一种基于图像多特征融合的胶囊胃镜图像出血点识别方法与流程
本发明属于医学图像处理技术领域,用于胶囊胃镜图像出血点识别,具体为一种基于图像多特征融合的胶囊胃镜图像出血点识别方法。
背景技术:
随着我们现代人生活的饮食习惯改变,以胃癌为主的消化道疾病检测越来越受到医生以及病人的重视。随着病人数量的快速增加与日渐增长的疾病诊断精确程度的需求,胃镜检测显微图像的分析数量成倍增加。这导致了实验室专家的工作量增加,需要增加更多人员、设备来应对病人的需求。并且胃镜图像检测结果受到当事者的状态限制,可能会产生错误的结果。利用计算机技术对胃镜检测图像进行分析,提高胃镜检查的准确率,无疑是是提高胃镜检查准确率的有效方法。若能利用计算机辅助系统分担部分病理图像分析工作,在当前医疗资源如此紧张的情况下具有重要意义。
技术实现要素:
本发明的目的是图像多特征融合结合起来用于胶囊胃镜图像出血点识别,并利用k-nn算法和adaboost算法实现强分类器的学习与训练,从而实现对出血点的有效识别,实现计算机辅助医生更便捷地开展诊断工作。
本发明采取的技术方案是:
首先,提取胶囊胃镜图像的多个特征;接着,对图像特征进行特征融合得到一组新的特征向量;然后,对特征向量的各个方向分量进行归一化处理;进而,使用k-nn(k-nearestneighbour,k近邻)算法训练基本分类器;最后,通过adaboost算法集成基本分类器为强分类器。
本发明解决其技术问题所采用的技术方案如下:
步骤(1).输入数据库中的图像id;
步骤(2).将步骤(1)输入的图像id从rgb空间映射到hsv空间,转换公式如下:
r=r/255(1)
g=g/255(2)
b=b/255(3)
max=max{r,g,b}(4)
min=min{r,g,b}(5)
v=max(8)
其中,r,g,b是图像id在rgb空间的三个分量,h,s,v是转换后的值。
步骤(3).对步骤(2)得到的hsv空间进行等间隔量化,h量化为qh级;s量化成qs级;v量化为qv级。
步骤(4).对步骤(3)得到等间隔量化后的hsv空间采用直方图法提取图像的颜色特征。公式如下:
g=qsqvh0+qvs0+v0(10)
f(g)=ng/n(11)
其中,n表示id的像素点总数,ng表示特征为g的像素点数,形成了一个直方图。从而得到颜色特征向量:
fcolor=[f(0)f(1)...f(g)](12)
步骤(5).将步骤(1)输入的图像id转换为灰度图像ig。转换公式如下:
gray=0.299*r+0.587*g+0.114*b(13)
其中,gray为转换后每个像素点的灰度值。
步骤(6).计算步骤(5)得到的灰度图像ig的灰度共生矩阵,选取4个方向(0°,45°,90°,135°),从而得到四个灰度共生矩阵m1,m2,m3,m4。
步骤(7).计算步骤(6)得到的灰度共生矩阵的能量ene、熵ent、惯性矩con和相关性hom,公式如下:
其中,p(i,j)为灰度共生矩阵中坐标为(i,j)的元素值。四个灰度共生矩阵就得到了四组ene、熵ent、惯性矩con和相关性hom。
步骤(8).对于步骤(7)得到的四组能量ene、熵ent、惯性矩con和相关性hom,分别计算其均值和方差。
步骤(9).以步骤(8)得到的8个数据组成纹理特征向量ftexture。
步骤(10).对步骤(5)得到的灰度图像ig计算其(p+q)阶归一化中心矩ηpq,公式如下:
r=(p+q+2)/2(22)
其中,p,q都是非负整数,mpq是图像ig的(p+q)阶矩,i0表示图像灰度在水平方向上的灰度质心,j0表示图像灰度在垂直方向上的灰度质心,μpq表示图像ig的(p+q)阶中心矩,ηpq表示图像ig的(p+q)阶归一化中心矩。
步骤(11).利用步骤(10)得到的灰度图像ig的(p+q)阶归一化中心矩ηpq计算其hu不变矩,公式如下:
φ1=η02+η20(24)
φ3=(η30-3η12)2+(3η21-η03)2(26)
φ4=(η30+η12)2+(η21+η03)2(27)
φ6=(η20-η02)[(η30+η12)2-(η21+η03)2]+4η11(η30+η12)(η21+η03)(29)
步骤(12).利用步骤(11)得到的hu不变矩构成图像形状特征向量,公式如下:
fshape=[φ1φ2...φ7](31)
步骤(13).对步骤(4)(9)(12)所得到的三个图像特征向量进行特征融合得到一组新的特征向量。即
f=[fcolorftexturefshape](32)
步骤(14).对步骤(13)得到的特征向量f进行归一化处理,使得向量f的各个方向分量在进行相似度度量时地位相同。归一化区间为[0,1]。得到归一化后的特征向量h。
步骤(15).将步骤(14)得到的特征向量h以及对应的输出y(是否有出血点,有出血点y为1,没有出血点y为-1)作为训练集t1,测试图像的特征向量ht以及对应的输出yt(是否有出血点,有出血点yt为1,没有出血点yt为-1)作为测试集t2,使用k-nn(k-nearestneighbour,k近邻)算法得到基本分类器dk(h)。距离度量方法为欧氏距离。具体过程如下:
①输入训练集t1={(h1,y1),(h2,y2),...,(hn,yn)},其中hn为第n幅图像的特征向量,yn为第n幅图像的输出。输入测试集t2中的一个向量ht。
②根据给定的距离度量,找出与ht距离最近的k个点,涵盖这k个点的ht的邻域记做nk(ht)。
③在nk(ht)中根据多数表决规则决定ht的类别yt,从而得到基本分类器dk(h)。k取不同的奇数值得到不同的基本分类器dk(h)。
步骤(16).利用adaboost算法集成基本分类器dk(h)为强分类器,具体过程如下:
①输入集合t2作为训练数据集t2={(ht1,yt1),(ht2,yt2),...,(htz,ytz)},输入步骤(15)得到的基本分类器dk(h)。
②按照公式(33)初始化训练数据的权值分布:
w1=[w11...w1i...w1z],w1i=1/z,i=1,2,...,z(33)
③对于迭代次数m=1,2,...,m:
(a)按照公式(34)计算基本分类器dk(h)在训练数据集t2上的分类误差率emk,选取当前误差率最低的分类器作为第m个基本分类器rm(h)。
(b)计算系数αm,公式如下:
(c)更新训练数据集的权值分布,公式如下:
wm+1=[wm+1,1...wm+1,i...wm+1,z](38)
其中,zm是规范化因子
(d)重复(a)(b)(c),直至达到迭代次数或者分类误差率小于设定的临界值。
④构建基本分类器的线性组合,得到最终分类器:
步骤(17).输入待检测的胶囊胃镜图像,利用步骤(16)训练好的强分类器进行出血点检测。
本发明的有益效果:
本发明通过将adaboost算法与图像多特征融合结合起来用于胶囊胃镜图像出血点识别,显著提高了识别率,可以更有效地辅助医生进行诊断。
附图说明
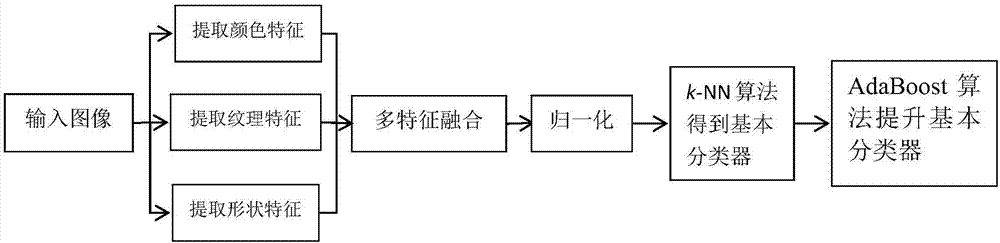
图1为本发明一种将图像多特征融合结合起来用于胶囊胃镜图像出血点识别方法的结构框图。
图2测试集中的出血点图像与位置标定示意图。
图3出血点识别效果示意图1;
图4出血点识别效果示意图2。
具体实施方式
下面结合附图对本发明方法作进一步说明。
如图1所示,将adaboost算法与图像多特征融合结合起来用于胶囊胃镜图像出血点识别的方法,其具体实施步骤如下:
步骤(1).在matlab环境下输入数据库中jpeg格式的训练图像id;
步骤(2).将步骤(1)得到的图像id从rgb空间映射到hsv空间,转换公式如下:
r=r/255(1)
g=g/255(2)
b=b/255(3)
max=max{r,g,b}(4)
min=min{r,g,b}(5)
v=max(8)
其中,r,g,b是图像id在rgb空间的三个分量,h,s,v是转换后的值。
步骤(3)对步骤(2)得到的hsv空间等间隔量化,h量化为8级;s量化成3级;v量化为3级。公式如下:
步骤(4).对步骤(3)得到的颜色空间采用直方图法提取图像的颜色特征。公式如下:
g=9h0+3s0+v0(13)
f(g)=ng/n(14)可知,g的取值范围是[0,71),且g是整数。n表示id的像素点总数,ng表示特征为g的像素点数,形成了一个72柄的直方图。从而得到72维的颜色特征向量:
fcolor=[f(0)f(1)...f(71)](15)
步骤(5).将步骤(1)中的id转换为灰度图像ig。转换公式如下:
gray=0.299*r+0.587*g+0.114*b(16)
其中,gray为转换后每个像素点的灰度值。
步骤(6).对于步骤(5)得到的灰度图像ig,在matlab中利用graycomatrix函数计算灰度图像ig的灰度共生矩阵,offset(a,b)分别设置为(1,0),(1,1),(0,1),(-1,1),分别对应0°,45°,90°,135°四个方向。从而得到四个灰度共生矩阵m1,m2,m3,m4。
步骤(7).计算步骤(6)得到的灰度共生矩阵的能量ene、熵ent、惯性矩con和相关性hom,公式如下:
其中,p(i,j)为灰度共生矩阵中坐标为(i,j)的元素值。四组offset(a,b)就得到了四组ene、熵ent、惯性矩con和相关性hom。
步骤(8).对于步骤(7)得到的四组能量ene、熵ent、惯性矩con和相关性hom,分别计算其均值和方差,公式如下
步骤(9).以步骤(8)得到的8个数据组成纹理特征向量ftexture,即:
步骤(10).对步骤(5)得到的灰度图像ig计算其(p+q)阶归一化中心矩ηpq,公式如下:
r=(p+q+2)/2(34)
其中,p,q都是非负整数,mpq是图像ig的(p+q)阶矩,i0表示图像灰度在水平方向上的灰度质心,j0表示图像灰度在垂直方向上的灰度质心,μpq表示图像ig的(p+q)阶中心矩,ηpq表示图像ig的(p+q)阶归一化中心矩。
步骤(11).利用步骤(10)得到的灰度图像ig的(p+q)阶归一化中心矩ηpq计算其hu不变矩,公式如下:
φ1=η02+η20(36)
φ3=(η30-3η12)2+(3η21-η03)2(38)
φ4=(η30+η12)2+(η21+η03)2(39)
φ6=(η20-η02)[(η30+η12)2-(η21+η03)2]+4η11(η30+η12)(η21+η03)(41)
步骤(12).利用步骤(11)得到的hu不变矩构成图像形状特征向量,公式如下:
fshape=[φ1φ2...φ7](43)
步骤(13).对步骤(4)(9)(12)所得到的三个图像特征向量进行特征融合得到一组新的特征向量。即
f=[fcolorftexturefshape](44)
步骤(14).对步骤(13)得到的特征向量f进行归一化处理,使得向量f的各个方向分量在进行相似度度量时地位相同。归一化区间为[0,1]。归一化方法如下:首先对训练集的所有图像提取特征向量f,接着分别对f的各个方向分量求均值μ和方差σ2,然后用公式(45)对f的各个方向分量进行归一化处理:
从而得到归一化后的特征向量h。
步骤(15).将步骤(14)得到的特征向量h以及对应的输出y(是否有出血点,有出血点y为1,没有出血点y为-1)作为训练集t1,测试图像的特征向量ht以及对应的输出yt(是否有出血点,有出血点yt为1,没有出血点yt为-1)作为测试集t2,使用k-nn(k-nearestneighbour,k近邻)算法得到基本分类器dk(h)。距离度量方法为欧氏距离。具体过程如下:
①输入训练集t1={(h1,y1),(h2,y2),...,(hn,yn)},其中hn为第n幅图像的特征向量,yn为第n幅图像的输出。输入测试集t2中的一个向量ht。
②根据给定的距离度量,找出与ht距离最近的k个点,涵盖这k个点的ht的邻域记做nk(ht)。
③在nk(ht)中根据多数表决规则决定ht的类别y:
k取不同的奇数值得到不同的基本分类器dk(h)。这里k取1,3,5,7,9,得到5个基本分类器d1(h),d3(h),d5(h),d7(h),d9(h)。
步骤(16).利用adaboost算法集成基本分类器d1(h),d3(h),d5(h),d7(h),d9(h)为强分类器,具体过程如下:
①输入集合t2作为训练数据集t2={(ht1,yt1),(ht2,yt2),...,(htz,ytz)},输入步骤(15)得到的基本分类器d1(h),d3(h),d5(h),d7(h),d9(h)。
②按照公式(46)初始化训练数据的权值分布:
w1=[w11...w1i...w1z],w1i=1/z,i=1,2,...,z(46)
③对于迭代次数m=1,2,...,m:
(a)按照公式(47)计算基本分类器d1(h),d3(h),d5(h),d7(h),d9(h)在训练数据集t2上的分类误差率em1,em3,em5,em7,em9,选取当前误差率最低的分类器作为第m个基本分类器rm(h)。
(b)计算系数αm,公式如下:
(c)更新训练数据集的权值分布,公式如下:
wm+1=[wm+1,1...wm+1,i...wm+1,z](51)
其中,zm是规范化因子
(d)重复(a)(b)(c),直至达到迭代次数或者分类误差率小于设定的临界值。
④构建基本分类器的线性组合,得到最终分类器:
步骤(17).输入待检测的胶囊胃镜图像,利用步骤(16)训练好的强分类器进行出血点检测。
为对本发明所提出的方法的性能评测,在本实施例中,利用本单位与合作公司共建的胶囊胃窥镜出血点测试集进行测试。测试集中共有1863张出血点图像,而且每一张出血点图像都对应一个出血点位置标定图,如图2所示,其中上面一排为出血点图像,下面一排为对应的出血点位置标定图。
在测试中,用训练好的模型对输入的测试图像进行处理,可以实现对出血点的自动识别,识别效果如图3和图4所示。可以看出,基于本发明提出的方法可以有效识别胃窥镜图像中出血点,如图3(b)和图4(b)中的标注。究其原因,本发明融合了图像,纹理和形状三个特征,并且先用k-nn算法训练基本分类器,得到的分类正确率已经较高,接着用adaboost算法集成为强分类器,进一步提高了正确率。
- 还没有人留言评论。精彩留言会获得点赞!