一种能源一体化采集系统的多任务实时调度方法与流程
本发明涉及能源技术领域,具体涉及一种能源一体化采集系统的多任务实时调度方法。
背景技术:
《计量发展规划(2013-2020年)》、《关于促进智能电网发展的指导意见》、《关于推进“互联网+”智慧能源发展的指导意见》等一系列文件,明确提出“应完善信息资源共享机制,支持能源数据集抄集采,建设能源数据集成平台,鼓励基础设施共享复用”、“丰富智能终端高级量测系统的实施功能,促进水、气、热、电的远程自动集采集抄,实现多表合一”。
基于用电信息采集系统的基础上增加对水表、气表和热力表的采集,建立能源计量一体化采集系统,实现多表合一。但由于能源计量点数量成倍增加,现有用电信息采集系统难以适应电、水、气、热能源综合计量发展的新形势和新要求,主要表现在采集数据量增多,采集频度提高,对外共享接口增加,系统并发处理能力不足,需要存储和处理的数据量是海量级的,对主站系统的并行计算能力、大容量存储和快速的数据访问能力都提出了新的需求,现有系统架构、技术方案、采集终端和通信协议难以满足能源计量一体化采集的应用需求。传统用电信息采集系统的多任务并发处理策略通常是根据任务属性分类执行,造成部分任务长时间未得到响应,导致系统用户体验差,上述问题制约了新的能源一体化采集系统的进一步发展和应用,急需提出新的多任务实时调度方法解决以上问题。
技术实现要素:
为解决现有技术中的不足,本发明提供一种能源一体化采集系统的多任务实时调度方法,解决了传统能源采集系统的多任务并发处理由于部分任务长时间未得到响应,导致系统用户体验差的问题。
为了实现上述目标,本发明采用如下技术方案:一种能源一体化采集系统的多任务实时调度方法,其特征在于:包括步骤:
步骤1:当系统前置通信模块接收当前新加入任务时,计算该任务的初始参数;
步骤2:根据任务的有效期和价值密度,建立多任务调度的二维优先级表;
步骤3:通过多任务调度二维优先级表计算队列中所有任务的优先级;
步骤4:完成任务的优先级预处理后,根据优先级将任务排序,当任务优先级相同时,根据任务到达时间判断,先到的任务先加入前置通信模块的待处理任务队列;当前置通信模块的待处理任务队列个数已达预定值时,则进入spark集群master节点调度中心,否则继续循环步骤1-步骤4;
步骤5:spark集群master节点调度中心采用自适应任务调度策略,每个worker节点动态根据cpu利用率cu、内存利用率mu作为衡量节点负载及资源情况,定期动态调整其节点权值,master节点优先选择权值较大的worker节点执行任务;
步骤6:把新加入spark集群master节点调度中心的任务分配给步骤5选中的worker节点,任务进入相应节点执行。
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:所述步骤1中,任务用公式表示为:
ti=<ai,di,vi,ei,vedi>(1)
其中,i为任务序号;ai表示任务到达时间;di表示任务有效期;vi表示任务重要等级;ei表示任务紧急程度;vedi表示任务的价值密度,指任务的价值与任务执行所需时间的比值,价值密度计算公式为:
vedi=(vi×ei)/di(2)。
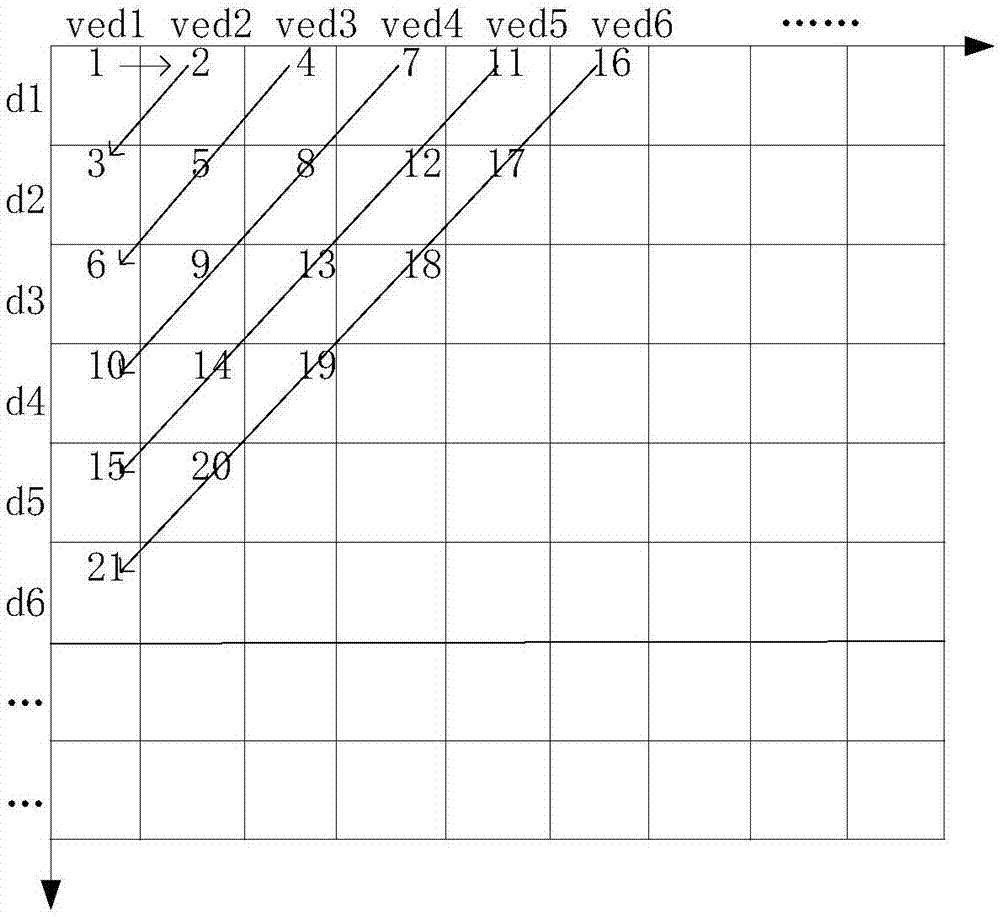
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:所述多任务调度的二维优先级表建立方法为:横轴表示任务的价值密度,从左至右,价值密度逐渐减小,对应优先级降序;纵轴表示任务的有效期,从上至下,有效期逐渐增大,对应优先级降序。
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:步骤3中,队列中所有任务的优先级p计算公式为:
p=(m+n-1)*(m+n-2)/2+m(3)
其中,m和n分别表示该任务在二维优先级表中对应的有效期和价值密度的坐标位置。
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:所述步骤5中,cpu利用率是通过连续两次的cpu采样值计算得到,定义公式如下:
cuk表示第k次实时监测的cpu利用率,k1表示第k次监测时第1次采样值,k2表示第k次监测时第2次采样值,cputimek2表示第k次监测时第2次采样的cpu工作时间和,cputimek1表示第k次监测时第1次采样的cpu工作时间和,cputotalk2表示第k次监测时第2次采样的cpu工作时间、空闲模式、磁盘i/o等待、硬件中断时间之和;cputotalk1表示第k次监测时第1次采样的cpu工作时间、空闲模式、磁盘i/o等待、硬件中断时间之和。
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:所述步骤5中,内存利用率定义公式如下:
muk表示第k次实时监测的内存利用率,totalk为第k次实时监测的总内存值,freek为第k次实时监测的空闲内存值,bufferk为第k次实时监测的buffer缓存大小,cachek为第k次实时监测的cache缓存大小。
前述的一种能源一体化采集系统的多任务实时调度方法,其特征是:第k次实时监测的worker节点的权值计算公式如下:
本发明所达到的有益效果:本发明充分考虑实时多任务的有效期和任务价值密度这两个参数,动态调整有效期-价值密度优先级表,实现多任务在过载的情况能自动降级,避免出现多米诺现象,提高任务处理性能,实现对多任务处理系统高效管理。
附图说明
图1是本发明多任务实时调度的二维优先级表图;
图2是本发明多任务实时调度的流程图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
能源一体化采集系统主要由系统主站、通信通道和采集设备组成,其中主站是系统的管理中心,位于系统的最上层,负责管理整个系统的正常运行以及安全,同时针对采集设备部分采集回来的用能信息进行处理分析,并与其他业务模块进行有效的数据信息交换。系统主站包括前置通信模块,用于负责各种终端任务远程调度,并负责协议解析。前置通信模块调度任务类型包括费控任务、参数任务、接口的数据召测任务、前置机内部自动召测任务等。
费控任务为:与用户用电费用相关如电价、费率、费率时段、阶梯、节假日等参数的设置任务。
参数任务为:终端档案参数、运行参数、电表参数等相关参数的集合任务统称为参数任务;
接口的数据召测任务为:外部服务器通过采集前置机对外开放的数据召测接口进行数据召测的任务称为接口的数据召测任务;
前置机内部自动召测任务为:采集前置机自身内部定时运行的数据召测任务称为前置机内部自动召测任务;
通信通道是主站与采集设备之间的桥梁,借助有限或无线的通信渠道为系统和终端设备建立链路链接,并以组网形式存在。采集设备主要通过各种传感设备和终端,为主站提供一手的信息和数据,并执行或转发主站下发的控制命令和信息。
由于任务类型的紧急性和时效性不同,因此本发明提出对任务的优先级预处理后进入能源一体化采集系统的spark集群master任务调度中心。
能源一体化采集系统采用基于spark集群架构,由于spark启用了内存分布数据集,提供了高性能和大数据的处理能力,出色的支持流计算和图计算,非常适合多次操作特定数据集的应用场景。spark集群包括master节点和worker节点,其中master节点负责管理集群和任务调度,而worker节点负责执行任务,master节点的任务调度策略采用fifo即先来先得和fair公平策略,未考虑到worker节点以及任务所需资源的差异,导致能源一体化采集系统的前置通信模块中时效性要求较高的任务因超时无响应,致使用户体验差,因此本文提出通过对spark集群master节点任务调度中心的多任务自适应调度策略来实现优先级高的任务及时执行,进一步提高任务的执行效率。
如图2所示,一种能源一体化采集系统的多任务实时调度方法,包括步骤:
步骤1:当系统前置通信模块接收当前新加入任务时,计算该任务的初始参数,任务用公式表示为:
ti=<ai,di,vi,ei,vedi>(1)
其中,i为任务序号;ai表示任务到达时间,即进入排队队列时间;di表示任务有效期,指该任务在指定时间点必须完成并产生结果输出,否则该任务无效,被弃之;
vi表示任务重要等级,将任务重要程度划分为五个等级:非常重要、重要、一般、不重要、非常不重要,可用数值5到1分别表示紧急程度,5为非常紧急,依次下降;能源一体化采集系统中费控任务、参数任务、接口的数据召测任务、前置内部自动召测任务的优先级从高到底;
ei表示任务紧急程度,将任务紧急程度划分为五个等级:非常紧急、紧急、一般、不紧急、非常不紧急,可用数值5到1分别表示紧急程度,5为非常紧急,依次下降。一般情况下由用户通过页面发起的接口数据召测任务与用户体验紧密相关,其等级划分为非常紧急,而前置内部自动召测任务的时间间隔最长,只需在截止时间完成即可,紧急等级划分为非常不紧急;
vedi表示任务的价值密度,指任务的价值与任务执行所需时间的比值,即单位时间内任务具备的价值,任务的价值为任务的紧急程度和重要程度的乘积,则价值密度计算公式为:
vedi=(vi×ei)/di(2)
步骤2:根据任务的有效期和价值密度,建立多任务调度的二维优先级表,如图1所示,建立方法为:横轴表示任务的价值密度vedi,从左至右,价值密度逐渐减小,对应优先级降序;纵轴表示任务的有效期di,从上至下,有效期逐渐增大,对应优先级降序;从表中,可以看出:任务优先级取决于价值密度和有效期;
步骤3:通过多任务调度二维优先级表并根据公式(3)计算队列中所有任务的优先级p:
p=(m+n-1)*(m+n-2)/2+m(3)
其中,m和n分别表示该任务在二维优先级表中对应的有效期和价值密度的坐标位置;
步骤4:完成任务的优先级预处理后,根据优先级将任务排序,当任务优先级相同时,根据任务到达时间ai判断,先到的任务先加入前置通信模块的待处理任务队列;当前置通信模块的待处理任务队列个数已达预定值时,则进入spark集群master节点调度中心,否则继续循环步骤1-步骤4;
步骤5:spark集群任务调度中心采用自适应任务调度策略,每个worker节点可以动态根据cpu利用率cu、内存利用率mu作为衡量节点负载及资源情况,定期动态调整其节点权值,master节点优先选择权值较大的worker节点执行任务。
其中:cpu利用率是通过连续两次的cpu采样值计算得到,定义公式如下:
cuk表示第k次实时监测的cpu利用率,k1表示第k次监测时第1次采样值,k2表示第k次监测时第2次采样值,cputimek2表示第k次监测时第2次采样的cpu工作时间和,cputimek1表示第k次监测时第1次采样的cpu工作时间和,cputotalk2表示第k次监测时第2次采样的cpu工作时间、空闲模式、磁盘i/o等待、硬件中断时间之和;cputotalk1表示第k次监测时第1次采样的cpu工作时间、空闲模式、磁盘i/o等待、硬件中断时间之和;。
内存利用率定义公式如下:
muk表示第k次实时监测的内存利用率,totalk为第k次实时监测的总内存值,freek为第k次实时监测的空闲内存值,bufferk为第k次实时监测的buffer缓存大小,cachek为第k次实时监测的cache缓存大小。
通过判断spark集群中所有worker节点的权值,按权值进行排序,master节点选取前预定个数的worker节点执行任务,第k次实时监测的worker节点的权值计算公式如下:
步骤6:把新加入spark集群master节点调度中心的任务分配给步骤5选中的worker节点,任务进入相应节点执行。
本发明提出一种基于有效期和价值密度的优先级预处理后,再通过监测计算spark集群节点的负载及资源利用率得到的参数,采用自适应任务调度策略。传统能源采集系统的多任务并发处理策略通常是根据任务属性分类执行,造成部分任务长时间未得到响应,导致系统用户体验差。本发明充分考虑实时多任务的有效期和任务价值密度这两个参数,动态调整有效期-价值密度优先级表,实现多任务在过载的情况能自动降级,避免出现多米诺现象,提高任务处理性能,实现对多任务处理系统高效管理。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!