一种基于RNN的电网科研热点预测与推送方法与流程
本发明涉及一种基于rnn的电网科研热点预测与推送系统及其实现方法。
背景技术:
科技情报对国家、社会、企业的战略、计划的制定以及实施都发挥了重要作用。科研热点预测是科技情报领域较新的应用需求。科研工作者、科研项目管理者在选题、立项必须有一定的前瞻性,即立足于当前科学技术现状与社会发展情况,对未来可能产生的新理论或者产生应用价值的新技术做出判断。
目前科研热点预测的方法严重依赖于本领域高级专业人员通过文献查阅与市场调研的方法确定热点出现的方向,另外,当一个新的理论与技术诞生后,其关联应用领域还需要大量的工作去发掘。因此,亟需设计一种科研热点预测与推送系统,可以对未来一段时间内的科学研究热点预测出来,并将其推送到科研用户,辅助科研工作者及科研项目管理者的工作,尤其是电网领域,其革新速度以及采用新技术的领域较多,因而需要及时准确的把握当前以及未来的科研热点极为重要,可以使电网科研工作得到正确的方向。
技术实现要素:
针对上述问题,本发明提出了一种基于rnn的电网科研热点预测与推送方法,该方法使得用户可以及时地获得未来一段时间电网科研热点关键词,并进行精确的预测和实时推送。
为了实现上述目的,本发明采用如下技术方案:
一种基于rnn的电网科技热点预测与推送方法,其特征在于包括以下步骤:
一.热点预测模型
利用过去一段时间内出现的科技新闻网站、文献数据库,并通过数据爬取模块、特征表示模块、基于深度玻尔兹曼机的特征抽取模块和基于rnn的模型训练模块形成热点预测模型;
二.电网科技热点预测与推送
a)采集t个周期电网科技文章,经过提取电网文章tf-idf向量、套用上述热点预测模型,得出科研热点关键词;
b)对自然语言语料库中的电网科技词汇聚类,并在聚类过程中生成科技词汇的关联度;
c)根据预测出的电网科技热点关键词与科技词汇关联度程度生成系列电网科技热点,并推送给用户。
热点预测模型包括以下步骤:
1)数据爬取模块,利用爬虫技术在科技新闻网站、文献数据库爬取电网科技信息文章,将爬取的文章文本化,设一段时间内抓取的科技信息文章集合为tt,其中t表示周期序号;
2)特征表示模块,本模块提供一种科技信息及科技论文文本特征表示方法,并对一个周期的文本进行特征表示,为特征抽取模块提供输入,基于权重tf-idf算法获得tt的关键词向量,记为
a2)设tj是tt的一个本文,基于标准tf-idf算法获得tj第i个词汇的tf-idf值,设为
b2)设tj的下载量或阅读量为nj,引用量为mj。那么
3)特征抽取模块,此模块基于深度玻尔兹曼机的对一个周期文本特征提取,为模型训练模块、预测与推荐模块提供数据输入,深度玻尔兹曼机模型结构与参数设置如下:
a3)深度玻尔兹曼机采用三层限制玻尔兹曼机;
b3)第一层为可见单元层,可见单元层为q×b二值矩阵。其中
c3)设vi,j为一个可视层的单元,在t周期内,对于
d3)第二层为隐层,第二层为
第三层为隐层,第三层为
e3)深度玻尔兹曼机采用限制玻尔兹曼机训练方法逐层训练;
f3)设在周期t,基于深度玻尔兹曼机的输出为xt;
4)模型训练模块,热点预测是指预测未来一段时间e后,出现的研究热点,本模块为预测与推荐模块提供预测模型,本模块的热点预测模型是基于rnn结构进行改进的,其结构与训练方法如下:
a4)热点预测模型结构如图3所示,由t周期循环层与3层bp神经网络组成,循环层输入周期数据xt,xt为t周期深度玻尔兹曼机的输出,
u为输入权重,w为循环权重,vl为bp神经网络l对应层的权重。向量
其中st-1为t-1时刻循环层的值,且
向量
ot为最终输出,计算方法为
b4)计算ot的过程中,向前基于以下公式迭代计算:
c4)用e表示模型误差,误差函数为
其中,n表示样本数量,y(n)表示样本n的实际值,o(n)表示样本n的输出值。y(n)与o(n)是词汇向量,设y(n)=[c1,c2,…,ci,…,cm],m为词汇总数量,若第i个词汇为热点关键词,则ci标记为1,其他非热点词汇标记为0,热点词汇可以有多个;设o(n)=[d1,d2,…,di,…,dm],那么y(n)logo(n)用如下公式计算:
y(n)logo(n)=c1logd1+c2logd2+…+cilogdi+…+cmlogdm。
4)模型训练模块中,
d4)再通过误差反向传播方向,用δ表示各层或各循环周期的误差项,各误差项的计算方法如下:
其中,diag[x]表示根据向量x创建一个对角矩阵,
ⅰ)计算误差函数e对任意周期k权重矩阵wk的梯度公式如下:
其中
循环层权重矩阵w的梯度是各个时刻的梯度之和,公式如下:
ⅱ)权重矩阵u的梯度计算公式如下:
其中xk,j表示xk的第j个分量值,
ⅲ)设
权重矩阵vl的梯度计算公式如下:
其中hk-1,j表示hk-1的第j个神经元的输出值。
提取电网文章tf-idf向量中,提供一种电网科技信息及科技论文文本特征表示方法,并对一个周期的文本进行特征表示,为特征抽取模块提供输入,基于权重tf-idf算法获得tt的关键词向量,记为
a1)设tj是tt的一个本文,基于标准tf-idf算法获得tj第i个词汇的tf-idf值,设为
b1)设tj的下载量或阅读量为nj,引用量为mj。那么
在本申请中,tf-idf(termfrequency–inversedocumentfrequency)是一种用于信息检索与数据挖掘的常用加权技术,在此不再详述。上述rnn为循环神经网络,recurrentneuralnetwork,神经网络是一种节点定向连接成环的人工神经网络,这种网络的内部状态可以展示动态时序行为,不同于前馈神经网络的是,rnn可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。限制玻尔兹曼机也可以称之为受限玻尔兹曼机,一种可通过输入数据集学习概率分布的随机生成神经网络,根据任务的不同,受限玻兹曼机可以使用监督学习或无监督学习的方法进行训练,限制玻尔兹曼机训练方法是现有技术,在此不再详述。电网科技词汇聚类中的聚类采用现有技术,如k-means,在此不再详述。
本发明具有以下优点:
1)本发明可以感知未来一段时间内可能出现的电网科技研究热点,为电网科研人员提供研究方向与研究思路;
2)基于电网科研词汇的关联度生成系列科研热点,可以将电网科技热点的相关潜在的技术应用推荐给电网科研工作者。
附图说明
图1是本发明的流程框架图;
图2是本发明中科研热点预测与推送框架图;
图3是本发明中深度玻尔兹曼机的结构图;
图4是本发明中基于rnn的热点预测模型结构图。
具体实施方式
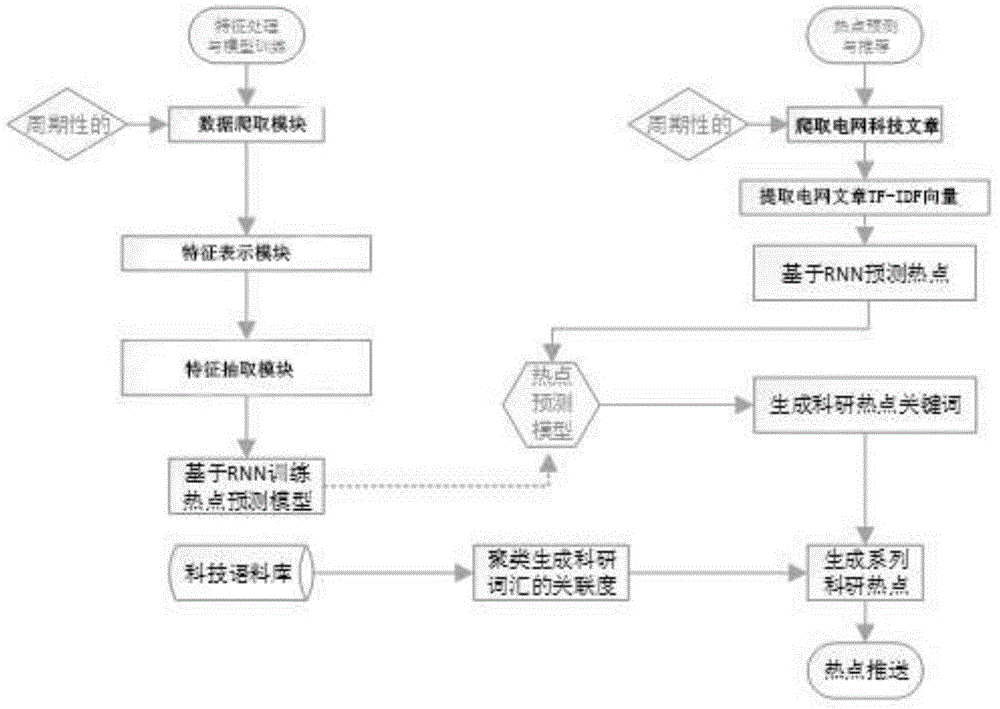
参考图1所示,本发明公开了一种基于rnn的电网科技热点预测与推送方法,本发明包括以下步骤:
一.热点预测模型
参考图2,利用过去一段时间内出现的科技新闻网站、文献数据库,并通过数据爬取模块、特征表示模块、基于深度玻尔兹曼机的特征抽取模块和基于rnn的模型训练模块形成热点预测模型;
二.电网科技热点预测与推送
a)爬取t个周期的电网科技文章,经过提取电网文章tf-idf向量、套用上述热点预测模型,得出科研热点关键词;
b)对自然语言语料库中的电网科技词汇聚类,并在聚类过程中生成科技词汇的关联度;
c)根据预测出的电网科技热点关键词与科技词汇关联度程度生成系列电网科技热点,并推送给用户。
热点预测模型包括以下步骤:
1)数据爬取模块,利用爬虫技术在科技新闻网站、文献数据库爬取电网科技信息文章,将爬取的文章文本化,设一段时间内抓取的科技信息文章集合为tt,其中t表示周期序号;
2)特征表示模块,本模块提供一种科技信息及科技论文文本特征表示方法,并对一个周期的文本进行特征表示,为特征抽取模块提供输入,基于权重tf-idf算法获得tt的关键词向量,记为
a2)设tj是tt的一个本文,基于标准tf-idf算法获得tj第i个词汇的tf-idf值,设为
b2)设tj的下载量或阅读量为nj,引用量为mj。那么
3)特征抽取模块,参考图3所示,此模块基于深度玻尔兹曼机的对一个周期文本特征提取,为模型训练模块、预测与推荐模块提供数据输入,深度玻尔兹曼机模型结构与参数设置如下:
a3)深度玻尔兹曼机采用三层限制玻尔兹曼机;
b3)第一层为可见单元层,可见单元层为q×b二值矩阵。其中
c3)设vi,j为一个可视层的单元,在t周期内,对于
d3)第二层为隐层,第二层为
e3)深度玻尔兹曼机采用限制玻尔兹曼机训练方法逐层训练;
f3)设在周期t,基于深度玻尔兹曼机的输出为xt;
4)模型训练模块,参考图4,图中的粗实箭头线表示向前计算方向,用于计算ot,虚线箭头线表示误差反向传播方向,热点预测是指预测未来一段时间e后,出现的研究热点,本模块为预测与推荐模块提供预测模型,本模块的热点预测模型是基于rnn结构进行改进的,其结构与训练方法如下:
a4)热点预测模型结构如图3所示,由t周期循环层与3层bp神经网络组成,循环层输入周期数据xt,xt为t周期深度玻尔兹曼机的输出,
u为输入权重,w为循环权重,vl为bp神经网络l对应层的权重。向量
其中st-1为t-1时刻循环层的值,且
向量
ot为最终输出,计算方法为
b4)计算ot的过程中,向前基于以下公式迭代计算:
c4)用e表示模型误差,误差函数为
其中,n表示样本数量,y(n)表示样本n的实际值,o(n)表示样本n的输出值。y(n)与o(n)是词汇向量,设y(n)=[c1,c2,…,ci,…,cm],m为词汇总数量,若第i个词汇为热点关键词,则ci标记为1,其他非热点词汇标记为0,热点词汇可以有多个;设o(n)=[d1,d2,…,di,…,dm],那么y(n)logo(n)用如下公式计算:
y(n)logo(n)=c1logd1+c2logd2+…+cilogdi+…+cmlogdm。
在4)模型训练模块中,
d4)再通过误差反向传播方向,用δ表示各层或各循环周期的误差项,各误差项的计算方法如下:
其中,diag[x]表示根据向量x创建一个对角矩阵,
ⅰ)计算误差函数e对任意周期k权重矩阵wk的梯度公式如下:
其中
循环层权重矩阵w的梯度是各个时刻的梯度之和,公式如下:
ⅱ)权重矩阵u的梯度计算公式如下:
其中xk,j表示xk的第j个分量值,
ⅲ)设
权重矩阵vl的梯度计算公式如下:
其中hk-1,j表示hk-1的第j个神经元的输出值。
提取电网文章tf-idf向量中,提供一种电网科技信息及科技论文文本特征表示方法,并对一个周期的文本进行特征表示,为特征抽取模块提供输入,基于权重tf-idf算法获得tt的关键词向量,记为
a1)设tj是tt的一个本文,基于标准tf-idf算法获得tj第i个词汇的tf-idf值,设为
b1)设tj的下载量或阅读量为nj,引用量为mj。那么
上述4)模型训练模块中,基于d4)的误差反向传播公式及误差项公式并通过反向传播神经网络训练算法训练模型,为电网科技热点以及预测提供精确模型。
上述虽然结合附图对本发明的具体实施方式和有效性进行了描述和验证,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!