基于非主属性离群点检测的实体匹配方法和计算机程序与流程
本发明属于互联网技术领域,特别是涉及一种基于非主属性离群点检测的实体匹配方法和计算机程序。
背景技术
未来三十年,数据应用越来越凸现,这必将影响到民航信息化的建设和发展。随着移动互联网的推广,可以将一些便捷性的应用推向智能终端,通过大数据技术来分析旅客的行为,了解他们的关注点,以改善用户的航空体验。
从全球民航发展情况看,由于市场竞争不断加剧,民航业长期处于微利运营水平。随着近年来全球金融危机的持续恶化,使得航空公司的生存压力日益增大。在日益艰难的市场环境中,航空公司希望通过不断提高旅客服务的水平,从而提升旅客忠诚度,提高公司盈利能力与行业竞争力。
美国纽约的约翰·肯尼迪国际机场是美国三大商务机场之一。该机场建立了一个完善的集空管、机场、航空公司信息为一体的网上信息整合平台,向公众发布各类实时信息,方便旅客的出行。然而,如今随着信息化产业的不断技术发展,旅客对信息的需求不单单局限于相关航空数据,而更多的希望获取更加完善的非航数据,航空旅游数据等。2015年5月28日举行的第七届数字民航趋势发展峰会上,中国南航、世纪互联、浪潮集团等知名企业的专家汇聚一堂,就如何运用大数据、互联网、云计算新一代信息技术,提升航空业的管理和民营环境、改善客户服务质量、提供个性化的航旅服务等问题进行了探讨。
在公共主动服务平台研发方面,国外厂商关注于利用现有技术和从其他行业收集而来的数据分析,来改善航空公司旅客的客户体验,通过抓取旅客在整个旅行途中的多内容数据和分析评估,为航空公司客户提供更个性化的服务。中国航信作为国内唯一的全球分销服务提供商,拥有丰富的民航运营数据资源,各类数据由不同的信息系统进行处理,但信息不能有效的共享,信息不对称,流程不通畅,形成了大量的信息孤岛。能否将企业内部数据资源与外部数据资源有效的整合起来,为企业服务水平提升及行业数据标准化提供有力支撑,成为摆在企业面前的严峻挑战。建立公共服务平台就是要统一为企业和民航业提供完备、一致的数据,以及灵活多样、丰富有效的服务,为数据共享提供良好基础,为服务标准化、专业化提供更完善的应用管理平台。
互联网等多内容数据资源汇聚整合:包括天气、事件、情景信息的采集,用于匹配旅客出行信息和其他行业数据,发现特定天气因素或情景因素导致的特殊民航信息规律等;整合非航数据(酒店信息、目的地旅游产品、租车、火车、大巴、社交网络等第三方媒体)、航空旅游数据(机票及航空公司增值附加服务,如餐食预定、贵宾通道等,crm,旅客价值信息)、销售规则及渠道控制策略、订单库、交易数据库和文件系统等。
综上所述,现有技术存在的缺陷为:本文引入的监督分类器模型是需要训练的,标签的标注是需要很大的工作量的,未来可以尝试采用弱监督或众包,使系统自动发现匹配,减少人工标注的工作量是下一步研究的重点。
技术实现要素:
发明目的:本发明要解决的技术问题是对非航数据实体描述多样性,提供一种基于非主属性离群点检测的实体匹配方法。该方法通过非主属性值可较好的消除不同源中同一实体主属性值不同所带来的歧义。同时,根据非主属性值较快的排除不匹配记录。将非主属性与离群点检测模型相结合,即考虑了主属性值多样性带来的歧义,又考虑了非匹配对数量远大于匹配对数引起的数据不均衡,建立了基于非主属性的离群点检测的匹配方法。最后引入监督分类器模型进行训练、识别。并在一定程度上克服离群点匹配在传统奇异值分解中不能应用在大规模数据的弊端。
技术方案
本发明的目的一是提供一种基于非主属性离群点检测的实体匹配方法,包含下列步骤:
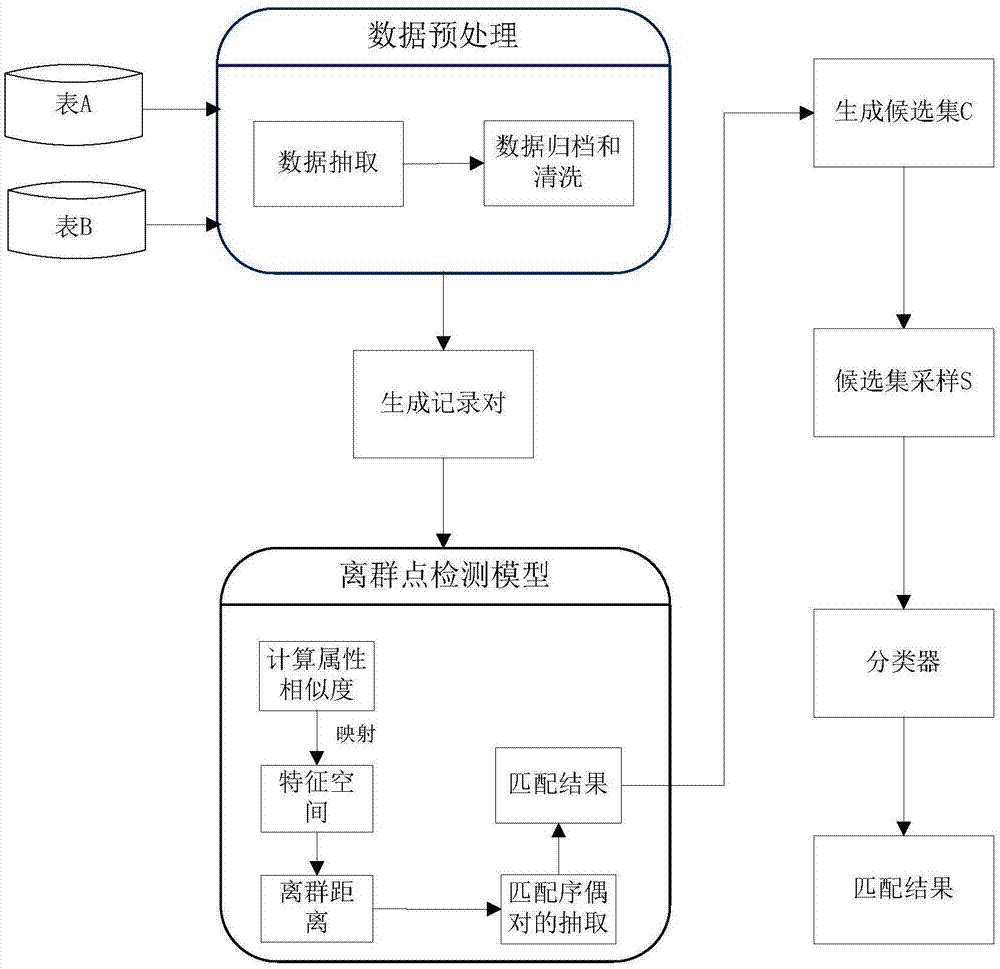
步骤一:数据预处理,即处理原始的数据实体,并生成em的输入数据集。根据输入数据和输出数据的不同,数据预处理主要包括两部分内容:
数据抽取:根据实验的目标,找出不同源数据的共同非主属性,采用增量抽取的方式,并将抽取的数据存到另外的表格。并用正则表达式或自然语言处理技术,去除有明显错误或无意义的字段信息。
数据归档和清洗:利用归档计算并统计数据的一些基本信息,比如:统计重复的数据,样本的个数等,从而方便数据的清洗,比如删除重复数据,文本标准化等替换一些其他特殊字符(“&”替换成“and”)等。从而达到统一的数据组织方式,将实体中杂乱的信息统一为相同的数据结构,为后续实体比较步骤提供数据输入。
步骤二:记录对生成,即收集数据预处理结果,对数据集依据非主属性重叠度和非主属性相似性进行分块。通过分块策略将数据切分为多块,属于不同块的实体将不生成记录对,从而减少记录对的生成量,提升处理效率。同时,由于不同块的记录间不会比较相似性,在一定程度上对效率也有所提升。分块策略描述如下:
(a)属性值重叠度(overlap_size)分块,给定表1和表2,对其特定公共的非主属性,比如“酒店描述”、“地址”等文本类型的数据,假定某个记录对的地址有重叠,对每个重叠的词进行标记一次,如果该记录对标记数不小于重叠数,就可以说明其是同一实体,具体来说,如果设定overlap_size=3,也就是需要记录对的地址至少有三个重叠标记,满足该条件的进行保留,否则就筛掉。该过程中对于“的”、“在”这样的停用词是不进行标记的,故进行重叠度分块之前是要删除停用词的。
(b)属性值相似度分块,即对记录对进行粗筛选,比如给定的表1和表2,对于其中的星级、价格(除国家旅游局评定的外),不同的网站有很大差异,比如携程和同程对“北京邮电会议中心”的星级分别为2.5钻和3钻,可将其差值的绝对值限制在不大于1.5,即可视为同一实体。
步骤三:离群点检测模型,具体步骤如下:
1)对每一个记录对的不同非主属性进行相似度计算。由于不同实体的属性的类型不同,通过选择不同的相似度计算方法(haversine公式、余弦相似度等)进行计算,来提高可信度。
在该过程中针对地址的相似度,是将其转化为经纬度,计算有great-circledistance和haversine公式两种方法,本文中采用haversine公式来计算给定两个点之间的距离。有以下两步:
(a)给定两点
其中:
haversin(θ)=sin2(θ/2)=(1-cos(θ))/2
r为地球半径,可取平均值6371km;ω1,ω2表示两点的经度;
(b)将求得的经纬度距离利用min-max标准化即
其中,haversine是经纬度的距离,min是经纬度距离的最小值,max是经纬度距离的最大值。
2)将求出的属性相似度序列所形成的矢量,比如(sim(build),sim(renovated),sim(lat-log)),其中(lat-log是经纬度),依次添加到矩阵中,构成特征矩阵m:
3)根据求得的离群距离在特征矩阵m的基础上,利用奇异值分解svd,
m=usvt
来提取矩阵v的前p个列向量[10],构成矩阵vm×p;在此基础上,并采用均值法计算每一维的中心值n=[u(sim(build)),…,u(sim(lat-log))],利用欧式距离
其中,xi∈m,yi∈n,来求每个序列的离群距离。
4)根据求得的离群距离,设定相应的阈值θ,由第3)步中矩阵s的迹乘以一个(0,1)范围内的值来确定,大于该阈值的保留下来,小于该阈值的舍去,并用字典保存下来。
步骤四:根据离群检测模型筛选后的匹配对,使用简单的启发式规则来限制被认为是潜在匹配的配对数量。此过程中,在各个数据集中新建一列,将重要非主属性的值合并在一起,可将该列称为混合列,使用混合列创建所需的候选集c。通过不同数据集的合并可减少候选集的数量。
最后从候选集c中进行随机采样,获得样本集s,并手动或根据主属性用机器标记抽样候选集,也即是指定候选对是否是正确的匹配。如果是正确的匹配标为1,否则标记为0。
步骤五:使用上一步抽样的数据集,用于训练分类器,针对将要预测目标进行各种机器学习算法的训练,并在机器学习算法:决策树、随机森林、支持向量积、逻辑回归、朴素贝叶斯进上行实验,通过实验结果进行对比分析,得到最佳的匹配器,在得到的最佳匹配器上,进行实体匹配实验,然后使用训练的模型加上相似度进行数据集的匹配,进而可以得到匹配对,并通过准确率、召回率和f1值来评估实验的效率。
本发明的目的二是提供一种实现上述基于非主属性离群点检测的实体匹配方法的计算机程序。
本发明的目的三是提供一种实现上述基于非主属性离群点检测的实体匹配方法的信息数据处理终端。
本发明的目的四是提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述基于非主属性离群点检测的实体匹配方法。
有益效果
针对互联网上同一实体描述多样性的问题特点,本发明是根据实体的非主属性采用基于规则的方法对数据进行粗筛选,降低记录对的数据规模,在此基础上根据离群点距离做进一步的筛选,得到初步的实体对集,最后根据生成的实体对集进行采样,利用机器学习选择合适的匹配器并训练,得到实体匹配对。本发明能够运用在互联网上海量多源旅游、酒店等互联网多内容数据,较准确的对不同来源的同一实体进行识别。
本发明采用网上自己爬取数据,将非主属性与离群点检测模型相结合,即考虑了主属性值多样性带来的歧义,又考虑了非匹配对数量远大于匹配对数引起的数据不均衡,建立了基于非主属性的离群点检测的匹配方法。最后引入监督分类器模型进行训练、识别。通过与现有方法相比,可以看到我们的准确率和召回率有很大的提高。
附图说明
图1是本发明的实体匹配框架图;
图2是本发明优选实施例中非主属性个数对实体对数的影响图;
图3是本发明优选实施例中准确率、召回率和f1在不同算法中的比较图;
图4是本发明优选实施例中样本个数对效率的影响图。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下:
请参阅图1,一种基于非主属性离群点检测的实体匹配方法,包含下列步骤:
步骤一:数据预处理,即处理原始的数据实体,并生成em的输入数据集。根据输入数据和输出数据的不同,数据预处理主要包括两部分内容:
数据抽取:根据实验的目标,找出不同源数据的共同非主属性,采用增量抽取的方式,并将抽取的数据存到另外的表格。并用正则表达式或自然语言处理技术,去除有明显错误或无意义的字段信息。
数据归档和清洗:利用归档计算并统计数据的一些基本信息,比如:统计重复的数据,样本的个数等,从而方便数据的清洗,比如删除重复数据,文本标准化等替换一些其他特殊字符(“&”替换成“and”)等。从而达到统一的数据组织方式,将实体中杂乱的信息统一为相同的数据结构,为后续实体比较步骤提供数据输入。
步骤二:记录对生成,即收集数据预处理结果,对数据集依据非主属性重叠度和非主属性相似性进行分块。通过分块策略将数据切分为多块,属于不同块的实体将不生成记录对,从而减少记录对的生成量,提升处理效率。同时,由于不同块的记录间不会比较相似性,在一定程度上对效率也有所提升。分块策略描述如下:
(a)属性值重叠度(overlap_size)分块,给定表1和表2,对其特定公共的非主属性,比如“酒店描述”、“地址”等文本类型的数据,假定某个记录对的地址有重叠,对每个重叠的词进行标记一次,如果该记录对标记数不小于重叠数,就可以说明其是同一实体,具体来说,如果设定overlap_size=3,也就是需要记录对的地址至少有三个重叠标记,满足该条件的进行保留,否则就筛掉。该过程中对于“的”、“在”这样的停用词是不进行标记的,故进行重叠度分块之前是要删除停用词的。
(b)属性值相似度分块,即对记录对进行粗筛选,比如给定的表1和表2,对于其中的星级、价格(除国家旅游局评定的外),不同的网站有很大差异,比如携程和同程对“北京邮电会议中心”的星级分别为2.5钻和3钻,可将其差值的绝对值限制在不大于1.5,即可视为同一实体。
步骤三:离群点检测模型,具体步骤如下:
1)对每一个记录对的不同非主属性进行相似度计算。由于不同实体的属性的类型不同,通过选择不同的相似度计算方法(haversine公式、余弦相似度等)进行计算,来提高可信度。
在该过程中针对地址的相似度,是将其转化为经纬度,计算有great-circledistance和haversine公式两种方法,本文中采用haversine公式来计算给定两个点之间的距离。有以下两步:
(a)给定两点
其中:
haversin(θ)=sin2(θ/2)=(1-cos(θ))/2
r为地球半径,可取平均值6371km;ω1,ω2表示两点的经度;
(b)将求得的经纬度距离利用min-max标准化即
其中,haversine是经纬度的距离,min是经纬度距离的最小值,max是经纬度距离的最大值。
2)将求出的属性相似度序列所形成的矢量,比如(sim(build),sim(renovated),sim(lat-log)),其中(lat-log是经纬度),依次添加到矩阵中,构成特征矩阵m:
3)根据求得的离群距离在特征矩阵m的基础上,利用奇异值分解svd,
m=usvt
来提取矩阵v的前p个列向量[10],构成矩阵vm×p;在此基础上,并采用均值法计算每一维的中心值n=[u(sim(build)),…,u(sim(lat-log))],利用欧式距离
其中,xi∈m,yi∈n,来求每个序列的离群距离。
4)根据求得的离群距离,设定相应的阈值θ,由第3)步中矩阵s的迹乘以一个(0,1)范围内的值来确定,大于该阈值的保留下来,小于该阈值的舍去,并用字典保存下来。
步骤四:根据离群检测模型筛选后的匹配对,使用简单的启发式规则来限制被认为是潜在匹配的配对数量。此过程中,在各个数据集中新建一列,将重要非主属性的值合并在一起,可将该列称为混合列,使用混合列创建所需的候选集c。通过不同数据集的合并可减少候选集的数量。
最后从候选集c中进行随机采样,获得样本集s,并手动或根据主属性用机器标记抽样候选集,也即是指定候选对是否是正确的匹配。如果是正确的匹配标为1,否则标记为0。
步骤五:使用上一步抽样的数据集,用于训练分类器,针对将要预测目标进行各种机器学习算法的训练,并在机器学习算法:决策树、随机森林、支持向量积、逻辑回归、朴素贝叶斯进上行实验,通过实验结果进行对比分析,得到最佳的匹配器,在得到的最佳匹配器上,进行实体匹配实验,然后使用训练的模型加上相似度进行数据集的匹配,进而可以得到匹配对,并通过准确率、召回率和f1值来评估实验的效率。
一种基于非主属性离群点检测的实体匹配方法,基于非主属性的离群点检测的实体匹配方法体现在两个方面,一方面利用非主属性值消除主属性值多样性带来的歧义,另一方面根据离群点模型快速的筛选数据,抽取匹配对;具体表现为:先根据不同源的公共非主属性集,根据不同非主属性的特性采用相应的规则对数据进行粗筛选,降低记录对的数据规模,在此基础上利用离群点模型中的五个步骤做进一步的筛选,得到初步的实体对集,然后根据生成的实体对集进行数据集的采样,最后利用机器学习选择合适的匹配器并训练;
上述五个步骤具体为:
步骤一:对采集的实体数据进行数据预处理;具体为:对数据进行抽取及数据归档和清洗,根据实验的目标,找出不同源数据的共同非主属性,采用增量抽取的方式,并将抽取的数据存到另外的表格;并用正则表达式或自然语言处理技术,去除有明显错误或无意义的字段信息,利用归档计算并统计数据的一些基本信息,从而达到统一的数据组织方式,将实体中杂乱的信息统一为相同的数据结构。
步骤二:收集数据预处理结果,对数据集依据非主属性重叠度和非主属性相似性进行分块;通过分块策略将数据切分为多块,属于不同块的实体将不生成记录对;
步骤三:
a、对每一个记录对的不同非主属性进行相似度计算;
b、将求出的属性相似度序列所形成的矢量;依次添加到特征矩阵m中;
c、根据求得特征矩阵m,利用奇异值分解(svd),
m=usvt
其中u和v分别为n×n,m×m的酉矩阵,s为n×m对角矩阵;
提取矩阵v的前p个列向量,构成矩阵vm×p;在此基础上,并采用均值法计算每一维的中心值n=[u(sim(build)),…,u(sim(lat-log))],u(sim(build))代表build相似度中所在列的均值利用欧式距离
其中,xi∈m,yi∈n,求出每个序列的离群距离;
d、根据求得的离群距离,设定相应的阈值θ,由步骤c中矩阵s的迹乘以一个(0,1)范围内的值来确定,大于该阈值θ的保留下来,小于该阈值θ的舍去,并保存下来;
步骤四:根据离群检测模型筛选后的匹配对,使用启发式规则来限制被认为是潜在匹配的配对数量,此过程中,在各个数据集中新建一列,将步骤三中筛选出的非主属性的值合并在一起,将该列称为混合列,使用混合列创建所需的候选集c;通过不同数据集的合并可减少候选集的数量;
从候选集c中进行随机采样,获得样本集t,并根据主属性用机器标记抽样候选集,即指定候选对是否是正确的匹配,如果是正确的匹配标为1,否则标记为0;
步骤五:使用上一步抽样的候选集,用于训练分类器,针对将要预测目标进行各种机器学习算法的训练,并在机器学习算法进上行实验,所述机器学习算法包括:决策树、随机森林、支持向量积、逻辑回归、朴素贝叶斯,通过实验结果进行对比分析,得到准确率、召回率和准确率和召回率的调和均值最高的匹配器,在得到的最佳匹配器上,进行实体匹配实验,然后使用训练的模型加上相似度进行数据集的匹配,进而得到匹配对,并通过准确率、召回率和准确率和召回率的调和均值(f1值)来评估实验的效率。
一种实现上述基于非主属性离群点检测的实体匹配方法的计算机程序。
一种实现上述基于非主属性离群点检测的实体匹配方法的信息数据处理终端。
一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述基于非主属性离群点检测的实体匹配方法。
一种实现上述基于非主属性离群点检测的实体匹配方法的计算机程序。
本发明的目的三是提供一种实现上述基于非主属性离群点检测的实体匹配方法的信息数据处理终端。
本发明的目的四是提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述基于非主属性离群点检测的实体匹配方法
下面结合具体的实验数据对本发明的效果进行具体的阐述:
实验数据集
某酒店数据集(hotel)。该数据集为网络爬取数据,分别从携程旅游网(ctrip)和同程网采集了酒店信息,ctrip数据表中有4042个元组,30个属性,同程网数据表中含有4981个元组,22个属性,这两个数据表中共有的实例个数为2642,共有的属性个数为20个,其中共有的属性如name,star,build,renovat,tel,address等。并分别在实体对为1000,3000,5421,8621,15000个样本上进行了实验(其中训练集占80%)。
为验证方法的有效性,采用准确率precision:所有的实体记录中正确匹配的实体所占的比重;召回率recall:所有应匹配的实体记录中正确匹配的实体所占的比重;f1-score:同时考虑准确率和召回率的效果,即:
实验结果与分析
非主属性个数对实体对影响
非主属性的个数会影响算法的离群点检测模型的匹配效率与效果,这是由于非主属性个数过多会影响算法的效率,个数过少时会降低算法的匹配效果。为了找到合适的公共非主属性,选取合适的非主属性及个数是该实验的必要条件。如图2所示,展示了非主属性个数对实体对的影响:
从图2可以看出,非主属性的个数对实体对的影响巨大,当非主属性的个数为3时,实体对数目从16488万已经降低到2.7万多,个数为4时,实体数目已经变化不大,说明很接近真实匹配对了,但为了防止筛选过程出现把匹配对也筛去,故选择3个非主属性。此刻,已经很大程度上提高了实验的效率。该过程中先对非主属性的重要度根据杨强,李直旭等提出的基于非主属性值的实体匹配进行排序,在此基础上来验证非主属性对实体对的影响。
监督学习分类器性能对比
根据酒店数据集,尝试了五种监督学习的分类器模型,在该五种分类器上,进行了实体匹配实验,下图为五种匹配器在实体对为5421个上的实验结果,如图3所示。
从图3可看出,五种模型中,rf(随机森林)对实体匹配的效果最好。实体对的识别率达到88.8%,召回率为82.15%且其f1值为85.34%。同样地,rong等学者也在amachinelearningapproachforinstancematchingbasedonsimilaritymetrics证明,随机森林模型的效果优于线性模型lr和dt;
svm仅局限于小集群样本,对于观测样本太多时,效率较低。且需要寻求合适的核函数相对困难,故效果相对不太好。而nb的前提是特征条件独立,而在实体匹配中,不同的非主属性之间是有一定的联系的,故其效果不是很好。因此,本文选择随机森林模型作为实体匹配的分类器。
针对上述的rf方法,对匹配对的数量为1000,3000,5421,8621,15000,其运行时间开销如图4所示:从4可以看出,rf的运行效率随着样本的个数增加是不断增长的。
最后根据离群点检测模型中的离群距离,作进一步的筛选,再一次降低数据的规模,最后使用rf进行实体匹配和实验评估验证。
实验对比
实验一,采用樊峰峰,李战怀提出的一种基于离群点检测的自动实体匹配方法中的baseline:基于difscore的实体匹配算法,使用非主属性区分某一实体不同于其他实体的能力来进行实体匹配。
实验二,采用基于规则的方法,再结合机器学习进行实体匹配,先根据相应的规则计算记录对中不同非主属性的相似度,用相应的阈值筛选数据,然后针对筛选后的数据进行采样,最后采用随机森林分类器进行实体匹配。
实验三,采用本文提出的基于非主属性的离群点检测的实体匹配方法,先进行规则的粗筛选,在此基础上计算记录
三种实验方法的效果如表1.
表1不同模型下的实验对比
从表1可以看出,对于互联网上的酒店数据,基于非主属性的离群点检测的实体匹配方法相实验二在准确率提升了2.7%,召回率提升了3.4%,比实验一在准确率提升了19.6%,召回率提升了56.5%,由此可见,本文提出的方法,在准确率和召回率上都有明显的优势。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!