一种基于大数据分层聚类的棉花生产工艺优化方法与流程
本发明涉及工艺优化算法
技术领域:
,具体涉及一种基于大数据分层聚类的棉花生产工艺优化方法。
背景技术:
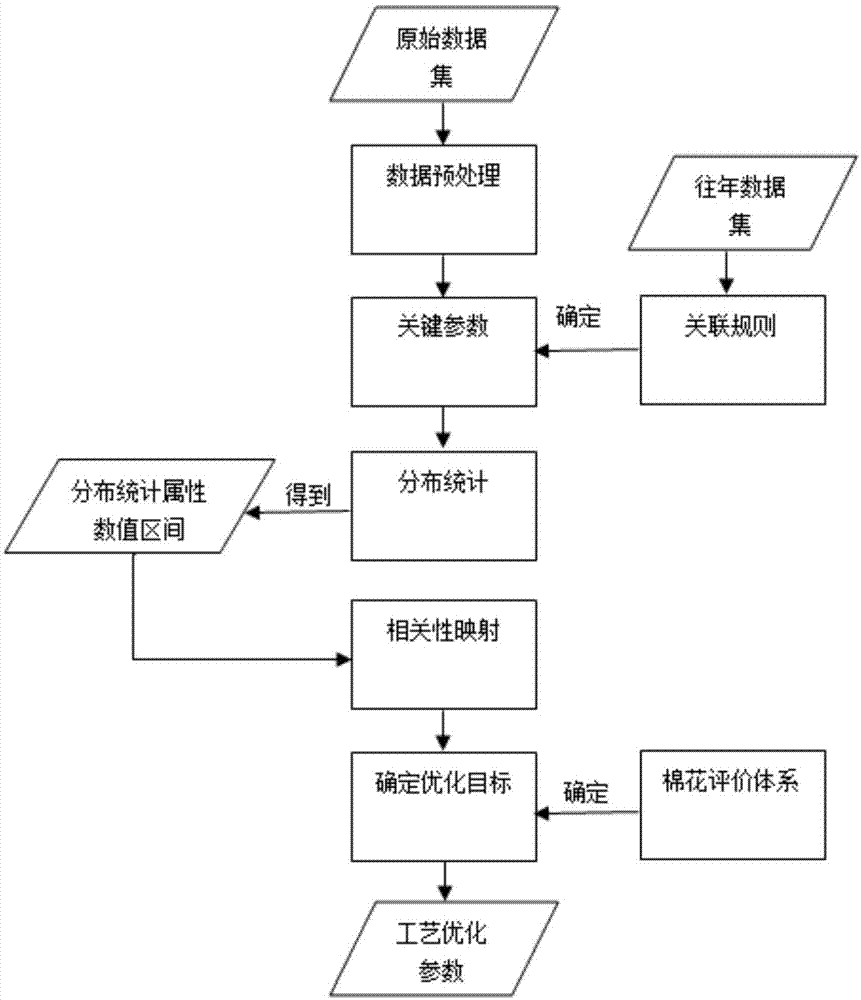
:在农作物中,棉花是一种关系到国计民生的重要战略资源,在工业,医疗及人们日常生活等方面得到了极为广泛的应用。棉花主要涉及农业和纺织业两大产业,它是产棉区农业经济发展的主要支柱,是纺织企业的关键原料,是出口创汇的重要来源,受到世界各大产棉国的重视。从成熟的棉稞上摘下的棉花叫做籽棉,籽棉经过加工后的纤维成为皮棉,棉花经过生长发育,收货,加工,运输等环节,或多或少都含有一定量的杂质,其产生的原因主要是包括自然生长,人工采摘,加工等方面。棉花的加工不同于其他,较为复杂,影响因素很多。而棉花加工技术的落后,也致使不同品级的籽棉混级,混轧现象严重,降低了皮棉品级。棉花能制成各种规格的织物。棉织物坚牢耐磨,能洗涤并在高温下熨烫。棉布吸湿和脱湿快速而使穿着舒适,应用人们日常生活的方方面面。可见棉花在生产生活的重要地位与作用,棉花是处于自然生长的状态,棉花与棉花间的各项数据没有完全相同的,所以采集到的棉花样本是难以复制的,无法找到完全相同棉花样本进行不同频率的除杂对比;只有更好的调节棉花的加工工序,优化棉花的加工生产,才能最大化提高棉花的质量品质,保证棉花产业经济快速发展。技术实现要素:本发明的目的是针对棉花的除杂加工是采用的单一的轧花模式,或者由操作人员仅凭经验现场手动调整,致使不同品级的籽棉混级,混轧现象严重,降低了皮棉品级,提供一种基于大数据分层聚类的棉花生产工艺优化方法,以解决上述技术问题。本发明的技术方案是:一种基于大数据分层聚类的棉花生产工艺优化方法,对原始数据进行数据分布统计,关联映射的方法来划分种类,得到各个关键生产参数的变化规律,获得数据中隐含的规律性知识,通过对参数的调整和预测优化工艺流程,包括如下步骤:对获取的生产监测原始数据进行数据预处理;对经过预处理后的原始数据确定描述参数属性的关键参数;对确定的关键参数进行数值统计得到分布统计属性数值分布分组;根据分布统计中得到的数值分布分组,使样本中各项属性数据分别映射到各属性分组区间中,形成新的数据集;确定优化目标,进行生产工艺参数的优化。进一步的,步骤对获取的生产监测原始数据进行数据预处理,包括:S11:进行数据清洗,消除重复冗余、冲突数据;S12:消减数据规模,同时对错漏数据进行修补;其中,对于棉花包号出现错误、重复的进行修复,对于棉花数据中出现空白的属性数据进行填充;通过对空白数据进行填充,可以保证数据的稳定性。S13:找到棉花加工环节中相同包号的棉花数据,形成新的数据集。对数据进行数据预处理可以更好的进行数据挖掘,发现数据间的关系。进一步的,步骤S12中,对于棉花数据中出现空白的属性数据进行填充,包括:如果数据中出现大量属性都出现空白缺失,直接将整条数据都删除掉;如果只有单个或少量的数据缺失,采用均值填充,如公式(1)所示;其中,Xi(tj)为Xi(tm)之前的n-m个数据,Xi(tk)为Xi(tn)之后的n-m个数据;若空缺值在数据的前面或后面,则直接将最前面和最后面的数据删除;若Xi(tm)前面或Xi(tn)后面数据不足n-m个,则从Xi(tn)后面或Xi(tm)前面顺延选取总量为2(n-m)个数据,使得到的均值含有足量的信息,而选择数据量过多,会增大计算复杂度;数据量过少,又不足以包含数据的信息。进一步的,步骤对经过预处理后的原始数据确定描述参数属性的关键参数,包括:S21:利用基于Apriori的维间关联规则算法对棉花往年的历史数据进行挖掘,得到任意两个属性的关联规则;其中,所述规则,用于表示不同属性的两个满足最小支持度和最小置信度的聚类之间的关系;S22:结合棉花的加工过程以及评价棉花的质量与等级,确定关键参数。进一步的,步骤S22中,所述关键参数包括马克隆值、反射率、黄度、含杂率;其中,马克隆值是反映棉花纤维细度与成熟度的综合反映,直接影响棉纤维的色泽、强力、细度、天然性、弹性等,可作为评价棉纤维内在品质的一个综合指标;反射率与黄度,评估色泽,表明棉纤维的外观形态,棉纤维色泽、含杂数量种类、皮棉表面粗糙度或平滑度,是用来划分棉花颜色级类型和级别的重要依据;含杂率,棉花中含有一定量的杂质颗粒,主要是由于棉花的自然生长的过程,和棉花的加工生产的过程混入一些杂质。含杂率就决定着棉花的品质质量,也是棉花检验的重要指标。进一步的,步骤S21的实现过程包括:设任意两个属性xi和xj共产生ωij条规则,其中任意一条规则为ia→jb,计算前项为xi和后项为xj的聚类之间的关联度cij(β),则cij(β)=Sβ(ia→jb)×I'β(ia→jb),β≤ωij(2)且I'β(ia→jb)=Iβ(ia→jb)-1(3)其中,I(ia→jb)为兴趣度,β表示所有规则中的第β条规则。进一步的,步骤对确定的关键参数进行数值统计得到分布统计属性数值分布分组,过程如下:S31:根据工艺过程的加工数据与属性数据,将确定的关键参数进行数值统计;S32:计算得到每项属性的数据分布情况;S33:根据各项属性的数据分布统计情况,通过数值分割,将每项属性的数据分别均匀分成若干份,得到数据的数值分布分组。进一步的,步骤对确定的关键参数进行数值统计得到分布统计属性数值分布分组,具体步骤如下:S301:对n个棉花样本Xn=(x1,x2,……,xm)中的马克隆值x1,反射率x2,黄度x3属性值分别进行数值排序,得到各项属性值的范围,确定每项属性数值的上下界x1∈(a0,an),x2∈(b0,bn),x3∈(c0,cn);S302:对已排序各属性序列,进行截断取值Cutoffvalue,如公式(4)所示,截断大小设为序列大小1/5或1/10,在各个属性上都得到5个截断值,根据得到的属性数值的上下界和截断值,每项属性都得到5个属性区间分组Intervali,如公式(5)所示,Cutoffvalue=ai*n/5,i∈(1,5)(4)S303:对马克隆值Ma-In、反射率Re-In、黄度Ye-In各属性的区间分组,进行分组组合组成一种三属性组合co(m),如公式(6)所示,co(m)=(Ma-Ini,Re-Inj,Ye-Ink),i,j,k∈(1,5)(6)列出所有属性分组组合情况,将其组成一张分组组合总表。进一步的,步骤根据分布统计中得到的数值分布分组,使样本中各项属性数据,分别映射到各属性分组区间中,形成新的数据集,即每一项的数据属性不再是具体的数值,而是相应的数值区间,具体步骤如下:S41:根据棉花样本的各属性的初始数据,对照在分布统计中得到的各属性的数值区间分组,得出马克隆值、反射率、黄度分别属于各自属性的具体分组;S42:生成一个新的数据集X'n,如公式(7)所示,其中各项的参数的数据不再是具体的数值,而是数值所对应的属性数值区间;X'n=(Ma-In,Re-In,Ye-In,x4,……xm)(7)S43:根据新数据中的各项棉花的属性数值区间,组成自身的分组组合,并将全部的棉花数据全部映射到分组组合表中,如公式(8)所示;其中Ma-In为马克隆值所对应马克隆分组,Re-In为反射率值所对应反射率分组,Ye-In为黄度值所对应黄度分组。进一步的,步骤确定优化目标,步骤如下:根据棉花的评价体系,确定棉花的含杂率Dp为优化目标;根据分组组合表中的每种属性组合中棉花样本数据,对其数据取平均值,得到该组合在各种不同加工工艺下的含杂率Dirt(m),如公式(9)所示,Dirt(m)=avg(co(m).Dp)(9)其中,Dp为含杂率,co(m)为马克隆值Ma-In、反射率Re-In、黄度Ye-In各属性的区间分组组合。从以上技术方案可以看出,本发明具有以下优点:对棉花数据进行分析,得到各种属性组合,性状组合的棉花,适合哪种加工的工艺类型。就可以针对不同类型的棉花,智能的选择不同的加工工艺工序,更好的优化棉花加工效果,从而降低棉花的含杂率,为棉花加工生产提供了更好的辅助作用。通过以上关键参数、分布统计、相关性映射、确定优化目标。四个步骤,通过离线对数据操作,对历史数据校验证实预测的准确度。并使用scala这种函数式编程与面向对象编程相结合的编程语言实现算法部分的编写,同时进行数学建模对数据进行预测和分析。结合棉花加工流程工艺分析。可以用于企业对工艺参数的分析调整。从而优化棉花生产、提高棉花质量、维护企业生产安全。本发明可针对棉花厂的多种频率除杂的历史数据进行处理,设计了相应算法流程,并进行数学建模,获取各个工序测点数据的变化趋势。对不同频率下的多种棉花除杂数据进行预测模拟,获得数据中隐含的规律性知识,用于辅助棉花厂对除杂机转速等参数调整,从而优化对不同种的棉花采用不同频率除杂,提高棉花的除杂加工效果。此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。由此可见,本发明与现有技术相比,具有突出的实质性特点和显著地进步,其实施的有益效果也是显而易见的。附图说明图1为一种基于大数据分层聚类的棉花生产工艺优化方法流程图;图2、图3为建模预测效果图,是对皮棉加工中一个重要参数含杂率做出的预测;其中,圆形“ο”示意的曲线为38hz下加工效果,三角形“Δ”示意的曲线为44hz下加工效果,星形示意的曲线为50hz下加工效果。具体实施方式下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。实施例一一种基于大数据分层聚类的棉花生产工艺优化方法,对原始数据进行数据分布统计,关联映射的方法来划分种类,得到各个关键生产参数的变化规律,获得数据中隐含的规律性知识,通过对参数的调整和预测优化工艺流程,包括如下步骤:S1:对获取的生产监测原始数据进行数据预处理;包括:S11:进行数据清洗,消除重复冗余、冲突数据;S12:消减数据规模,同时对错漏数据进行修补;其中,对于棉花包号出现错误、重复的进行修复,对于棉花数据中出现空白的属性数据进行填充;通过对空白数据进行填充,可以保证数据的稳定性,包括:如果数据中出现大量属性都出现空白缺失,直接将整条数据都删除掉;如果只有单个或少量的数据缺失,采用均值填充,如公式(1)所示:其中,Xi(tj)为Xi(tm)之前的n-m个数据,Xi(tk)为Xi(tn)之后的n-m个数据;若空缺值在数据的前面或后面,则直接将最前面和最后面的数据删除;若Xi(tm)前面或Xi(tn)后面数据不足n-m个,则从Xi(tn)后面或Xi(tm)前面顺延选取总量为2(n-m)个数据,使得到的均值含有足量的信息,而选择数据量过多,会增大计算复杂度;数据量过少,又不足以包含数据的信息。S13:找到棉花加工环节中相同包号的棉花数据,形成新的数据集。对数据进行数据预处理可以更好的进行数据挖掘,发现数据间的关系。S2:对经过预处理后的原始数据确定描述参数属性的关键参数;包括:S21:利用基于Apriori的维间关联规则算法对棉花往年的历史数据进行挖掘,得到任意两个属性的关联规则;其中,所述规则,用于表示不同属性的两个满足最小支持度和最小置信度的聚类之间的关系;S22:结合棉花的加工过程以及评价棉花的质量与等级,确定关键参数。S3:对确定的关键参数进行数值统计得到分布统计属性数值分布分组;包括:S31:根据工艺过程的加工数据与属性数据,将确定的关键参数进行数值统计;S32:计算得到每项属性的数据分布情况;S33:根据各项属性的数据分布统计情况,通过数值分割,将每项属性的数据分别均匀分成若干份,得到数据的数值分布分组。S4:根据分布统计中得到的数值分布分组,使样本中各项属性数据分别映射到各属性分组区间中,形成新的数据集;包括:S5:确定优化目标,进行生产工艺参数的优化。实施例二在棉花的加工生产的过程的中数据具有典型的流程对象特点,整个生产工艺包括了多个前后相关环节或工序,在整个棉花生产加工环节中都部署了数据采集接口,可以将实时检测数据存储到数据库中,集中数据库中获得的生产监测原始数据,通常存在着大量的噪声数据以及错漏信息,而且环节间的相互影响关系无法在数据中直接体现,并且具有分布、异步、离散的特性,无法直接用于大数据处理,需要将棉花包号错乱的,属性数据大量缺失的数据,进行数据清洗,去除噪声,消除冗余与冲突数据,消减数据规模,同时对错漏数据进行修补,形成内部生产系统元数据集,进行处理进行生产工艺的参数优化。如图1所示,本发明实施例提供一种基于大数据分层聚类的棉花生产工艺优化方法,包括如下步骤:S1:对获取的生产监测原始数据进行数据预处理;对于采集、整合后的原始数据,首先需要进行数据清洗,即数据预处理,便于后续算法的操作执行。数据预处理(DataPreprocessing)包括消除重复冗余,冲突数据,消减数据规模,同时对错漏数据进行修补,对于棉花包号出现确实,错误,重复的进行修复,对于棉花数据中出现空白的属性数据进行填充。找到棉花加工环节中相同包号的棉花数据,形成新的数据集。对数据进行数据预处理可以更好的进行数据挖掘,发现数据间的关系。空值填充,如果数据中出现大量空白缺失,我们将条数据直接删除掉;对于单个或少量的数据缺失,采用均值填充,如公式(1)所示。通过对空白数据进行填充,可以保证数据的稳定性。其中,Xi(tj)为Xi(tm)之前的n-m个数据,Xi(tk)为Xi(tn)之后的n-m个数据;若空缺值在数据的前面或后面,则将其直接删除;若Xi(tm)前面或Xi(tn)后面数据不足n-m个,则从Xi(tn)后面或Xi(tm)前面顺延选取总量为2(n-m)个数据,使得到的均值含有足量的信息,而选择数据量过多,会增大计算复杂度;数据量过少,又不足以包含数据的信息。采用数据清洗等方法对于未处理的历史数据进行处理,针对数据分散的问题,将数据进行整合,选取所有环节处于相同包号的数据,合并成为新的数据。此时得到的数据含有大量工艺流程顺序的信息,对数据进行工艺流程顺序模式挖掘时会得到较为准确的结果。S2:对经过预处理后的原始数据确定描述参数属性的关键参数;棉花的各类属性参数众多。我们利用基于Apriori的维间关联规则算法对棉花往年的历史数据进行挖掘,得到任意两个属性的关联规则。通过两两之间的规则,得到属性间的关联。设置最小支持度sup,最小置信度conf,搜索频繁2-维项集,生成不同属性任意两属性间的二项关联规则,这些规则表示不同属性的两个满足最小支持度和最小置信度的聚类之间的关系;设任意两个属性xi和xj共产生ωij条规则,其中任意一条规则为ia→jb,计算前项为xi和后项为xj的聚类之间的关联度cij(β),则cij(β)=Sβ(ia→jb)×I'β(ia→jb),β≤ωij(2)且I'β(ia→jb)=Iβ(ia→jb)-1(3)其中,I(ia→jb)为兴趣度,β表示所有规则中的第β条规则。然后找到关联度最强的规则,从而得到属性间关联的关系。我们结合棉花的加工过程以及评价棉花的质量与等级。我们确定了棉花的关键参数。这些参数包括:马克隆值,反射率,黄度,含杂率等。其中,马克隆值是反映棉花纤维细度与成熟度的综合反映,直接影响棉纤维的色泽、强力、细度、天然性、弹性等,可作为评价棉纤维内在品质的一个综合指标;反射率与黄度,评估色泽,表明棉纤维的外观形态,棉纤维色泽、含杂数量种类、皮棉表面粗糙度或平滑度,是用来划分棉花颜色级类型和级别的重要依据;含杂率,棉花中含有一定量的杂质颗粒,主要是由于棉花的自然生长的过程,和棉花的加工生产的过程混入一些杂质。含杂率就决定着棉花的品质质量,也是棉花检验的重要指标。S3:对确定的关键参数进行数值统计得到分布统计属性数值分布分组;根据棉花的加工数据与属性数据,分别棉花的关键参数,马克隆值,反射率,黄度进行数值统计,计算得到每项属性的数据分布情况。根据各项属性的分布统计情况,通过数值分割,将每项属性的数据分别均匀分成5份或者10份。每份数据均匀分配。得到马克隆值,反射率、黄度等数据的数值分布分组;对n个棉花样本Xn=(x1,x2,……,xm)中的马克隆值x1,反射率x2,黄度x3属性值分别进行数值排序,得到各项属性值的范围,确定每项属性数值的上下界x1∈(a0,an),x2∈(b0,bn),x3∈(c0,cn);对已排序各属性序列,进行截断取值Cutoffvalue,如公式(4)所示,截断大小设为序列大小1/5或1/10,在各个属性上都得到5个截断值,根据得到的属性数值的上下界和截断值,每项属性都得到5个属性区间分组Intervali,如公式(5)所示,Cutoffvalue=ai*n/5,i∈(1,5)(4)S303:对马克隆值Ma-In、反射率Re-In、黄度Ye-In各属性的区间分组,进行分组组合组成一种三属性组合co(m),如公式(6)所示,co(m)=(Ma-Ini,Re-Inj,Ye-Ink),i,j,k∈(1,5)(6)列出所有属性分组组合情况,将其组成一张分组组合总表,如表1所示,表1是皮棉的分布统计属性数值区间表分割属性马克隆值反射率黄度1(3.9,4.26)(72,73.9)(8.6,8.9)2(4.27,4.4)(74,74.5)(9.0,9.1)3(4.41,4.47)(74.6,75.1)(9.2,9.3)4(4.48,4.53)(75.2,75.7)(9.4,9.5)5(4.54,5)(75.8,80)(9.6,12)S4:根据分布统计中得到的数值分布分组,使样本中各项属性数据分别映射到各属性分组区间中,形成新的数据集;初始棉花样本数据,通过分布统计中得到的马克隆值,反射率,黄度等数据的数值分布分组,使样本中各项属性数据,分别映射到各属性分组区间中,形成新的数据集,即每一项的数据属性不再是具体的数值,而是相应的数值区间。根据棉花样本的各属性的初始数据,对照在分布统计中得到的各属性的数值区间分组,得出马克隆值、反射率、黄度分别属于各自属性的哪个分组;生成一个新的数据集X'n,如公式(7)所示,其中各项的参数的数据不再是具体的数值,而是数值所对应的属性数值区间;X'n=(Ma-In,Re-In,Ye-In,x4,……xm)(7)根据新数据中的各项棉花的属性数据(属性数值区间),就可以组成自身的分组组合,最后将全部的棉花数据全部映射到分组组合表中。如公式(8)所示;其中,Ma-In为马克隆值所对应马克隆分组,Re-In为反射率值所对应反射率分组,Ye-In为黄度值所对应黄度分组。根据棉花的特点,棉花自然生长,数据无法复制且各不相同,我们通过分布统计,相关性映射有效的解决了对棉花分类鉴别。S5:确定优化目标,进行生产工艺参数的优化;在棉花加工和生产的过程中,皮棉需要四道加工工序,根据棉花的评价体系,棉花的含杂率Dp是需要考虑的重要指标。根据分组组合表中的每种属性组合中棉花样本数据,对其数据取平均值,得到该组合在各种不同加工工艺下的含杂率Dirt(m),如公式(9)所示,Dirt(m)=avg(co(m).Dp)(9)其中,Dp为含杂率,co(m)为马克隆值Ma-In、反射率Re-In、黄度Ye-In各属性的区间分组组合。如此就可以得到各种棉花的加工工艺,各自更适用于哪一类属性的棉花。如如图2、3所示,我们得到在皮棉38hz的加工工艺下(1.20%)皮棉在马克隆值为3.9到4.26的范围,反射率在75.8到80的范围,并且黄度在9.6到12的范围时棉花除杂效果最好。在44hz下(1.26%)皮棉除杂效果最好的情况时,在马克隆值为4.48到4.53的范围,反射率在75.2到75.7的范围,并且黄度在9到9.1的范围。在50hz下(0.84%)皮棉在两种情况下棉花除杂效果最好,第一种情况皮棉在马克隆值为4.27到4.4的范围,反射率在74.6到75.1的范围,并且黄度在8.6到8.9的范围。第二种情况皮棉在马克隆值为4.54到5的范围,反射率在75.8到80的范围,并且黄度在9.6到12的范围。本发明是针对棉花的除杂加工是采用的单一的轧花模式,或者由操作人员仅凭经验现场手动调整,致使混轧现象严重,降低了皮棉品级。所以我们对棉花数据进行分析,得到各种属性组合,性状组合的棉花,适合哪种加工的工艺类型。就可以针对不同类型的棉花,智能的选择不同的加工工艺工序,更好的优化棉花加工效果,从而降低棉花的含杂率,为棉花加工生产提供了更好的辅助作用。本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1