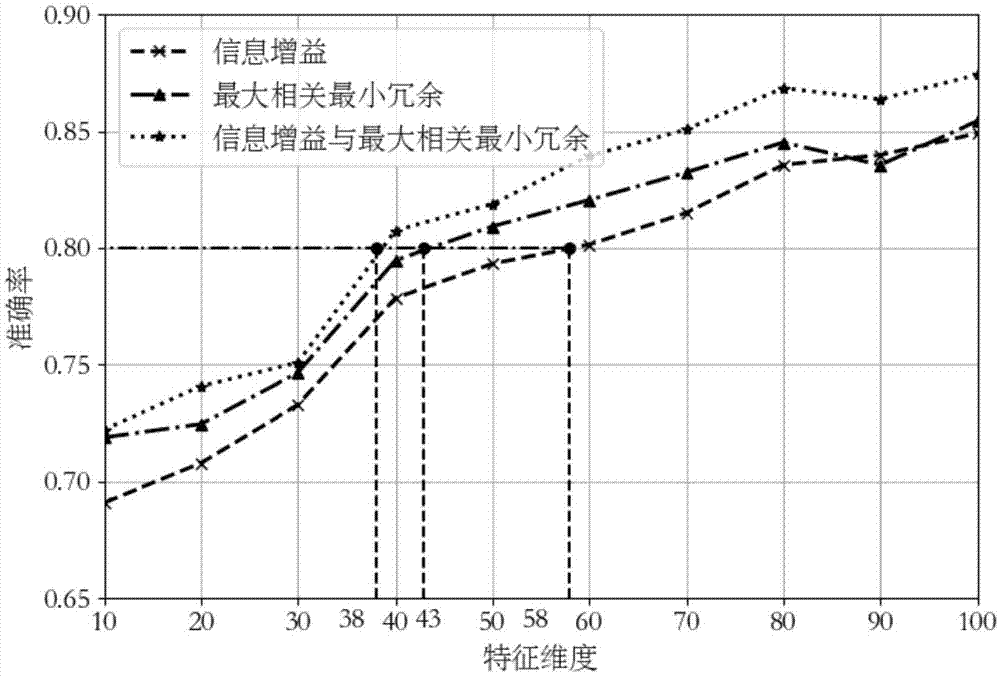
图1是本发明实施例中分别采用信息增益、信息增益与传统最大相关最小冗余以及本发明的三种特征选择方法在10~100维特征集合分类准确率仿真图;
图2是本发明实施例中分别采用信息增益、信息增益与传统最大相关最小冗余以及本发明的三种特征选择方法在100~1000维特征集合分类f1值仿真图。
具体实施方式
下面根据附图并结合实施例对本发明的技术方案作进一步阐述。
一种基于信息增益与最大相关最小冗余二阶段特征选择方法,具体步骤如下:
1)利用信息增益算法初步选取特征词,得到特征词子集;
特征词wi的信息增益ig(wi)计算如下:
其中,m表示文本类别总数,ct表示第t类文本,p(ct)表示ct类文本在总文本中出现的概率,p(wi)表示包含特征词wi的文本在总文本中出现的概率,p(ct|wi)表示文本包含特征词wi并且属于ct类的条件概率,
按信息增益从大到小选取信息增益最大的部分特征词,得到特征词子集。
2)计算步骤1)得到的特征词与文本类别之间的互信息值;
特征词wi与文本类别集合c之间的互信息值i(wi;c)为
式中,m表示文本类别总数,ct表示第t类文本,p(wi,ct)表示ct类文本中包含特征词wi的概率;
3)计算特征词之间的互信息值;
特征词wi和特征词wj之间的互信息值i(wi;wj)为:
式中,p(wi,wj)表示同时包含特征词wi和特征词wj的文本在总文本中出现的概率,其中i≠j;
4)计算特征词的类差分度;
特征词wi的类差分度为:
式中,βt表示特征词wi在ct类中的类差分度;ac表示特征词wi的类间离散度;dct表示特征词wi在ct类中的类内耦合度;ft(wi)表示在ct类中包含特征词wi的文本数;
5)计算特征词的类差分度差值;
计算特征词wi的类差分度差值α:
式中,βmax1,βmax2分别表示特征词wi的类差分度最大值以及次大值,ac表示特征词wi的类间离散度,dcmin1,dcmin2分别表示特征词wi的类内耦合度最小值以及次小值,λ为常数。
6)将类差分度差值引入最大相关最小冗余mrmr算法进行二阶段特征选取。
选取第k个特征词的公式为:
式中,α表示特征词wi的类差分度差值;i(wi;c)表示特征词wi与文本类别集合c之间的互信息值;d1表示通过信息增益初步选取的特征词子集;sk-1表示二阶段特征已选择的特征词子集,其中k-1表示已选择的特征词个数;i(wi;wj)表示特征词wi和特征词wj之间的互信息值;
结合仿真结果:
图1中可以看出传统信息增益算法在分类准确率达到80%时需要58个特征项,信息增益与传统最大相关最小冗余二阶段特征选取方法分类准确率达到80%时需要43个特征项,而本发明的特征提取方法在达到相同准确率时只需要38个特征项。由此可见本发明的特征选取方法能够利用更少的特征项达到好的预测结果;同时在选取的特征子集数量一致时,本发明的特征选取方法准确率最高,说明本发明的特征选择方法选择的特征项表征能力要优于其他两种方法。
图2中可以看出,当特征子集的维度在超过400维时,三个特征提取算法的综合分类率宏平均f1(macro-averaging)呈现下降的趋势,特征子集达到400维度左右时,能够准确区分文本类别的特征已经被筛选出来,再增加筛选的特征子集的维度,极可能将不相干的特征词筛选进入特征子集,造成干扰,从而导致分类效果下降。由于特征维度的增加,干扰的特征词增多,三种特征选择方法的分类效果都有所下降。但本发明的综合分类率宏平均f1仍高于其他两种方法,这也间接说明了本发明能够更加准确的优先提取出合适的特征子集,最大限度减少了干扰词的混入。
综上所述,本发明提出的基于信息增益与最大相关最小冗余二阶段特征选择方法能够有限提取出表征能力强的特征项,较好的避免了干扰词的混入,从而提升了分类器的分类效果。
- 还没有人留言评论。精彩留言会获得点赞!