基于机器视觉和深度学习的目标检测方法与流程
本发明具体涉及一种基于机器视觉和深度学习的目标检测方法。
背景技术:
随着智能化时代的到来,智能机器人技术的发展已经越来越快。在智能机器人技术领域中,机器视觉则是一个关键所在。
目标检测是计算机视觉领域一个关键问题,同时更是安防机器人的研究重点之一。目前为止,机器人安防工作过程中需要判定环境是否异常,而这一判定过程需要计算机视觉完成。比如,机器人在小区进行安全防卫工作的时候,需要判定井盖是否存在或移位,需要判定消防器材是否缺失或移位,需要判定消防通道是否堵塞,以及需要判定小区内是否有异常行人出没等;这些静态的已经存在的事物,或者动态开始没有存在的事物等,都需要视觉传感器来解决。
一般情况下,基于传统的目标检测包含以下几个步骤:目标分割,目标检测,目标识别及目标跟踪。目标分割是根据像素对前景和背景进行分类,将背景剔除,留出前景。目标检测就是定位目标,确定目标位置及大小。目标识别就是将目标进行定性分析,确定目标属于哪一类。目标跟踪是指追踪目标运动轨迹。
在上述的目标检测的整个过程中,由于需要考虑物体的旋转、放大和缩小时的物体检测问题,所以目前的传统的目标检测方法,其在检测过程上耗时较长,从而严重影响了智能机器人的反应速度。
技术实现要素:
本发明的目的在于提供一种能够快速对目标进行检测,检测耗时较短的基于机器视觉和深度学习的目标检测方法。
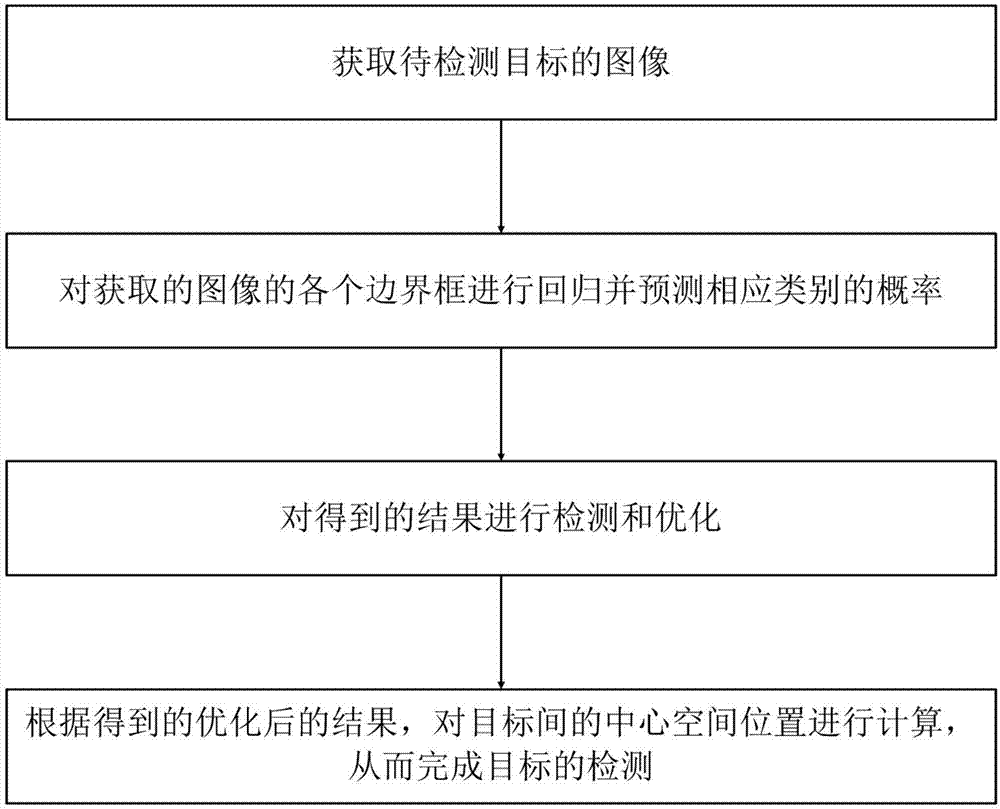
本发明提供的这种基于机器视觉和深度学习的目标检测方法,包括如下步骤:
s1.获取待检测目标的图像;
s2.对步骤s1获取的图像的各个边界框进行回归并预测相应类别的概率;
s3.对步骤s2得到的结果进行检测和优化;
s4.根据步骤s3得到的优化后的结果,对目标间的中心空间位置进行计算,从而完成目标的检测。
步骤s1所述的获取待检测目标的图像,具体为采用单目摄像头获取目标的实时图像,并将获取的实时图像调整为正方形大小。
步骤s2所述的对图像的各个边界框进行回归并预测相应类别的概率,具体为采用卷积神经网络进行回归并预测相应类别的概率。
所述的采用卷积神经网络进行回归并预测相应类别的概率,具体包括步骤:
a.将步骤s1得到的图片分为s×s个网格,每个网格至少检测b个边界框;
b.对步骤a得到的每个网格,采用如下公式进行置信度评分,并进行归一化:
式中z为置信度评分;pr(object)为0-1函数,且若该网格包括物体,则pr(object)取值为1,否则pr(object)取值为0;
c.采用如下算式构造损失函数:
式中λloss为损失函数,λnobj为修正指标系数,s为网格数,b为边界框个数,
步骤s3所述的对结果进行检测和优化,具体为采用如下步骤进行检测和优化:
a.采用如下算式计算每一个边界框的面积smj:
smj=(x2-x1+1)(y2-y1+1)
式中(x1,y1)为边界框最左上点的坐标,(x2,y2)为边界框最右下点的坐标;
b.对所有边界框的置信度进行排序,并获取置信度的最大值,并将置信度最大的边界框加入队列;
c.计算除最大置信度对应的边界框外剩余所有边界框的置信度与置信度最大值之间的值iou,所述iou为两个区域重叠的部分与两个区域的集合部分之间的比值;
d.根据步骤c计算得到的各个边界框的iou值,剔除iou值大于设定的iou阈值的边界框;
e.重复步骤a~d直至边界框为空,从而得到最终的边界框队列。
步骤s4所述的对目标间的中心空间位置进行计算,具体为采用如下步骤进行计算:
(1)获取检测物体理论所在位置的矩形框参数;
(2)获取检测物体实际的物理尺寸;
(3)采用如下公式计算图像中物体的矩形框的中心的世界坐标:
式中w为图像中矩形框的宽,w'为实际物体的矩形框的宽,fx为相机的内部参数,为x轴上的归一化焦距,fy为相机的内部参数,为y轴上的归一化焦距,cx为像素坐标系与成像平面相差的相对于原点的横坐标平移,cy为像素坐标系与成像平面相差的相对于原点的纵坐标平移,f为相机焦距,(u,v)为图像坐标,(x,y,h)为物体的矩形框的中心的世界坐标;
(4)若步骤(3)得到的物体的矩形框的中心的世界坐标与物体理论所在位置的矩形框的中心的世界坐标重合,则认定该物体在所在位置且物体完整。
本发明提供的这种基于机器视觉和深度学习的目标检测方法,采用对图片进行直接识别的方式对图片的特征进行提取,因此本发明方法能够快速的对目标物体进行检测和定位,而且本发明方法简单可靠。
附图说明
图1为本发明方法的方法流程图。
图2为本发明方法的根据物体实际尺寸计算h的相似关系示意图。
图3为本发明方法的针孔相机模型计算世界坐标系到图像坐标系的转换关系示意图。
具体实施方式
如图1所示为本发明方法的方法流程图:本发明提供的这种基于机器视觉和深度学习的目标检测方法,包括如下步骤:
s1.获取待检测目标的图像;具体为采用单目摄像头获取目标的实时图像,并将获取的实时图像调整为正方形大小;
s2.对步骤s1获取的图像的各个边界框,采用卷积神经网络进行回归并预测相应类别的概率;具体包括步骤:
a.将步骤s1得到的图片分为s×s个网格,每个网格至少检测b个边界框;
b.对步骤a得到的每个网格,采用如下公式进行置信度评分,并进行归一化:
式中z为置信度评分;pr(object)为0-1函数,且若该网格包括物体,则pr(object)取值为1,否则pr(object)取值为0;
c.采用如下算式构造损失函数:
式中λloss为损失函数,λnobj为修正指标系数,s为网格数,b为边界框个数,
s3.对步骤s2得到的结果进行检测和优化;具体为采用如下步骤进行检测和优化:
a.采用如下算式计算每一个边界框的面积smj:
smj=(x2-x1+1)(y2-y1+1)
式中(x1,y1)为边界框最左上点的坐标,(x2,y2)为边界框最右下点的坐标;
b.对所有边界框的置信度进行排序,并获取置信度的最大值,并将置信度最大的边界框加入队列;
c.计算除最大置信度对应的边界框外剩余所有边界框的置信度与置信度最大值之间的值iou,所述iou为两个区域重叠的部分与两个区域的集合部分之间的比值;
d.根据步骤c计算得到的各个边界框的iou值,剔除iou值大于设定的iou阈值的边界框;
e.重复步骤a~d直至边界框为空,从而得到最终的边界框队列;
s4.根据步骤s3得到的优化后的结果,对目标间的中心空间位置进行计算,从而完成目标的检测;具体为采用如下步骤进行计算:
(1)获取检测物体理论所在位置的矩形框参数;
(2)获取检测物体实际的物理尺寸;
(3)采用如下公式计算图像中物体的矩形框的中心的世界坐标:
式中w为图像中矩形框的宽,w'为实际物体的矩形框的宽,fx为相机的内部参数,为x轴上的归一化焦距,fy为相机的内部参数,为y轴上的归一化焦距,cx为像素坐标系与成像平面相差的相对于原点的横坐标平移,cy为像素坐标系与成像平面相差的相对于原点的纵坐标平移,f为相机焦距,(u,v)为图像坐标,(x,y,h)为物体的矩形框的中心的世界坐标;
(4)若步骤(3)得到的物体的矩形框的中心的世界坐标与物体理论所在位置的矩形框的中心的世界坐标重合,则认定该物体在所在位置且物体完整;
以下结合一个具体实施例对本发明方法进行进一步说明:
训练数据集,优化目标函数:输入一组数据集,包含井盖、消防器材和消防信道等的照片,并画框和对物体标签进行标注;设计网格成7*7的大小,将数据集放入卷积神经网络;非极大值抑制重复检测的矩形框,并最终定位一个最佳的矩形框;至此,得到一个最优的训练模型。
测试图片集:首先,是提取单目摄像头的图像,调整其分辨率适应网络的分辨率;其次,将测试的图片集放入该网络训练的模型,输出物体的大小和类别;然后根据图像坐标系到世界坐标系间的相似三角形关系,得到物体的世界坐标系;最后,计算物体间的中心坐标进行判断。其根据实际物体尺寸计算h的相似三角形关系如图2所示。
如图3所示为本发明方法的针孔相机模型计算世界坐标系到图像坐标系的转换关系示意图:图中,加粗的虚线为相似三角形,设p点的坐标为(x,y,z)t,p’的坐标为(x',y',z')t,则有
- 还没有人留言评论。精彩留言会获得点赞!