一种基于拉普拉斯正则化的低秩稀疏表征图像特征学习方法与流程
本发明涉及人脸图像识别方法,特别涉及一种基于拉普拉斯正则化的低秩稀疏表征图像特征学习方法。
背景技术
目前在大规模的图像特征学习上,带有标签的训练样本难以获取,导致一些现有常用的监督型特征学习技术难以运用,而带有噪音的训练样本进一步限制了它们的性能。
现有方法中通常假设图像样本数据都分布在独立的低维子空间中,或者近似跨越多个低维子空间,且具有低秩稀疏的结构。一些方法利用低秩稀疏约束表征学习方法学习原始数据的空间结构,同时对数据起到去噪的作用。它通过核范数寻找数据的低秩结构,通过l1范数寻找数据的稀疏结构,通过l2,1范数处理噪音,在一定的技术条件下,可以精确地恢复样本数据的低维子空间结构,在此基础上,对恢复的数据运用一些通用的降维方法进行特征提取,具有一定的鲁棒性。但已有的特征学习方法通常没有将特征学习与分类任务相关联,使得学习到的特征判别性较弱,稳定性差,导致这些方法的总体性能受到损害。
技术实现要素:
为克服上述现有图像分析方法的不足,本发明提出了一种新的基于拉普拉斯正则化的低秩稀疏表征图像特征学习方法。本发明充分利用小样本的标签信息进行特征学习,并在特征学习的同时,训练分类模型,使得学习到的数据的特征更具有判别性和鲁棒性,算法更加稳定。
为解决上述技术问题,本发明的技术方案如下:
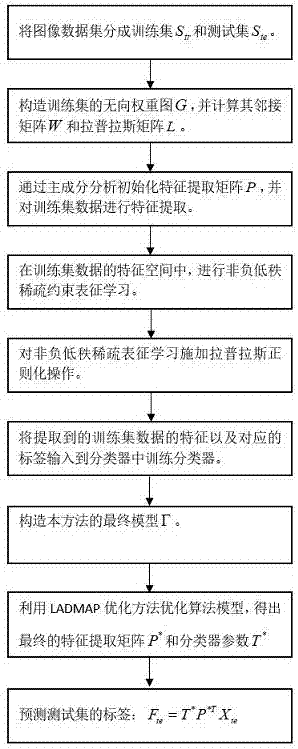
一种基于拉普拉斯正则化的低秩稀疏表征图像特征学习方法,其特征在于,包括以下步骤:
s1:将图像数据集分成训练集str={xtr,ytr}和测试集ste={xte,fte},所述的xtr是训练集,所述的ytr是训练集的标签,所述的xte是测试集,所述的fte是预测测试集的标签;
s2:构造训练集str的无向权重图g={v,e},所述的v为样本点集,所述的e为样本边集,通过无向权重图g得到g的邻接矩阵w以及g的拉普拉斯矩阵l=d-w,其中
s3:采用主成分分析方法初始化正交的特征提取矩阵p,通过矩阵p对训练集数据xtr提取特征ptxtr;
s4:基于s1~s3设计一个非负低秩稀疏表征的学习模型γ;
s5:采用ladmap优化方法对s4中的学习模型γ进行优化,得到最终的特征提取矩阵p*和最终的分类器参数t*;
s6:通过s5中的最终的特征提取矩阵p*对测试集样本xte提取特征p*txte,再将提取到的特征p*txte输入到分类器中预测标签fte=t*p*txte。
在一种优选的方案中,所述的s4包括以下步骤:
s4.1:在训练集数据xtr的特征空间ptxtr中,进行非负低秩稀疏约束表征学习,得到相关模型d,所述的相关模型d通过下式进行表达:
其中,所述的rank(·)为秩函数,所述的z是重构系数矩阵,所述的e是重构误差矩阵,所述的p是正交矩阵,所述的λ、γ均是惩罚因子,所述的i是单位矩阵,所述的||·||表示范数;
s4.2:通过s2中的拉普拉斯矩阵l进行正则化操作,结合相关模型d得到模型d’,所述的模型d’通过下式进行表达:
s.t.ptxtr=ptxtrz+e,z≥0,ptp=i
其中,所述的tr(·)为迹函数,所述的β是惩罚因子;
s4.3:在模型d’上添加损失函数f(ptxtr,ytr,t),得到学习模型γ,所述的学习模型γ通过下式进行表达:
s.t.ptxtr=ptxtrz+e,z≥0,ptp=i
其中,所述的α是惩罚因子。
本优选方案中,由于s2中在数据的原始空间中计算拉普拉斯矩阵,然后在s4.2中,在数据的特征空间中引入拉普拉斯正则化,保持了数据局部结构一致性。其次,非负低秩稀疏表征学习模型γ是运行在训练样本集xtr的特征空间ptxtr中而非在原始数据空间。
在一种优选的方案中,s4.3中的f(ptxtr,ytr,t)通过下式进行表达:
所述的||·||f是f范数。
本优选方案中,样本xtr与其标签ytr通过一个可学习且维度大小可调的特征空间p连接在一起。损失函数f(ptxtr,ytr,t)将特征学习和分类器模型参数学习两个学习过程合并在其中,同时计算特征提取矩阵p*和最终分类器参数t*,经过一步优化使特征提取矩阵p*与分类器参数t*达到全局最优。
与现有技术相比,本发明技术方案的有益效果是:
1、本发明在数据的特征空间对其进行非负低秩稀疏约束表征学习,保证了数据的全局低秩结构,更准确的地恢复了数据的子空间结构,具有很强的鲁棒性,而拉普拉斯正则项则考虑到了数据的局部几何结构,使得数据特征空间的几何结构与原始数据空间的结构尽可能地保持一致;
2、本发明中的算法模型通过将特征学习与分类器学习相结合,使得特征提取矩阵和分类器参数达到全局最优,有效提高了算法的精确度和鲁棒性;
3、本发明的模型算法运行在数据的低维特征空间中,极大地降低了算法的时间复杂度,减少了迭代次数。
附图说明
图1为本实施例流程图。
图2为本实施例部分实验结果示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。下面结合附图和实施例对本发明的技术方案做进一步的说明。
orl人脸数据库由英国剑桥olivetti实验室从1992年4月到1994年4月期间拍摄的一系列人脸图像组成,共有40个不同年龄、不同性别和不同种族的对象。每个人10幅图像,共计400幅灰度图像,每幅图像的分辨率为32×32。本实施例结合图1做进一步的详细描述。
一种基于拉普拉斯正则化的低秩稀疏表征图像特征学习方法,包括以下步骤:
步骤s1,将orl数据集分成训练集str={xtr,ytr}和测试集ste={xte,fte}。对于每一个对象,从其10幅人脸图像中随机选出5幅作为训练样本,而剩余的5幅作为测试样本,即xtr包含40*5=200幅人脸图像,xte同样也包含200幅人脸图像。令x={xtr,xte}表示所有的人脸图像。为了验证本实施例的鲁棒性,对所有的图像xi,i=1,2,...400,随机添加不同程度的白色灰度图ai,即xi+ai,最终得到带有噪音的训练集和测试集。为了便于接下来的计算,我们将xtr中的每一幅图像矩阵列向量化,得到200列向量,每一列代表一幅人脸图像,再将这200列向量按列排列拼成一个矩阵,仍记为xtr,对于xte施加同样的操作。ytr∈r40×200,第i列是训练集第i个样本的标签,
步骤s2,构造训练集str的无向权重图g={v,e},v为数据点集,总共有200个点,e为边集,
步骤s3,通过主成分分析方法初始化正交的特征提取矩阵p。首先对所有样本进行中心化:
步骤s4-s8,构建本实施例的最终的模型γ:
s.t.ptxtr=ptxtrz+e,z≥0,ptp=i
将拉普拉斯矩阵l,ptxtr和ytr作为输入,利用ladmap优化算法解出模型γ,最终学习到特征提取矩阵p*和分类器参数t*。
步骤s9,通过学习到的特征提取矩阵p*对测试集数据xte进行特征提取p*txte,再将提取到的特征p*txte输入到分类器中预测其标签fte=t*p*txte。对于测试集中的第i个样本
本实施例中,实验平台是win10系统上的matlabr2017a软件,cpu的型号为inteli7-6700k@4.00ghz。实验结果如图2所示,图示为部分测试集识别结果,20个类,每个类包含5个样本,其中蓝色框为正确识别的样本,红色框为识别错误的样本。
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!