一种抽取网页半结构化数据的方法与流程
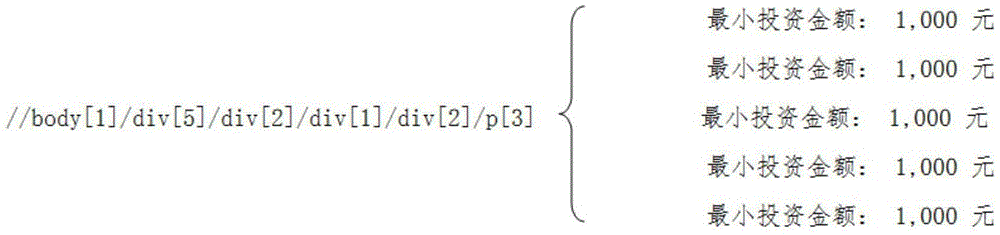
本发明涉及一种抽取网页半结构化数据的方法,属于数据抽取领域。
背景技术:
:半结构化数据抽取是数据抽取领域的难题,要解决的问题是如何从网页的html源码中抽出感兴趣的区域,并转化为更规整的结构化数据,便于后期的其他处理。具体来讲需要完成以下功能:使用网络爬虫技术,爬取指定网站的全部页面,网络爬虫现在已经是很成熟的技术,这里不再赘述。需要对网页进行预处理,去掉页面内无用元素以降低页面噪声,补充html缺失的文字节点标签,反转义html语法转义的字符等等操作。对网络爬虫爬取到的网站以url进行分类,一个网站的某个栏目下的url样式一致,对应的网页页面的结构也极其相似,通过对多个网页的相似结构进行分析,可以抽取出网页的结构化部分的模板。针对每个网页以该模板进行匹配就能得到需要的结构化数据。半结构化数据抽取方面目前还没有完全可靠的自动化抽取方法,针对不同的网站主要抽取网站模板的方法还停留在人工手动生成阶段。而面对网站数量巨大的情况,只凭借手动配置模板是很困难的。技术实现要素:针对以上问题,本发明提供一种简单快速的方法抽取出网站中的结构化数据。本发明从web站点爬取页面;人工定制化爬取目标页的url;配置一类网站的关键词词根;对类似的网页进行分析,根据case1,case2,case3进行分类判别,并对复杂的嵌套情况加以处理,抽取出网页模板。通过指定的url选出同类(栏目)url,同栏目url对应的html文本结构相似,遍历所有html节点,通过节点间的联系或节点本身,发现对应关键词的模板。从一个网站的所有子url中,找出和人工给定的相似的url。把目标格式分为case1,case2,case3,三种情况,对每一种情况分别进行处理,生成网页模板。为了解决以上问题,本发明采用了如下技术方案为:一种抽取网页半结构化数据的方法,其特征在于,包括以下内容:下面给出本发明中所需的一些定义:半结构化数据在网页中存在的形式是key-value对应的形式,通常存在3种对应的情况:case1情况:key节点,value节点同在一个父节点下case2情况:key、value同在一个节点下<div>key1:value1key2:value2</div>case3情况:key节点在同一个父节点下,value节点在同一个父节点下,同时key节点的父节点和value节点的父节点同在一个父节点下key节点:key所在的节点value节点:value所在的节点一、首先需要人工的两个步骤:①给定一个网站所有页面中,需要进行分析的目标页面的一个url;②维护一个想抽取的词的词根,用来过滤html中的文字节点,选出其中的key节点;二、一类网站只需要配置一组关键词,每个网站需要指定各自的目标分析页面的url;1、首先需要根据指定的url选出一个网站的同栏目下的网页,分析爬取的所有url,以“?”,“&”,“/”,“=”为分隔符切分所有的url,统计所有url分片出现的次数;修改指定目标页的url,高频部分不变,低频部分变为可标记符号,例如“[xxx]”,指定的url变为:https://www.rongcoo.com/p2p_loan/[xxx],以此为模板可以选出同类(栏目)的url和url对应的html文本;2、html文本清洗2.1、由于语法规则的限制,在html中转义了部分字符串;首先反转义这些字符,反转列表如下所示:表2.2html转义字符串html编码原字符 ;空格&;&";“<;<>;>2.2、html的部分标签包含和数据无关的大量的其他内容,在进行数据抽取的时候预先过滤掉这些和数据无关的标签;表2.3html不含数据标签2.3、在html孤立的文字节点上下文加入自定义的标签,以区别现有的html标签;html文本中的某些字段节点没有标签,添加自定义标签之后,可以通过自定义标签选出这些文字节点;3、解析html文本从预处理之后的页面选出4至5个进行分析;以所有html标签为分隔符,切分整篇html文本,寻找case1情况和case3情况的key节点,寻找节点遵循以下规则:节点包含关键词词根、不包含任何数字、除去首尾位置,其余位置不包含标点符号、长度在2-10个字符之间、包含该字面值的节点没有href属性;所有符合特征的字符串放入list<string>keyword中;使用htmlcleaner解析器对html源码进行分析;xpath语言用在标记xml路径中,预处理之后的html文档和xml格式一致,此时使用xpath来定位html节点位置;使用htmlcleaner对html文档进行解析,遍历每一个节点,并放入一个map<string,list<string>>map_xpath_reverse中;该map集合key为每个节点的xpath路径,value为在4至5个文档中,该xpath对应的节点字面值的集合;字面值在加入到集合前进行预处理操作:把所有的中文空格变为英文空格,把所有连续的空白符变成一个英文空格,去掉首尾的空格;所述的步骤3还包括以下内容:3.1、遍历map_xpath_reverse,分别生成case1、case2、case3的备选集合,map_xpath_reverse每个xpath对应list<string>valuetxt集合;遍历valuetxt集合,如果有某个节点字面值包含在keyword中,则把字面值放入新的map<string,set<string>>keywordxpath集合,集合的key是节点字面值,集合的value是字面值所有可能出现的xpath位置;keywordxpath实际上是map_xpath_reverse的子集的反转;如果valuelist没有被判定为key的节点,把该xpath放入另一个list<string>diffxpath,作为case2的备选集合;现在分析diff_xpath和keywordxpath,尝试为每个字面值生成对应的模式。3.2、分析case1,case2,case3情况3.2.1、case2情况分析首先处理case2情况的集合diff_xpath;case2情况的一个特殊情况是xpath对应的字面值节点都完全相同;case2的这种特殊情况key与value具有明显的分隔符,常用的分隔符有中文冒号“:”,中文空格“”两种;以这两种字符切分字符串,若能得到两个字符串,且有一个字符串符合key的判定规则,则为key生成模式;若xpath对应的字面值集合不同,则①对所有的字面值进行分析,取出最长的公共子串,若没有公共子串则不进行处理;②若最长的公共子串可以判定为需要的key,则认定找到一个关键词的模式;③xpath对应的字面值均去掉取出的最长公共子串,之后重新从①开始;3.2.2、case1情况分析case1情况处理的对象是关键词所在的父节点,case1解决的问题是判定key节点和value节点的顺序关系,判断方式:①如果第一个子元素为keyword中包含的元素,则为key-value模式;②如果最后一个子元素为keyword中包含的元素,则为value-key模式;某些网页的case1情况可能存在嵌套情况,例如case1之间互相嵌套,或case1、case2互相嵌套;嵌套情况下针对每一个key生成的模式以key1为开头,以key2为结尾;3.2.3、case3情况分析case3处理的对象是关键词的父父节点longnode“即最外层的div”和case1一样,首先要先判断key-value的位置关系;判断方法:遍历longnode的子元素,如果第一层均为key则为key-value模式,如果最后一层为key,则为value-key模式;随后判断keys层为longnode的第几层节点,如果keys位于第i层,在key-value模式下,values层为longnode的i+1层,value-key模式下,values为longnode的i-1层;最后判断skey为keys层的第几个元素,结果返回values层的对应位置的xpath;case3情况的模式不是正则表达式的形式,仅是给出value的xpath。本发明在处理网页的时候是面向网页的全部内容,把符合规则判定的字段拿出来的同时,很可能抽出了不需要的字段。本发明在生成网页模板的时候已经按xpath的顺序排序,因此可以很方便的去掉导航栏和页尾的友情链接栏的噪声。本发明以多个网站为样本进行分析,以准确率和召回率作为指标,结果如下表所示:表3.1实验结果表网站名称召回率准确率创贷网9/11(82%)9/12(75%)春雨金服11/11(100%)11/14(79%)鼎诚创投16/20(80%)16/21(76%)蜂融网10/11(91%)10/10(100%)河北长汇11/14(79%)11/16(69%)恒信易贷12/13(92%)13/14(93%)红杉资产8/12(67%)8/14(57%)金牌理财9/11(82%)9/9(100%)金融社14/14(100%)14/14(100%)人文贷12/14(86%)12/14(86%)春天金融10/10(100%)10/11(91%)方泽金服9/9(100)9/11(82%)718金融7/10(70%)7/7(100%)天邦16/18(89%)16/21(76%)附图说明图1:数据库中爬取的数据。图2:针对网站生成的模板。图3:网站首页截面图。图4:待抽取数据部分网站截面图。图5:map_xpath_reverse结构示意.图6:当网页格式较为混乱的时候一个字面值可能对应多个xpath的例子示意图。图7:在3.2.1中case2情况的一个特殊情况是xpath对应的字面值节点都完全相同的例子示意图。图8:在3.2.1中xpath对应的字面值集合不同的例子示意图。图9:在3.2.1中去掉公共子串后集合显示的内容示意图。具体实施方式一、定义下面给出本发明中所需的一些定义:半结构化数据在网页中存在的形式是key-value对应的形式,通常存在3种对应的情况:case1情况:key节点,value节点同在一个父节点下case2情况:key、value同在一个节点下<div>key1:value1key2:value2</div>case3情况:key节点在同一个父节点下,value节点在同一个父节点下,同时key节点的父节点和value节点的父节点同在一个父节点下key节点:key所在的节点value节点:value所在的节点二、方法步骤一:首先需要人工的两个步骤:①给定一个网站所有页面中,需要进行分析的目标页面的一个url,例如对于融客网来讲,目标页的url是:https://www.rongcoo.com/p2p_loan/20180425500014②需要维护一个关键词词组,用来过滤html中的文字节点,选出哪些是key节点,在互联网金融页面中,维护的词组如下表2.1需要的关键词词根步骤二:一类网站只需要配置一组关键词,每个网站需要指定各自的目标分析页面的url。1、首先需要根据指定的url选出一个网站的同栏目下的网页,分析爬取的所有url,以“?”,“&”,“/”,“=”为分隔符切分所有的url,统计所有url分片出现的次数,以融客网为例,p2p_loan出现的次数为50次,属于高频分片,20180425500014只出现2次,属于低频分片。修改指定目标页的url,高频部分不变,低频部分变为“[xxx]”,指定的url变为:https://www.rongcoo.com/p2p_loan/[xxx],以此为模板可以选出同类(栏目)的url和url对应的html文本。2、html文本清洗2.1、由于语法规则的限制,在html中转义了部分字符串,例如“&”变成了“&;”等等,首先反转义这些字符,反转列表如下所示:表2.2html转义字符串html编码原字符 ;空格&;&";“<;<>;>2.2、html的部分标签包含和数据无关的大量的其他内容,例如<script>标签,当中含有大量的数学表达式。这些标签的作用是控制页面的其他节点的位置,或者展示属性(例如display:none),或者是动画效果,这部分html标签不涉及到网页页面显示的数据,在分析页面数据的时候如果同时分析这些标签的文本会引入大量噪声,降低程序抽取效果。在进行数据抽取的时候可以预先过滤掉这些和数据无关的标签。表2.3html不含数据标签2.3、在html孤立的文字节点上下文加入特殊标签。html文本中的某些字段节点没有标签,例如这种情况如果想定位到可投金额,定位到div标签的同时也会把0元选出,如果先选出div的内容再减掉span的内容又过于麻烦,并且通用性不强,本文的处理方式是给可投金额添加一个标签,变成如下模式:添加mytag标签之后这样就可以通过//div/mytag选出可投金额,选择div的时候key与value可以分离开,后期处理更加方便。3、解析html文本从预处理之后的页面选出5个进行分析。以所有html标签为分隔符,切分整篇html文本,寻找case1情况和case3情况的key节点,寻找节点遵循以下规则:节点包含关键词词根、不包含任何数字、除去首尾位置,其余位置不包含标点符号、长度在2-10个字符之间、包含该字面值的节点没有href属性。所有符合特征的字符串放入list<string>keyword中。htmlcleaner是一个dom解析器,使用htmlcleaner可以很方便的操作dom树,包括添加、删除、修改节点,提取节点信息,寻找父节点及列出所有子节点等操作。htmlcleaner是一个开源的解析器,本发明使用该解析器对html源码进行分析。xpath语言用在标记xml路径中,预处理之后的html文档和xml格式一致,此时可以使用xpath来定位html节点位置。使用htmlcleaner对html文档进行解析,遍历每一个节点,并放入一个map<string,list<string>>map_xpath_reverse中。该map集合key为每个节点的xpath路径,value为在5个文档中,该xpath对应的节点字面值的集合。字面值在加入到集合前进行预处理操作:把所有的中文空格变为英文空格,把所有连续的空白符变成一个英文空格,去掉首尾的空格。字面值的预处理可以提高后期的准确率。3.1、遍历map_xpath_reverse,分别生成case1、case2、case3的备选集合,map_xpath_reverse结构示意:如图5所示。map_xpath_reverse每个xpath对应list<string>valuetxt集合。遍历valuetxt集合,如果有某个节点字面值包含在keyword中,则把字面值放入新的map<string,set<string>>keywordxpath集合,集合的key是节点字面值,集合的value是字面值所有可能出现的xpath位置。keywordxpath实际上是map_xpath_reverse的子集的反转。当网页格式较为混乱的时候一个字面值可能对应多个xpath,例如:如图6所示。如果valuelist没有被判定为key的节点,把该xpath放入另一个list<string>diffxpath,作为case2的备选集合。现在分析diff_xpath和keywordxpath,尝试为每个字面值生成对应的模式。3.2、分析case1,case2,case3情况3.2.1、case2情况分析首先处理case2情况的集合diff_xpath。case2情况的一个特殊情况是xpath对应的字面值节点都完全相同,例如:如图7所示。通过大量观察case2的这种特殊情况key与value通常具有明显的分隔符,常用的分隔符有中文冒号“:”,中文空格“”两种。以这两种字符切分字符串,若能得到两个字符串,且有一个字符串符合key的判定规则,则为key生成模式,以上的对应模式为“最小投资金额:[xxx]”。若xpath对应的字面值集合不同,例如:如图8所示。本发明处理过程中先选出一个最长的公共子串,公司名称和公司地址长度一致,此时优先选出排在前面的key,之后所有的字符串均去掉公共子串,集合中的内容变为:如图9所示。然后二次寻找最大公共子串,可以选出公司地址。处理的情形类似上面简单的情况,取出集合中的一条,按照关键词进行切分得到{“公司名称”,“:卓致科技,”,“公司地址”,“:湖北武汉”}。复杂情况生成了两个或者多个key对应“公司名称”的模式为“公司名称[xxx]公司地址”,对应“公司地址”的模式为“公司地址[xxx]”。3.2.2、case1情况分析case1情况处理的对象是关键词所在的父节点,case1主要解决的问题是判定key节点和value节点的顺序关系,即判断传入节点是判断方式:①如果第一个子元素为keyword中包含的元素,则为key-value模式②如果最后一个子元素为keyword中包含的元素,则为value-key模式生成的对应模式分别为“年化利率[xxx]”,“[xxx]年化利率”。某些网页的case1情况可能存在嵌套情况,例如case1之间互相嵌套,或case1、case2互相嵌套,如下所示:本发明针对嵌套情况作出了处理,在嵌套情况下针对每一个key生成的模式以key1为开头,以key2为结尾。上面左边生成两个模式为“公司名称[xxx]公司地址”、“公司地址[xxx]”和“借款金额[xxx]发布时间”、“发布时间[xxx]”。3.2.3、case3情况分析标准型示例为:case3处理的对象是关键词的父父节点longnode(最外层的div)。和case1一样,首先要先判断key-value的位置关系。判断方法:遍历longnode的子元素,如果第一层均为key则为key-value模式,如果最后一层为key,则为value-key模式。随后判断keys层为longnode的第几层节点,如果keys位于第i层,在key-value模式下,values层为longnode的i+1层,value-key模式下,values为longnode的i-1层。最后判断skey为keys层的第几个元素,结果返回values层的对应位置的xpath。假设投资人数在上例中的xpath为//div[1]/div[1]/span[3],则生成的value的xpath为//div[1]/div[2]/span[3],case3情况的模式不是正则表达式的形式,仅是给出value的xpath。下面结合附图对本发明做进一步阐述。以下以微微金融网为例,展示具体实施过程。首先网络爬虫爬取微微金融网的全部链接并存入数据库,如图3所示。选出指定目标页的5个页面,以下为项目产品页的内容,如图4所示:年利率的代码片段如上所示,根据技术解决方案中的逻辑,可以生成模板“年利率[xxx]”。<li>计息方式:t+1(t是满标日)</li>计息方式的代码片段入上所示,可以生成模板“计息方式[xxx]”。项目进度的代码片段如上所示,可以生成模板“项目进度[xxx]”。利用模板直接在网页中进行匹配可以得到规整的结构化数据。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1