云环境下基于密文的多关键词模糊查询方法与流程
本发明涉及数据处理
技术领域:
,尤其涉及一种云环境下基于密文的多关键词模糊查询方法。
背景技术:
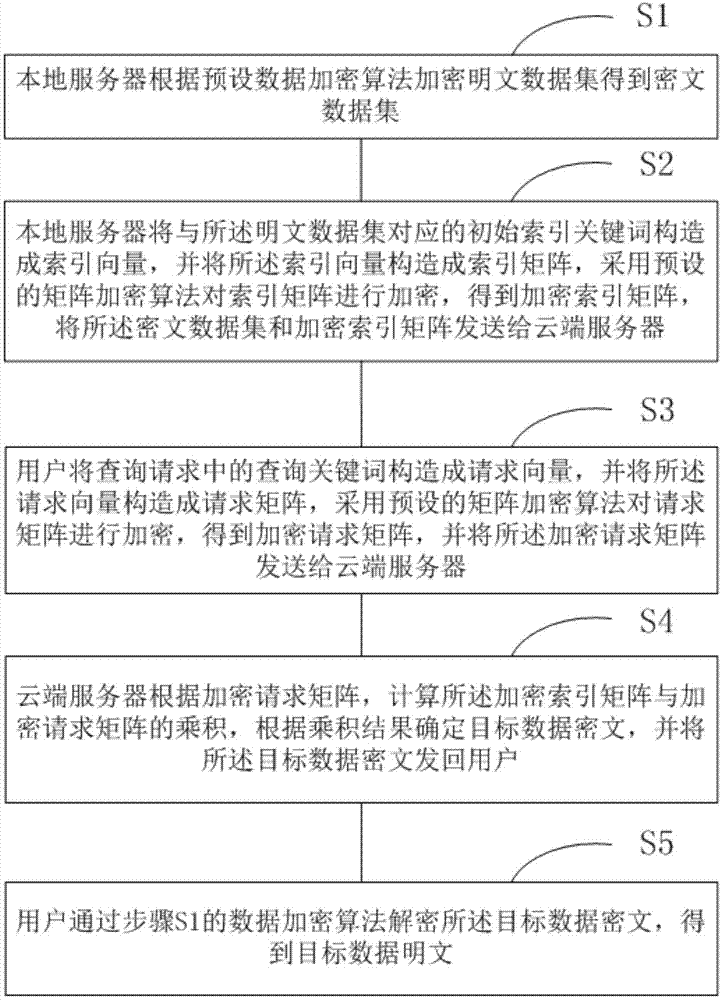
:云计算的出现和发展,实现了人类将计算作为一种基础设施的梦想。云计算是一种基于互联网的计算方式,处于共享状态的软件硬件资源和信息可以按照需求提供给网络中的计算机和其他设备使用。然而,云计算在有效地解决用户资源受限状况的同时,也带来了新的、不容忽视的安全问题。为了保护存储在云服务器上的敏感隐私数据不被泄露,用户必须将数据进行加密处理后存储在云平台。现有的基于关键词的可搜索密文模糊查询技术允许用户输入中含有微小的错误和形式不一致的问题,极大地提高了系统的可用性和用户搜索体验。然而,现有的方案中存在如下方面的缺陷:(1)更新删除不灵活:现有方案需要一个预定义字典,字典包含每个关键词可能的错误形式,这就导致查询和更新的效率比较低;(2)现有方案运算效率低:因为现有方案中,支持多关键词查询的方法需要多轮运算才能得到结果,因此运算效率低;(3)现有方案不支持灵活的and/or查询;(4)现有方案无法抵抗选择明文攻击,安全性较低。技术实现要素:为了解决现有技术中存在的上述问题,本发明提供了一种云环境下基于密文的多关键词模糊查询方法。本方法引入通配符来解决多关键词模糊查询问题,淘汰预设字典的方式,提供了高效的更新删除文件索引;同时,本方法支持多关键词的一轮运算,减少运算次数;再者,本方法有着较高的查准率和查全率,提供十分灵活的and/or查询,即本方法既支持关键词之间的逻辑并查询,又支持关键词之间的逻辑或查询。本发明提供了一种云环境下基于密文的多关键词模糊查询方法,包括:步骤s1:本地服务器根据预设数据加密算法加密明文数据集得到密文数据集;步骤s2:本地服务器将与所述明文数据集对应的初始索引关键词构造成索引向量,并将所述索引向量构造成索引矩阵,采用预设的矩阵加密算法对索引矩阵进行加密,得到加密索引矩阵,将所述密文数据集和加密索引矩阵发送给云端服务器;步骤s3:用户将查询请求中的查询关键词构造成请求向量,并将所述请求向量构造成请求矩阵,采用预设的矩阵加密算法对请求矩阵进行加密,得到加密请求矩阵,并将所述加密请求矩阵发送给云端服务器;步骤s4:云端服务器根据加密请求矩阵,计算所述加密索引矩阵与加密请求矩阵的乘积,根据乘积结果确定目标数据密文,并将所述目标数据密文发回用户;步骤s5:用户通过步骤s1的数据加密算法解密所述目标数据密文,得到目标数据明文;其中,每一个所述初始索引关键词对应一个索引向量;所述索引矩阵的每一行元素对应一个索引向量;所述查询请求中的查询关键词包含通配符;所述查询请求中的查询关键词通过逻辑运算符连接;所述逻辑运算符包括“and”或者“or”。本发明提供的方法,通过将初始索引关键词构造成索引向量进而构造索引矩阵再进而加密得到加密索引矩阵,将查询关键词构造为请求向量进而构造查询矩阵再进而加密得到加密请求矩阵,通过计算加密索引矩阵与加密请求矩阵的乘积来确定目标数据密文。采用本发明提供的方法构造向量和矩阵后,只有当矩阵中某一个索引向量与请求向量乘积为整数时,该索引向量对应的数据密文才是目标数据密文。同时,本发明方案中的查询关键词包含通配符,在构造请求向量时,考虑通配符的影响,对请求向量进行相应处理,由此可以实现模糊查询功能。通配符可以代表任何不确定的英文字母,例如当查询关键词为“**sure”时,“unsure”和“insure”均为正确的查询结果。因为本发明方案中的查询请求中的查询关键词之间存在逻辑运算关系(即逻辑和或者逻辑或),所以,本发明还可以实现逻辑查询。在本发明方案中,关键词包含两种类型,一种是精确关键词,另一种是模糊关键词。初始索引关键词只能为精确关键词,而查询关键词可以是精确关键词,也可以是包含通配符的模糊关键词。在现有技术中,假设有查询关键字w1,w2,w3,需要先查出含有w1的文件集d(w1),再从文件集d(w1)中查出含有w2的文件集d(w1∩w2),最后从文件集d(w1∩w2)中查出含有w3的文件集d(w1∩w2∩w3),这样就是3轮运算得到同时含有w1,w2和w3的文件集,相当于执行了3次查询算法。而本发明方案支持逻辑运算关系,可以实现逻辑查询,只需执行一次查询算法得到目标文件d(w1∩w2∩w3)。进一步的,所述预设的矩阵加密算法为knn算法;所述预设的矩阵加密算法的密钥为sk,密钥sk至少包括:素数序列表p、补全字母表s和可逆加密矩阵m;所述素数序列表p={p1,...,pi,...pl},其中,每一个元素pi均为一个随机产生的素数;所述补全字母表s={s1,...,si,...sl},其中,每一个元素si均为从26个英文字母顺序词典字母表中随机选取的英文字母,所述可逆加密矩阵m={m1,m2,s},其中,m1和m2均为大小为d×d的可逆矩阵,m1和m2相应的逆矩阵分别表示为m1-1和m2-1,s是一个列数为d的一维矩阵,矩阵元素的值为0或1,通过伪随机数函数生成;其中,d≥26,l大于或等于长度最长的所述初始索引关键词所包含的字母个数,且d和l均为正整数。现有文献资料《secureknncomputationonencrypteddatabases》(w.k.wong,d.w.-l.cheung,b.kao,andn.mamoulis,proc.ofsigmod,2009)公开了将knn算法用于加密处理的方法,本发明则利用knn算法来加密本方案中涉及的向量,从而加强方案中涉及向量的加密安全性。其中,素数序列表由随机生成的素数按从小到大的顺序排列组成。l的取值由初始索引中长度最长的关键词决定,l的取值应该大于或者等于该关键词所包含的字母总数。出于方案正确性考虑,d的取值应该大于或等于26;出于安全性考虑,d的取值最好是大于或等于128。顺序词典字母表中的英文字母不区分大小写。补全字母表中的字母为随机顺序,进一步增加本发明方案的安全性。进一步的,根据如下步骤构造每一个初始索引关键词wi,k对应的d维索引向量pi,k:步骤s201:将初始索引关键词wi,k的字母个数补全到统一长度l;判断初始索引关键词wi,k包含的字母个数||wi,k||:当||wi,k||<l时,从所述补全字母表s中顺序选取l-||wi,k||个字母补全初始索引关键词wi,k,使得||wi,k||=l;当||wi,k||≥l时,直接执行步骤s202;步骤s202:初始化d维索引向量pi,k,将索引向量pi,k的所有元素均设为1,使pi,k[l]=1,l∈[1,d],l为整数;其中,pi,k[l]表示索引向量pi,k第l位元素的初始值;步骤s203:选取初始索引关键词wi,k包含的字母在索引向量pi,k中的填充位置;依次将索引向量pi,k的第posl位确定为初始索引关键词wi,k包含的第l位的字母的填充位置;其中,posl=fkf(wi,k[l]),fkf()为伪随机数函数,wi,k[l]表示初始索引关键词wi,k包含的第l位的字母,l∈[1,l];步骤s204:更新索引向量pi,k的第posl位上的值pi,k[posl];其中,pi,k[posl]=pi,k[posl]/pl;pi,k[posl]的初始值为pi,k[l],pl为所述素数序列表p中第l位的素数,l∈[1,l];步骤s205:随机选取一个自然数α,将索引向量pi,k中仍为初始值1的位置的值替换为α,得到最终的索引向量pi,k。在构造索引向量时,第一步是将所有的初始索引关键词补全为统一长度,对于长度不够的初始索引关键词,采用从补全字母表中选取字母直接补充到初始索引关键词原字母后面的方式补全初始索引关键词。而向量构造过程的总体思路为“先选位,再算值”,步骤s203用于选取初始索引关键词中每一个字母在索引向量中所处的位置,步骤s204用于确定每一个字母在向量中对应位置所填充的值。而步骤s205的作用在于明文数据集中即使有两个数据均包含同一个初始索引关键词,而这两个数据对应的初始索引关键词的索引向量也会不一样,学术上称为“indexindistinguishability”(索引不可区分),从而提高方案的安全性。进一步的,根据如下步骤将由索引向量pi,k构成的索引向量集pi构造为索引矩阵ai,并通过knn算法对索引矩阵ai进行加密处理:步骤s211:依次将索引向量集pi={pi,1,...,pi,k,...,pi,mi}中的pi,k放置在索引矩阵ai的第k行中,得到一个大小为mi×d的索引矩阵ai,k∈[1,mi];步骤s212:根据索引矩阵ai生成两个大小为mi×d的矩阵ai'和ai",生成规则如下:对于索引矩阵ai的每一行ai[k][*]:若s[j]=0,则ai'[k][j]=ai"[k][j]=ai[k][j];若s[j]=1,则ai'[k][j]+ai"[k][j]=ai[k][j];其中,s[j]表示所述密钥sk中的一维矩阵s的第j位,ai[k][j]表示索引矩阵ai中第k行第j列的元素,ai'[k][j]表示矩阵ai'中第k行第j列的元素,ai"[k][j]表示矩阵ai"中第k行第j列的元素,j∈[1,d];步骤s213:将矩阵ai'和ai"分别与所述m1和m2相乘,得到加密索引矩阵ii;其中,ii=(ii',ii")=(ai'·m1,ai"·m2),·表示两个矩阵相乘。在本发明方案中,先将索引向量构造成索引矩阵,然后采用knn算法对索引矩阵进行加密处理,得到加密索引矩阵。由此使得在本方案中的数据交互过程中传输的索引内容均为加密内容,进一步提高了方案的安全性。进一步的,根据如下步骤构造每一个查询关键词对应的d维请求向量qj,k:步骤s301:将查询关键词的字母个数补全到统一长度l;判断查询关键词包含的字母个数当时,从所述补全字母表s中顺序选取个字母补全查询关键词的原字母后面,使得当时,直接执行步骤s302;步骤s302:初始化d维请求向量qj,k,将请求向量qj,k的所有元素均设为1,使qj,k[l]=1,l∈[1,d],l为整数;其中,qj,k[l]表示请求向量qj,k第l位元素的初始值;步骤s303:选取查询关键词包含的字母在请求向量qj,k中的填充位置,并更新请求向量qj,k的第l位上的值qj,k[posl];当时,将请求向量qj,k的第posl位确定为查询关键词包含的第l位的字母的填充位置,并使qj,k[posl]=qj,k[posl]×pl;当时,使请求向量qj,k中所有位置的值均乘以pl;从而得到最终的请求向量qj,k;其中,fkf()为伪随机数函数,表示查询关键词包含的第l位的字母,l∈[1,l],qj,k[posl]的初始值为qj,k[l],pl为所述素数序列表p中第l位的素数。因为本发明针对的是包含通配符“*”的查询关键词,所以如何将包含通配符“*”的查询关键词构造成请求向量是本发明方案的关键所在。第一步,与构造索引向量相同,还是将所有关键词填充到统一的长度。第二步,需要区分关键词中的字母和通配符“*”来进行对应的处理:处理字母时,总体思路与构造索引向量相同,也是“先选位,再算值”;而处理通配符“*”的方式为将请求向量中的所有位置的值均乘以一个素数。采用这种方法处理,可以将通配符的影响体现到请求向量中,从而实现多关键词模糊查询的功能。进一步的,根据如下步骤将请求向量qj,k构造为请求矩阵qj,k,并通过knn算法对由请求矩阵qj,k构成的请求矩阵集qj={qj,1,...,qj,k,...,qj,nj}进行加密处理:步骤s311:选取随机数e,其中,e∈[2,d],且e为整数;步骤s312:依次将qj,k[l]放入qj,k[l][num]中,并填充qj,k[l][*]中除qj,k[l][num]以外的其他元素,将每一个请求向量qj,k均扩充为大小为d×e的请求矩阵qj,k;其中,qj,k[l]表示请求向量qj,k中的第l位上的元素,qj,k[l][num]表示矩阵qj,k的第l行第num列,num为随机数且num∈[1,e],l为整数且l∈[1,d],qj,k[l][*]中除qj,k[l][num]以外的其他元素的和为γl,使得γl=tl×qj,k[l][num];其中tl=0或tl+1为一个素数且qj,k[l][*]表示请求矩阵qj,k第l行的全部元素;步骤s314:将构成请求矩阵集qj={qj,1,...,qj,k,...,qj,nj}的每一个请求矩阵qj,k中的每一行元素依次放入中间矩阵的每一列中,从而得到一个大小为d×(nj×e)的中间矩阵其中,k为整数且k∈[1,nj];步骤s315:根据中间矩阵生成两个大小为d×(nj×e)的矩阵和生成规则如下:对中间矩阵中的每一列均有:若s[i]=0,则使若s[i]=1,则其中,s[i]表示所述密钥sk中的一维矩阵s的第i位,表示中间矩阵中第i行第k列的元素,表示矩阵中第i行第k列的元素,表示矩阵中第i行第k列的元素,i∈[1,d];步骤s316:将m1和m2相应的逆矩阵m1-1和m2-1分别与矩阵和相乘,得到加密请求矩阵tq;其中,·表示两个矩阵相乘。在本发明方案中,将请求向量扩展为请求矩阵,主要是出于方案安全性的考虑。然后采用knn算法对请求矩阵进行加密处理,进一步提升方案的安全性。进一步的,所述步骤s4中计算所述加密索引矩阵与加密请求矩阵的乘积,根据乘积结果确定目标数据密文的步骤如下:步骤s401:计算乘积矩阵其中,为一个由所述加密索引矩阵与加密请求矩阵的乘积生成的大小为mi×(nj×e)的矩阵;步骤s402:对乘积矩阵中每一行中每e个元素进行求和,得到一个大小为mi×nj的结果矩阵对于结果矩阵的每一行都有:当k2%e==0时,计算并将计算结果依次作为结果矩阵第k1行每一列上的元素,得到一个大小为mi×nj的结果矩阵其中,k1为整数且k1∈[1,mi],k2为整数且k2∈[1,nj×e];步骤s403:根据矩阵判断加密索引矩阵ii对应的数据密文是否为目标数据密文:当所述查询请求中包含逻辑运算符“and”时,若加密索引矩阵对应的结果矩阵中,每一列至少有一个元素为整数,则该加密索引矩阵对应的数据密文即为目标数据密文;当所述查询请求中包含逻辑运算符“or”时,若加密索引矩阵对应的结果矩阵中,至少有一列有一个元素为整数,则该加密索引矩阵对应的数据密文即为目标数据密文。在本发明方案中,云端服务器并不需要数据明文、初始索引和查询关键词的具体内容,仅仅通过计算加密索引矩阵和加密请求矩阵的乘积,即可判断数据密文是否为目标数据密文,不存在泄密的风险,整个过程具有很好的安全性。同时,通过本方案的方法构造的矩阵,可以通过乘积结果得到查询关键词中包含的“and”或“or”的逻辑查询的结果,使查询更加方便灵活。本发明方案中,通过结果矩阵中的元素是否为整数来判断搜索结果的原理如下:假设索引向量为p,请求向量为q,其维度均为d,则向量的点积表示为:p·q=p[1]×q[1]+p[2]×q[2]+...+p[i]×q[i]+...+p[d]×q[d]其中,p[i]和q[i]表示对应向量的第i位的值。根据本发明方案的内容,索引向量p的每一位上的值由公式pi,k[posl]=pi,k[posl]/pl计算获得或者为整数,即索引向量每一位上的值或者为分数(形如:p1和p2是素数,分子一定是1,因为向量每一位初始值均为1),或者为随机整数(即步骤s205中确定的随机自然数);请求向量q的每一位上的值由公式qj,k[posl]=qj,k[posl]×pl计算获得,即请求向量每一位上的值只可能为整数(形如:p1×p2×p3,p1、p2和p3均为素数)。因此,如果p[i]×q[i]是整数,则其或者是整数与整数相乘的情况,或者是两个向量对应位置的值可以约分。例如:该计算结果为整数,分子p1×p2×p3分解成三个素数因子组成的素数因子集{p1,p2,p3},包含了分母p1×p2分解成的素数因子集{p1,p2},即{p1,p2}∈{p1,p2,p3}。而且整数的素数分解结果是唯一的。根据本发明方案记载的公式posl=fkf(wi,k[l])和假设初始索引关键词wi,k的第l个字母是wi,k[l],查询关键词的第l个字母是如果该两个字母相同,即则分别映射到向量pi,k和向量qj,k的位置posl是一样的;如果该两个字母不同,即则分别映射到向量pi,k和向量qj,k的位置posl是不一样的。例如,关键词“hello”中的第三个字母和第四个字母“l”映射到向量中的位置一样;第一个字母“h”和第三个字母“l”映射到向量中的位置不一样。可以得出的结论是:无论是向量pi,k还是向量qj,k,在同一个伪随机函数fkf()计算下,同一个字母映射到向量的位置是相同的,不同字母映射到向量的位置一定不同。在本发明方案中,初始索引关键词wi,k的第l位和查询关键词的第l位可能出现以下两种情况:(1)初始索引关键词wi,k的第l位和查询关键词的第l位字母相同(包含查询关键词具有通配符“*”的情况,因为通配符“*”可以代表26个字母中的任何一个字母):向量pi,k的第posl位的值的分母一定包含了素数因子pl,向量qj,k的第posl位的值一定包含了素数因子pl,而且向量pi,k的第posl位和向量qj,k的第posl位是同一个posl值。(2)初始索引关键词wi,k的第l位和查询关键词的第l位字母不相同(此时,查询关键词的第l位的字母一定不是通配符):向量pi,k的第posl位的值的分母一定包含了素数因子pl,向量qj,k的第posl位的值一定包含了素数因子pl,但是向量pi,k的第posl位和向量qj,k的第posl位是不是同一个posl值。记vl=posl=fkf(wi,k[l]),则那么,向量pi,k的第vl位的值的分母一定包含素数因子pl,而向量qj,k的第vl位的值不包含素数因子pl,素数因子pl存在向量qj,k的第位,向量pi,k的分母无法与向量qj,k对应位置的值约分故p[posl]×q[posl]一定是分数。如果发生以下两种情况,则本发明的方案不成立:情况一:初始索引关键词wi,k和查询关键词相匹配,但是索引向量p与请求向量q的点积不是整数。情况二:初始索引关键词wi,k和查询关键词不匹配,但是索引向量p与请求向量q的点积是整数。下面通过反证法分别证明情况一和情况二均不可能出现:反证情况一:若索引向量p与请求向量q的点积不是整数,则存在p[i]×q[i]的值是分数的情况,而且q[i]分解成的素数因子集必然不包含p[i]的分母分解成的素数因子集。此时说明,初始索引关键词wi,k的第l位字母对应的素数pl映射到了向量p的x位上,而查询关键词的第l位字母对应的素数pl映射到了x位以外的其他位置。而根据伪随机函数的特点,映射位置不同则说明初始索引关键词wi,k的第l位字母与查询关键词的第l位字母不相同,而这一情况则与“初始索引关键词wi,k和查询关键词相匹配”这一前提相互矛盾。所以,情况一不可能出现。反证情况二:若索引向量p与请求向量q的点积是整数,则每个p[i]×q[i]的值均为整数。此时,每个p[i]×q[i]的值可能为0,也可能不为0。当该值不为0时,q[i]分解成的素数因子集必包含p[i]的分母分解成的素数因子集,即p[i]的分母分解成的素数因子集的每一个素数因子都存在于q[i]分解成的素数因子集。根据伪随机函数的特点,此时必然存在查询关键词的每一位字母均与初始索引关键词wi,k的对应位置的字母相同的情况,即初始索引关键词wi,k和查询关键词相匹配,而这一情况与“初始索引关键词wi,k和查询关键词不匹配”这一前提相互矛盾。因此,情况二也不可能出现。综上所述,情况一和情况二均不可能出现,因此,本发明提供的方案是成立的。有益效果本发明提供了一种云环境下基于密文的多关键词模糊查询方法。本方法通过构造向量和矩阵的方法,引入通配符来解决多关键词模糊查询问题,淘汰预设字典的方式,提供了高效的更新删除文件索引;同时,本方法支持多关键词的一轮运算,减少运算次数;再者,本方法有着较高的查准率和查全率,提供十分灵活的and/or查询,即本方法既支持关键词之间的逻辑并查询,又支持关键词之间的逻辑或查询。另外,采用knn算法加密处理方案中的矩阵,是本发明方案具有很好的安全性。附图说明图1示出了本发明提供的一种云环境下基于密文的多关键词模糊查询方法的步骤示意图;图2为本发明实施例中用于理解步骤s202的初始化后的26维的索引向量;图3为本发明实施例中用于理解步骤s204的向量phello;图4为本发明实施例中用于理解步骤s204的向量pkey;图5为本发明实施例中用于理解步骤s205的最终的索引向量;图6为本发明实施例中用于理解步骤s211的索引矩阵a1;图7为本发明实施例中用于理解步骤s302的初始请求向量qw*r*d和qk*y;图8为本发明实施例中用于理解步骤s303的向量pw*r*d;图9为本发明实施例中用于理解步骤s303的向量pk*yab;图10为本发明实施例中用于理解步骤s312和步骤s313中内容的5维向量q;图11为本发明实施例中用于理解步骤s312和步骤s313中内容的填充前的矩阵q;图12为本发明实施例中用于理解步骤s312和步骤s313中内容的填充后的矩阵q;图13为本发明实施例中用于理解步骤s314内容的中间矩阵图14为本发明实施例中用于理解步骤s403内容的索引向量和查询向量。具体实施方式为了更好的理解本发明方案的内容,下面结合具体实施例进行进一步阐述。如图1所示,本发明提供了一种云环境下基于密文的多关键词模糊查询方法,包括:步骤s1:本地服务器根据预设数据加密算法加密明文数据集得到密文数据集;步骤s2:本地服务器将与所述明文数据集对应的初始索引关键词构造成索引向量,并将所述索引向量构造成索引矩阵,采用预设的矩阵加密算法对索引矩阵进行加密,得到加密索引矩阵,将所述密文数据集和加密索引矩阵发送给云端服务器;步骤s3:用户将查询请求中的查询关键词构造成请求向量,并将所述请求向量构造成请求矩阵,采用预设的矩阵加密算法对请求矩阵进行加密,得到加密请求矩阵,并将所述加密请求矩阵发送给云端服务器;步骤s4:云端服务器根据加密请求矩阵,计算所述加密索引矩阵与加密请求矩阵的乘积,根据乘积结果确定目标数据密文,并将所述目标数据密文发回用户;步骤s5:用户通过步骤s1的数据加密算法解密所述目标数据密文,得到目标数据明文;其中,每一个所述初始索引关键词对应一个索引向量;所述索引矩阵的每一行元素对应一个索引向量;所述查询请求中的查询关键词包含通配符;所述查询请求中的查询关键词通过逻辑运算符连接;所述逻辑运算符包括“and”或者“or”。本发明提供的方法,通过将初始索引关键词构造成索引向量进而构造索引矩阵再进而加密得到加密索引矩阵,将查询关键词构造为请求向量进而构造查询矩阵再进而加密得到加密请求矩阵,通过计算加密索引矩阵与加密请求矩阵的乘积来确定目标数据密文。采用本发明提供的方法构造向量和矩阵后,只有当矩阵中某一个索引向量与请求向量乘积为整数时,该索引向量对应的数据密文才是目标数据密文。同时,本发明方案中的查询关键词包含通配符,在构造请求向量时,考虑通配符的影响,对请求向量进行相应处理,由此可以实现模糊查询功能。通配符可以代表任何不确定的英文字母,例如当查询关键词为“**sure”时,“unsure”和“insure”均为正确的查询结果。因为本发明方案中的查询请求中的查询关键词之间存在逻辑运算关系(即逻辑和或者逻辑或),所以,本发明还可以实现逻辑查询。在本实施例中,所述预设的矩阵加密算法为knn算法;所述预设的矩阵加密算法的密钥为sk,密钥sk至少包括:素数序列表p、补全字母表s和可逆加密矩阵m;所述素数序列表p={p1,...,pi,...pl},其中,每一个元素pi均为一个随机产生的素数;所述补全字母表s={s1,...,si,...sl},其中,每一个元素si均为从26个英文字母顺序词典字母表中随机选取的英文字母,所述可逆加密矩阵m={m1,m2,s},其中,m1和m2均为大小为d×d的可逆矩阵,m1和m2相应的逆矩阵分别表示为m1-1和m2-1,s是一个列数为d的一维矩阵,矩阵元素的值为0或1,通过伪随机数函数生成;其中,d≥26,l大于或等于长度最长的所述初始索引关键词所包含的字母个数,且d和l均为正整数。现有文献资料《secureknncomputationonencrypteddatabases》(w.k.wong,d.w.-l.cheung,b.kao,andn.mamoulis,proc.ofsigmod,2009)公开了将knn算法用于加密处理的方法,本发明则利用knn算法来加密本方案中涉及的向量,从而加强方案中涉及向量的加密安全性。其中,素数序列表由随机生成的素数按从小到大的顺序排列组成。l的取值由初始索引中长度最长的关键词决定,l的取值应该大于或者等于该关键词所包含的字母总数。出于方案正确性考虑,d的取值应该大于或等于26;出于安全性考虑,d的取值最好是大于或等于128。顺序词典字母表中的英文字母不区分大小写。在本实施例中,根据如下步骤构造每一个初始索引关键词wi,k对应的d维索引向量pi,k:步骤s201:将初始索引关键词wi,k的字母个数补全到统一长度l;判断初始索引关键词wi,k包含的字母个数||wi,k||:当||wi,k||<l时,从所述补全字母表s中顺序选取l-||wi,k||个字母补全初始索引关键词wi,k,使得||wi,k||=l;当||wi,k||≥l时,直接执行步骤s202;步骤s202:初始化d维索引向量pi,k,将索引向量pi,k的所有元素均设为1,使pi,k[l]=1,l∈[1,d],l为整数;其中,pi,k[l]表示索引向量pi,k第l位元素的初始值;步骤s203:选取初始索引关键词wi,k包含的字母在索引向量pi,k中的填充位置;依次将索引向量pi,k的第posl位确定为初始索引关键词wi,k包含的第l位的字母的填充位置;其中,posl=fkf(wi,k[l]),fkf()为伪随机数函数,wi,k[l]表示初始索引关键词wi,k包含的第l位的字母,l∈[1,l];步骤s204:更新索引向量pi,k的第posl位上的值pi,k[posl];其中,pi,k[posl]=pi,k[posl]/pl;pi,k[posl]的初始值为pi,k[l],pl为所述素数序列表p中第l位的素数,l∈[1,l];步骤s205:随机选取一个自然数α,将索引向量pi,k中仍为初始值1的位置的值替换为α,得到最终的索引向量pi,k。在构造索引向量时,第一步是将所有的初始索引关键词补全为统一长度,对于长度不够的初始索引关键词,采用从补全字母表中选取字母直接补充到初始索引关键词原字母后面的方式补全初始索引关键词。而向量构造过程的总体思路为“先选位,再算值”,步骤s203用于选取初始索引关键词中每一个字母在索引向量中所处的位置,步骤s204用于确定每一个字母在向量中对应位置所填充的值。而步骤s205的作用在于明文数据集中即使有两个数据均包含同一个初始索引关键词,而这两个数据对应的初始索引关键词的索引向量也会不一样,学术上称为“indexindistinguishability”(索引不可区分),从而提高方案的安全性。具体而言,假设明文数据集d={d1,d2},明文数据集d对应的初始索引为w={w1,w2},d=26,素数序列表p={3,5,7,11,13},补全字母表s={'a','b','c','d','e'},其中,数据d1对应的索引w1={"hello","key"},数据d2对应的索引w2={"key"},故l=5。则构造关键词"hello"和"key"对应的索引向量的过程如下:根据步骤s201,关键词"hello"无需填充,而关键词"key"需要填充,得到w1={"hello","keyab"};根据步骤s202,初始化两个26维的索引向量,将索引向量中所有元素均设置为1,如图2所示;根据步骤s203,对于关键词"hello"而言,whello[1]='h',whello[2]='e',whello[3]='l',whello[4]='l',whello[5]='o';选取一个伪随机数函数fkf(),计算得到各个字母对应的填充位置。同理计算关键词"keyab"的填充位置,最后得到关键词"hello"和"keyab"对应的填充位置如下表所示:“hello”‘h’‘e’‘l’‘l’‘o’pos91311117“keyab”‘k’‘e’‘y’‘a’‘b’pos81310515根据步骤s204,通过上表得到的填充位置根据公式pi,k[posl]=pi,k[posl]/pl计算各个位置具体的填充值:对于关键词"hello"而言,构成的向量phello如图3所示:①pos'h'=9(上表可得),素数表p={3,5,7,11,13}p1=3,那么(计算的含义是:代表关键词“hello”的向量phello第9位的值更新为);②pos'e'=13,素数表p={3,5,7,11,13}p2=5,那么(计算的含义是:代表关键词“hello”的向量phello第13位的值更新为);③pos'l'=11,素数表p={3,5,7,11,13}p3=7,那么(计算的含义是:代表关键词“hello”的向量phello第11位的值更新为);④pos'l'=11,素数表p={3,5,7,11,13}p4=11,那么(计算的含义是:代表关键词“hello”的向量phello第11位的值更新为);⑤pos'o'=7,素数表p={3,5,7,11,13}p5=13,那么(计算的含义是:代表关键词“hello”的向量phello第7位的值更新为)。对于关键词"keyab"而言,构成的向量pkey如图4所示:①pos'k'=8(上表可得),素数表p={3,5,7,11,13}p1=3,那么②pos'e'=13,素数表p={3,5,7,11,13}p2=5,那么③pos'y'=10,素数表p={3,5,7,11,13}p3=7,那么④pos'a'=5,素数表p={3,5,7,11,13}p4=11,那么⑤pos'b'=15,素数表p={3,5,7,11,13}p5=13,那么根据步骤s205,设随机数α=0,将索引向量中仍未初始值1的位置的值替换为α,得到最终的索引向量如图5所示。在本实施例中,根据如下步骤将由索引向量pi,k构成的索引向量集pi构造为索引矩阵ai,并通过knn算法对索引矩阵ai进行加密处理:步骤s211:依次将索引向量集pi={pi,1,...,pi,k,...,pi,mi}中的pi,k放置在索引矩阵ai的第k行中,得到一个大小为mi×d的索引矩阵ai,k∈[1,mi];步骤s212:根据索引矩阵ai生成两个大小为mi×d的矩阵ai'和ai",生成规则如下:对于索引矩阵ai的每一行ai[k][*]:若s[j]=0,则ai'[k][j]=ai"[k][j]=ai[k][j];若s[j]=1,则ai'[k][j]+ai"[k][j]=ai[k][j];其中,s[j]表示所述密钥sk中的一维矩阵s的第j位,ai[k][j]表示索引矩阵ai中第k行第j列的元素,ai'[k][j]表示矩阵ai'中第k行第j列的元素,ai"[k][j]表示矩阵ai"中第k行第j列的元素,j∈[1,d];步骤s213:将矩阵ai'和ai"分别与所述m1和m2相乘,得到加密索引矩阵ii;其中,ii=(ii',ii")=(ai'·m1,ai"·m2),·表示两个矩阵相乘。在本发明方案中,先将索引向量集构造成索引矩阵,然后采用knn算法对索引矩阵进行加密处理,得到加密索引矩阵。由此使得在本方案中的数据交互过程中传输的索引内容均为加密内容,进一步提高了方案的安全性。延续上文提到的例子,根据步骤s211,将p1={phello,pkey}放置在一个2×26的矩阵a1:phello放在矩阵a1的第一行,pkey放在矩阵a1的第二行,得到的索引矩阵a1如图6所示。为了方便步骤s212的拆分步骤,下面以一个一维例子来具体说明。假设s={1,0,0,1},a=[1,2,3,4],拆分成a'=[a′1,a′2,a′3,a′4]和a”=[a″1,a″2,a″3,a″4]。①s[1]=1,满足拆分条件a[1][1]=a'[1][1]+a”[1][1]即可,如:1=2-3,那么a'=[2,a′2,a′3,a′4],a”=[-3,a″2,a″3,a″4]。②s[2]=0,满足拆分条件a'i[k][j]=a″i[k][j]=ai[k][j]即可,那么a'=[2,2,a′3,a′4],a”=[-3,2,a″3,a″4]③s[3]=0,满足拆分条件a'i[k][j]=a″i[k][j]=ai[k][j]即可,那么a'=[2,2,3,a′4],a”=[-3,2,3,a″4]④s[4]=1,满足拆分条件a[1][1]=a'[1][1]+a”[1][1]即可,如:4=0+4,那么a'=[2,2,3,0],a”=[-3,2,3,4]。在本实施例中,根据如下步骤构造每一个查询关键词对应的d维请求向量qj,k:步骤s301:将查询关键词的字母个数补全到统一长度l;判断查询关键词包含的字母个数当时,从所述补全字母表s中顺序选取个字母补全查询关键词的原字母后面,使得当时,直接执行步骤s302;步骤s302:初始化d维请求向量qj,k,将请求向量qj,k的所有元素均设为1,使qj,k[l]=1,l∈[1,d],l为整数;其中,qj,k[l]表示请求向量qj,k第l位元素的初始值;步骤s303:选取查询关键词包含的字母在请求向量qj,k中的填充位置,并更新请求向量qj,k的第l位上的值qj,k[posl];当时,将请求向量qj,k的第posl位确定为查询关键词包含的第l位的字母的填充位置,并使qj,k[posl]=qj,k[posl]×pl;当时,使请求向量qj,k中所有位置的值均乘以pl;从而得到最终的请求向量qj,k;其中,fkf()为伪随机数函数,表示查询关键词包含的第l位的字母,l∈[1,l],qj,k[posl]的初始值为qj,k[l],pl为所述素数序列表p中第l位的素数。因为本发明针对的是包含通配符“*”的查询关键词,所以如何将包含通配符“*”的查询关键词构造成请求向量是本发明方案的关键所在。第一步,与构造索引向量相同,还是将所有关键词填充到统一的长度。第二步,需要区分关键词中的字母和通配符“*”来进行对应的处理:处理字母时,总体思路与构造索引向量相同,也是“先选位,再算值”;而处理通配符“*”的方式为将请求向量中的所有位置的值均乘以一个素数。采用这种方法处理,可以将通配符的影响体现到请求向量中,从而实现多关键词模糊查询的功能。假设根据步骤s301得到根据步骤s302,得到26维初始请求向量qw*r*d和qk*y如图7所示。根据步骤s303,得到关键词"w*r*d":关键词"k*yab":获得的填充位置如下表所示:“w*r*d”‘w’‘r’‘d’pos61412“k*yab”‘k’‘y’‘a’‘b’pos810515对于关键词"w*r*d"而言,构成的向量pw*r*d如图8所示:①pos'w'=6(上表可得),素数表p={3,5,7,11,13}p1=3,那么qw*r*d[6]=qw*r*d[6]×pl=1×3=3(计算的含义是:代表关键词“w*r*d”的向量qw*r*d第6位的值更新为3);②“w*r*d”的第二位是“*”,素数表p={3,5,7,11,13}p2=5。向量qw*r*d从第1位到第26位执行qj,k[posli]=qj,k[posli]×5;③pos'r'=14,素数表p={3,5,7,11,13}p3=7,那么qw*r*d[14]=qw*r*d[14]×pl=1×7=7;(‘r’是“w*r*d”的第三位,因此使用素数表第三个素数p3=7);④“w*r*d”的第四位是“*”,素数表p={3,5,7,11,13}p4=11。向量qw*r*d从第1位到第26位执行qj,k[posli]=qj,k[posli]×11;⑤pos'd'=12,素数表p={3,5,7,11,13}p5=13,那么qw*r*d[12]=qw*r*d[12]×pl=1×13=13;(‘d’是“w*r*d”的第五位,因此使用素数表第五个素数p5=13)。对于关键词"k*yab"而言,构成的向量pk*yab如图9所示:①pos'k'=8(上表可得),素数表p={3,5,7,11,13}p1=3,那么qk*y[8]=qk*y[8]×pl=1×3=3(计算的含义是:代表关键词“k*y”的向量qk*y第8位的值更新为3);②“k*yab”的第二位是“*”,素数表p={3,5,7,11,13}p2=5。向量qk*y从第1位到第26位执行qj,k[posli]=qj,k[posli]×5;③pos'y'=10,素数表p={3,5,7,11,13}p3=7,那么qk*y[10]=qk*y[10]×pl=1×7=7(‘y’是“k*y”的第三位,因此使用素数表第三个素数p3=7);④pos'a'=5,素数表p={3,5,7,11,13}p4=11,那么qk*y[5]=qk*y[5]×pl=1×11=11(‘a’是“k*yab”的第四位,因此使用素数表第四个素数p4=11);⑤pos'b'=15,素数表p={3,5,7,11,13}p5=13,那么qk*y[15]=qk*y[15]×pl=1×13=13(‘a’是“k*yab”的第五位,因此使用素数表第五个素数p5=13)。在本实施例中,根据如下步骤将请求向量qj,k构造为请求矩阵qj,k,并通过knn算法对由请求矩阵qj,k构成的请求矩阵集qj={qj,1,...,qj,k,...,qj,nj}进行加密处理:步骤s311:选取随机数e,其中,e∈[2,d],且e为整数;步骤s312:依次将qj,k[l]放入qj,k[l][num]中,并填充qj,k[l][*]中除qj,k[l][num]以外的其他元素,将每一个请求向量qj,k均扩充为大小为d×e的请求矩阵qj,k;其中,qj,k[l]表示请求向量qj,k中的第l位上的元素,qj,k[l][num]表示矩阵qj,k的第l行第num列,num为随机数且num∈[1,e],l为整数且l∈[1,d],qj,k[l][*]中除qj,k[l][num]以外的其他元素的和为γl,使得γl=tl×qj,k[l][num];其中tl=0或tl+1为一个素数且qj,k[l][*]表示请求矩阵qj,k第l行的全部元素;步骤s314:将构成请求矩阵集qj={qj,1,...,qj,k,...,qj,nj}的每一个请求矩阵qj,k中的每一行元素依次放入中间矩阵的每一列中,从而得到一个大小为d×(nj×e)的中间矩阵其中,k为整数且k∈[1,nj];步骤s315:根据中间矩阵生成两个大小为d×(nj×e)的矩阵和生成规则如下:对中间矩阵中的每一列均有:若s[i]=0,则使若s[i]=1,则其中,s[i]表示所述密钥sk中的一维矩阵s的第i位,表示中间矩阵中第i行第k列的元素,表示矩阵中第i行第k列的元素,表示矩阵中第i行第k列的元素,i∈[1,d];步骤s316:将m1和m2相应的逆矩阵m1-1和m2-1分别与矩阵和相乘,得到加密请求矩阵tq;其中,·表示两个矩阵相乘。在本发明方案中,将请求向量扩展为请求矩阵,主要是出于方案安全性的考虑。然后采用knn算法对请求矩阵进行加密处理,进一步提升方案的安全性。为了简单距离说明步骤s312和步骤s313中将请求向量扩充为请求矩阵的过程,下面假设存在一个5维向量q(如图10所示),取e=3,从l=1开始以步长为1递增:当l=1,随机选取num=1,取q[1]放置在矩阵q[1][1];当l=2,随机选取num=2,取q[2]放置在矩阵q[2][2];当l=3,随机选取num=3,取q[3]放置在矩阵q[3][3];当l=4,随机选取num=2,取q[4]放置在矩阵q[4][2];当l=5,随机选取num=3,取q[5]放置在矩阵q[5][3];得到对应的矩阵q(如图11所示)。然后填充矩阵q中其他位置,得到扩充后的矩阵q(如图12所示):①当l=1,填充除了q[1][1]以外的元素;选取t1=0,则γ1=t1q[1][1]=0;除q[1][1]以外的元素是q[1][2]和q[1][3],那么满足条件γ1=q[1][2]+q[1][3]=0即可;取q[1][2]=-2,q[1][3]=2。②当l=2,填充除了q[2][2]以外的元素;选取t2=1(因为t2+1=2是一个素数且则γ2=t2q[2][2]=11;除q[2][2]以外的元素是q[2][1]和q[2][3],那么满足条件γ2=q[2][1]+q[2][3]=11即可;取q[2][1]=1,q[2][3]=10。③当l=3,填充除了q[3][3]以外的元素;选取t3=0,则γ3=t3q[3][3]=0;除q[3][3]以外的元素是q[3][1]和q[3][2],那么满足条件γ3=q[3][1]+q[3][2]=0即可;取q[3][1]=-5,q[3][2]=5。④当l=4,填充除了q[4][2]以外的元素;选取t4=16(因为t4+1=17是一个素数且则γ4=t4q[4][2]=16×5=90;除q[4][2]以外的元素是q[4][1]和q[4][3],那么满足条件γ4=q[4][1]+q[4][3]=90即可;取q[4][1]=0,q[4][3]=90。⑤当l=5,填充除了q[5][3]以外的元素;选取t5=16(因为t5+1=17是一个素数且则γ5=t5q[5][3]=16×13=208;除q[5][3]以外的元素是q[5][1]和q[5][2],那么满足条件γ5=q[5][1]+q[5][2]=208即可;取q[5][1]=200,q[5][2]=8。为了方便理解步骤s314的内容,若请求矩阵集q1={qw*r*d,qk*y},中间矩阵如图13所示,就是把qw*r*d放在矩阵的第1列-第3列,qk*y放在矩阵的第4列-第6列。qw*r*d和qk*y都是一个26×3的矩阵,因此是一个26×(2×3)即26×6的矩阵。所述步骤s4中计算所述加密索引矩阵与加密请求矩阵的乘积,根据乘积结果确定目标数据密文的步骤如下:步骤s401:计算乘积矩阵其中,为一个由所述加密索引矩阵与加密请求矩阵的乘积生成的大小为mi×(nj×e)的矩阵;步骤s402:对乘积矩阵中每一行中每e个元素进行求和,得到一个大小为mi×nj的结果矩阵对于结果矩阵的每一行都有:当k2%e==0时,计算并将计算结果依次作为结果矩阵第k1行每一列上的元素,得到一个大小为mi×nj的结果矩阵其中,k1为整数且k1∈[1,mi],k2为整数且k2∈[1,nj×e];步骤s403:根据矩阵判断加密索引矩阵ii对应的数据密文是否为目标数据密文:当所述查询请求中包含逻辑运算符“and”时,若加密索引矩阵对应的结果矩阵中,每一列至少有一个元素为整数,则该加密索引矩阵对应的数据密文即为目标数据密文;当所述查询请求中包含逻辑运算符“or”时,若加密索引矩阵对应的结果矩阵中,至少有一列有一个元素为整数,则该加密索引矩阵对应的数据密文即为目标数据密文。在本发明方案中,云端服务器并不需要数据明文、初始索引和查询关键词的具体内容,仅仅通过计算加密索引矩阵和加密请求矩阵的乘积,即可判断数据密文是否为目标数据密文,不存在泄密的风险,整个过程具有很好的安全性。同时,通过本方案的方法构造的矩阵,可以通过乘积结果得到查询关键词中包含的“and”或“or”的逻辑查询的结果,使查询更加方便灵活。为了方便理解步骤s402的内容,假设有2×(2×3)的矩阵(mi=2,nj=2,e=3)。这个公式“当k2%e==0时,”,可以这样简单理解:对于矩阵的每一行,每e个元素求和。例如:每3个元素求和。对于第一行(1+2+3)=6,(4+5+6)=15;对于第二行(1+1+3)=5,(3+6+6)=15。因此得到新的2×2(即:mi×nj)的矩阵为了方便理解步骤s403的内容,假设索引向量和查询向量如图14所示,则得到:矩阵矩阵a2=[pkey],矩阵可以看出,因为没有一份文件既包含“w*r*d”又包含“k*y”,所以矩阵和都不满足“每一列至少有一个整数”的要求,故没有符合逻辑“and”的查询结果;因为两份文件中都包含了“k*y”,所以矩阵和都满足“至少有一列有一个整数”的要求,故存在符合逻辑“or”的查询结果。综上所述,本发明提供了一种云环境下基于密文的多关键词模糊查询方法。本方法通过构造向量和矩阵的方法,引入通配符来解决多关键词模糊查询问题,淘汰预设字典的方式,提供了高效的更新删除文件索引;同时,本方法支持多关键词的一轮运算,减少运算次数;再者,本方法有着较高的查准率和查全率,提供十分灵活的and/or查询,即本方法既支持关键词之间的逻辑并查询,又支持关键词之间的逻辑或查询。另外,采用knn算法加密处理方案中的矩阵,是本发明方案具有很好的安全性。以上所述仅为本发明的实施例而已,并不用以限制本发明,凡在本发明精神和原则之内,所作任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1