一种基于样本共识的近红外光谱建模方法与流程
本发明涉及化学计量学和光谱学领域领域,特别涉及一种基于样本共识的近红外光谱建模方法。
背景技术:
近红外光谱的波数范围为12500~4000cm-1,其光谱信息的来源于此区域有机物含氢官能团的倍频和合频吸收。随着近些年近红外光谱技术的快速发展,以及近红外光谱技术本身所具有快速、无损、安全、样品无需预处理和无需有毒有害化学试剂等优点,使得近红外光谱技术已经被广泛的应用于有机物定性和定量分析中。
虽然近红外光谱技术具有方便、简单、快速等特点,但在实际样本的近红外光谱信息采集过程中,会由于采集样本对象本身所具有的限制(例如样本稀少、样本的季节性、储藏性时间短等特性)或外界环境的限制(例如经济条件、实验时间、仪器的复杂性等条件限制),使得实际中采集到的样本数据较少,导致构建的定性和定量检测模型具有较低的准确性和稳定性。
技术实现要素:
本发明要解决的技术问题是提供在一定程度上解决模型样本数据较少的问题,并且提升模型的准确性和鲁棒性的基于样本共识的近红外光谱建模方法。
为解决上述技术问题,本发明是通过以下技术方案实现的:一种基于样本共识的近红外光谱建模方法,包括以下步骤:
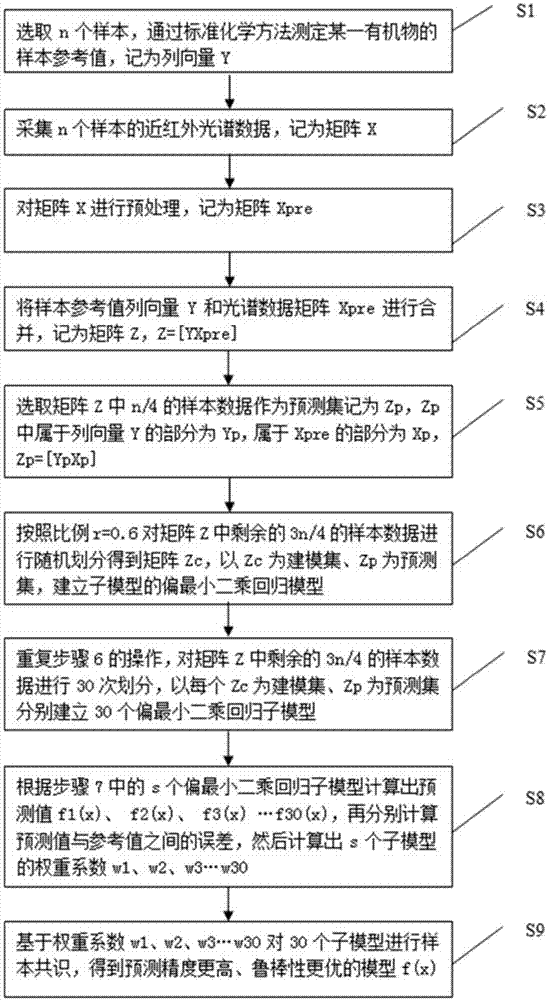
步骤1,选取n个样本,通过标准化学方法测定某一有机物的样本参考值,记为列向量y;
步骤2,采集n个样本的近红外光谱数据,记为矩阵x;
步骤3,对矩阵x选用一阶导数、二阶导数、矢量归一化、多元散射校正或平滑处理中的一种或多种方法进行预处理,记为矩阵xpre;
步骤4,将样本参考值列向量y和光谱数据矩阵xpre进行合并,记为样本数据矩阵z,z=[yxpre];
步骤5,采用蒙特卡洛取样法随机选取矩阵z中n/4的样本数据作为预测集记为zp,zp中属于列向量y的部分为yp,属于xpre的部分为xp,zp=[ypxp];
步骤6,按照比例r对矩阵z中剩余的3/4的样本数据进行随机划分得到矩阵zc,其中r∈[0.5,0.9],以zc为建模集、zp为预测集,建立子模型的偏最小二乘回归模型;
步骤7,重复步骤6的操作,对矩阵z中剩余的3n/4的样本数据进行s次随机划分,以每次得到的zc为建模集、固定的zp为预测集分别建立s个偏最小二乘回归子模型f1(x)、f2(x)、f3(x)…fk(x)…fs(x);
步骤8,根据步骤7中建立的s个偏最小二乘回归子模型对预测集样本进行预测,并分别计算每个子模型预测值与真实参考值之间的误差,然后计算出s个子模型的权重系数w1、w2、w3…wk…ws,其中wk为第k个子模型的权重系数,权重系数的计算公式为:
步骤9,基于权重系数w1、w2、w3…wk…ws对s个子模型进行样本共识,得到预测精度更高、鲁棒性更优的模型f(x),样本共识计算公式为:
进一步的:步骤6中r=0.6,步骤7中s=30。
本发明的有益效果是在当前样本数据较少的情况下,提出一种样本共识模型,此模型通过建立多个偏最小二乘子模型,并对这些子模型进行共识计算,相比于单个偏最小二乘回归模型,共识后模型f(x)的rmsep值更低,说明共识模型充分利用了采集到的样本信息,提升检测模型的精度,rmsec与rmsep之间的差值减少,说明共识模型提升了检测模型的鲁棒性。
附图说明
图1为本发明的实施流程图。
具体实施方式
为了使本发明的技术方案更加清楚明白,以下结合附图及实施例,对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参考图1,本发明提供一种基于样本共识的近红外光谱建模方法,下面以玉米样本为例解释本发明,包括以下步骤:
s1:选取80个玉米目标样本,测定玉米的淀粉含量作为样本参考值,记为列向量y。
s2:采集80个玉米样本的近红外光谱数据,记为矩阵x,光谱范围为1100-2498nm,间隔为2nm,共700个波段。
s3:对矩阵x进行一阶导数的savitzky–golay预处理,记为矩阵xpre。
s4:将样本参考值列向量y和光谱数据矩阵xpre进行合并,记为样本数据矩阵z,z=[yxpre]。
s5:采用蒙特卡洛取样法随机选取矩阵z中20个的样本数据作为预测集记为zp,zp中属于列向量y的部分为yp,属于xpre的部分为xp,zp=[ypxp]。
s6:对样本矩阵z中剩余的60个样本数据按照比例r=0.6随机划分得到矩阵zc,以zc为建模集、zp为预测集,建立偏最小二乘回归子模型。
s7:重复步骤6的操作,对矩阵z中剩余的60个样本数据进行30次划分,以每次得到的zc为建模集、zp为预测集分别建立30个偏最小二乘回归子模型f1(x)、f2(x)、f3(x)…fk(x)…fs(x)。
s8:根据步骤7中的30个偏最小二乘回归子模型对预测集样本进行预测,并分别计算每个子模型预测值与真实参考值之间的误差,然后计算出30个子模型的权重系数w1、w2、w3…w30,权重系数的计算公式为。
s9:基于权重系数w1、w2、w3…w30对30个子模型进行样本共识,得到预测精度更高、鲁棒性更优的模型f(x),样本共识计算公式为:
f(x)=∑kwkfk(x)。
以上实施例仅仅是对本发明的解释,其并不是对本发明的限制,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围,因此本发明专利的保护范围应以权利要求为准。
技术特征:
技术总结
本发明公开了一种基于样本共识的近红外光谱建模方法,包括以下步骤:选取n个样本,测定某一有机物样本参考值,记为列向量Y,采集n个样本的近红外光谱数据,记为矩阵X,对矩阵X进行预处理,记为矩阵Xpre,将样本参考值列向量Y和光谱数据矩阵Xpre进行合并,记为矩阵Z,选取矩阵Z中n/4的样本数据作为预测集记为Zp,按照比例r对矩阵Z中剩余的3n/4的样本数据进行s次随机划分得到矩阵Zc,以每个Zc为建模集、Zp为预测集分别建立s个偏最小二乘回归子模型,再采用样本共识算法计算出模型表达式。本发明的有益效果是在当前样本数据较少的情况下,提出一种样本共识模型,此模型可以充分利用采集到的样本信息,提升检测模型的精度。
技术研发人员:陈孝敬;李理敏;石文;袁雷明
受保护的技术使用者:温州大学
技术研发日:2018.07.31
技术公布日:2019.01.04
- 还没有人留言评论。精彩留言会获得点赞!