一种基于二级结构片段组装的群体蛋白质结构预测方法与流程
本发明是一种涉及生物学信息学、分子动力学模拟、统计学习与组合优化、计算机应用领域,具体涉及的是,一种基于二级结构片段组装的群体蛋白质结构预测方法。
背景技术
蛋白质是生命的蓝图,蛋白质是生命的机器。核酸序列中蕴藏着生命的信息,而蛋白质则执行者生物体内各种重要的工作,如生物化学反应的催化、营养物质的运输、生长和分化控制、生物信号的识别和传递等工作。蛋白质具有不同的长度、不同的氨基酸排列和不同的空间结构,实验分析表明蛋白质能够形成特定的结构。
研究蛋白质的结构意义重大,分析蛋白质结构、功能及其关系是蛋白质组计划中的一个重要组成部分。研究蛋白质结构,有助于了解蛋白质的作用,了解蛋白质如何行使其生物功能,认识蛋白质与蛋白质(或其它分子)之间的相互作用,这无论是对于生物学还是对于医学和药学,都是非常重要的。但是,蛋白质的空间结构又是由什么决定的呢?当一个蛋白质的空间结构被破坏以后,或者蛋白质解折叠,可以恢复其自然的折叠结构。大量的实验结果证明:蛋白质的结构由蛋白质序列所决定。虽然影响蛋白质空间结构的另一个因素是蛋白质分子所处的溶液环境,但是决定蛋白质结构的信息则是被编码于氨基酸序列之中。然而,这种编码是否能被破译呢?或者说是否能够直接从氨基酸序列预测出蛋白质的空间结构呢?虽然一般认为蛋白质的结构是由其氨基酸序列所决定的,但我们现在所拥有的指示还不足以准确预测一条蛋白质的三级结构。
现有的蛋白质结构预测实验方法主要有x-射线,核磁共振以及冷冻电镜等方法,然而这些方法花费昂贵且耗时较长,在理论需求和实际应用的双重推动下,人们采用通过依据氨基酸序列以及计算机优化方法进行蛋白质结构的预测,其中从头预测方法存在预测精度差,采样能力不足的缺陷。
因此,本发明提出一种基于二级结构片段组装的群体蛋白质结构预测方法,从而改进现有的蛋白质结构预测方法中存在的预测精度和采样能力不足的问题。
技术实现要素:
为了克服现有的蛋白质结构预测方法采样能力和预测精度不足的缺陷,本发明提出一种基于二级结构片段组装的群体蛋白质结构预测方法,设计了一种基于二级结构的片段组装,通过基于loop的信息交互以及基于二级结构的片段组装来采样能量和结构更接近于天然态的蛋白质构象,提高采样能力,然后通过给予构象的loop区域以小的扰动来改变loop区域的结构,从而有效地改进由于能量函数的不精确导致的蛋白质结构预测精度低的问题。
本发明解决其技术问题所采用的技术方案是:
一种基于二级结构片段组装的群体蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置,过程如下:
读入目标蛋白质的序列信息,片段库信息,设置蛋白质构象的种群pose={p1,p2,...,pi,...,pn},其中n是种群大小,pi表示种群的第i个个体,迭代次数为g,最大迭代次数gmax,信息交互概率r,序列长度为l;
2)种群初始化,过程如下:
根据蛋白质构象的初始直链,复制这些直链得到n个初始种群个体,使用片段长度为9的片段对种群中的每个个体pi进行片段组装直到所有位置的残基类型都被至少替换过一次为止;
3)种群信息交互,过程如下:
对种群中每一个个体pi,根据信息交互概率进行判断该个体是否进行种群交互,若进行种群交互,则从种群中随机选取另外一个个体pj,其中i≠j,随机选取pi构象的其中一个loop区域,与pj构象相对应的区域进行二面角信息的交换,信息交互后得到两个新的个体pi′,pj′,若不进行种群交互,则对种群中下一个个体进行步骤3),完成对种群中所有个体的信息交互;
4)基于二级结构的种群片段组装,过程如下:
对个体pi′,i∈[1,np]进行9片段的片段组装,在每次片段组装后进行判断,若片段组装的区域中包括loop区域的残基,则使用片段组装前构象的loop区域的残基信息替换当前的loop区域残基的信息,得到个体pi″,对种群中所有个体都进行基于二级结构的片段组装操作;
5)对loop区域进行扰动,过程如下:
对个体pi″,i∈[1,np]的loop区域进行扰动,对构象loop区域的每一个残基的二面角进行±2的角度范围内的微调,得到个体pi″′,在扰动过程之后,利用能量函数分别对扰动前后的个体进行评价得到ei和ei′,若ei<ei′,则跳回至步骤4)重新进行片段组装,若ei>ei′,则结束变异操作并得到新的个体;
6)使用能量函数对种群进行选择,过程如下:
首先,把初始种群和扰动后的种群合并成一个种群大小为2*n的新种群,然后,根据能量函数计算新种群个体的能量,根据能量的高低对合并后的种群排序,选取前n个能量低的个体作为选择后的种群个体,最后,设置g=g+1;
7)判断是否达到最大得迭代次数gmax,若满足条件则停止迭代并输出最后一代种群个体信息,否则返回步骤3)。
本发明的技术构思为:本发明在群体算法的框架下提出一种基于二级结构片段组装的群体蛋白质结构预测方法。首先,在群体算法中信息交互过程概率的设置可以控制群体收敛的速度;然后,基于二级结构的片段组装操作可以增加构象的多样性,从而获得更近天然态的构象;最后,对loop区域以微小的扰动,并在选择的过程中通过使用能量对种群进行择优,淘汰能量较高的个体,留下较优个体进行下一次迭代。
本发明的有益效果表现为:一方面使用群体算法,群体间进行信息交互,增加构象空间的搜索;另一方面,通过基于二级结构的片段组装操作以及loop区域中残基的微小扰动增加构象的多样性,提高了预测精度。
附图说明
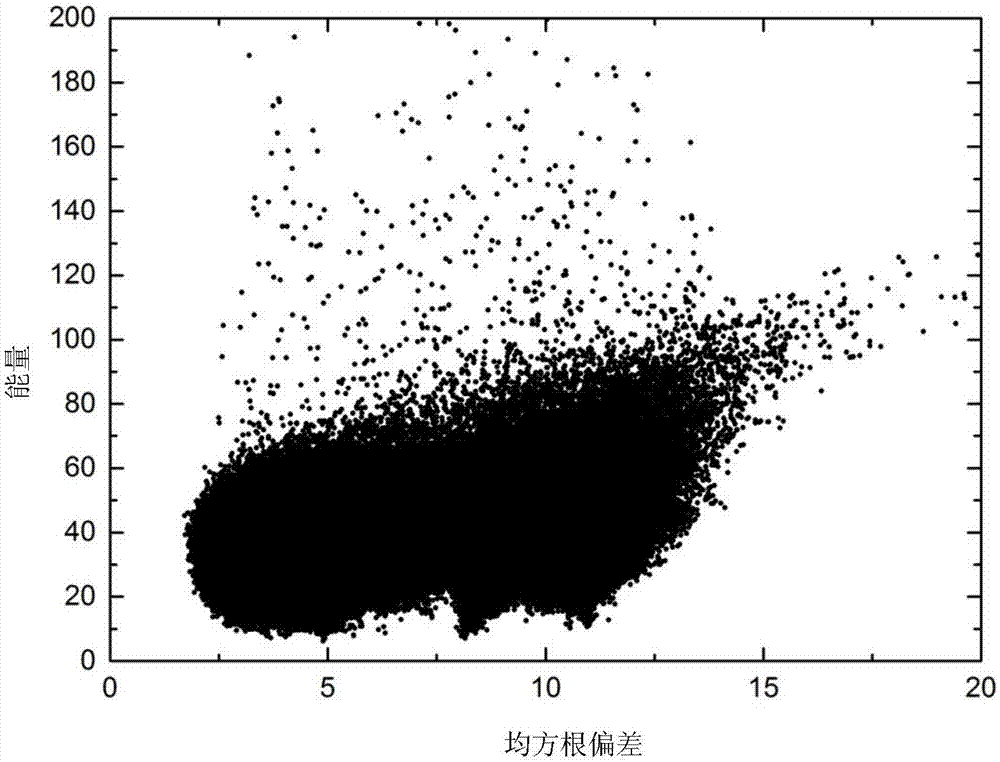
图1是基于种群的受限于loop区域片段组装的蛋白质结构预测方法对蛋白质1gyz进行结构预测时得到的构象分布图。
图2是基于种群的受限于loop区域片段组装的蛋白质结构预测方法对蛋白质1gyz进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明做进一步描述。
参照图1和图2,一种基于二级结构片段组装的群体蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置,过程如下:
读入目标蛋白质的序列信息,片段库信息,设置蛋白质构象的种群pose={p1,p2,...,pi,...,pn},其中n是种群大小,pi表示种群的第i个个体,迭代次数为g,最大迭代次数gmax,信息交互概率r,序列长度为l;
2)种群初始化,过程如下:
根据蛋白质构象的初始直链,通过复制这些直链得到n个初始种群个体,使用片段长度为9的片段对种群的个体pi进行片段组装,组装至构象所有位置的残基类型都被至少替换过一次,则视作初始化操作完成,对种群中所有个体进行初始化操作;
3)种群信息交互,过程如下:
对种群中每一个个体pi,根据所给的信息交互概率进行判断该个体是否进行种群交互,若进行种群交互,则从种群中随机选取另外一个个体pj,其中i≠j,随机选取pi构象的其中一个loop区域,与pj构象相对应的区域进行二面角信息的交换,信息交互后得到两个新的个体pi′,pj′,若不进行种群交互,则对种群中下一个个体进行步骤3),完成对种群中所有个体的信息交互;
4)基于二级结构的种群片段组装,过程如下:
对个体pi′,i∈[1,np]进行9片段的片段组装,在每次片段组装后进行判断,若片段组装的区域中包括loop区域的残基,则使用片段组装前的构象的loop区域的残基的信息替换当前的loop区域残基的信息,即保留loop区域的结构信息,得到个体pi″,对种群中所有个体都进行基于二级结构的片段组装操作;
5)对loop区域进行扰动,过程如下:
对个体pi″,i∈[1,np]的loop区域进行扰动,对构象loop区域的每一个残基的二面角进行±2的角度范围内的微调,得到个体pi″′,在扰动过程之后,利用能量函数分别对扰动前后的个体进行评价得到ei和ei′,若ei<ei′,则跳回至步骤4)重新进行片段组装,若ei>ei′,则结束变异操作并得到新的个体;
6)使用能量函数对种群进行选择,过程如下:
首先,把初始种群和扰动后的种群合并成一个种群大小为2*n的新种群,然后,根据能量函数计算新种群个体的能量,根据能量的高低对合并后的种群排序,选取前n个能量低的个体作为选择后的种群个体,最后,设置g=g+1;
7)判断是否达到最大得迭代次数gmax,若满足条件则停止迭代并输出最后一代种群个体信息,否则返回步骤3)。
本实施例以序列长度为60的α折叠蛋白质1gyz为实施例,一种基于种群的受限于loop区域片段组装的蛋白质结构预测方法,所述方法包括以下步骤:
1)参数设置,过程如下:
读入目标蛋白质的序列信息,片段库信息,设置蛋白质构象的种群pose={p1,p2,...,pi,...,pn},其中n=100是种群大小,pi表示种群的第i个个体,迭代次数为g,最大迭代次数gmax=100,信息交互概率r=0.1,序列长度为l=60;
2)种群初始化,过程如下:
根据蛋白质构象的初始直链,通过复制这些直链得到100个初始种群个体,使用片段长度为9的片段对种群的个体pi进行片段组装,组装至构象所有位置的残基类型都被至少替换过一次,则视作初始化操作完成,对种群中所有个体进行初始化操作;
3)种群信息交互,过程如下:
对种群中每一个个体pi,根据所给的信息交互概率进行判断该个体是否进行种群交互,若进行种群交互,则从种群中随机选取另外一个个体pj,其中i≠j,随机选取pi构象的其中一个loop区域,与pj构象相对应的区域进行二面角信息的交换,信息交互后得到两个新的个体pi′,pj′,若不进行种群交互,则对种群中下一个个体进行步骤3),完成对种群中所有个体的信息交互;
4)基于二级结构的种群片段组装,过程如下:
对个体pi′,i∈[1,np]进行9片段的片段组装,在每次片段组装后进行判断,若片段组装的区域中包括loop区域的残基,则使用片段组装前的构象的loop区域的残基的信息替换当前的loop区域残基的信息,即保留loop区域的结构信息,得到个体pi″,对种群中所有个体都进行基于二级结构的片段组装操作;
5)对loop区域进行扰动,过程如下:
对个体pi″,i∈[1,np]的loop区域进行扰动,对构象loop区域的每一个残基的二面角进行±2的角度范围内的微调,得到个体pi″′,在扰动过程之后,利用能量函数“score3”分别对扰动前后的个体进行评价得到ei和ei′,若ei<ei′,则跳回至步骤4)重新进行片段组装,若ei>ei′,则结束变异操作并得到新的个体;
6)使用能量函数对种群进行选择,过程如下:
首先,把初始种群和扰动后的种群合并成一个种群大小为2*n的新种群,然后,根据能量函数“score3”计算新种群个体的能量,根据能量的高低对合并后的种群排序,选取前n个能量低的个体作为选择后的种群个体,最后,设置g=g+1;
7)判断是否达到最大得迭代次数gmax,若满足条件则停止迭代并输出最后一代种群个体信息,否则返回步骤3)。
以序列长度为60的α折叠蛋白质1gyz为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为
以上说明是本发明以1gyz蛋白质为实例所得出的优化效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!