一种多元离散的特征选择方法、装置、设备及存储介质与流程
本发明属于机器学习技术领域,尤其涉及一种多元离散的特征选择方法、装置、设备及存储介质。
背景技术:
随着大数据时代的来临,数据的重要性日益凸显,海量的数据推动着信息社会的发展,然而数据维度的不断增长,“维度灾难”将无法避免。近年来,机器学习被应用于各种大数据场景之中,例如,dna微阵列分析、图像分类、文本分类等,由于这些数据具有较高的数据维度,同时数据中存在一些不相关的数据特征和冗余特征,直接使用原始的数据将会影响学习算法的效率和性能,因此,在机器学习过程中,需要对原始数据进行特征选择、数据离散等一系列预处理操作,以减少数据特征数量,使得学习算法可以生成一个较好的数据模型,从而提高算法的执行效率和算法的拟合精度。
特征选择也叫特征子集选择(featuresubsetselection,简称fss),例如一个数据存在n个特征,那么该数据就具有(2n-1)个特征子集可供选择。特征选择是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。特征选择的任务实际是一个组合优化问题,特征选择过程中,由于特征数目繁多,搜索空间较大,所以需要搜索算法去获得最优的选择方案,存在的搜索方法有序列前向选择(sfs)和序列后向选择(sbs),然而这些算法不仅需要很大的计算代价,同时容易陷入局部最优,因此需要具有全局搜索能力的启发式搜索算法应用到特征选择中。
粒子群算法(particleswarmoptimization,简称pso)是近年来由j.kennedy和r.ceberhart提出的一种新的进化算法(evolutionaryalgorithm,简称ea),其凭借算法简单、快速等优势已广泛应用于特征选择中,粒子群算法将问题的每个可能解当作一个粒子,然后通过一个适应度函数fiteness评价粒子的好坏,它通过记录每个粒子所经过的最佳位置(pbest)和种群经过的最佳位置(gbest)来进行引导粒子更新。
常见的使用pso来进行特征选择的算法有连续pso(continuouspso)和二进制pso(binarypso),这些算法证明了类似pso的启发式搜索算法可以在特征选择上取得较好的效果。然而这些算法在处理数据维度非常高的数据集(例如医学基因数据)时,仍无法取得比较好的效果。因此,j.kennedy提出了一种基于pso算法的改进算法----骨干粒子群优化算法(bare-boneparticleswarmoptimization,简称bbpso),相比于pso算法,它拥有更简单的更新机制和更快的收敛速度,binhtran等人提出了基于bbpso的特征选择算法----进化粒子群算法(evolveparticleswarmoptimization,简称epso)和对epso算法改进的潜在粒子群优化(potentialparticleswarmoptimization,简称ppso)算法,相比较传统的特征选择算法,这两个算法能快速的去除掉那些冗余特征和不相关特征,特别是在高特征维度的数据集中,具有非常好的效果。
ppso相较于epso改进了粒子的初始化方案,ppso采用fayyad和irani提出的最小描述长度(minimaldescriptionlength,简称mdl)算法来计算符合最小描述长度准则(minimumdescriptionlengthprinciple,简称mdlp)的分割点,以此来离散特征数据,由于mdl是通过信息增益的方式来进行切点的选择,所以训练集所包含的不同信息将会对该算法造成比较大的影响,且ppso算法是一个二元离散的特征选择算法,其使用将特征离散为多元的分割点来进行二元离散,在处理高维度数据时,可能会导致部分特征的信息丢失,且无法有效的去除存在相关性的相关特征和关联特征,从而影响结果的准确性。
技术实现要素:
本发明的目的在于提供一种多元离散的特征选择方法、装置、设备及存储介质,旨在解决由于现有技术无法提供一种有效的特征选择方法,导致无关特征与冗余特征的消除效果差,分类结果不准确的问题。
一方面,本发明提供了一种多元离散的特征选择方法,所述方法包括下述步骤:
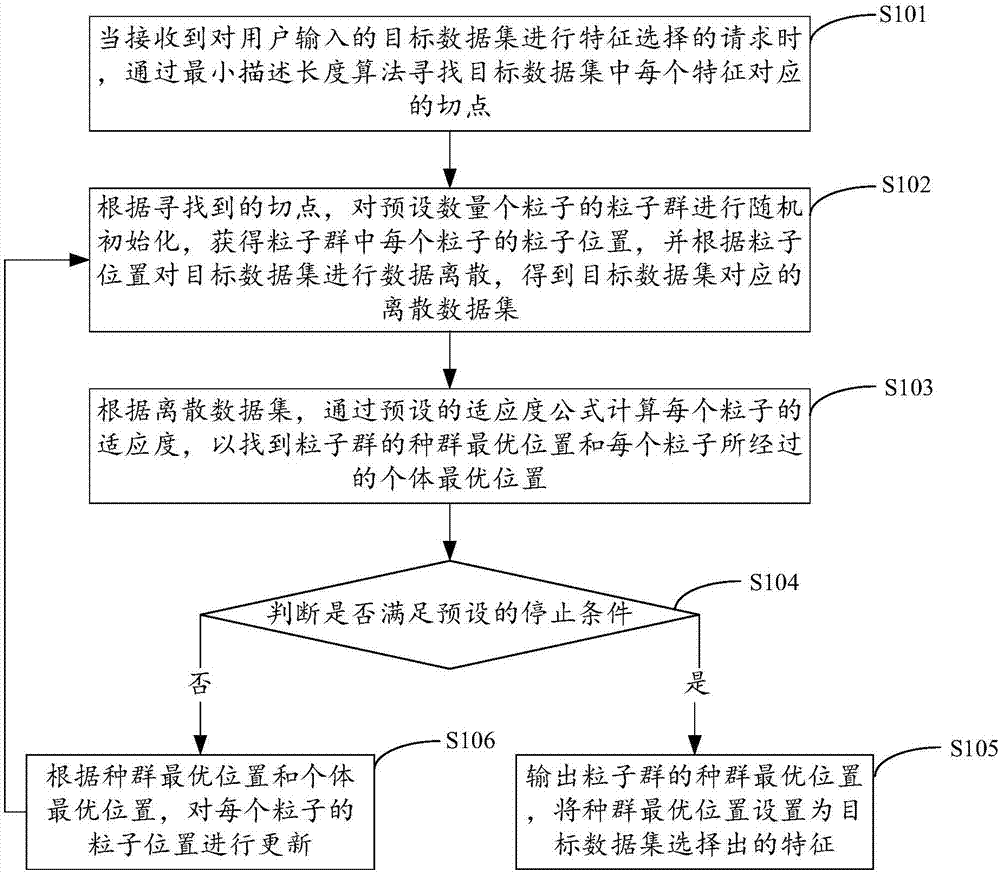
当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找所述目标数据集中每个特征对应的切点;
根据寻找到的所述切点,对预设数量个粒子的粒子群进行随机初始化,获得所述粒子群中每个粒子的粒子位置,并根据所述粒子位置对所述目标数据集进行数据离散,得到所述目标数据集对应的离散数据集;
根据所述离散数据集,通过预设的适应度公式计算所述每个粒子的适应度,以找到所述粒子群的种群最优位置和所述每个粒子所经过的个体最优位置;
判断是否满足预设的停止条件,是则,输出所述粒子群的种群最优位置,将所述种群最优位置设置为所述目标数据集选择出的特征,否则,根据所述种群最优位置和所述个体最优位置,对所述每个粒子的粒子位置进行更新,并跳转至根据所述粒子位置对所述数据集进行数据离散的步骤。
另一方面,本发明提供了一种多元离散的特征选择装置,所述装置包括:
切点寻找单元,用于当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找所述目标数据集中每个特征对应的切点;
初始化及离散单元,用于根据寻找到的所述切点,对预设数量个粒子的粒子群进行随机初始化,获得所述粒子群中每个粒子的粒子位置,并根据所述粒子位置对所述目标数据集进行数据离散,得到所述目标数据集对应的离散数据集;
适应度计算单元,用于根据所述离散数据集,通过预设的适应度公式计算所述每个粒子的适应度,以找到所述粒子群的种群最优位置和所述每个粒子所经过的个体最优位置;以及
停止条件判断单元,用于判断是否满足预设的停止条件,是则,输出所述粒子群的种群最优位置,将所述种群最优位置设置为所述目标数据集选择出的特征,否则,根据所述种群最优位置和所述个体最优位置,对所述每个粒子的粒子位置进行更新,并触发数据离散单元执行根据所述粒子位置对所述数据集进行数据离散的步骤。
另一方面,本发明还提供了一种计算设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述多元离散的特征选择方法所述的步骤。
另一方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述多元离散的特征选择方法所述的步骤。
本发明通过最小描述长度算法寻找用户输入的目标数据集中每个特征对应的切点,根据寻找到的切点对粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,根据离散数据集,通过适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,判断是否满足预设的停止条件,是则,输出种群最优位置,并将种群最优位置设置为目标数据集选择出的特征,否则,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,继续执行数据离散和寻优的操作,从而实现选择更少的特征,提高冗余特征与无关特征的消除效果,进而提高分类学习算法的正确率。
附图说明
图1是本发明实施例一提供的多元离散的特征选择方法的实现流程图;
图2是本发明实施例一提供的多元离散的特征选择方法中的粒子位置示例图;
图3是本发明实施例二提供的多元离散的特征选择装置的结构示意图;以及
图4是本发明实施例三提供的计算设备的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的多元离散的特征选择方法的实现流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤s101中,当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找目标数据集中每个特征对应的切点。
本发明实施例适用于计算设备,例如,个人计算机、服务器等。当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找目标数据集中每个特征对应的切点,目标数据集由高维数据组成,例如基因数据。一个切点是目标数据集中每个特征对应的特征值范围内的任一特征值,切点用来根据特征值范围将目标数据分割为若干个间隔。
在通过最小描述长度算法寻找目标数据集中每个特征对应的切点时,优选地,根据以下步骤寻找目标数据集中每个特征对应的切点:
(1)通过最小描述长度(mdl)算法在特征值范围内递归地选择最佳的切点,并通过预设的信息增益公式
(2)当切点的信息增益满足mdlp停止准则时,则停止寻找切点,具体地,切点的信息增益要满足预设的公式
通过mdl递归地选择最佳的切点,将一个间隔分割为两个,并利用信息增益来对切点进行评价,以确定切点,直到实现mdlp,从而提高后续分类学习算法的特征分类正确率。
在通过最小描述长度算法寻找所述目标数据集中每个特征对应的切点之前,优选地,根据目标数据集中目标数据对应特征的特征值,对目标数据进行排序,以获得排序后的目标数据集,从而提高最小描述长度算法的运行效率。
在步骤s102中,根据寻找到的切点,对预设数量个粒子的粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,并根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集。
在本发明实施例中,根据寻找到的切点,对预设数量个粒子的粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,并根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,其中,粒子的维度和目标数据集的特征总数相同,粒子的每个维度代表一个特征(例如,目标数据集中的数据包含5个特征,则每个粒子的维度为5),粒子每个维度的值代表该维度特征是否被选择(例如,0代表该维度对应的特征不被选择,大于0代表该维度对应的特征被选择)。在本发明实施例中,粒子位置不再代表选择某个切点对目标数据进行二元离散,而是代表同时选择多少个切点来对目标数据进行多元离散化,以便于提升分类学习算法的准确率。
作为示例地,图2示出了粒子位置示例图,图2中的切点表是由步骤s101通过mdl算法生成的,#c代表一个特征存在切点的总个数,c1代表一个切点对应的下标位置,例如,特征f1寻找到的切点个数为0,其对应的#c为0,特征f2寻找到的切点个数为2,其对应的#c为2,且对应的切点为c1和c2。根据切点表中的#c数量,对粒子群进行随机初始化,例如,一粒子的f3维度特征的初始化则根据切点表中f3特征对应的#c数量4,从[04]中随机选择一个数字作为该维度特征的粒子位置,图2示出的粒子位置中特征f3的粒子位置为3,表示选择切点表中特征f3的c1、c2以及c3这三个切点来对目标数据进行离散,这样将传统的二元离散变化为多元离散。
在步骤s103中,根据离散数据集,通过预设的适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置。
在本发明实施例中,根据离散数据集,通过预设的适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,粒子群的种群最优位置gbest即种群中适应度最高的粒子,个体最优位置pbest即每个粒子所经历的位置中适应度最高的值。
在通过预设的适应度公式计算每个粒子的适应度时,优选地,该适应度公式为fitness=μ×balanced_accuracy+(1-μ)distance-β×selection_proportion,从而通过在适应度公式中加入特征选择的比例selection_proportion作为评判标准,实现在函数收敛的时候找到那些效果好但具有更少特征的粒子,其中,balanced_accuracy为平衡分类精度,μ为预设的、平衡分类精度balanced_accuracy的权重系数,distance为所述离散数据集中离散数据间的距离,selection_proportion为特征选择的比例,通过公式
在步骤s104中,判断是否满足预设的停止条件。
在步骤s105中,输出粒子群的种群最优位置,将该种群最优位置设置为目标数据集选择出的特征。
在步骤s106中,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新。
在本发明实施例中,判断是否满足预设的停止条件,是则,执行步骤s105输出粒子群的种群最优位置,将该种群最优位置设置为目标数据集选择出的特征,否则,执行步骤s106根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,并跳转至步骤s102执行根据粒子位置对数据集进行数据离散。
在输出所述粒子群的种群最优位置之前,优选地,当满足预设的停止条件,且种群最优位置达到预设的缩放条件时,增加粒子群的粒子数,并跳转至步骤s102执行对预设数量个粒子的粒子群进行随机初始化,具体地,当种群的适应度没有更新,且当前适应度值比上一个值要高出1%时,就将种群个数增加50个,再重新进行粒子初始化迭代,从而提高遍历的可能解的数量。
在判断是否满足预设的停止条件时,优选地,判断迭代次数是否达到预设的最大迭代次数,从而提高算法的运行效率。
在判断迭代次数是否达到预设的最大迭代次数之前,优选地,将最大迭代次数设置为15,从而能够遍历更多的可能解,提高了分类学习算法的正确率。
在对每个粒子的粒子位置进行更新时,优选地,根据粒子更新过程中的变异概率确定更新后的粒子位置,具体地,一个粒子的每个维度在每次更新过程中都有2%的变异概率将该维度粒子位置突变为0,即不选择该特征,同时有8%的变异概率保持原有位置不变,余下90%的变异概率使用公式
在本发明实施例中,通过最小描述长度算法寻找用户输入的目标数据集中每个特征对应的切点,根据寻找到的切点对粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,根据离散数据集,通过适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,判断是否满足预设的停止条件,是则,输出种群最优位置,并将种群最优位置设置为目标数据集选择出的特征,否则,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,继续执行数据离散和寻优的操作,从而实现选择更少的特征,提高冗余特征与无关特征的消除效果,进而提高分类学习算法的正确率。
实施例二:
图3示出了本发明实施例二提供的多元离散的特征选择装置的结构,为了便于说明,仅示出了与本发明实施例相关的部分,其中包括:
切点寻找单元31,用于当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找目标数据集中每个特征对应的切点。
本发明实施例适用于计算设备,例如,个人计算机、服务器等。当接收到对用户输入的目标数据集进行特征选择的请求时,通过最小描述长度算法寻找目标数据集中每个特征对应的切点,目标数据集由高维数据组成,例如基因数据。一个切点是目标数据集中每个特征对应的特征值范围内的任一特征值,切点用来根据特征值范围将目标数据分割为若干个间隔。
在通过最小描述长度算法寻找目标数据集中每个特征对应的切点时,优选地,根据以下步骤寻找目标数据集中每个特征对应的切点:
(1)通过最小描述长度(mdl)算法在特征值范围内递归地选择最佳的切点,并通过预设的信息增益公式
(2)当切点的信息增益满足mdlp停止准则时,则停止寻找切点,具体地,切点的信息增益要满足预设的公式
通过mdl递归地选择最佳的切点,将一个间隔分割为两个,并利用信息增益来对切点进行评价,以确定切点,直到实现mdlp,从而提高后续分类学习算法的特征分类正确率。
在通过最小描述长度算法寻找所述目标数据集中每个特征对应的切点之前,优选地,根据目标数据集中目标数据对应特征的特征值,对目标数据进行排序,以获得排序后的目标数据集,从而提高最小描述长度算法的运行效率。
初始化及离散单元32,用于根据寻找到的切点,对预设数量个粒子的粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,并根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集。
在本发明实施例中,根据寻找到的切点,对预设数量个粒子的粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,并根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,其中,粒子的维度和目标数据集的特征总数相同,粒子的每个维度代表一个特征(例如,目标数据集中的数据包含5个特征,则每个粒子的维度为5),粒子每个维度的值代表该维度特征是否被选择(例如,0代表该维度对应的特征不被选择,大于0代表该维度对应的特征被选择)。在本发明实施例中,粒子位置不再代表选择某个切点对目标数据进行二元离散,而是代表同时选择多少个切点来对目标数据进行多元离散化,以便于提升分类学习算法的准确率。
适应度计算单元33,用于根据离散数据集,通过预设的适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置。
在本发明实施例中,根据离散数据集,通过预设的适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,粒子群的种群最优位置gbest即种群中适应度最高的粒子,个体最优位置pbest即每个粒子所经历的位置中适应度最高的值。
在通过预设的适应度公式计算每个粒子的适应度时,优选地,该适应度公式为fitness=μ×balanced_accuracy+(1-μ)distance-β×selection_proportion,从而通过在适应度公式中加入特征选择的比例selection_proportion作为评判标准,实现在函数收敛的时候找到那些效果好但具有更少特征的粒子,其中,balanced_accuracy为平衡分类精度,μ为预设的、平衡分类精度balanced_accuracy的权重系数,distance为所述离散数据集中离散数据间的距离,selection_proportion为特征选择的比例,通过公式
停止条件判断单元34,用于判断是否满足预设的停止条件,是则,输出粒子群的种群最优位置,将该种群最优位置设置为目标数据集选择出的特征,否则,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,并触发初始化及离散单元32执行根据粒子位置对数据集进行数据离散的步骤。
在本发明实施例中,在输出所述粒子群的种群最优位置之前,优选地,当满足预设的停止条件,且种群最优位置达到预设的缩放条件时,增加粒子群的粒子数,并触发初始化及离散单元32执行对预设数量个粒子的粒子群进行随机初始化,具体地,当种群的适应度没有更新,且当前适应度值比上一个值要高出1%时,就将种群个数增加50个,再重新进行粒子初始化迭代,从而提高遍历的可能解的数量。
在判断是否满足预设的停止条件时,优选地,判断迭代次数是否达到预设的最大迭代次数,从而提高算法的运行效率。
在判断迭代次数是否达到预设的最大迭代次数之前,优选地,将最大迭代次数设置为15,从而能够遍历更多的可能解,提高了分类学习算法的正确率。
在对每个粒子的粒子位置进行更新时,优选地,根据粒子更新过程中的变异概率确定更新后的粒子位置,具体地,一个粒子的每个维度在每次更新过程中都有2%的变异概率将该维度粒子位置突变为0,即不选择该特征,同时有8%的变异概率保持原有位置不变,余下90%的变异概率使用公式
因此,优选地,本发明实施例的多元离散的特征选择装置还包括:
数据排序单元,用于根据目标数据集中目标数据对应特征的特征值,对目标数据进行排序,以获得排序后的目标数据集;以及
粒子数增加单元,用于当种群最优位置达到预设的缩放条件时,增加粒子群的粒子数,并触发初始化及离散单元32执行对预设数量个粒子的粒子群进行随机初始化。
在本发明实施例中,多元离散的特征选择装置的各单元可由相应的硬件或软件单元实现,各单元可以为独立的软、硬件单元,也可以集成为一个软、硬件单元,在此不用以限制本发明。
实施例三:
图4示出了本发明实施例三提供的计算设备的结构,为了便于说明,仅示出了与本发明实施例相关的部分。
本发明实施例的计算设备4包括处理器40、存储器41以及存储在存储器41中并可在处理器40上运行的计算机程序42。该处理器40执行计算机程序42时实现上述多元离散的特征选择方法实施例中的步骤,例如图1所示的步骤s101至s106。或者,处理器40执行计算机程序42时实现上述各装置实施例中各单元的功能,例如图3所示单元31至34的功能。
在本发明实施例中,通过最小描述长度算法寻找用户输入的目标数据集中每个特征对应的切点,根据寻找到的切点对粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,根据离散数据集,通过适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,判断是否满足预设的停止条件,是则,输出种群最优位置,并将种群最优位置设置为目标数据集选择出的特征,否则,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,继续执行数据离散和寻优的操作,从而实现选择更少的特征,提高冗余特征与无关特征的消除效果,进而提高分类学习算法的正确率。
本发明实施例的计算设备可以为个人计算机、服务器。该计算设备4中处理器40执行计算机程序42时实现多元离散的特征选择方法时实现的步骤可参考前述方法实施例的描述,在此不再赘述。
实施例四:
在本发明实施例中,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述多元离散的特征选择方法实施例中的步骤,例如,图1所示的步骤s101至s106。或者,该计算机程序被处理器执行时实现上述各装置实施例中各单元的功能,例如图3所示单元31至34的功能。
在本发明实施例中,通过最小描述长度算法寻找用户输入的目标数据集中每个特征对应的切点,根据寻找到的切点对粒子群进行随机初始化,获得粒子群中每个粒子的粒子位置,根据粒子位置对目标数据集进行数据离散,得到目标数据集对应的离散数据集,根据离散数据集,通过适应度公式计算每个粒子的适应度,以找到粒子群的种群最优位置和每个粒子所经过的个体最优位置,判断是否满足预设的停止条件,是则,输出种群最优位置,并将种群最优位置设置为目标数据集选择出的特征,否则,根据种群最优位置和个体最优位置,对每个粒子的粒子位置进行更新,继续执行数据离散和寻优的操作,从而实现选择更少的特征,提高冗余特征与无关特征的消除效果,进而提高分类学习算法的正确率。
本发明实施例的计算机可读存储介质可以包括能够携带计算机程序代码的任何实体或装置、记录介质,例如,rom/ram、磁盘、光盘、闪存等存储器。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!