基于谱聚类分析下多特征信息加权融合的故障诊断方法与流程
本发明涉及电厂设备故障诊断技术领域,尤其是涉及一种基于谱聚类分析下多特征信息加权融合的故障诊断方法。
背景技术:
当电厂设备发生故障时,监控系统会在较短时间内将大量的信息提供给运行人员,其中也包含了大量不必要上传的无用信息,给故障的及时处理带来了严重的阻碍。另外,scada/ems所能提供的信息有限,这些信息并不能完全满足运行人员对故障进行全面分析的需求,保护及开关的误动、拒动,以及因通信信道干扰所造成的信息缺失也均会使基于单一信息源的故障分析的准确性受到严重影响。而随着电厂自动化程度的不断提高以及各种智能电子设备的使用,运行人员可以获得更多的设备信息,且电力通信网的快速发展也使电网故障分析时利用多源信息成为可能。
因此,在智能化、规模化的背景下,有效地精简用于故障分析的信息,通过冗余、异构的多信息源数据融合,有效地减小因保护及开关的误动、拒动,以及因信道干扰造成的信息缺失等的影响,将大大有助于运行人员对故障的正确分析,进而保证及时对故障进行处理,从而保障电网的安全、稳定运行,具有现实的社会效益及其明显的经济效益。将svm与证据理论相结合在多信息融合的故障诊断中进行应用具有较好的应用前景,然而,由于证据合成时将每个证据体都视为同等重要,没有考虑到不同来源的证据对辨识框架中各命题的识别具有不同的可靠性这一事实,这就造成了合成结果不能反映客观事实的缺点。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于谱聚类分析下多特征信息加权融合的故障诊断方法。
本发明的目的可以通过以下技术方案来实现:
基于谱聚类分析下多特征信息加权融合的故障诊断方法,该方法包括以下步骤:
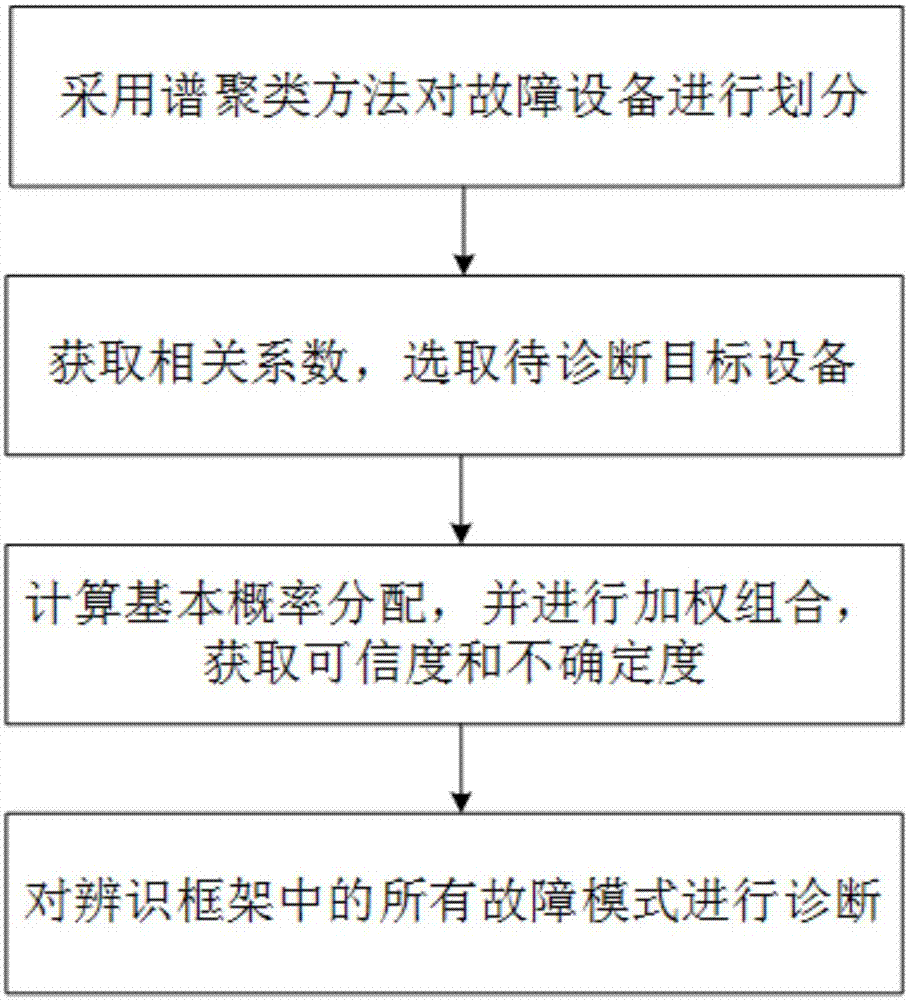
s1:对各个电厂故障设备进行判断,若某两个故障设备情况集中,则将二者置于同一分区,否则,采用谱聚类方法对故障设备进行划分,获取多个分区域;具体包括以下步骤:
11)将多个故障设备划分为同一样本集合:
假设有n个故障设备,则需要被划分的样本集合为:
x={x1,x2,...,xi,...,xn}∈rm×n
式中,rm×n为实数集,m为矩阵行数,xi为第i台故障设备中通过对该机组数据xi(t)进行采样所构成的参数集合,xi的表达式为:
xi={xi(1),xi(2),...,xi(t),,...,xi(m)}t
12)获取样本集合的markov转移矩阵:
将各个故障设备对应于高斯权重图的各个顶点,获取两点间的相似矩阵aij,其表达式为:
式中,|xi-xj|2为两点之间的欧几里得距离,σ为尺度参数;
则样本集合的markov转移矩阵pij为:
13)对markov转移矩阵进行谱分析,获取故障设备的划分区域数量:
假设某样本集合的markov转移矩阵为p,对其进行分解:
式中,λz为矩阵p的第z个特征值,
若矩阵p有q<n个主要特征值,其中λq<<λq-1,λ1,λ2,...,λq数值相近且趋于数值1,则p的相似矩阵pq可由前q个特征值和对应特征向量计算;若不符合前述情况,但矩阵p相邻特征值之间的差值骤降,即λq-λq+1>>λk-λk+1,q+1≤k≤n,λq+1值小于0.001,则依旧按照前述情况处理。
对相似矩阵pq获取谱分解式:
即q为所有故障设备中待划分区域数。
14)对样本集合中各个点进行扩散距离计算,确定划分区域:
定义映射ψ:
其中,ψ为r→r,设任意两故障设备xi与xj之间的扩散距离为:
式中,e1、...、en为x1、...、xn对应的单位向量;
根据λ1,λ2,...,λq及其特征向量,将xi与xj之间的扩散距离简化:
考虑各点间的扩散距离以及分区域数,给出定限值η>0,当d2(xi,xj)≤η时,确定其对应的故障设备划分在同一分区中。
s2:对各个分区域中的故障设备获取相关系数,并进行正序排序,将绝对值大于设定阈值的相关系数所对应的故障设备作为待诊断目标设备,具体内容包括:
21)假设存在某一个含有故障设备数为a的分区域,对其中故障设备分别进行编号:1,2,3,...,a,则第i个故障设备的相关系数ri为:
式中,b为采样数,xik为第i个分区域中,第k个采样点实测参数,yk为包含点k所在分区的实测参数;
22)对步骤21)获取的ri的绝对值按正序排序,将绝对值大且大于设定的阈值的故障设备,设为该分区域中的标准故障设备,具体条件如下:
式中,s为前s个相关性最高故障设备,rall为所有故障设备的相关系数。
s3:结合svm局部诊断及改进的证据理论方法,对待诊断目标设备的故障模式计算基本概率分配并进行加权组合,获取可信度和不确定度,具体内容包括:
31)对待诊断目标设备的故障模式获取特征向量,结合证据理论与svm局部诊断,获取各故障模式的证据体的隶属度;
假设辨识框架θ中共有l类故障模式,b为故障模式,
式中,f(bg,bh)为故障模式是属于bi类还是属于bh类的标准svm判决的硬输出,若属于bi类,则f(bg,bh)=+1,若属于bh类,则f(bg,bh)=-1,判决矩阵sm第一行表示第b1类与其他类两两分类的svm硬输出判决结果,判决矩阵第l行表示为第bl类与其他类两两分类的svm硬输出判决结果;
对判决矩阵sm的第h行向量可知,第bh类与其它类进行两两分类的总分类次数为(l-1)次,同时第h行判决硬输出为1的次数之和,即第bh类与其它类进行两两分类时判决属于第bj类的次数,将判决属于第bh类的分类次数与第bh类参与的总分类次数之比定义为第bh类的隶属度uh,其表达式为:
将不能确定属于任何一类的隶属度,定义为qθ:
uθ=1-max{u1,u2,…,ul}
则基本概率分配m(bh)的表达式为:
式中,m为svm多分类的规模;
32)根据证据体的隶属度获取svm的基本概率分配,并将各证据体按基本概率分配进行加权处理,获取多个证据加权融合后的最终诊断结果:
对于同一辨识框架θ,假设svm证据具体对辨识框架中c个命题的可靠度为re(b)→[0,1],则辨识框架θ上的可靠度加权系数v(b)为:
进行多证据加权融合,获取可信度w(b)和不确定度w(θ):
s4:根据可信度和不确定度对辨识框架中所有故障模式进行诊断:
设定诊断规则,根据诊断规则对诊断结果进行判断,假设诊断结果为fc,所述的诊断规则包括:
规则一:
规则二:w(fc)-w(fj)>ε;w(fc)>w(θ)
规则三:w(θ)<γ
规则一为诊断的基本条件,即所判定故障模式具有最大的可信度;规则二表明所判定故障模式的可信度必须比其它故障模式的可信度大,其中ε为设定的判定阈值;规则三表明不确定度必须小于阈值γ,保证故障样本是充分可判断的。
与现有技术相比,本发明具有以下优点:
(1)本发明方法先对电厂故障设备情况等进行现场考察,若两故障设备情况相对集中,各参数数据相差不多则放在同一个分区;反之,则采用谱聚类分析法划分该区域,在保证其准确性的同时,也提高了划分效率;
(2)本发明方法首先对故障设备进行谱聚类分析,以考虑不同来源的证据对辨识框架中各命题的识别具有不同的可靠性,其次通过获取各svm局部诊断证据对各故障模式的可靠度,同时由各svm局部诊断硬输出判决矩阵构造出基本概率分配,并对基本概率分配进行加权处理,降低了各svm局部诊断间的冲突,实现了svm和改进证据理论的有效结合,进而解决了识别的不可靠性造成的合成结果不能反映客观事实的缺点;
(3)本发明方法采用设定判断规则进行故障诊断,判定阈值可根据实际情况来选择,本发明方法可允许用户按照自己的需要建立融合多种数据的判断规则,并可自动积累,进而提高设备和部件分析和早期主动诊断的智能化程度。
附图说明
图1为本发明方法的流程图;
图2为高斯权重图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
如图1所示,本发明涉及一种基于谱聚类分析下多特征信息加权融合的故障诊断方法,包括以下步骤:
s1:对各个电厂故障设备进行判断,若某两个故障设备情况集中,则将二者置于同一分区,否则,采用谱聚类方法对故障设备进行划分,获取多个分区域;具体内容包括:
11)将多个故障设备划分为同一样本集合。
假设有n个故障设备,则需要被划分的样本集合为:
x={x1,x2,...,xi,...,xn}∈rm×n
式中,rm×n为实数集,m为矩阵行数,xi为第i台故障设备中通过对该机组数据xi(t)进行采样所构成的参数集合,xi的表达式为:
xi={xi(1),xi(2),...,xi(t),,...,xi(m)}t
12)获取样本集合的markov转移矩阵。
将各个故障设备对应于高斯权重图的各个顶点,如图2所示,获取两点间的相似矩阵aij,其表达式为:
式中,|xi-xj|2为两点之间的欧几里得距离,σ为尺度参数;
则样本集合的markov转移矩阵pij为:
13)对markov转移矩阵进行谱分析,获取故障设备的划分区域数量。
假设某样本集合的markov转移矩阵为p,对其进行分解:
式中,λz为矩阵p的第z个特征值,
若矩阵p有q<n个主要特征值,其中λq<<λq-1,λ1,λ2,...,λq数值相近且趋于数值1,则p的相似矩阵pq可由前q个特征值和对应特征向量计算;若不符合该情况,但矩阵p相邻特征值之间的差值骤降,即λq-λq+1>>λk-λk+1,q+1≤k≤n,λq+1值小于0.001,则依旧按照由前q个特征值和对应特征向量计算进行处理;
对相似矩阵pq获取谱分解式可得:
即q为所有故障设备中待划分区域数。
14)对样本集合中各个点进行扩散距离计算,确定划分区域。
定义映射ψ:
其中,ψ为r→r,设任意两故障设备xi与xj之间的扩散距离为:
式中,e1、...、en为x1、...、xn对应的单位向量;
根据λ1,λ2,...,λq及其特征向量,将xi与xj之间的扩散距离简化:
考虑各点间的扩散距离以及分区域数,给出定限值η>0,当d2(xi,xj)≤η时,确定其对应的故障设备划分在同一分区中。
s2:对各个分区域中的故障设备获取相关系数,并进行正序排序,选取绝对值大于设定阈值的相关系数所对应的故障设备作为待诊断目标设备;
s3:结合svm局部诊断及改进的证据理论方法,对待诊断目标设备的故障模式计算基本概率分配并进行加权组合,获取可信度和不确定度;具体包括以下步骤:
31)对待诊断目标设备的故障模式获取特征向量,结合证据理论与svm局部诊断,获取各故障模式的证据体的隶属度;
假设辨识框架θ中共有l类故障模式,b为故障模式,
式中,f(bg,bh)为故障模式是属于bi类还是属于bh类的标准svm判决的硬输出,若属于bi类,则f(bg,bh)=+1,若属于bh类,则f(bg,bh)=-1,判决矩阵sm第一行表示第b1类与其他类两两分类的svm硬输出判决结果,判决矩阵第l行表示为第bl类与其他类两两分类的svm硬输出判决结果;
对判决矩阵sm的第h行向量可知,第bh类与其它类进行两两分类的总分类次数为(l-1)次,同时第h行判决硬输出为1的次数之和,即第bh类与其它类进行两两分类时判决属于第bj类的次数,将判决属于第bh类的分类次数与第bh类参与的总分类次数之比定义为第bh类的隶属度uh,其表达式为:
将不能确定属于任何一类的隶属度,定义为qθ:
uθ=1-max{u1,u2,...,ul}
则基本概率分配m(bh)的表达式为:
式中,m为svm多分类的规模;
32)根据证据体的隶属度获取svm的基本概率分配,并将各证据体按基本概率分配进行加权处理,获取多个证据加权融合后的最终诊断结果:
对于同一辨识框架θ,假设svm证据具体对辨识框架中c个命题的可靠度为re(b)→[0,1],则辨识框架θ上的可靠度加权系数v(b)为:
进行多证据加权融合,获取可信度w(b)和不确定度w(θ):
s4:根据获取的可信度和不确定度,对辨识框架中所有的故障模式进行诊断;
设定诊断规则,根据诊断规则对诊断结果进行判断,假设诊断结果为fc,本发明设定的诊断规则包括:
规则一:
规则二:w(fc)-w(fj)>ε;w(fc)>w(θ)
规则三:w(θ)<γ
规则一为诊断的基本条件,即所判定故障模式具有最大的可信度;规则二表明所判定故障模式的可信度必须比其它故障模式的可信度大,其中ε为设定的判定阈值;规则三表明不确定度必须小于阈值γ,保证故障样本是充分可判断的。
本实施例以发电机转子的正常、不平衡、不对中、径向碰磨和油膜涡动五种单一工况故障模式的诊断识别为例来证明本发明方法的有效性及应用型。本实施例中的故障设备共有23台。
建立概率转移矩阵pp、pq:
markov概率转移矩阵谱分析:
计算pp和pq特征值得:
λp=[λ1,λ2,λ3,...,λ23]
=[1,0.904,0.798,0.4187,...,0.1135];λq=[λ1,λ2,λ3,...,λ23]
=[1,0.812,0.735,0.554,0.52,...,0.158];
由上可知,pp、pq均为前三个特征值间数值差较大,之后的特征值间数值差则相对较小。因此,应该将其分为三个区域。
分区域划分
设定限值η为0.4。对于故障设备13号、6号的划分仍有争议,两故障设备与各个分区域的有功无功距离计算结果分别为:0.4128、0.3583、0.3675、0.4174、0.3897、0.4415;0.4344、0.3609、0.3713、0.4132、0.3941、0.4064。
由算术平均值法可计算出13号故障设备、6号故障设备与各个分区域间的相似距离为:0.3854、0.3925、0.4156;0.3976、0.3922、0.4002。因此13号故障设备应该纳入1号分区域;6号故障设备应该纳入到2号分区域。因此、最后的分配结果如表1所示:
表1分区域划分结果
本实施例以2号分区域作为分析对象,其他分区域的分析方法可同理。由计算可得6、10、11、16、18、23号机组相关系数是0.010、0.38、0.17、0.200、1.028、0.828。分析可知,18、23号相关系数最高。因此,该分区域的标准故障设备为18号、23号,即该分区域的标准故障设备群由18号、23号组成。
系统辨识框架为θ={b1,b2,b3,b4,b5},其中b1为正常状态,b2为不平衡状态,b3为不对中状态,b4为径向碰磨状态,b5为油膜涡动状态。这里的数据主要是布置在轴承座水平和垂直方向上测点得到的振动信号。
分析辨识框架中各故障模式的发生机理,分别从转轴振动信号中提取频域小波能量分析特征向量(λ1,λ2,…,λ6)、时域ar模型自回归参数特征向量(α1,α2,…,α15)和轴心轨迹不变矩特征向量(β1,β2,…,β10)作为三个独立特征向量子空间,从不同侧面对设备进行局部诊断。
基于频域小波能量分析特征向量搭建svm进行局部诊断作为证据体一,并选取各故障模式下典型样本各100组进行测试,得到该证据体一的混淆矩阵cm1:
基于时域ar模型自回归参数特征向量搭建svm进行局部诊断作为证据体二,同样选取各故障模式下典型样本各100组进行测试,得到该证据体二的混淆矩阵cm2:
基于轴心轨迹不变矩特征向量搭建svm进行局部诊断作为证据体三,同样选取各故障模式下典型样本各100组进行测试,得到该证据体三的混淆矩阵cm3:
对混淆矩阵cm1、cm2、cm3进行计算得到三个证据体对转子五种故障模式识别的可靠度如表2所示;取故障模式类别l=5得到各证据体对各状态模式的加权系数如表3所示。
表2各证据体识别的可靠度
表3各证据体的加权系数
现取该转子的一组不平衡状态(b2)信号样本,分别提取其频域、时域和轴心轨迹特征向量,通过各单一特征svm局部诊断获得各证据体对各故障模式的“一对一”多分类svm判决(投票)结果统计如表4所示;根据svm局部诊断获取的证据体的隶属度、基本概率分配分别如表5、如表6所示;加权后的概率分配如表7所示;进行多证据的合成运算后的结果及采用传统s证据理论的计算对比结果如表8所示。
表4“一对一”多分类svm判决(投票)结果
表5各证据体的隶属度
表6各证据体的概率分配
表7各证据体的加权概率分配
表8多证据体证据融合诊断对比
由表4、表5和表6可以看出,三个svm单一特征局部诊断证据的判决结论冲突严重,不利于多证据的融合诊断。但从表6、表7的对比可看出,当各证据体被加权处理后,证据g1对b2正确识别的可信度从0.4511提升到0.6499;证据g3对b4错误识别的可信度从0.4511下降到0.2640。由此可见,各svm单一特征局部诊断证据体通过加权处理后正确识别的可信度能够提升,错误识别的可信度能够下降,各证据体间的冲突明显减小,有利于提高多证据融合诊断的准确率。
从表8中可以看出,传统的d-s证据理论对g1、g2、g3融合后对b2正确识别的可信度和对b4错误识别的可信度都是0.3793,无法对故障模式进行正确诊断;但采用改进后的加权证据理论对多证据体进行加权合成,g1、g2、g3融合后对b2正确识别的可信度提升到了0.6174,对b4错误识别的可信度下降到了0.1596,能够正确诊断该故障模式为b2。由此可见,多证据体通过加权合成处理后能够使得正确识别的结论相互加强,错误识别的结论相互削弱,融合诊断后的结果可信度具有更好的峰值性和可分性,从而能够提高故障诊断系统对故障模式的诊断识别能力。
为了评估该融合诊断系统的性能,选取不同故障模式下典型样本各100组分别进行单一特征的svm故障诊断和多特征融合的svm-ds故障诊断测试,在相同的决策规则下(ε=0.40,γ=0.20),诊断识别结果对比如表9所示。
表9测试样本故障诊断识别结果对比
识别率越高,则诊断越准确,从表9的对比结果可以看出,加权证据融合svm-ds的识别率达到0.88,远远高于其他方法,可以证明本发明提出的方法确实能够有效提高故障诊断的准确率。本发明提出的谱聚类分析下,结合svm和改进证据理论的多数据融合故障诊断方法具有很好的应用前景,在实际使用时需要充分结合电厂实际需求,确定需要接入的数据源,根据电厂实际情况完成基于svm和改进证据理论的多数据融合故障诊断方法的实施。充分发挥电厂工程师在实际设备方面的技术优势,将这些经验转化为系统的规则,在使用过程中可以不断扩充规则内容和使用方法,使得整个故障诊断系统更智能,更人性,更高效。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的工作人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!