一种基于PageRank和信息熵的裁判文书的文本分词方法与流程
本发明属于自然语言处理技术领域中的中文分词技术,是用于针对法律文书进行中文分词的技术。
背景技术
分词是指将已有的文本切分成为一个个分开的、单独的、有意义的单元。中文分词是指将一个连续的汉字序列切分成单独的词,使之成为符合语义的、可读的词序列。汉语相比于英文,词与词之间没有明确的分隔符作为切分的依据,因此,在分词方面,中文分词的难度要更高于其他语言。而分词算法产生的分词结果,也将直接影响到上层的应用效果,如词性标注、关键词提取等。因此,如何使计算机理解中文文本段,进行准确分词而为上层的文本处理应用提供支持就是中文分词最难以解决的问题。
目前,中文分词最常用的主要方法有:基于词典的字符串匹配方法、基于规则的分词方法和基于统计的分词方法。
(1)基于词典的字符串匹配方法主要是通过扫描查找出输入文本中存在于词典里的词,并以此作为依据进行分词。基于词典的匹配方法通过正向/逆向匹配词典,得到所有在词典中出现过的词,并依照最长/最短词匹配的原则,生成分词文本。但是这种方法较为依赖分词词典,必须对词典保持持续更新以获得较好效果,同时词典的建立需要总结大量文本语料库,较为耗费时间。对于新词识别以及歧义的问题,该方法并不能很好地解决。
(2)基于规则的方法是指总结语言的语法与语义,模拟人理解文本的过程进行分词。该方法在于判断词性、语义,并按照建立好的规则库匹配得到符合语法语义的分词文本。但是这种方法需要大量语义学知识,并以此为基础建立规则库。由于汉语的复杂性,且部分文本中语言的使用不严格遵循语法规则,因此该方法对于汉语分词效果并不是特别理想。
(3)基于统计的分词方法是指统计词出现的频率、频次以及其它特征,以此作为依据进行分词。比较著名的方法有隐形马尔科夫模型、条件随机场等。统计学方法通过统计词在语料库中的出现频率、字与字之间的共现频率等作为是否能够成词的依据。近几年机器学习技术使得很多基于统计的机器学习方法取得不错的效果,尤其是在歧义消除和新词发现方面。基于统计的分词方法不需要额外的词典,而是仅对语料库中的字组进行统计。但是,该方法有时会抽取出一些频次高却无语义的词。而且,基于统计的机器学习方法也需要准备大量人工标记的数据集以进行训练。
本发明结合了以上三种方法进行文本分词,主要实现方式为:基于规则对文本进行预处理;基于统计学方法计算词的rank值、信息熵、互信息进行分词;基于关键词词典对专业术语进行合并。
在法律方面,法律文书一般具有较高的结构性,裁判文书的撰写依照严格的格式要求进行。但是,在法律文书中存在大量的地名、人名、机构名以及其它特殊名称,因此,如何对这些特殊词进行识别也是一个难题。同时,由于法律文书中经常会用到一些专用的术语,例如“夫妻共同财产”、“人民陪审员”、“肇事逃逸罪”等。这些术语由多个常用短词共同组合而成,传统的分词方法往往会将此类术语拆分成为“夫妻/共同/财产”、“人民/陪审员”、“肇事/逃逸罪”,而实际上这些词语并不应该在分词过程中被拆分。
技术实现要素:
本发明要解决的技术问题是:提供一种基于pagerank的中文文书分词方法,该方法不仅能有效识别文本之间的术语以及特殊词,而且不需要对模型以大规模语料库或数据集进行统计训练,所统计识别的范围仅在于输入文本,仅需要针对小范围术语建立关键词词典即可提升领域术语识别的效果。
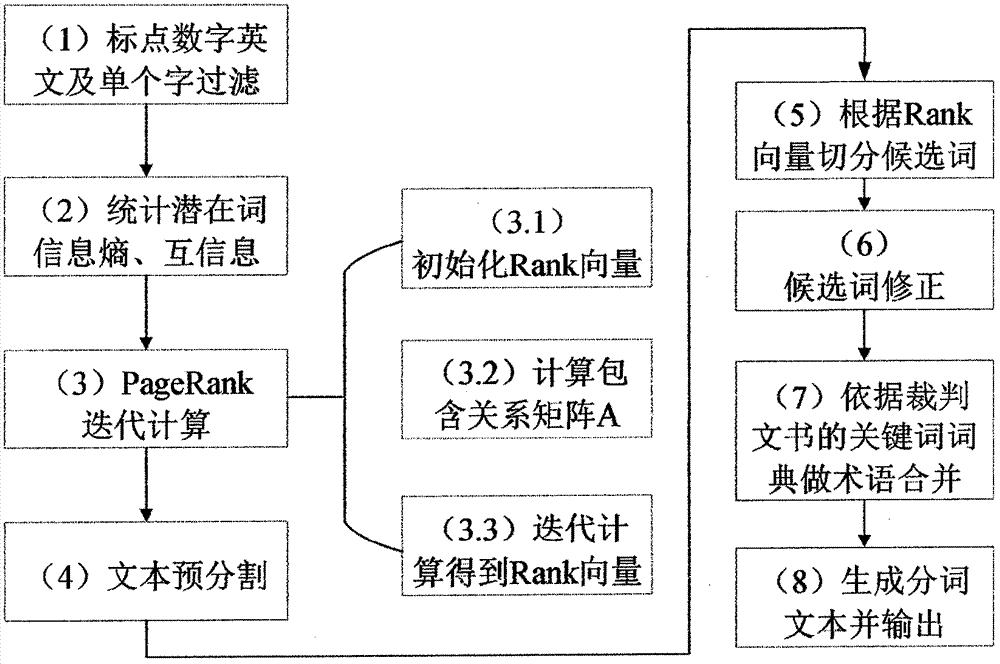
本发明的技术方案为:基于pagerank的中文文书分词方法,首先通过对输入文本进行预处理,提取出标点符号、英文、数字以及特殊模式(日期、金额等),保留余下的中文字符序列;然后计算所有潜在词的特征,主要有pagerank值、信息熵和互信息;最终根据潜在词的pagerank值选出候选词,根据信息熵对候选词修正,再匹配关键词词典得到最终的分词序列。该方法引入pagerank算法使得分词工作不需要依赖外部大量的语料,该分词方法整体流程如图1所示。包含以下步骤(如图10所示):
步骤(1)读取输入文本,以标点符号、数字以及英文字母作为分隔符进行切分,得到文本中的全部汉字,再过滤去除词长只有1的字,得到一个字符串列表s;
步骤(2)对于s中的每一个字符串si的长度不超过k(k=6)的子串ssub(潜在词),计算ssub在文本中的频率,计算ssub的左右信息熵hl,hr以及互信息i(ssub);
步骤(3)调用pagerank计算过程:获得所有字符串ssub间的包含关系矩阵a和初试rank向量r并迭代n(n=10)次计算出rank得分;
步骤(4)将步骤(1)中提取出的分隔符,以及s中符合特殊模式的词(如日期、法律条目、金额等)进行提前分割;
步骤(5)根据步骤(3)得到的rank得分向量r对文书剩余文字部分进行切分,得到一个词列表w;
步骤(6)根据步骤(2)中计算的信息熵对步骤(5)得到的候选切分结果w进行修正,得到修正后的分词列表wr;
步骤(7)读取已有的词典d,对于步骤(6)修正后的结果wr中的每两个相邻词wi,wi+1,合并d中存在的术语,得到术语合并后的词列表wrd;
步骤(8)根据wrd和给定分隔符o,返回最终分词结果。
在以上的流程中,pagerank的计算过程步骤如下:
步骤(3.1)根据计算的互信息值建立潜在词的rank列向量的初始值r0;
步骤(3.2)遍历所有ssub,建立所有潜在词之间的包含关系矩阵a,若存在ssub1是ssub2的子串,则
步骤(3.3)迭代u(u=10)次计算所有潜在词的pagerank,迭代公式为:
r=c1ar+c2(rta)t,(c1=1,c2=0.01)。
根据rank得分切分出候选词的过程步骤如下:
步骤(5.1)首先,通过设立大小为t(t=5)的滑动窗口,在滑动窗口内取出最大pagerank值的词作为候选词,直至滑动窗口滑至底部。分别正向和逆向切分,可以得到两个词列表wf和wb;
步骤(5.2)比较wf和wb中不同的切分部分,对每一部分取出最大pagerank值的词作为候选词,并继续对该词左右部分递归应用全局最大值切分直至所有剩余部分长度不大于2。
在步骤(2)中,需要计算潜在词的左右信息熵hl和hr以及互信息i(ssub),具体的计算公式为:
其中x为某个潜在词,xl和xr分别为潜在词x的左右临近字集合,p(x)为字x在临近字集合中出现的概率。
互信息的计算公式为:
其中w为某个潜在词,(x,y)为w的划分集合,使得w=xy,p(x,y)为xy在文本中共现的频率,也就是w出现的频率。
在步骤(3)中,本发明对pagerank算法进行了改进,以适用于文本分词。其中有向图模型的建立方法如下:
将每一个候选词视为一个节点。对任意两个候选词s1,s2(s1≠s2),存在一条从s1到s2的链当且仅当s1是s2的子串(见图11)。如果某个候选词具有多个入链,则说明该候选词更容易被“引用”,也就更可能是一个有意义的词。同时,考虑到多个短词组成的长词术语问题,若某一个候选词具有多个出链指向的分别是rank值高的短候选词,则这个长词也很有可能是有意义的术语。因此本发明中的pagerank算法加入了短词对长词的rank值反馈。对某个候选词的rank值定义如下:
其中u代表某个候选词节点,fu表示u指向的候选词集合,bu表示指向u的候选词集合。nu=|fu|表示u指向的候选词个数(也就是出链个数),mu=|bu|表示指向u的候选词个数(也就是入链个数),c1和c2是反馈系数。
在步骤(4)中预分割的过程中,首先以正则匹配的方式将标点符号、数字、英文字母以及日期金额等模式预先提取出来,直接产生关于这些模式的匹配,并进行提前分割,不参与后续文书分词。其具体的匹配模式与分割模式如下:
(1)标点符号单独分割。例如:判处拘役五个月/,/并处罚金2000元人民币;
(2)时间、金额小粒度分割。例如:二零一五年/十二月/二十四日,2015年/12月/24日,2000元/人民币;
(3)法律条款条目按每个款项分割。例如:第一百四十五条/第三款,昆民初字/第4xxx号;
(4)其余英文字母与数字分割最长串。例如:车牌号/b12xxxx。
在步骤(6)中的修正过程中,主要合并独立的字以及分裂无意义的两字词。对于某个单个字c,记其前候选词为p,后候选词为n,若能满足hl(pc)+hr(pc)>hl(p)+hr(p)或hl(cn)+hr(cn)>hl(n)+hr(n),则说明合并c会使新词的信息熵增加,那么新词则有可能是应合并的词。此时根据左右信息熵最大的原则进行合并。对于某个两字词c1c2,尝试将其分裂,并将c1,c2,分别作为单字应用单字合并原则。即若hl(pc1)+hr(pc1)>hl(p)+hr(p)或hl(c2n)+hr(c2n)>hl(n)+hr(n),则认为该两字词是无意义的,应该将其分裂合并到相邻词。
根据本发明内容,我们已经开发出了可视化分词系统“一种基于pagerank和信息熵的裁判文书的文本分词系统”。该可视化分词系统能够从输入的法律文书中,计算出词特征,并可视化输出已分词完成的文书。
本发明的有益效果是:该方法不仅能有效识别文本之间的术语以及特殊词,而且不需要对模型以大规模语料库或数据集进行统计训练。由于引入了改进的pagerank算法,该方法在保证分词准确率的基础上,仅需要专业关键词(不超过500kb)的帮助即可分词,大大减少了分词所需的准备资源。而且,若要移植到除法律之外的领域分词,仅需要更换相应的关键词词典,具有较好的可扩展性。该方法第一次关注了少语料甚至是无语料基础下的分词,着重于发掘分词输入文本本身的词语特征。
附图说明
图1为基于pagerank的文本分词方法的流程图。
图2为法律文书示例。
图3为实例过滤后的文本列表。
图4为实例“人民法院”的包含关系矩阵。
图5为实例预分割后的文本结果。
图6为句子“江苏省泰兴市人民法院”根据pagerank正向匹配的过程与结果。
图7为句子“江苏省泰兴市人民法院”正逆向切分结果匹配的过程。
图8为本发明实例中对输入文本的最终分词结果。
图9为根据实例的输入文本,运用工具展现的可视化分词结果。
图10为基于pagerank的文本分词方法流程
图11为入链出链关系
图12为“原告钱某某”的所有潜在词的信息熵和互信息值
具体实施方式
本发明主要是使用改进的pagerank算法建立潜在词之间包含关系的图模型,并以此计算所有潜在词的rank值以及结合了信息熵和互信息进行分词,本发明加入了关键词词典以更好地适配不同领域的术语。该分词方法整体流程如图1所示。其具体实施步骤如下:
1.该方法的主要流程如图10上半部分所示。
步骤(1),读取输入文本,以标点符号、数字以及英文字母作为分隔符进行切分,得到文本中的全部汉字,再过滤去除词长只有1的字,得到一个字符串列表s;
步骤(2),对于s中的每一个字符串si的长度不超过k(k=6)的子串ssub(潜在词),计算ssub在文本中的频率,计算ssub的左右信息熵hl,hr以及互信息i(ssub);
步骤(3),调用pagerank计算过程:获得所有字符串ssub间的包含关系矩阵a和初试rank向量r并迭代n(n=10)次计算出rank得分;
步骤(4),将步骤(1)中提取出的分隔符,以及s中符合特殊模式的词(如日期、法律条目、金额等)进行提前分割;
步骤(5),根据步骤(3)得到的rank得分向量r对文书剩余文字部分进行切分,得到一个词列表w;
步骤(6),根据步骤(2)中计算的信息熵对步骤(5)得到的候选切分结果w进行修正,得到修正后的分词列表wr;
步骤(7),读取已有的词典d,对于(6)修正后的结果wr中的每两个相邻词wi,wi-1,合并d中存在的术语,得到术语合并后的词列表wrd;
步骤(8),根据wrd和给定分隔符o,返回最终分词结果。
2.该方法的pagerank计算过程如图10下半部分所示。
步骤(31),根据计算的互信息值建立潜在词的rank列向量的初始值r0;
步骤(3.2),遍历所有ssub,建立所有潜在词之间的包含关系矩阵a,若存在ssub1是ssub2的子串,则
步骤(3.3),迭代u(u=10)次计算所有潜在词的pagerank,迭代公式为:
r=c1ar+c2(rta)t,(c1=1,c2=0.01)。
下面通过具体的实例来说明本发明的实施流程。
本发明的实例将以图2中的法律文书作为输入文本进行分词,为保护隐私,对其中涉及人名、案号、日期等信息以″xx″替代。
对于该实例,我们将采用如下步骤实施该方法:
步骤(1),读取输入文本,以标点符号、数字以及英文字母作为分隔符进行切分,得到文本中的全部汉字,再过滤去除词长只有1的字,得到一个字符串列表s(如图3)。
步骤(2),对于s中的每一个字符串si的长度不超过k(k=6)的子串ssub(潜在词),计算ssub在文本中的频率,计算ssub的左右信息熵hl,hr以及互信息i(ssub),如图12显示计算得到的部分结果。
步骤(3),调用pagerank计算过程:获得所有字符串ssub间的包含关系矩阵a和初试rank向量r并迭代n(n=10)次计算出rank得分,其具体过程如下:
步骤(3.1),根据计算的互信息值建立潜在词的rank列向量的初始值r0;
步骤(3.2)遍历所有ssub,建立所有潜在词之间的包含关系矩阵a,若存在ssub1是ssub2的子串,则
步骤(3.3),迭代u(u=10)次计算所有潜在词的pagerank,迭代公式为:
r=c1ar+c2(rta)t,(c1=1,c2=0.01)。
步骤(4),将步骤(1)中提取出的分隔符(包括空格),以及s中符合特殊模式的词(如日期、法律条目、金额等)进行提前分割,得到如图5的结果。
步骤(5),根据步骤(3)得到的rank得分向量r对文书剩余文字部分进行切分,得到一个词列表w。其具体过程为:
步骤(5.1)正向逆向切分:首先,通过设立大小为t(t=5)的滑动窗口,在滑动窗口内取出最大pagerank值的词作为候选词,直至滑动窗口滑至底部。可以得到正向和逆向两个词列表wf和wb;
步骤(5.2)全局最大值切分:比较wf和wb中不同的切分部分,对每一部分取出最大pagerank值的词作为候选词,并继续对该词左右部分递归应用全局最大值切分直至所有剩余部分长度不大于2。
为方便示意,图6和图7以句子“江苏省泰兴市人民法院”为例展示了切分过程。
步骤(6),根据步骤(2)中计算的信息熵对(5)得到的候选切分结果w进行修正,得到修正后的分词列表wr。
步骤(7),读取已有的词典d,对于(6)修正后的结果wr中的每两个相邻词wi,wi+1,合并d中存在的术语,得到术语合并后的词列表wrd。
步骤(8),第8步,根据wrd和给定分隔符o,返回最终分词结果,如图8所示。
以上步骤获得了分词完成的文本n,通过我们建立的基于pagerank和信息熵的裁判文书的文本分词系统可以看到最终结果,如图9所示。
- 还没有人留言评论。精彩留言会获得点赞!