基于深度卷积对抗生成网络DCGAN的双光图像融合模型的制作方法
本发明涉及计算机图像采集合成技术领域,具体的说是一种基于深度卷积对抗生成网络dcgan的双光图像融合模型。
背景技术:
近年来,随着现代科学技术的不断发展与互联网的广泛普及,温度夜视监控装备的各项功能得到了大幅提升,其应用成本也有了大幅度的下降。因此,利用红外监控摄像头获取各项工业机械设备的热度信息变得非常普及,很多处理红外光监控图像的方法也顺势出现。一般的红外探测器主要通过接收场景中目标向外辐射或者反射出来的红外辐射进行成像,其对烟雾具有较强的穿透能力,且在光照条件较差情况下仍具有较好的目标探测能力,但其所成的红外图像细节表现能力较差,这就导致红外光图像无法观察较细致的信息。而可见光图像的内容丰富,细节纹理清晰,空间分辨率较高,但其在光照条件差时,所以成像质量将受到严重影响。因此,如何开发一种融合低分辨率红外热图像与可见光图像算法非常重要。目前能解决双光融合问题的方法分两类,一类是通过光学设备产生对称光轴直接融合图像,另一类则是利用传统的图像增强和融合方法进行处理。
技术实现要素:
本发明的目的是提供一种基于深度卷积对抗生成网络dcgan的双光图像融合模型,以解决传统图像融合和增强方法中图像融合效果不佳的问题。
为解决上述技术问题,本发明所采取的技术方案为:
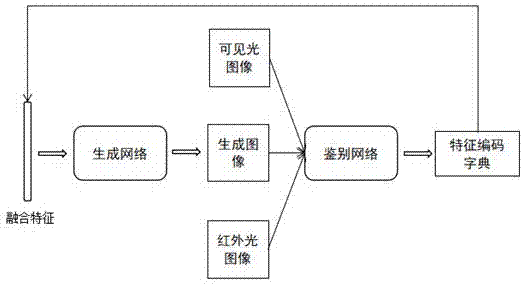
一种基于深度卷积对抗生成网络dcgan的双光图像融合模型,该模型将同一物体的可见光图像与红外光图像进行融合,该模型的建立过程包括以下步骤:
步骤一、鉴别网络提取特征:先将物体的大量可见光图像与红外光图像按照图像比例放缩到相同尺寸,构成图像训练库;然后构建一个以vgg网络为初始参数的卷积神经网络作为鉴别网络,利用图像库训练该鉴别网络,使得鉴别网络能有效区分红外光图像与可见光图像;再将待融合的可见光图像和红外光图像输入到该鉴别网络中,分别提取对应的图像特征;
步骤二、稀疏编码特征融合:将所有图像特征构建成完备的特征库,利用无监督的k-means方法在特征库数据上创建一个特征字典,用求解lasso问题的自我学习方法获得待融合的可见光图像和红外光图像特征在该特征字典上的编码,然后利用平均加权的方式融合该编码信息;
步骤三、生成网络生成图像:创建一个反卷积网络作为模型的生成网络,将步骤二所得的训练图像中的融合编码信息输入生成网络得到融合图像,利用融合图像在鉴别网络中的特征和实际融合编码特征之间的误差调整生成网络的参数;训练完成后,直接将待融合两幅图像的融合编码数据输入生成网络,便可生成同一物体的双光融合图像。
优选的,步骤一中所述鉴别网络提取特征的步骤为:
(1)用于提取可见光和红外光图像的特殊信息,鉴别网络在原本的vgg网络后面加上结构为500-100-2的小型神经网络,初始化鉴别网络时,小型神经网络用截断正态分布随机数初始化,其他参数均使用原本vgg网络训练好的参数作为初始化;
(2)鉴别网络的训练方式为将训练图像库中的数据按照可见光图像和红外光图像分为两类,将训练图像输入鉴别网络得到实际输出
在设置完成迭代次数和优化器参数后,就可以进行鉴别网络训练,训练好的鉴别网络作为一个特定的特征提取器;
(3)训练完成鉴别网络之后,利用该鉴别网络提取可见光图像和红外光图像的最后一层语义一维特征,设该网络提取的最后一层可见光图像和红外光图像的特征集为
特征样本分类完成后再对每个类别重新按照以下公式计算该类别的聚类中心:
通过反复的重复迭代之后得到网络最后一层语义特征集的最终聚类中心,而该聚类中心样本便是该层特征的编码字典
优选的,所述步骤二中特征字典编码的训练过程为:在融合两种同一物体的可见光图像和红外光图像时,将两张图像首先分别输入鉴别网络,通过鉴别网络提取可见光图像和红外光图像的语义特征,然后求解以下公式:
将可见光图像和红外光图像的特征带入该公式,得到该特征在特征字典上对应的编码结果;得到两个编码结果后将编码结果按照评价加权求和的方式进行融合,融合后的编码结果将附带两种光照图像的各项信息;最后利用该编码信息和特征字典得到融合特征,该特征将作为深度卷积对抗生成网络dcgan的输入隐变量。
优选的,所述步骤三所述的生成网络图像的方法为:所述步骤三所述的生成网络图像的方法为:首先构造一个16层的反卷积网络,该反卷积网络的输入维度为100,与鉴别网络的最后一层神经网络的神经元维度相同,反卷积网络的输出维度与鉴别网络的输入图像尺寸相同;构造完成深度卷积对抗生成网络dcgan后将融合编码特征输入深度卷积对抗生成网络dcgan将得到一张生成图像,该生成图像通过鉴别网络提取特征,鉴别网络逐层将所提取生成图像的特征:记生成图像第l层的特征为
来调节生成网络的参数;该误差函数保证了生成图像在像素级别和特征级别上均近似于可见光图像和红外光图像;利用该误差函数反复迭代调整生成模型的参数,训练完成之后将融合特征输入深度卷积对抗生成网络dcgan时就可以自动生成双光融合图像。
本发明所述的模型需要大量的红外光图像和可见光图像进行模型的训练,训练完成后输入待融合的两种光图便可以直接生成融合的双光图像。本发明所述的模型采用深度卷积对抗生成网络dcgan模型进行图像的生成和特征自动匹配,可以实现直接生成融合效果不错的双光图像。
本发明可应用于对可见光和红外光图像的融合利于,其有益效果是:
(1)首先在图像处理算法上完成了这个双光图像融合过程,避免了融合双光问题对硬件设备的高需求;
(2)由于提出了一个基于深度卷积对抗生成网络dcgan模型的双光融合模型,其中的生成网络结构和鉴别网络结构均是深度卷积神经网络,因此本模型保证了对待融合图像在像素级别和特征级别上的双重融合,达到远优于传统图像处理方法的融合效果;
(3)本发明所述的模型在训练结束后可随时调用,同时输入可见光和红外光图像便可自动生成融合质量较高的双光图像,减轻了传统融合双光图像所需要具备的硬件压力。
附图说明
图1是本发明所述的深度卷积对抗生成网络dcgan模型的结构示意图;
图2是特征融合过程示意图。
具体实施方式
下面结合附图对本发明做进一步详细的说明。
如图1所示的一种基于深度卷积对抗生成网络dcgan的双光图像融合模型,该模型将同一物体的可见光图像与红外光图像进行融合,该模型的建立过程包括以下步骤:
步骤一、鉴别网络提取特征:先将物体的大量可见光图像与红外光图像按照图像比例放缩到相同尺寸,构成图像训练库;然后构建一个以vgg网络为初始参数的卷积神经网络作为鉴别网络,利用图像库训练该鉴别网络,使得鉴别网络能有效区分红外光图像与可见光图像;再将待融合的可见光图像和红外光图像输入到该鉴别网络中,分别提取对应的图像特征;其具体过程为:
(1)用于提取可见光和红外光图像的特殊信息,鉴别网络在原本的vgg网络后面加上结构为500-100-2的小型神经网络,初始化鉴别网络时,小型神经网络用截断正态分布随机数初始化,其他参数均使用原本vgg网络训练好的参数作为初始化;
(2)鉴别网络的训练方式为将训练图像库中的数据按照可见光图像和红外光图像分为两类,将训练图像输入鉴别网络得到实际输出
在设置完成迭代次数和优化器参数后,就可以进行鉴别网络训练,训练好的鉴别网络作为一个特定的特征提取器;
(3)训练完成鉴别网络之后,利用该鉴别网络提取可见光图像和红外光图像的最后一层语义一维特征,设该网络提取的最后一层可见光图像和红外光图像的特征集为
特征样本分类完成后再对每个类别重新按照以下公式计算该类别的聚类中心:
通过反复的重复迭代之后得到网络最后一层语义特征集的最终聚类中心,而该聚类中心样本便是该层特征的编码字典
步骤二、稀疏编码特征融合:将所有图像特征构建成完备的特征库,利用无监督的k-means方法在特征库数据上创建一个特征字典,用求解lasso问题的自我学习方法获得待融合的可见光图像和红外光图像特征在该特征字典上的编码,然后利用平均加权的方式融合该编码信息;
在融合两种同一物体的可见光图像和红外光图像时,将两张图像首先分别输入鉴别网络,通过鉴别网络提取可见光图像和红外光图像的语义特征,然后求解以下公式:
将可见光图像和红外光图像的特征带入该公式,得到该特征在特征字典上对应的编码结果;得到两个编码结果后将编码结果按照评价加权求和的方式进行融合,融合后的编码结果将附带两种光照图像的各项信息;最后利用该编码信息和特征字典得到融合特征,该特征将作为深度卷积对抗生成网络dcgan的输入隐变量。
步骤三、生成网络生成图像:创建一个反卷积网络作为模型的生成网络,将步骤二所得的训练图像中的融合编码信息输入生成网络得到融合图像,利用融合图像在鉴别网络中的特征和实际融合编码特征之间的误差调整生成网络的参数;训练完成后,直接将待融合两幅图像的融合编码数据输入生成网络,便可生成同一物体的双光融合图像。
所述的生成网络图像的方法为:首先构造一个16层的反卷积网络,该反卷积网络的输入维度为100,与鉴别网络的最后一层神经网络的神经元维度相同,反卷积网络的输出维度与鉴别网络的输入图像尺寸相同;构造完成深度卷积对抗生成网络dcgan后将融合编码特征输入深度卷积对抗生成网络dcgan将得到一张生成图像,该生成图像通过鉴别网络提取特征,鉴别网络逐层将所提取生成图像的特征:记生成图像第l层的特征为
来调节生成网络的参数;该误差函数保证了生成图像在像素级别和特征级别上均近似于可见光图像和红外光图像;利用该误差函数反复迭代调整生成模型的参数,训练完成之后将融合特征输入深度卷积对抗生成网络dcgan时就可以自动生成双光融合图像。
本发明提出的融合模型训练完成之后就可以直接进行线上融合,不需要重复训练,且本发明利用特征编码字典的方式,使得不同图像在融合时能自动匹配对应的特征。另外得益于深度学习模型超强的语义学习能力,本模型可以做到对可见光和红外光图像在像素级别和特征级别均进行融合,使得最终的双光融合图像融合效果远优于传统的融合模型。本发明所述的模型在训练结束后可随时调用,同时输入可见光和红外光图像便可自动生成融合质量较高的双光图像,减轻了传统融合双光图像所需要具备的硬件压力。
- 还没有人留言评论。精彩留言会获得点赞!