基于大数据的互联网金融黑名单系统及其应用方法与流程
本发明涉及大数据、数据分析和数据挖掘的技术领域,尤其涉及基于大数据的互联网金融黑名单系统及其应用方法。
背景技术:
在互联网时代,运用大数据技术与数据分析和数据挖掘等技术,可以更有效更低廉收集用户数据,从而可以更加准确评估个人或者企业的信用水平,提高了风险管理的效率。黑名单数据来源多种多样,往往具有完全不同的数据格式,更新频率也都不一致;黑名单的数据量非常大,数据结构繁杂;由于黑名单数据其松散的性质,黑名单系统一般也是一个结构松散的系统,不同数据源区别太大,关联度不高,无缝整合难度比较大。
在调用互联网金融黑名单数据时,数据处理系统由于处理非常大的数据量,包括几十种甚至上百种不同格式的数据源,需要很多计算资源,所以需要较长的计算时间,不能快速给出响应。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供基于大数据的互联网金融黑名单系统及其应用方法,旨在解决现有技术的互联网金融黑名单系统不能快速响应服务请求的问题。
本发明的目的采用以下技术方案实现:
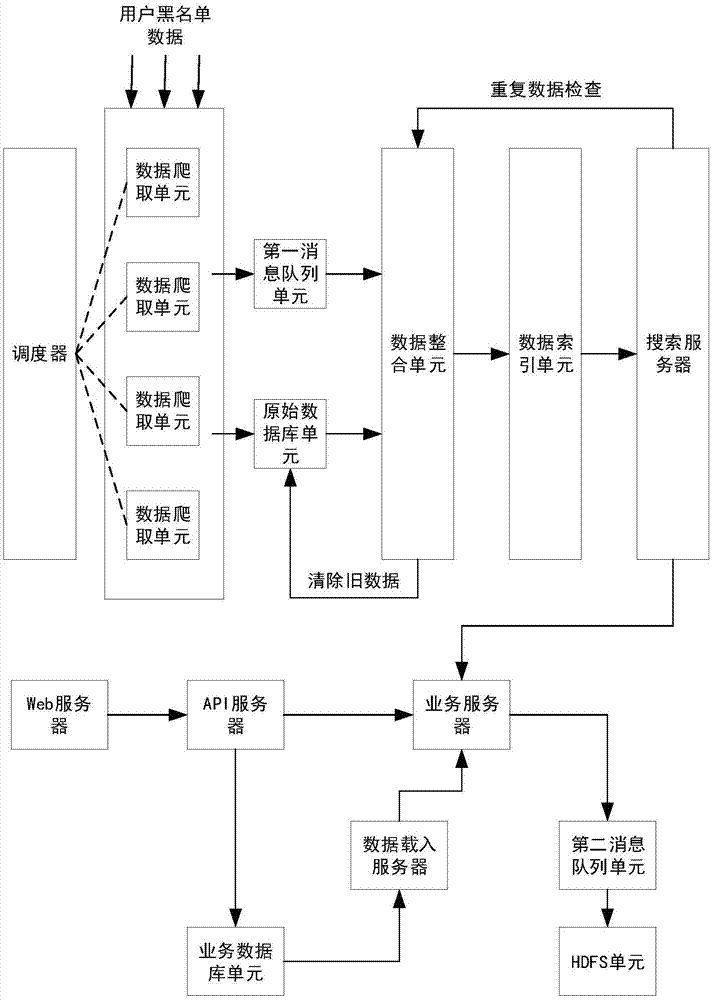
一种基于大数据的互联网金融黑名单系统,包括离线数据索引模块、在线数据查询模块和搜索服务器,其中:
离线数据索引模块包括顺序连接的数据爬取单元、数据整合单元、数据索引单元;
在线数据查询模块包括业务服务器;
数据索引单元和业务服务器分别与搜索服务器连接;
数据爬取单元爬取用户黑名单数据;数据整合单元获取用户黑名单数据,对数据进行清洗和加工,并将处理后的数据发送到数据索引单元;数据索引单元根据数据整合单元发送的数据在搜索服务器上建立或者更新数据索引;
业务服务器接收到服务请求后,查询搜索服务器上已经处理并索引好的用户黑名单数据,根据查询到的结果作出评估,将评估结果返回给用户。
在上述实施例的基础上,优选的,所述离线数据索引模块还包括调度器、第一消息队列单元和原始数据库单元;
调度器与数据爬取单元连接;
原始数据库单元设置于数据爬取单元与数据整合单元之间;
第一消息队列单元设置于数据爬取单元与数据整合单元之间;
数据整合单元还和搜索服务器连接;
调度器根据每种数据源的特性调度数据爬取单元;
数据爬取单元将爬取到的用户黑名单数据存入原始数据库单元,然后使用元数据产生一条信息写入第一消息队列单元;
数据整合单元从第一消息队列单元获取新的消息,对数据进行清洗和加工,并将处理后的结果发送到数据索引单元;
数据索引单元根据数据整合单元发送的结果建立或者更新数据索引。
在上述任意实施例的基础上,优选的,所述在线数据查询模块还包括web服务器和api服务器;
web服务器、api服务器、业务服务器顺序连接;
web服务器接收用户通过网页或者手机app发送的服务请求,将服务请求通过api服务器发送到业务服务器。
在上述任意实施例的基础上,优选的,所述在线数据查询模块还包括业务数据库单元和数据载入服务器;
业务数据库单元、数据载入服务器、业务服务器顺序连接;
业务服务器通过数据载入服务器调用业务数据库单元的数据。
在上述任意实施例的基础上,优选的,所述在线数据查询模块还包括第二消息队列单元和hdfs单元;
业务服务器、第二消息队列单元和hdfs单元顺序连接;
业务服务器通过第二消息队列单元将业务请求数据存入hdfs单元。
在上述任意实施例的基础上,优选的,所述搜索服务器为elasticsearch。
一种基于大数据的互联网金融黑名单系统的应用方法,包括:
离线数据索引步骤,数据爬取单元爬取用户黑名单数据;数据整合单元获取用户黑名单数据,对数据进行清洗和加工,并将处理后的数据发送到数据索引单元;数据索引单元根据数据整合单元发送的数据在搜索服务器上建立或者更新数据索引;
在线数据查询步骤,业务服务器接收到服务请求后,查询搜索服务器上已经处理并索引好的用户黑名单数据,根据查询到的结果作出评估,将评估结果返回给用户。
在上述实施例的基础上,优选的,所述离线数据索引步骤,具体为:
调度器根据每种数据源的特性调度数据爬取单元;
数据爬取单元将爬取到的用户黑名单数据存入原始数据库单元,然后使用元数据产生一条信息写入第一消息队列单元;
数据整合单元从第一消息队列单元获取新的消息,对数据进行清洗和加工,并将处理后的结果发送到数据索引单元;
数据索引单元根据数据整合单元发送的结果建立或者更新数据索引。
在上述任意实施例的基础上,优选的,所述在线数据查询步骤前,还包括:
web服务器接收用户通过网页或者手机app发送的服务请求,将服务请求通过api服务器发送到业务服务器。
在上述任意实施例的基础上,优选的,所述对数据进行清洗和加工,包括:
数据整合单元检索搜索服务器,查询是否有用户黑名单数据的相关纪录;如果有的话,根据实际情况进行去重、删掉重复纪录或者和相关纪录进行合并整合。
相比现有技术,本发明的有益效果在于:
本发明公开了基于大数据的互联网金融黑名单系统及其应用方法,通过离线数据索引模块离线处理海量互联网金融黑名单数据,提取特征并进行高效索引,在接收到服务请求时,通过在线数据查询模块对准备授信用户的相关黑名单数据进行实时查询,在线数据查询模块直接利用离线服务产生的结果,对服务数据进行实时评估计算,快速给出响应。数据爬取并建立数据索引比较耗费资源,需要较长的时间做数据清洗、数据整合,甚至分析数据关联和建立数据模型,本发明对于服务请求,可以直接查询已经处理并索引好的数据,并快速作出评估,将结果返回给客户,这样就极大地降低了坏账率,提高了金融风险控制的整体效率和准确率。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1示出了本发明实施例提供的一种基于大数据的互联网金融黑名单系统的结构示意图;
图2示出了本发明实施例提供的一种基于大数据的互联网金融黑名单系统的应用方法的流程示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
具体实施例一
如图1所示,本发明实施例提供了一种基于大数据的互联网金融黑名单系统,包括离线数据索引模块、在线数据查询模块和搜索服务器,其中:离线数据索引模块包括顺序连接的数据爬取单元、数据整合单元、数据索引单元;在线数据查询模块包括业务服务器;数据索引单元和业务服务器分别与搜索服务器连接。数据爬取单元爬取用户黑名单数据;数据整合单元获取用户黑名单数据,对数据进行清洗和加工,并将处理后的数据发送到数据索引单元;数据索引单元根据数据整合单元发送的数据在搜索服务器上建立或者更新数据索引;业务服务器接收到服务请求后,查询搜索服务器上已经处理并索引好的用户黑名单数据,根据查询到的结果作出评估,将评估结果返回给用户。
本发明实施例通过离线数据索引模块离线处理海量互联网金融黑名单数据,提取特征并进行高效索引,在接收到服务请求时,通过在线数据查询模块对准备授信用户的相关黑名单数据进行实时查询,在线数据查询模块直接利用离线服务产生的结果,对服务数据进行实时评估计算,快速给出响应。数据爬取并建立数据索引比较耗费资源,需要较长的时间做数据清洗、数据整合,甚至分析数据关联和建立数据模型,本发明实施例对于服务请求,可以直接查询已经处理并索引好的数据,并快速作出评估,将结果返回给客户,这样就极大地降低了坏账率,提高了金融风险控制的整体效率和准确率。
优选的,所述离线数据索引模块还可以包括调度器、第一消息队列单元和原始数据库单元;调度器与数据爬取单元连接;原始数据库单元设置于数据爬取单元与数据整合单元之间;第一消息队列单元设置于数据爬取单元与数据整合单元之间;数据整合单元还和搜索服务器连接。调度器根据每种数据源的特性调度数据爬取单元;数据爬取单元将爬取到的用户黑名单数据存入原始数据库单元,然后使用元数据产生一条信息写入第一消息队列单元;数据整合单元从第一消息队列单元获取新的消息,对数据进行清洗和加工,并将处理后的结果发送到数据索引单元;数据索引单元根据数据整合单元发送的结果建立或者更新数据索引。优选的,数据整合单元还与原始数据库单元连接。这样做的好处是,调度器会针对每种数据源的特性来智能调度数据爬取服务,使得数据爬取服务可以按需要周期性运行。
优选的,所述在线数据查询模块还可以包括web服务器和api服务器;web服务器、api服务器、业务服务器顺序连接;web服务器接收用户通过网页或者手机app发送的服务请求,将服务请求通过api服务器发送到业务服务器。用户终端,如手机、平板电脑、笔记本电脑和台式机等,分别与web服务器连接。这样做的好处是,用户的服务请求可以通过网页或者手机app发送到web服务器,然后再通过api服务器,并最终发送到业务服务器。
优选的,所述在线数据查询模块还可以包括业务数据库单元和数据载入服务器;业务数据库单元、数据载入服务器、业务服务器顺序连接;业务服务器通过数据载入服务器调用业务数据库单元的数据。优选的,api服务器还与业务数据库单元连接。这样做的好处是,在做决策判断的时候,业务服务器可能会用到业务数据库的一些信息,此时可以通过数据载入服务器来实现。数据载入服务器会定期获取数据库里更新之后的纪录,载入内存并编译成相关的数据结构。这样,业务服务器就可以定期去获取相关纪录。业务服务器和数据载入服务器之间的通讯可以通过httpget/post进行。数据载入服务器和业务服务器都会将拿到的数据在本地存一份拷贝,目的是避免机器重新启动之后又去数据库拿历史纪录。通过这种方式,机器刚起来的时候,首先从本地硬盘载入过往已经读取过的数据,再去业务数据库获取更新之后的数据,降低了数据库的压力。
优选的,所述在线数据查询模块还可以包括第二消息队列单元和hdfs单元;业务服务器、第二消息队列单元和hdfs单元顺序连接;业务服务器通过第二消息队列单元将业务请求数据存入hdfs单元。这样做的好处是,可以将业务请求数据存入hdfs单元,供离线数据索引模块进行数据加工的时候使用。
本发明实施例对搜索服务器不做限定,优选的,所述搜索服务器可以选用elasticsearch。
本发明实施例对实际应用中所搭建的基于大数据的架构模型不做限定,优选的,可以选择lambda结构,该结构是一个指导大数据系统搭建的架构模型,可以很好地解决实时大数据系统的关键特性。
优选的,原始数据库里面存储的原始数据会定期被清除,从而节约空间。
数据整合单元还可以检索elasticsearch,查询是否有重复或者相关纪录。如果有的话,根据实际情况进行去重,或者是删掉重复纪录,或者是和相关纪录进行合并整合,并最终将新产生的数据写入elasticsearch,建立或者是更新索引。
离线数据索引模块由于处理非常大的数据量,包括几十种甚至上百种不同格式的数据源,需要很多计算资源,所以需要较长的计算时间。幸运的是,数据爬取和数据处理这部分对时间要求相对不敏感,放在离线系统处理可以使用更多的计算资源,也可以处理更复杂的运算,使得计算结果更精确更有效。
在线数据查询模块由于其对响应速度要求非常严格,处理的qps也相当高,可以避免处理需要计算资源太多,数据量太大的操作。
离线数据索引模块和在线数据查询模块又是相互补充。离线数据索引模块定期运行,将处理好的结果建立索引,放入elasticsearch。另一方面,在线数据查询模块直接利用离线服务产生的结果,对服务数据进行实时评估计算,快速给出响应。值得一提的是,业务请求数据也会存入hdfs,供离线数据索引模块进行数据加工的时候使用。
两个系统既相对独立,又互相耦合,缺一不可。离线数据索引模块的数据分析和数据更新不会直接影响在线数据查询模块的业务逻辑。另一方面,在线数据查询模块的业务逻辑的更改也不会直接影响离线系统的数据处理。而且,两套系统分开运行,通过定义好的接口进行配合工作,又可以分开维护。
在上述的具体实施例一中,提供了基于大数据的互联网金融黑名单系统,与之相对应的,本申请还提供基于大数据的互联网金融黑名单系统的应用方法。由于方法实施例基本相似于系统实施例,所以描述得比较简单,相关之处参见系统实施例的部分说明即可。下述描述的方法实施例仅仅是示意性的。
具体实施例二
如图2所示,本发明实施例提供了一种基于大数据的互联网金融黑名单系统的应用方法,包括:
离线数据索引步骤s101,数据爬取单元爬取用户黑名单数据;数据整合单元获取用户黑名单数据,对数据进行清洗和加工,并将处理后的数据发送到数据索引单元;数据索引单元根据数据整合单元发送的数据在搜索服务器上建立或者更新数据索引;
在线数据查询步骤s102,业务服务器接收到服务请求后,查询搜索服务器上已经处理并索引好的用户黑名单数据,根据查询到的结果作出评估,将评估结果返回给用户。
本发明实施例通过离线数据索引模块离线处理海量互联网金融黑名单数据,提取特征并进行高效索引,在接收到服务请求时,通过在线数据查询模块对准备授信用户的相关黑名单数据进行实时查询,在线数据查询模块直接利用离线服务产生的结果,对服务数据进行实时评估计算,快速给出响应。数据爬取并建立数据索引比较耗费资源,需要较长的时间做数据清洗、数据整合,甚至分析数据关联和建立数据模型,本发明实施例对于服务请求,可以直接查询已经处理并索引好的数据,并快速作出评估,将结果返回给客户,这样就极大地降低了坏账率,提高了金融风险控制的整体效率和准确率。
优选的,所述离线数据索引步骤s101,可以具体为:调度器根据每种数据源的特性调度数据爬取单元;数据爬取单元将爬取到的用户黑名单数据存入原始数据库单元,然后使用元数据产生一条信息写入第一消息队列单元;数据整合单元从第一消息队列单元获取新的消息,对数据进行清洗和加工,并将处理后的结果发送到数据索引单元;数据索引单元根据数据整合单元发送的结果建立或者更新数据索引。
在上述任意实施例的基础上,优选的,所述在线数据查询步骤s102前,还可以包括:web服务器接收用户通过网页或者手机app发送的服务请求,将服务请求通过api服务器发送到业务服务器。
在上述任意实施例的基础上,优选的,所述对数据进行清洗和加工,可以包括:数据整合单元检索搜索服务器,查询是否有用户黑名单数据的相关纪录;如果有的话,根据实际情况进行去重、删掉重复纪录或者和相关纪录进行合并整合。当搜索服务器为elasticsearch时,数据整合单元可以检索elasticsearch,查询是否有重复或者相关纪录。如果有的话,根据实际情况进行去重,或者是删掉重复纪录,或者是和相关纪录进行合并整合,并最终将新产生的数据写入elasticsearch,建立或者是更新索引。
本发明实施例的应用场景可以是:
针对每一种数据源,比如微博、支付宝、领英、公积金、社保,或者其他的第三方的服务商都有一个单独的数据爬取服务进行专门对接,爬取用户相关的数据;所有的这些数据爬取服务通过一个统一调度器来集中管理,调度器会针对每种数据源的特性来智能调度数据爬取服务,使得数据爬取服务可以按需要周期性运行;数据爬取的结果会被爬取服务解析,并存入爬取数据库,然后使用元数据产生一条信息,写入分布式消息队列;数据整合服务会从消息队列获取新的消息,对数据进行清洗和加工;数据检索服务还会检索elasticsearch,查询是否有重复或者相关纪录,如果有的话,根据实际情况进行去重,或者是删掉重复纪录,或者是和相关纪录进行合并整合,并最终将新产生的数据写入elasticsearch,建立或者是更新索引。更新后的索引就可以提供给业务服务器进行实时检索。
本发明从使用目的上,效能上,进步及新颖性等观点进行阐述,其具有的实用进步性,己符合专利法所强调的功能增进及使用要件,本发明以上的说明及附图,仅为本发明的较佳实施例而己,并非以此局限本发明,因此,凡一切与本发明构造,装置,待征等近似、雷同的,即凡依本发明专利申请范围所作的等同替换或修饰等,皆应属本发明的专利申请保护的范围之内。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。尽管本发明已进行了一定程度的描述,明显地,在不脱离本发明的精神和范围的条件下,可进行各个条件的适当变化。可以理解,本发明不限于所述实施方案,而归于权利要求的范围,其包括所述每个因素的等同替换。对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!