数据处理流程设定方法和装置与流程
本说明书实施例涉及数据处理领域,更具体地,涉及数据处理流程设定方法和装置。
背景技术
针对互联网中海量规模、无限增长的大数据,机器学习是非常高效有用的工具。大数据是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。在针对大数据的机器学习领域,用户在样本生成,特征工程等方面投入的时间与精力占据了很大的比例。尤其在数据预处理时,用户需要读取各种数据源。如果数据量很大,超过单机的处理能力,则需要借助大数据计算平台,其调试逻辑往往相当耗时。目前常用的实时计算平台有storm、flink,spark等。对于用户暴露的接口,常见的是两种接口,sql接口;以及,基于面向流数据对象的开发接口。其中,sql要求数据结构化,而基于面向流数据对象的开发接口面向开发者,调试需要重新编译代码。而机器学习中常有复杂的流处理需求,如在线学习依赖的实时样本生成、特征抽取常涉及较为复杂的业务逻辑。因此,需要一种更有效的数据处理流程设定方案,以满足上述需求。
技术实现要素:
本说明书实施例旨在提供一种更有效的数据处理流程设定方法,以解决现有技术中的不足。
为实现上述目的,本说明书一个方面提供一种数据处理流程设定方法,包括:获取所述数据处理流程的语言描述,其中,所述语言描述包括,所述数据处理流程的输入数据集的名称、在所述数据处理流程中获取的各个中间数据集的名称、所述数据处理流程的输出数据集的名称、各个数据集之间的处理逻辑、以及与所述各个数据集分别对应的多个算子,其中所述多个算子用于施加与所述各个数据集分别对应的数据处理;获取配置信息,所述配置信息中包括对所述各个数据集和所述多个算子的配置;基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定。
在一个实施例中,在上述数据处理流程设定方法中,所述多个算子中包括用户自定义算子,所述方法还包括,在获取所述数据处理流程的语言描述之后,获取用于实现所述用户自定义算子的代码,以及其中,所述基于所述数据处理流程的语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定包括,基于所述语言描述、所述配置信息和所述代码,对用于实施所述数据处理流程的计算模块进行设定。
在一个实施例中,在上述数据处理流程设定方法中,所述语言描述为类dot语言描述,所述类dot语言以dot语言的语法结构对数据处理流程进行描述。
在一个实施例中,在上述数据处理流程设定方法中,所述类dot语言描述被保存为dot文件。
在一个实施例中,在上述数据处理流程设定方法中,所述配置信息配置所述多个算子的参数。
在一个实施例中,在上述数据处理流程设定方法中,所述语言描述与所述配置信息被保存在一个文件中。
在一个实施例中,在上述数据处理流程设定方法中,所述配置信息被保存为以下一种文件:conf文件、xml文件、yaml文件、json文件和properties文件。
在一个实施例中,在上述数据处理流程设定方法中,所述计算模块为外部计算平台,所述基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定包括,基于所述语言描述和所述配置文件,生成用于输入所述计算平台的任务代码,所述计算平台通过执行所述任务代码而实施所述数据处理流程。
在一个实施例中,在上述数据处理流程设定方法中,所述计算平台为以下任一种计算平台:storm、flink、spark和hadoop。
在一个实施例中,在上述数据处理流程设定方法中,所述输入数据集为批数据或流数据。
本说明书另一方面提供一种数据处理流程设定装置,包括:语言描述获取单元,配置为,获取所述数据处理流程的语言描述,其中,所述语言描述包括,所述数据处理流程的输入数据集的名称、在所述数据处理流程中获取的各个中间数据集的名称、所述数据处理流程的输出数据集的名称、各个数据集之间的处理逻辑、以及与所述各个数据集分别对应的多个算子,其中所述多个算子用于施加与所述各个数据集分别对应的数据处理;配置信息获取单元,配置为,获取配置信息,所述配置信息中包括对所述各个数据集和所述多个算子的配置;设定单元,配置为,基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定。
在一个实施例中,在上述数据处理流程设定装置中,所述多个算子中包括用户自定义算子,所述装置还包括,代码获取单元,配置为,在获取所述数据处理流程的语言描述之后,获取用于实现所述用户自定义算子的代码,以及其中,所述设定单元还配置为,基于所述语言描述、所述配置信息和所述代码,对用于实施所述数据处理流程的计算模块进行设定。
通过根据本说明书实施例的数据处理流程设定方案,可有效降低用户的接入门槛,加快模型迭代效率。用户可简洁直观地设定数据处理流程并对其进行改动,而不需要重新编译代码,并且本说明书实施例的方案不强制要求数据结构化,可以组建复杂计算需求,并且可以灵活地对数据处理流程进行调优。
附图说明
通过结合附图描述本说明书实施例,可以使得本说明书实施例更加清楚:
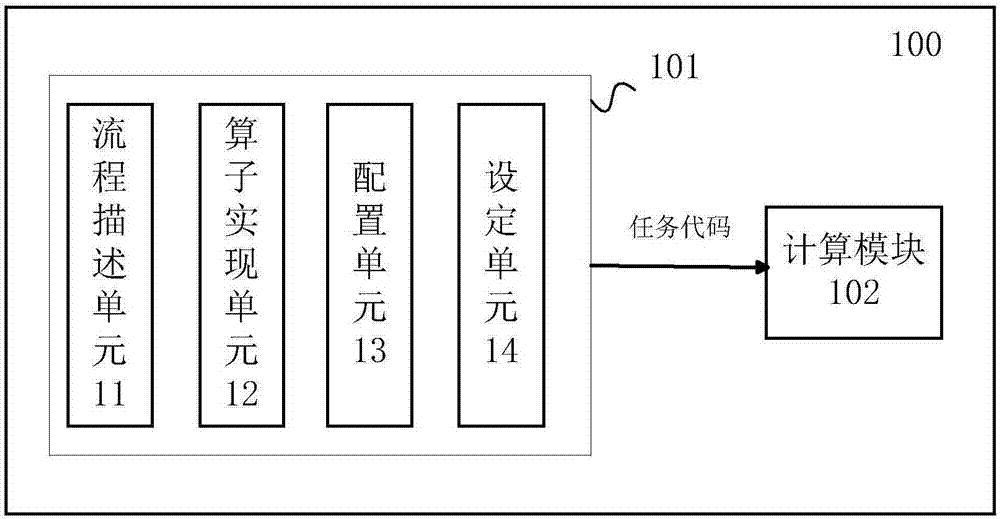
图1示出了根据本说明书实施例的系统100的示意图;
图2示出了根据本说明书实施例的数据处理流程设定方法;
图3示出了对数据处理流程的语言描述的示例;
图4示出了根据本说明书实施例的配置信息的示例;
图5示出了对数据处理流程的语言描述的又一示例;
图6示出了根据本说明书实施例的配置信息的又一示例;以及
图7示出了根据本说明书实施例的数据处理流程设定装置700。
具体实施方式
下面将结合附图描述本说明书实施例。
图1示出了根据本说明书实施例的系统100的示意图。系统100用于对输入数据集进行一系列的数据处理(即数据处理流程),以最终获取需要的数据集。这里,输入数据集可以是批数据或者流数据。在一个实例中,所述输入数据集是机器学习的源数据流(例如,购物平台用户在预定时段内的操作数据,如点击、曝光数据等),所述数据处理流程例如可以包括读取源数据流、对源数据流进行解析、过滤、分组等数据处理、以及写入输出数据流,所述输出数据流为将进行机器学习的样本数据集。
如图1所示,系统100包括开发模块101和计算模块102。其中,开发模块101包括流程描述单元11、算子实现单元12、配置单元13和设定单元14。其中,在流程描述单元11获取对所述数据处理流程的语言描述,所述语言描述描述数据处理流程的节点(各个数据集名称)、节点之间的关系(数据集处理的上下依赖关系)以及各个节点对应的算子。在算子实现单元12获取用于实现用户自定义算子的代码。在配置单元13获取对各个所述数据集和算子的配置,例如配置输入数据集的存储位置,配置算子的参数值等。设定单元14基于所述语言描述、所述算子代码和所述配置信息生成用于输入计算模块102的任务代码。最后计算模块102通过执行所述任务代码,从而实施所述数据处理流程。所述计算模块102可以是外部的计算平台,例如flink、spark等等,也可以是内部的计算平台。图1所示的系统100仅是示意性的,根据本说明书实施例的系统不限于图1所示的系统100,例如,在算子都是计算平台提供的算子的情况下,不需要提供算子的实现代码,从而不需要算子实现单元12。
图2示出了根据本说明书实施例的数据处理流程设定方法,该方法在用于实施数据处理流程的系统的开发模块中执行。包括:在步骤s21,获取所述数据处理流程的语言描述,其中,所述语言描述包括,所述数据处理流程的输入数据集的名称、在所述数据处理流程中获取的各个中间数据集的名称、所述数据处理流程的输出数据集的名称、各个数据集之间的处理逻辑、以及与所述各个数据集分别对应的多个算子,其中所述多个算子用于施加与所述各个数据集分别对应的数据处理;在步骤s22,获取配置信息,所述配置信息中包括对各个所述数据集和所述多个算子的配置;在步骤s23,基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定。
首先,在步骤s21,获取所述数据处理流程的语言描述,其中,所述语言描述包括,所述数据处理流程的输入数据集的名称、在所述数据处理流程中获取的各个中间数据集的名称、所述数据处理流程的输出数据集的名称、各个数据集之间的处理逻辑、以及与所述各个数据集分别对应的多个算子,其中所述多个算子用于施加与所述各个数据集分别对应的数据处理。
其中,输入数据集可以是批数据或者流数据,所述批数据为大容量静态数据集,其对应的数据处理为批处理,所述批处理操作所述批数据,并在计算过程完成后返回结果。所述流数据可视为随时间延续而无限增长的动态数据集合,其对应的数据处理为流处理,所述流处理适用于流数据的处理,其以低延迟对流数据进行计算和处理。
数据处理流程可以表示为dag图(有向无环图)、拓扑图等,数据处理流程通常包括多个数据处理阶段,可以以数据处理流程的输入数据集作为例如dag图的初始节点,以在数据处理流程中获取的中间数据集作为中间节点,以及,以数据处理流程的输出数据集作为终止节点。另外,在例如所述dag图中,通过数据集之间的箭头连接示出数据处理流程的处理逻辑,通过在各个节点处包括的算子示出各个处理阶段施加的处理。
所述语言描述即对例如上述dag图的语言描述,即,在所述语言描述中,所述数据处理流程的输入数据集名称即描述所述dag图的初始节点,所述数据处理流程中获取的中间数据集名称即描述所述dag图的中间节点,所述数据处理流程的输出数据集名称即描述所述dag图的终止节点,所述各个数据集之间的处理逻辑即描述所述dag图中的箭头指向,以及与各个数据集分别对应的多个算子即描述所述dag图中各个节点处包括的算子。
图3示出了对数据处理流程的语言描述的示例。图3所示的语言描述所使用的语言为类dot语言。dot语言本身是开源图像可视化工具包graphviz中用于画图的一种脚本语言,其可描述有向图和无向图,支持对图的每个节点和边配置相应的属性。图3所示的类dot语言通过借用dot语言的语法结构对数据处理流程图进行描述。所述类dot语言包括以下具体限定:(1)使用dag关键字用于声明有向图;(2){}表示数据处理流程的起始和终止,嵌套的{}表示流程中的子流程;(3)节点表示数据集,有向边表示数据集的上下游关系;(4)通过提供数据集名称和算子定义节点,数据集名称和算子之间以“:”作为分割符;(5)用户通过数据集名称引用数据集,同时作为与配置文件相关联的标记符;(6)在用户后续不需要引用数据集或者配置算子的情况中,可以仅提供算子,而不需提供数据集名称;(7)算子由算子名和算子参数组成.算子后的括号之间的字符串表示算子参数,双引号内的字符串表示用户自定义算子。
如图3所示,输入数据集为“click(点击)”数据集和“view(曝光)”数据集,其中,“click(点击)”和“view(曝光)”为输入数据集名称,其也为起始节点。其中,“kafkasource”为与“click(点击)”数据集和“view(曝光)”数据集对应的算子,其对应的数据处理为,从kafka中读取“click(点击)”数据集和“view(曝光)”数据集。图中的“->”即上述有向边,其表示数据处理流程的处理流向(处理逻辑),例如,对“click”数据集进行过滤处理,以获取“filter(过滤)”数据集。
所述“filter(过滤)”为中间节点的数据集名称,通过“:”与其隔开的为用于获取该数据集的算子,即“filter(过滤算子)”,而在“filter”后面的括号中的内容为其参数,例如,“from(选自)”和“type(类型)”等,该算子“filter”为计算模块或者计算平台中自带的算子,即,非自定义算子。这里,通过对数据集“click”进行通过算子“filter”的处理,即保留来自“apple”终端且类型为“test”的数据,从而获取数据集“filter”。
图3中的“_”表示匿名的数据集,在该节点中,通过使用“keyby(分组)”算子进行处理而获取该匿名数据集,其中“uid(用户标识)”为该算子的参数。该节点如上文第(6)项中所述,即,在用户后续不需要引用数据集或者配置算子的情况中,可以仅提供算子,而不需提供数据集名称。最后,“sink”为输出节点的数据集名称,其中,kafkasink为对应的算子,其用于将匿名数据集写入kafka。这里,对数据集“filter”进行算子“keyby”的处理获取匿名数据集,并且通过将匿名数据集写入kafka,从而获取输出数据集“sink”。
数据处理的业务人员在输入图3所示的语言描述之后可将其保存为dot文件,以使得系统的开发模块可通过读取该dot文件而获取所述语言描述。
图3所示的类dot语言描述只是示例性的,根据本说明书实施例的数据处理流程的语言描述不限于图3所示的形式,例如,在语言描述中可以去除dag声明,可以以其它字符串替换图3中的dag、{}、:、()等字符,可以以其它形式描述其中的有向边,等等。另外,根据本说明书实施例的语言描述还可以是其它图形描述语言,例如,google图形描述语言等。另外,所述语言描述不限于保存为dot文件,而是可以保存为任何开发模块可读取的文件。
再回到图2,在步骤s22,获取配置信息,所述配置信息中包括对所述各个数据集和所述多个算子的配置。图4示出了根据本说明书实施例的配置信息的示例。如图4所示,配置信息中对算子的配置可通过数据集名称与算子关联。例如,在“click”数据集名称后面的大括号中间的内容为对相应的算子“kafkasource”的配置,其中,kafka.cluster="test_cluster"配置在kafka中读取数据集“click”的集群,kafka.topic="click_log"配置在kafka中读取数据集“click”的主题(topic)。即,该配置限定了数据集“click”的获取位置,或者可以理解为获取地址,即,通过在"test_cluster"集群下的"click_log"主题中可读取数据集“click”。即,所述配置信息配置所述算子的参数。图4顶部的“job.name”限定将输入计算模块的任务代码的名称。另外,配置信息中还可以包括对数据集的配置(未示出),其中,通过数据集名称与数据集关联,例如,配置信息中可在数据集后面的大括号中配置数据集的存储位置、数据集的保存时间等。
当该数据处理流程的业务人员在输入上述配置信息之后,可将其与上述语言描述保存为一个文件,或者,也可以将该配置信息保存为单独的文件,例如如下一种文件:conf文件、xml文件、yaml文件、json文件和properties文件等。开发模块通过获取所述文件(例如conf文件)而获取所述配置信息。
在图2中的步骤s23,基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定。当所述数据集涉及的批数据或流数据规模较小时,所述计算模块可以与所述开发模块在一个服务器内。而当所述批数据或流数据数量很大时,则所述计算模块为大数据计算平台,例如storm、flink、spark、hadoop等等。对计算模块进行设定可以是生成用于输入计算模块的任务代码,然而,所述设定不限于该方式,其可以是其它方式,例如可通过在特定计算模块中设定相应参数而实施数据处理流程。
以计算模块为flink计算平台为例,开发模块基于所述语言描述和所述配置信息,生成输入flink平台的任务代码可包括以下步骤:将所述语言描述翻译成有向图结构;对有向图进行拓扑排序,然后根据算子的类型,将所述有向图翻译成flink的程序,例如,将算子kafkasource翻译成flink的sourcefunction,将算子keyby翻译成flink的keyby算子等;以及,根据所述配置信息,在flink程序中设置数据集的资源使用情况(如cpu,内存等)以及各个算子的参数,从而获取flink可执行的任务代码。开发模块在生成计算模块的任务代码之后,向计算模块(或者计算平台)提交所述任务代码,从而,所述计算平台可通过执行所述任务代码,而实施上述数据处理流程。
在一个实施例中,上述多个算子中包括用户自定义算子,在该情况中,上述方法还包括,在获取所述数据处理流程的语言描述之后,获取用于实现所述用户自定义算子的代码。例如,图5示出了对数据处理流程的语言描述的另一示例。如图5所示,在“parsed”之后的双引号内的字符串“com.antfin.aiflow.logparser”表示自定义算子。即,通过对输入数据集“click”和“view”进行通过自定义算子“com.antfin.aiflow.logparser”的处理(一种解析处理),从而获取数据集“parsed”。在该情况中,通过业务人员的输入,获取图3所示的自定义算子“com.antfin.aiflow.logparser”的实现代码,该代码一般通过java语言实现,其也可以通过其它语言实现。
图6示出了根据本说明书实施例的配置信息的又一示例。如图6所示,在“parsed”数据集名称后面的大括号中的内容为对图5中的自定义算子“com.antfin.aiflow.logparser”的配置,其中,“resource.paral”和“delimited”为该自定义算子中的参数。另外,相比于图4,图6顶部还包括jars="my_test.jar",其配置自定义算子的代码的获取方式(即代码名称)。
在上述包括用户自定义算子的情况中,所述开发模块基于所述语言描述、所述配置信息和所述代码生成计算模块的任务代码。例如,开发模块将流程描述语言中的“click:kafkasource->parsed:"com.antfin.aiflow.logparser"”翻译成:env.addsource(click).flatmap(newmyflatmapfunction("com.antfin.aiflow.logparser")),并在所述任务代码中包括该自定义算子的代码。
图7示出了根据本说明书实施例的数据处理流程设定装置700,包括:语言描述获取单元71,配置为,获取所述数据处理流程的语言描述,其中,所述语言描述包括,所述数据处理流程的输入数据集名称、所述数据处理流程各处理阶段获取的中间数据集名称、所述数据处理流程的输出数据集名称、所述各个数据集之间的处理逻辑、以及与各个所述中间数据集分别对应的多个算子,其中所述多个算子为所述各处理阶段分别对应的处理;配置信息获取单元72,配置为,获取配置信息,所述配置信息中包括对所述各个数据集和所述多个算子的配置;以及设定单元73,配置为,基于所述语言描述和所述配置信息,对用于实施所述数据处理流程的计算模块进行设定。
在一个实施例中,在上述数据处理流程设定装置700中,所述多个算子中包括用户自定义算子,所述装置还包括,代码获取单元74,配置为,在获取所述数据处理流程的语言描述之后,获取用于实现所述用户自定义算子的代码,以及其中,所述设定单元还配置为,基于所述语言描述、所述配置信息和所述代码,对用于实施所述数据处理流程的计算模块进行设定。
通过根据本说明书实施例的数据处理流程设定方案,通过数据处理流程的描述语言构建流程图,更加简洁直观;通过将描述语言与配置信息分开处理,能够将主体拓扑逻辑与配置相互隔离,使得计算逻辑更加独立清晰;用户可以更容易地对数据处理流程进行改动,例如,对于添加/删除算子,只需要在描述语言中添加/删除相应的节点后重新提交,而不需要重新编译代码;本说明书实施例的方案不要求数据结构化,可以组建复杂计算需求;通过配置文件可以灵活地对数据处理流程进行调优;另外,本说明书实施例方案可集成sql的部分算子,方便用户使用。
本领域普通技术人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执轨道,取决于技术方案的特定应用和设计约束条件。本领域普通技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执轨道的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!