一种基于贝叶斯神经网络的深度知识追踪方法与流程
基于贝叶斯神经网络的深度知识追踪是一种知识追踪方法,本发明涉及一种在线测评技术。
背景技术:
在大数据背景下,学生的学习习惯、学习进度、学习状况等指标都被有效地量化和收集。对学生的学习行为进行数据分析,及时反馈学生的学习效果,推荐合理的学习路径和恰当难度的学习资源,实现高效的知识传授与学习,是智能教育系统(intelligenttutoringsystems,its)的一项重要研究课题。实现个性化自适应学习的前提是对学生的知识掌握情况有一个精准的评估。学生行为数据之间的关系复杂,传统的基于特征工程的方法挖掘学习行为关系、评估知识点掌握情况显得捉襟见肘,学生在its上的交互数据追踪其知识点的掌握情况可信度不高。现有的基于深度神经网络的知识追踪方法,不用显式编码人类领域知识,能够挖掘出学生行为复杂关系,但效果不佳且易过拟合。究其原因主要有两点。
其一,知识追踪方法对影响学生行为表现的诸多属性特征考虑不够周全。传统的学生知识追踪方法项目反应理论(itemresponsetheory,irt)和贝叶斯知识追踪(bayesianknowledgetracing,bkt)均忽略了学生答题知识点间的关联关系。irt追踪评估学生能力,考虑学生能力和和题目难度的差异,获取的是静态属性,不适用于建模学生学习的动态过程。bkt能够根据学生的行为表现动态获取学生的知识点掌握情况,但bkt假定学生能力和同一知识点下的题目难度相同,未考虑题目难度和学生能力,与实际不符。
其二,知识追踪方法模型自身存在不足。(1)传统的知识追踪方法能力有限。学生的学习行为数据的数据量巨大,数据复杂,数据中存在着大量的潜在关系,不仅知识点之间存在着联系,而且学生的行为之间也存在着联系,学生答题的顺序和各知识点对错顺序都会影响到最终的结果和表现,传统的特征工程建模方法用于建模特征丰富的学生行为数据显得极为困难。(2)现有的深度神经网络知识追踪模型,采用传统的循环神经网络(recurrentneuralnetwork,rnn),使用时间截断反向传播算法,易遭遇过拟合问题。
本发明针对现有的知识追踪方法的不足,基于贝叶斯神经网络和深度知识追踪,提出了基于贝叶斯神经网络的深度知识追踪(bayesianneuralnetworkdeepknowledgetracing,bdkt)方法,该方法完美的结合了概率编程和深度学习,既保留了深度神经网络在知识追踪上的优势,又有效的避免深度知识追踪易出现的过拟合问题。借鉴自然语言处理中词向量训练的思想,在贝叶斯神经网络深度知识追踪方法中加入学生行为向量训练,更有针对性的对学生行为编码,极大程度上提高了测评结果的准确性。
技术实现要素:
本发明提出一种基于贝叶斯神经网络的深度知识追踪方法。该方法的关键是得到一个尽可能完美的模型模拟学生答题过程。下面将从模型构建方法、模型参数形式设置方法和模型训练方法三个方面详细阐述贝叶斯神经网络的深度知识追踪模型的形成过程。
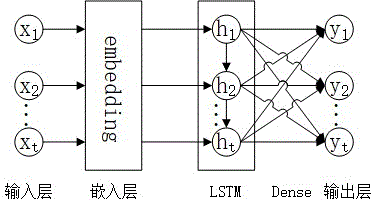
模型构建方法:模型的构建如图1所示,采用embedding+lstm+dense结构。embedding层用来训练学生行为向量库,将行为特征索引映射到通过模型训练得到的学生行为特征向量,降低输入数据维度的同时,更多的保留数据特征信息。循环神经网络的lstm用来处理学生答题前后行为的长依赖关系,lstm是处理长依赖问题的有效技术。dense层用来将lstm输出的数据处理映射到n个知识点,得到学生各个时刻知识点的掌握情况。
模型参数形式设置方法:模型参数由原始点值形式替换为概率分布形式,权重
参数训练方法:引入了模型参数的贝叶斯先验知识进行参数训练。传统模型损失函数是计算输出值与真实值的差值,改进后的模型损失计算包括参数先验与后验分布差值以及输出值与真实值的差值两部分。根据模型的损失运用贝叶斯反向传播算法和批梯度下降算法进行模型参数的调整。引入贝叶斯先验知识,可有效地加快模型收敛速度,提升模型的泛化能力,能有效的防止过拟合。
本发明提出的贝叶斯神经网络深度知识追踪方法,可以更好的模拟学生答题过程,更加准确的预测学生知识点掌握情况,很好的弥补现有知识追踪方法的缺点和不足。
附图说明:
图1bdkt模型结构图
图2bdkt模型生成流程图
图3bdkt模型评测流程图
具体实施步骤:
本发明实现的方法主要包含以下四个步骤:数据收集,数据预处理,模型生成和模型运用。
数据收集:学生交互记录中数据繁多,首先需要对学生交互数据中的有效数据进行提取,主要包括数据集中的以下字段:学生id,学生名,题目名,题目知识点,答题对错,答题记录产生时间,从所有的交互数据中以学生为单位提取出每个学生的交互记录数据。
数据预处理:首先对收集到的数据中的n个知识点排序编号,用序号0~n-1来表示,建立知识点与序号一一对应关系。然后对学生答题行为进行编码,第i个知识点答题结果为
模型生成:模型的生成参照如图2所示流程,将数据处理成所需要求,分成训练集和测试集两部分,运用训练集进行模型训练,用测试集检测训练模型的acc和auc指标,达到标准就保存模型,不达标就继续进行参数的调整,直至生成理想模型。
模型运用:模型运用参照如图3所示流程,将学生已经完成的答题记录数据提取后,经过数据预处理数据标准化后,输入到已经训练好的模型,根据学生行为索引,找到embedding层中对应的学生行为向量,生成学生交互记录的数据化矩阵,经过lstm和dense层得到n个知识点的掌握情况。
结合一个具体的实例方法,操作流程步骤如下:
1)收集所有学生在教辅系统上的答题记录数据;
2)特征数据选取,提取学生答题记录的有效数据;
3)对提取学生数据进行预处理,数据化学生交互记录;
4)构建并训练bdkt模型,保存达标模型;
5)输入某个学生答题记录数据;
6)进行上述2,3步,完成学生数据处理;
7)运用4步训练好的模型,进行学生知识点掌握情况评估;
8)给出该学生当前时刻的知识点掌握水平。
- 还没有人留言评论。精彩留言会获得点赞!