基于深度学习的小尺寸行人目标检测方法与流程
本发明属于图像处理技术领域,特别涉及一种70个像素下的小尺寸行人目标检测方法,可用于无人驾驶或辅助驾驶。
背景技术
行人检测是使用计算机视觉等方法判断图像中是否存在行人并给出在图像中的精准位置。因为其在车辆辅助驾驶和自动驾驶中的重要应用价值,行人检测已经成为当前计算机视觉和智能车辆领域最为活跃的研究课题之一。行人检测可以及时检测出车辆前方的行人以针对实际状况采取相应措施。在自动驾驶中,行人检测结合其它技术,可以在保障交通安全的同时将人从驾驶汽车的工作中解脱出来。国内外已经有很多公司开始做无人驾驶汽车的相关工作,车辆辅助驾驶技术的需求也越来越浓烈,已成为了学术界工业界共同关注的热点。
目前一些汽车生产厂商、大学和研究机构相继开始了行人检测技术的研究。比如,欧洲戴姆勒、德国大众等就发起了旨在研究行人保护方案的protector项目,并且已经取得了初步的成效。2004-2005年的save-u项目实现的目标是减少行人和车辆碰撞造成的伤亡数量和事故等级,并在危险状况下驾驶员警告和车辆自动减速试验车辆。作为无人驾驶的先驱技术之一,行人检测系统在近几年也已成为研发热点,它通常整合到碰撞预防系统当中,利用雷达摄像头和感应器来检测行人,并及时减速刹车从而减少事故伤害。沃尔沃、丰田等车企已率先推出先进的行人检测系统,而福特也推出了先进的行人检测系统,能够识别路上的行人并进行动态分析,预测他们是否会闯入驾驶路线中。除了传统汽车公司外,很多互联网公司也在研发行人检测系统,以期实现智能汽车。谷歌最新的行人检测系统只靠摄像机影像来掌握行人动向,但是优化了速度问题。行人检测在智能交通等领域越来越受到重视。
行人检测方法主要分为两大类,基于手工特征提取和基于深度学习,其中:
基于手工提取特征的方法有hog,hog-lbp,haar等,主要利用从数据中提取出的相关特征训练svm和adaboost等分类器,其中目前最主流的是hog+svm,许多文献在hog+svm的基础上进行了优化。然而手工提取特征又称为特征工程,有着许多缺点。hog特征对于遮挡问题效果不好,sift特征要求检测目标包含足够多的纹理信息,haar特征有着计算量大、训练时间很长而且对复杂的目标的描述效果不够好的缺点。
基于深度学习方法,随着近几年深度学习理论的快速发展,取得了很大的进步,特别是检测精度比原有算法有较大的提高。大量文献表明深度学习自我学习的特征可以更好地描述检测目标的特性,避免了复杂的特征提取和数据建模过程。主流的是卷积神经网络cnn,最早用于mnist手写数字字符数据集上。现在主流的目标检测算法是r-cnn系列,最早的r-cnn算法使用了selectivesearch方法从一张图像生成约2000-3000个候选区域,然后通过卷积神经网络在候选区域提取特征并进行判断,之后出现的fastr-cnn、faster-rcnn算法都是r-cnn算法的提高。行人检测领域,sermanet等人提出了convnet模型在行人检测数据库获得了很好的效果,tian等人通过考虑行人和场景的语义属性学习更具有表达能力的特征,cai等人提出复杂性的级联训练,成功结合了手工提取的特征和卷积神经网络得到的特征,zhang等人提出了一种使用rpn得到候选区域,然后通过boostedforests分类的行人检测算法。
然而,上述方法只利用了卷积网络中最高层的特征,最高层的特征由于经过多次池化,每一特征点映射到原图只能检测特定大小以上的目标,同时忽略了低层卷积特征中的图像局部方差特征,对70像素下的小尺寸行人检测效果不好。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于深度学习的小尺寸行人目标检测方法,以提高对70像素下小尺寸行人的检测效果。
为实现上述目的,本发明融合卷积神经网络中的多重卷积特征,在网络结构加入了反卷积层并使用了新的损失函数,其实现方案包括如下:
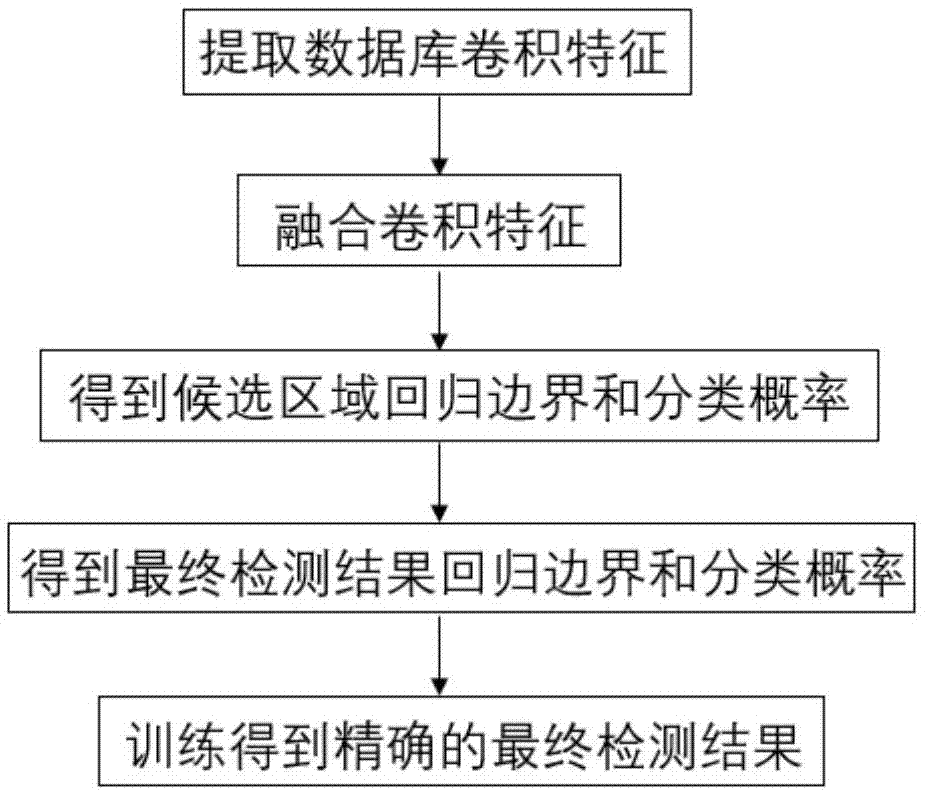
(1)读取行人检测数据库数据,使用vgg卷积神经网络提取行人检测数据库的卷积特征:
1a)vgg卷积神经网络拥有5组卷积层,每一组内有2~3个卷积层,同时每组尾部连接一个最大池化层用来缩小卷积层尺寸,每一个卷积层使用同样尺寸的卷积核提取卷积特征;
(2)将vgg卷积神经网络不同层提取的卷积特征进行叠加融合,得到两种卷积特征融合层:
2a)将vgg卷积神经网络中第4组第3个卷积特征层conv4_3提取的卷积特征进行反卷积处理,再将反卷积处理的结果与vgg卷积神经网络中第3组第3个卷积特征层conv3_3提取的卷积特征进行叠加融合,得到第一种卷积特征融合层;
2b)将vgg卷积神经网络中第3组第3个卷积特征层conv3_3、第4组第3个卷积特征层conv4_3和第5组第3个卷积特征层conv5_3提取的卷积特征进行叠加融合,得到第二种卷积特征融合层;
(3)根据vgg卷积神经网络中第5组第3个卷积特征层conv5_3和2a)得到的第一种卷积特征融合层,获得最终候选区域的回归边界和分类概率:
3a)将第一种卷积特征融合层进行全卷积处理,得到第一种候选区域的回归边界和分类概率,该候选区域是指在数据中可能有行人目标的数千个区域;
3b)将vgg卷积神经网络中第5组第3个卷积特征层conv5_3进行全卷积处理,得到第二种候选区域的回归边界和分类概率;
3c)将两种候选区域的回归边界和分类概率融合,得到最终候选区域的回归边界和分类概率;
(4)根据最终候选区域的回归边界和第二种卷积特征融合层,得到最终检测结果的回归边界和分类概率:
4a)将最终候选区域的回归边界通过roi池化,映射到第二种卷积特征融合层中,得到每个候选区域在第二种卷积特征融合层中对应的卷积特征;
4b)将4a)得到的卷积特征进行全卷积处理,得到最终检测结果的回归边界和分类概率;
(5)根据(4)中最终的回归边界和分类概率,使用损失函数l对(1)中vgg卷积神经网络进行训练,得到最终检测结果:
5a)设损失函数l包括表示分类概率的损失子函数lcls和表示回归边界的损失子函数lreg,并通过下式计算分类概率的损失子函数lcls:
其中,i为候选区域的索引,pi为每个候选区域是否代表一个行人的检测概率,
5b)计算回归边界的损失子函数lreg,并根据lcls和lreg的值,得到损失函数l;
5c)通过反向传播迭代更新vgg卷积神经网络中的权值10万次,使损失函数l的值逐渐减小,得到精确的最终检测结果。
本发明具有如下优点:
第一,本发明从小尺寸行人目标的特征提取出发,构建深度卷积神经网络结构,在候选区域生成阶段使用了反卷积处理,并对vgg网络的卷积特征层进行融合处理,所以能更好的利用表征图像局部信息的低层特征,得到对小尺寸目标更敏感的候选区域;
第二,本发明通过vgg网络最高卷积层,在候选区域中加入了表征图像全局信息的高层特征,保证了候选区域对非小尺寸目标的检测效果;
第三,由于本发明重新定义了损失函数,增加了不容易分类样本在损失函数中的权重,提高了对不容易分类样本的检测效果。
附图说明
图1是本发明的实现流程图;
图2是本发明的示意图;
图3是用本发明对celtech行人检测数据库中小尺寸行人目标的检测结果图;
图4是用本发明对celtech行人检测数据库不限尺寸大小情况下的检测结果图。
具体实施方式
以下结合附图对本发明的内容和效果进行进一步描述。
参照图1和图2,本发明的具体实施步骤如下:
步骤1,读取行人检测数据库数据,使用vgg卷积神经网络提取行人检测数据库数据的卷积特征:
vgg卷积神经网络拥有5组卷积层,每一组内有2~3个卷积层,同时每组尾部连接一个最大池化层用来缩小卷积层尺寸,每一个卷积层使用同样尺寸的卷积核提取卷积特征。
步骤2,将vgg卷积神经网络不同卷积层提取的卷积特征进行叠加融合,得到两种卷积特征融合层:
将vgg卷积神经网络中第4组第3个卷积特征层conv4_3提取的卷积特征进行反卷积处理,再将反卷积处理的结果与vgg卷积神经网络中第3组第3个卷积特征层conv3_3的卷积特征进行叠加融合,得到第一种卷积特征融合层;
将vgg卷积神经网络中第3组第3个卷积特征层conv3_3、第4组第3个卷积特征层conv4_3和第5组第3个卷积特征层conv5_3的卷积特征进行叠加融合,得到第二种卷积特征融合层。
步骤3,根据vgg卷积神经网络中第5组第3个卷积特征层conv5_3和第一种卷积特征融合层,获得最终候选区域的回归边界和分类概率。
将第一种卷积特征融合层进行全卷积处理,得到第一种候选区域的回归边界和分类概率,该候选区域是指在数据中可能有行人目标的数千个区域;
将vgg卷积神经网络中第5组第3个卷积特征层conv5_3进行全卷积处理,得到第二种候选区域的回归边界和分类概率;
将两种候选区域的回归边界和分类概率融合,得到最终候选区域的回归边界和分类概率。
步骤4,根据最终候选区域的回归边界和第二种卷积特征融合层,得到最终检测结果的回归边界和分类概率。
将最终候选区域的回归边界通过roi池化,映射到第二种卷积特征融合层中,得到每个候选区域在第二种卷积特征融合层中对应的卷积特征;
将得到的卷积特征进行全卷积处理,得到最终检测结果的回归边界和分类概率。
步骤5,根据最终检测结果的回归边界和分类概率,使用损失函数l对vgg卷积神经网络进行训练,得到最终检测结果。
5.1)设损失函数l包括表示分类概率的损失子函数lcls和表示回归边界的损失子函数lreg;
5.2)通过下式计算分类概率的损失子函数lcls:
其中,i为候选区域的索引,pi为每个候选区域是否代表一个行人的检测概率,
5.3)通过下式计算回归边界的损失子函数lreg:
其中,i为候选区域的索引,ti为候选区域的坐标,
5.4)根据lcls和lreg的值,计算损失函数l:
其中,i为候选区域的索引,pi为每个候选区域是否代表一个行人的概率,
5.5)通过反向传播迭代更新vgg卷积神经网络中的权值10万次,使计算出的损失函数l的值逐渐减小,得到精确的最终检测结果。
下面结合仿真实验对本发明的效果做进一步的描述。
1.仿真条件:
硬件设施上,配有搭载内存为128gb的i7-5930k处理器及4块泰坦x显卡的高性能计算机。
实验使用celtech行人检测数据库进行评估,该celtech行人检测数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640×480,30帧/秒。标注了约250,000帧,约137分钟,350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。
该celtech行人检测数据库的数据集分为set00~set10,本发明在set00~set05数据集训练,在set06~set10数据集测试本发明训练后的效果。
仿真实验是本发明和现有的三种行人检测方法在celtech行人检测数据库上进行的对比实验,其中第一种方法是发表在iccv2015的卷积信道特征方法ccf,第二种方法是发表在eccv2016的区域生成网络级联增强森林方法rpn+bf,第三种方法是发表在tpami2017的特征联合学习方法udn+。
2.仿真内容:
仿真实验1:用本发明和现有的三种方法对celtech行人检测数据库中70个像素下的小尺寸行人目标进行检测,得到mr-fppi曲线,如图3所示,其中横坐标为丢失率mr,丢失率是正样本被错误判别为负样本的数目和全部正样本数目的比率;纵坐标为每张图像中错误正样本数目fppi,其中错误正样本指检测结果为行人,实际上不是行人的一些样本;本实验指定fppi的范围为[10-2,100],图中数值为本发明和现有的三种方法在该fppi范围内的平均丢失率。从图3可见,本发明对70个像素下的小尺寸行人目标的检测结果要优于其它三种方法。仿真实验1验证了本发明对小尺寸目标有良好的效果。
仿真实验2:用本发明和现有的三种方法对celtech行人检测数据库在不限尺寸大小情况下进行检测,得到mr-fppi曲线,如图4所示,其中横坐标为丢失率mr,丢失率是正样本被错误判别为负样本的数目和全部正样本数目的比率;纵坐标为每张图像中错误正样本数目fppi,其中错误正样本指检测结果为行人,实际上不是行人的一些样本。本实验指定fppi的范围为[10-2,100],图中数值为本发明和现有的三种方法在该fppi范围内的平均丢失率。从图4可见,本发明对不限尺寸的行人目标的检测结果要优于其它三种方法。仿真实验2验证了本发明对不限尺寸的行人目标同样有良好的效果。
上述仿真结果验证了本发明的正确性、有效性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!