一种基于图划分的实体对齐优化方法与流程
本发明涉及了数据库领域中的一种实体处理方法,尤其是涉及了一种基于图划分的实体对齐优化方法。
涉及数据库领域中的倒排索引和局部敏感哈希方法、机器学习领域中的tf-idf模型和doc2vec模型、社交网络领域中的社区划分算法以及语义网络领域中的实体对齐方法。
背景技术:
目前互联网上涌现出了包含大量信息和知识的互联网资源,例如百度百科、互动百科等。这些不同的数据源之间天然存在着数据屏障,导致这些数据之间难以关联、互动。然而,如果仅用单个数据源描述现实世界中对象,会存在对象覆盖度低、信息描述不完全等问题。实体对齐就是研究如何挖掘出不同数据源中指向现实世界中同一对象的问题。
目前传统的实体对齐方法的研究存在三个问题:(1)仅两个数据源进行实体匹配时,如果直接遍历所有的实体对,计算复杂度与数据源规模的平方成正比,计算代价过高。(2)目前大部分实体对齐方法都集中在rdfs或owl等语义框架下进行对齐,以大量三元组的形式表示实体信息,语义表达和关系信息都较为丰富。而在互联网中普遍是以单个页面或者文档的形式表示实体数据,目前的实体对齐方法不具有通用性。(3)在面对多数据源的情况下,目前大部分实体对齐方法将其转化为多组两两数据源的实体对齐问题,而没有从多数据源全局的角度去进行分析计算。
技术实现要素:
为了解决背景技术中存在的问题,本发明的目的在于针对现有技术的不足,提供了一种基于图划分的实体对齐优化方法。
本发明解决其技术问题采用的技术方案如下:
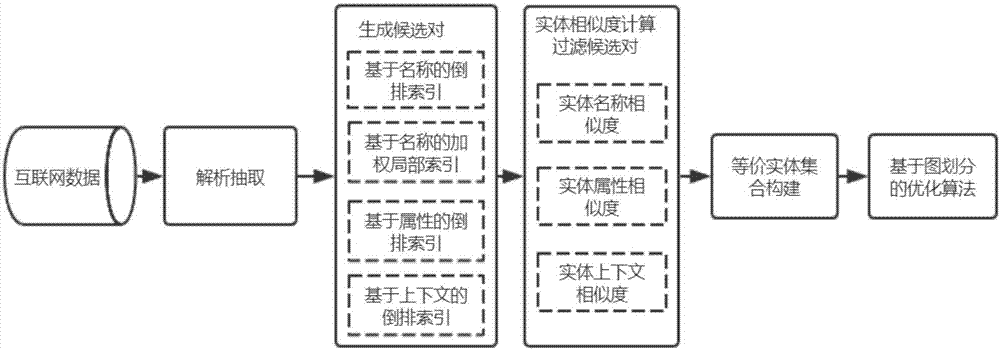
本发明利用组合索引从所有实体中挖掘候选实体对,通过实体的相似度度量方法判别候选实体对是否对齐获得等价实体对,再利用实体之间的相似度关系提出基于图划分的优化算法提升等价实体对对齐的准确性。
所述的实体是由来自互联网数据解析抽取转换后获得。
文档类型数据例如可以为网站的网页、词条、文档。
实体例如为网页记录、词条记录、文档记录。
所述的方法步骤如下:
1)对互联网数据进行解析抽取获得文档类型数据,将单个文档类型数据转换成实体,实体主要信息包括名称、唯一编码(id)、属性和上下文信息,并由所有实体的上下文信息构成上下文语料库;
从互联网数据解析抽取获得的文档类型数据均转换为数据结构统一的实体。
例如网页的属性为网页中的编辑者信息、发布时间信息,网页的上下文信息为文本信息。
2)利用倒排索引和局部敏感哈希索引组合索引方式挖掘候选实体对,再对不同索引挖掘出的候选实体对进行合并去重;
3)遍历步骤2)中得到的候选实体对集合,先分别计算实体相似度,若实体相似度大于相似度阈值,则认为是候选实体对进行保留,否则舍弃,等价实体即现实中指向同一对象的实体,保留得到的候选实体对作为等价实体对,从而完成候选实体对的对齐;
4)在多数据源的情况下,会有多个实体是等价实体,而通过步骤3中我们得到的仅为实体对。通过等价关系具有传递性,将相关联的等价实体对通过并查集转换为等价实体集合;
若两对等价实体对中存在相同的实体,则两对等价实体对相关联。
5)由于实体相似度的计算存在一定的误差,在等价实体集合中可能会存在被错误混淆进来的实体,计算等价实体集合中两两实体的上下文相似度作为实体间的边权重,构造等价实体关系图,利用实体间边权重,对实体关系图进行进一步划分获得最终实体集合。
所述步骤2)采用基于名称的倒排索引、基于属性的倒排索引、基于上下文的倒排索引、基于名称的局部敏感哈希索引的四种索引生成候选实体对,具体为:
2.a、基于名称的倒排索引以实体名称作为索引键、以实体id集合作为索引值进行构建,穷举实体id集合中以两两实体的唯一编码作为候选实体对;
2.b、基于属性的倒排索引通过遍历所有实体的属性p,属性p包括属性名与属性值,然后以属性名与属性值作为复合键、以索引值为实体id集合,建立以下形式的映射关系:(p.name,p.value)→{id1,id2,..,idn},将具有相同属性名且具有相同属性值的实体归为同一实体属性集合,其中p.name表示属性名,p.value表示属性值,id1,id2,..,idn分别表示实体的各个唯一编码;
采用以下公式计算实体属性集合中每个实体的属性累加权重weight(p.name,p.value),获得:
其中,|samevaluecount|表示具有相同属性名且具有相同属性值的实体数量;
再对基于属性的倒排索引中的索引值进行遍历统计,对于每一组实体id集合,穷举任意两两实体对,每个实体初始化属性权重设为零,将计算获得属性的权重累加到实体的原有属性权重上,遍历所有实体对,如果实体对权重大于预设的属性权重阈值,则作为候选实体对;
2.c、基于上下文的倒排索引以关键词t作为索引键、以实体id的集合为索引值,建立以下形式的索引结构:t→{id1,id2,..,idn},
遍历所有实体的唯一编码,穷举任意两两实体对,每个实体初始化关键词权重设为零,计算关键词累加权重累加到实体的原有关键词权重上,关键词累加权重为实体上下文信息中的词语在上下文语料库中的词频-逆文本频率指数(tfidf)值;遍历所有实体对,如果实体对累加后获得的关键词权重和大于预设的关键词权重阈值,则作为候选实体对;
2.d、如图2所示,基于名称的局部敏感哈希索引生成候选实体对的流程分为向量化、最小哈希和局部敏感哈希的三个过程,
首先,向量化的过程是将实体的名称转化为01向量的格式,获得各个实体的实体向量,由所有实体向量组成实体矩阵;例如借助n-gram模型,先将实体名称表示短字符串的集合。实体名称通过n-gram分解后得到的字符串全集如果表示成s,将实体名称映射成一个维度为|s|的01向量,向量中一维都对应s中的某个字符串,如果实体名称经n-gram分解后包含该字符串,则为该位标记为1,不存在则该位标记为0。
接着,最小哈希的过程是根据实体向量的维度生成随机数,随机数数量和实体向量的维度相同,根据随机数产生不同的最小哈希函数minhash对实体矩阵进行打乱重排,每次最小哈希函数minhash的返回值为实体矩阵中每个实体向量中第一个1所在的位置,利用最小化哈希的方法进行若干次将实体向量压缩成哈希签名矩阵,即将实体高维稀疏的01向量压缩成低维的哈希签名,也是将实体矩阵的大规模矩阵转换为哈希签名矩阵的小规模矩阵;
然后,局部敏感哈希的过程是对哈希签名矩阵进行局部敏感哈希处理获得候选实体对;
具体是将哈希签名矩阵按水平方向分割成b个区块brand,每个区块brand有r行,其中哈希签名矩阵每一列代表一个实体的特征签名,按列对同一区块brand中每个实体的特征签名进行哈希处理,获得的哈希值映射到若干个桶bucket中,不同的区块brand具有的若干个桶bucket不同;对每个区块brand均进行上述过程,共进行b次哈希过程;遍历所有的桶bucket,穷举桶bucket中任意两个实体组成候选实体对,形成候选实体对集合。
最后,将四种索引生成候选实体对组合取并集,获得最终候选实体对集合。
所述步骤3)中,实体对相似度是分别计算实体名称相似度、属性相似度和上下文相似度后,再对三种相似度进行加权计算得到。
所述的实体名称相似度、属性相似度和上下文相似度分别采用以下方式计算获得:
实体名称相似度计算:计算名称编辑距离相似度作为实体名称相似度:
sim_name(ea,eb)=lev_sim(namea,nameb)
其中,namea,nameb分别表示两个实体的实体名称,lev_sim(namea,nameb)表示编辑距离相似度函数,sim_name(namea,nameb)表示实体名称相似度函数,ea,eb分别表示两个实体;
实体属性相似度计算:先获取两个实体的共有属性集合,共有属性指两个实体共有的属性名称所对应的属性,再计算所有共有属性值的编辑距离相似度的算术平均值作为实体属性相似度:
其中,vai和vbi分别表示两个实体的属性值,i表示两个实体的共有属性的序数,s表示两个实体的共有属性的总数,lev_sim()表示编辑距离相似度函数;
实体上下文相似度计算:通过文档向量模型(doc2vec)对上下文语料库进行训练,用训练后的文档向量模型(doc2vec)将实体上下文转换为向量,再计算两个向量的余弦值作为实体上下文相似度:
其中,
所述步骤4)具体是构造并查集的数据结构,先将每个实体自身初始化为独立的集合,再遍历所有等价实体对,将存在相同实体的所有等价实体对合并成一个集合,对所有等价实体对处理获得了若干的等价实体集合。
所述步骤5)具体是将步骤4得到的每个等价实体集合转换为实体关系图,实体关系图中的节点为实体,节点之间的边用实体间的上下文相似度来表示,实体关系图中移除权重低于边权重阈值的边,每个等价实体集合中的各个实体采用社交网络模块度划分计算方法进行计算判断和划分处理,将等价实体集合划分为若干实体集合。
本发明先对互联网中的文档数据进行抽取,转换数据结构统一的实体,再利用倒排索引和局部敏感哈希索引等多种组合索引挖掘出候选实体对,同时设计了一种实体相似度度量方法用于判断实体对是否对齐。接下来将已对齐的实体对转换为等价实体集合,并提出了一种基于图划分的优化算法,将实体集合转为实体关系图,根据节点的疏密关系和图中权重大小,对实体集合进行进一步划分提高实体对齐的准确性。
等价实体指现实世界中指向同一客观对象的实体。
本发明具有的有益效果是:
本发明方法结合倒排索引和局部敏感哈希技术,缩小了实体匹配的计算空间并生成了高质量的候选集。
本发明综合了实体的名称、属性和上下文信息,定义了计算实体相似度度量方法,有效地判别了实体对是否对齐。
本发明最终划分为多实体构成的等价实体集合,进一步提高了实体对齐算法的准确性。
本发明方法能够应用于大规模互联网数据的实体对齐问题,在实体对齐效率较高的情况下,能更准确地完备地挖掘出原始数据中相互等价的实体集合。
附图说明
图1是本发明方法步骤流程图。
图2是本发明局部敏感哈希索引生成候选实体对的流程图。
具体实施方式
现结合具体实施和示意图对本发明的技术方案作进一步说明。
如图1,本发明的实施例及其具体实施过程如下:
步骤1:对原始来自互联网的网页等文档类型的数据进行解析抽取,利用现有的工具,如scrapy将其转换为数据结构统一的实体。把单个页面或者文档映射成一个实体,实体主要信息包括名称、唯一编码(id)、属性和上下文信息,并由所有实体的上下文信息构成上下文语料库。
实体匹配前的预处理过程。遍历实体的属性信息,统计不同属性的权重大小,遍历实体的上下文信息,对其上下文进行分词,并统计整个语料库的词频分布等信息。计算上下文中词语的tf-idf值作为词语的权重,并选取tf-idf值最高的词作为上下文的关键词作为保留。
步骤2:本步骤通过构建多种索引,进行来挖掘更多的等价实体对,具体构建基于名称、基于属性和基于上下文的倒排索引和基于名称的局部敏感哈希索引等四种索引生成候选实体对,具体为:
2.a、基于名称的倒排索引以实体名称作为索引键、以实体id集合作为索引值进行构建,穷举实体id集合中以两两实体的唯一编码作为候选实体对;
2.b、基于属性的倒排索引通过遍历所有实体的属性p,属性p包括属性名与属性值,然后以属性名与属性值作为复合键、以索引值为实体id集合,建立以下形式的映射关系:(p.name,p.value)→{id1,id2,..,idn},将具有相同属性名且具有相同属性值的实体归为同一实体属性集合,其中p.name表示属性名,p.value表示属性值,id1,id2,..,idn分别表示实体的各个唯一编码;
采用以下公式计算实体属性集合中每个实体的属性累加权重weight(p.name,p.value),获得:
其中,|samevaluecount|表示具有相同属性名且具有相同属性值的实体数量;
再对基于属性的倒排索引中的索引值进行遍历统计,对于每一组实体id集合,穷举任意两两实体对,每个实体初始化属性权重设为零,将计算获得属性累加权重累加到实体的原有属性权重上,遍历所有实体对,如果实体对累加后获得的属性权重和大于预设的属性权重阈值,则作为候选实体对;
2.c、基于上下文的倒排索引以关键词t作为索引键、以实体id的集合为索引值,建立以下形式的索引结构:t→{id1,id2,..,idn},
遍历所有实体的唯一编码,穷举任意两两实体对,每个实体初始化关键词权重设为零,计算关键词累加权重累加到实体的原有关键词权重上,关键词累加权重为实体上下文信息中的词语在上下文语料库中的词频-逆文本频率指数(tfidf)值;遍历所有实体对,如果实体对累加后获得的关键词权重和大于预设的关键词权重阈值,则作为候选实体对;
2.d、如图2所示,基于名称的局部敏感哈希索引生成候选实体对的流程分为向量化、最小哈希和局部敏感哈希的三个过程,
首先,向量化的过程是将实体的名称转化为01向量的格式,获得各个实体的实体向量,由所有实体向量组成实体矩阵;例如借助n-gram模型,先将实体名称表示短字符串的集合。实体名称通过n-gram分解后得到的字符串全集如果表示成s,将实体名称映射成一个维度为|s|的01向量,向量中一维都对应s中的某个字符串,如果实体名称经n-gram分解后包含该字符串,则为该位标记为1,不存在则该位标记为0。
接着,最小哈希的过程是根据实体向量的维度生成随机数,随机数数量和实体向量的维度相同,根据随机数产生不同的最小哈希函数minhash对实体矩阵进行打乱重排,每次最小哈希函数minhash的返回值为实体矩阵中每个实体向量中第一个1所在的位置,利用最小化哈希的方法进行若干次将实体向量压缩成哈希签名矩阵,即将实体高维稀疏的01向量压缩成低维的哈希签名,也是将实体矩阵的大规模矩阵转换为哈希签名矩阵的小规模矩阵;
然后,局部敏感哈希的过程是对哈希签名矩阵进行局部敏感哈希处理获得候选实体对;
具体是将哈希签名矩阵按水平方向分割成b个区块brand,每个区块brand有r行,其中哈希签名矩阵每一列代表一个实体的特征签名,按列对同一区块brand中每个实体的特征签名进行哈希处理,获得的哈希值映射到若干个桶bucket中,不同的区块brand具有的若干个桶bucket不同;对每个区块brand均进行上述过程,共进行b次哈希过程;遍历所有的桶bucket,穷举桶bucket中任意两个实体组成候选实体对,形成候选实体对集合。
最后,将四种索引生成候选实体对组合取并集,获得最终候选实体对集合。
步骤3:遍历步骤2得到的最终候选实体对集合,计算实体对相似度,如果相似度大于相似度阈值,则认为候选实体对为等价实体对;
所述的实体对相似度是分别计算实体名称相似度、属性相似度和上下文相似度后,再对三种相似度进行加权计算得到。
所述的实体名称相似度、属性相似度和上下文相似度分别采用以下方式计算获得:
实体名称相似度计算:计算名称编辑距离相似度作为实体名称相似度:
sim_name(ea,eb)=lev_sim(nameai,namebj)
其中,nameai,namebj分别表示两个实体的实体名称,lev_sim()表示编辑距离相似度函数,sim_name()表示实体名称相似度函数,ea,eb分别表示两个实体;
实体属性相似度计算:先获取两个实体的共有属性集合,共有属性指两个实体共有的属性名称所对应的属性,再计算所有共有属性值的编辑距离相似度的算术平均值作为实体属性相似度:
其中,vai和vbi分别表示两个实体的属性值,i表示两个实体的共有属性的序数,s表示两个实体的共有属性的总数,lev_sim()表示编辑距离相似度函数;
实体上下文相似度计算:通过文档向量模型(doc2vec)对上下文语料库进行训练,用训练后的文档向量模型(doc2vec)将实体上下文转换为向量,再计算两个向量的余弦值作为实体上下文相似度:
其中,
步骤4:经过步骤3的计算实体相似度的过程,得到了若干相似度较高的实体对作为等价实体对。由于等价关系存在传递性,在多源的情况下会存在n(n≧3)个实体e均是等价的,要将等价实体对转换为等价实体集合。构造并查集的数据结构,先将每个实体自身初始化为独立的集合,再遍历所有等价实体对,将存在相同实体的所有等价实体对合并成一个集合,对所有等价实体对处理获得了若干的等价实体集合。
步骤5:在步骤4中得到了等价实体集合,但由于实体相似度计算的过程存在一定的误差,可能存在被错误混淆的实体在集合中。该步骤通过基于图划分的优化算法对实体集合进行进一步的划分,划分出若干真正等价的集合。
将步骤4得到的每个等价实体集合转换为实体关系图,实体关系图中的节点为实体,节点之间的边用实体间的上下文相似度来表示,实体关系图中移除权重低于边权重阈值的边,每个等价实体集合中的各个实体采用社交网络模块度划分计算方法进行计算判断和划分处理,将等价实体集合划分为若干实体集合。
- 还没有人留言评论。精彩留言会获得点赞!