基于极坐标模糊信息粒的时间序列预测方法、系统及介质与流程
本发明涉及基于极坐标模糊信息粒的时间序列预测方法、系统及介质。
背景技术:
时间序列是指将同一统计变量的数值按照其发生的时间先后顺序排列而成的序列。时间序列的建模和预测一直是研究者广泛研究的经典问题。研究人员早期利用线性系统理论、随机过程理论和黑盒方法开发了许多时间序列的经典数值模型,如arma,arima,ararma,ann(人工神经网络)模型等。时间序列预测已经被广泛的应用到气象学、农业产量、旅游人数及能源等诸多领域,特别是在控制领域和金融市场中有极其重要的意义,但这些模型由于其可解释性低而难以理解。模糊集理论(zadeh,1965)可以用来缓解时间序列模型解释性低的缺点,模糊时间序列的概念最初是由song和chissom提出的,它涉及模糊集理论的形式,可以应对历史数据不完整或模糊的不确定环境下的预测问题,目前已广泛应用于预测入学率,温度等多个领域,具有较好的预测性能。同时模糊推理提供了一种可行的替代方案来确保对固有不确定性的鲁棒性,这也涉及到时间序列的建模。
虽然经典时间序列模型得到了广泛的应用,但是也存在一些不足,例如ar、ma、vecm等均建立在时间序列数据具有线性结构的假设之下,而现实世界中的数据通常具有较强的非线性结构;预测得到的是定量的结果,不易被人们理解;对于模糊或不完整的时间序列,预测偏差较大,等等。考虑到上述方法预测结果语义性不足的问题,具有人类感知和处理抽象实体(而不是数字实体)的能力的时间序列模糊时间序列模型更适用于某些决策问题,对于模糊语义变量的时间序列预测有较好的效果。
信息粒是zadeh于1979年提出的概念,其一般形式为
其中,x是论域u上的取值变量,g是论域u中的凸模糊子集,由隶属度函数来刻画,λ表示值x属于模糊子集g的可能性概率。信息粒度和粒度计算起着根本性的作用,研究者建立基于模糊信息粒的时间序列模型主要包括五个关键步骤:(1)将时间序列的话域划分为一系列区间;(2)根据划分区间定义模糊集;(3)将数字时间序列转换为模糊时间序列,即模糊化时间序列的历史数据;(4)从模糊时间序列挖掘模糊逻辑关系;(5)预测和去模糊输出。
技术实现要素:
为了解决现有技术的不足,本发明提供了基于极坐标模糊信息粒的时间序列预测方法、系统及介质;
作为本发明的第一方面,提供了基于极坐标模糊信息粒的时间序列预测方法;
基于极坐标模糊信息粒的时间序列预测方法,包括:
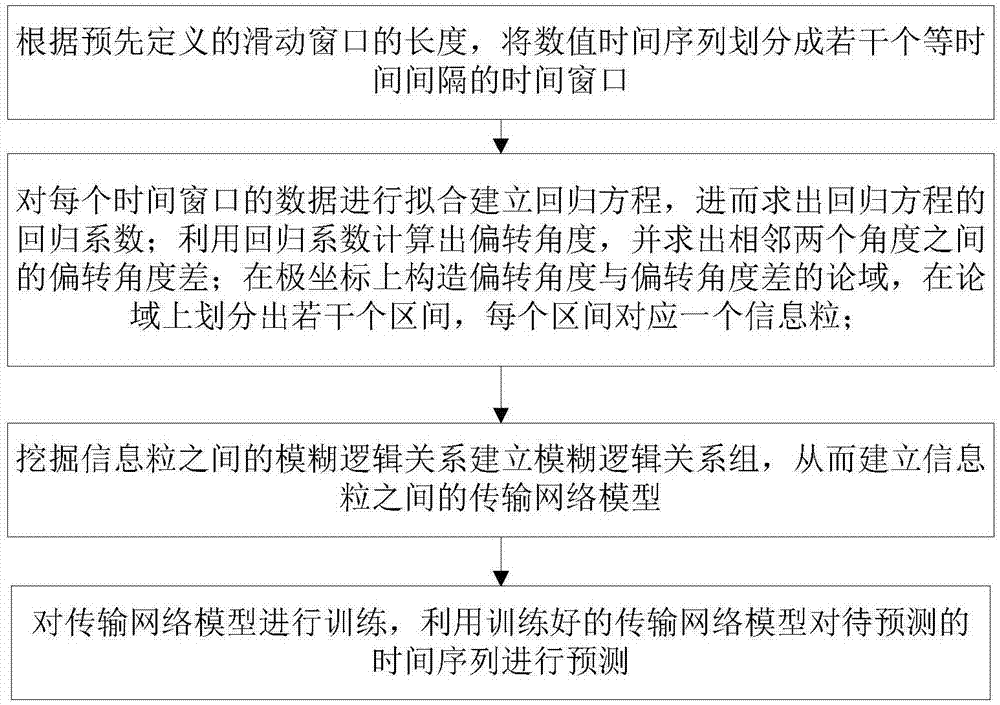
步骤(1):根据预先定义的滑动窗口的长度,将数值时间序列划分成若干个等时间间隔的时间窗口;
步骤(2):对每个时间窗口的数据进行拟合建立回归方程,进而求出回归方程的回归系数;所述回归系数包括:斜率和截距;利用回归系数计算出偏转角度,并求出相邻两个角度之间的偏转角度差;确定偏转角和偏转角度差的最值;在极坐标上构造偏转角度与偏转角度差的论域,在论域上划分出若干个区间,每个区间被定义为一个信息粒,不同的区间定义出不同名称的信息粒;
步骤(3):挖掘信息粒之间的模糊逻辑关系建立模糊逻辑关系组,从而建立信息粒之间的传输网络模型;
步骤(4):对传输网络模型进行训练,利用训练好的传输网络模型对待预测的时间序列进行预测。
进一步的,对每个时间窗口的数据进行拟合建立回归方程的步骤为:
pti=ait+bi,
其中,pti表示第i个时间窗口的回归方程,ai和bi是第i个时间窗口的回归方程的回归系数;ai是回归方程的斜率,bi是回归方程的截距。
测量每个时间窗口回归方程的回归系数ai和bi,从而求得回归系数ai和bi的集合{[a1,b1],[a2,b2],...[αi,bi],...[am,bm]};am和bm是第m个时间窗口的回归方程的回归系数;
进一步的,利用回归系数计算出偏转角度的步骤为:
根据第i个时间窗口的回归方程的回归系数ai求得对应的偏转角度αi:
αi=arctan(ai);
进一步的,求出相邻两个角度之间的偏转角度差的步骤为:
δαi=αi+1-αi;
则每个时间窗口都对应一组参数αi和δαi;从而,得到
集合a={[α1,δα1],[α2,δα2],...[αi,δαi],...[αm,δαm]}。
αi指的是曲线相对于横轴的偏转角,后面将其转化为极坐标系上的极角;δαi是相邻偏转角之间的差值,后面将其转化为极坐标系上的极半径°
进一步的,在极坐标系上构造偏转角度与偏转角度差的论域,在论域上划分出若干个区间的步骤为:
得到集合a={[α1,δα1],[α2,δα2],...[αi,δαi],...[αm,δαm]};将集合a分为数据拟合偏转角集合ai={α1,α2,...,αn}和偏转角的变化情况集合δai={δα1,δα2,...δαn}两个集合,基于数据拟合偏转角集合ai和偏转角的变化情况集合δai构建论域,构建论域过程中将偏转角视为极坐标系上的极角,将偏转角的变化视为极坐标系上的极半径,从而在极坐标系上构建论域;
定义偏转角和偏转角度差的最值
aimin=min{α1,α2,...,αn};
aimax=max{α1,α2,...,αn};
δaimin=min{δα1,δα2,...δαn};
δaimax=max{δα1,δα2,...δαn};
其中,aimin表示时间序列拟合的偏转角度振幅的最小值,aimax表示时间序列拟合的偏转角度振幅的最大值;δaimin表示偏转角度差值的最小值,δaimax表示偏转角度差值的最大值;
u=[u1,u2]表示偏转角度的值域,
u=[u1,u2]=[aimin-l1,aimax+l2];
其中,l1和l2是修剪因子trimfactor,
r=[r1,r2]表示偏转角度差的值域,
r=[r1,r2]=[rimim-m1,rimax+m2];
其中m1和m2是修剪因子trimfactor,
在极坐标上表示拟合后的数据信息,其中,极角θ的取值是由回归方程的斜率对应的偏转角度确定的,极半径ρ为相邻极角之差,根据极角和极半径的取值范围,在极坐标上建立扇形论域;
根据提前设定的划分数目h对论域进行横向划分,根据设定的划分数目i对论域进行纵向划分;其中,h≥2,i≥2,最后将论域划分成h×i的区间,每个区间被定义为一个信息粒。
进一步的,对新的论域进行划分的步骤为:
根据偏转角的幅度,使用横向分割点s=[p1,p2,...,ph-1]进行划分,则l1=[u1,p1],l2=[p1,p2],...,lj=[pj-1,pj],...,lh=[ph-1,u2],同理,使用纵向分割点t=[h1,h2,...,hi-1]进行划分,则t1=[r1,h1],t2=[h1,h2],...,tj=[hj-1,hj],...th=[hi-1,r2]。
进一步的,步骤(3)的具体步骤为:
假设颗粒时间序列由n个信息粒a1,a2,...,an组成,预测第n+1个信息粒an+1;
一阶模糊逻辑关系:ai,ai+1为时间序列上两个连续观测到的颗粒,则他们之间的关系用一个模糊逻辑关系表示,记作ai→ai+1.其中,ai称为模糊逻辑关系的左件,ai+1称为模糊逻辑关系的右件;
二阶模糊逻辑关系:ai-1,ai,ai+1为时间序列上三个连续观测到的颗粒,则他们之间的关系用一个模糊逻辑关系表示,记作ai-1,ai→ai+1;
三阶模糊逻辑关系:ai-2,ai-1,ai,ai+1为时间序列上四个连续观测到的颗粒,则他们之间的关系用一个模糊逻辑关系表示,记作ai-2,ai-1,ai→ai+1;
步骤31:根据一阶模糊逻辑关系,首先判断观测序列an′对应的信息粒an在模糊逻辑关系中的后件是否是唯一值,如果是唯一的,则可直接预测an+1;
否则,根据二阶模糊逻辑关系判断观测序列an-1′,,an′对应的信息粒an-1,an在二阶模糊逻辑关系中对应的后件是否为唯一值,如果是唯一值,则直接预测an+1;
否则,根据三阶模糊逻辑关系判断信息粒an-2,an-1,an在三阶模糊逻辑关系中对应的后件是否为唯一值,如果是唯一的,则直接预测an+1,否则进入步骤32;
步骤32:判断观测序列an-2′对应的信息粒an-2在扇形论域中的位置,
如果an-2位于论域的最左侧边缘或者最右侧边缘,则要找到信息粒包含自己在内的4个信息粒;
如果an-2位于论域的最上侧边缘或者最下侧边缘,则要找到信息粒包含自己在内的6个信息粒;
如果an-2位于论域的中间部分,则要找到信息粒包含自己在内的9个信息粒;
同样的操作分别确定观测序列an-1′和an′对应的信息粒an-1和an在扇形论域中的位置;
步骤33:求出观测序列an-2′与周围信息粒的隶属度f(x;μ,y,ν,σ),并取出隶属度最大的两个信息粒,记作{a1,a2};同理,依次求出观测序列an-1′与周围信息粒的隶属度,并取出隶属度最大的两个信息粒,记作{b1,b2};观测序列an′与周围信息粒的隶属度,并取出隶属度最大的两个信息粒,记作{c1,c2};
步骤34:依次分别从{a1,a2},{b1,b2},{c1,c2}中取出一个信息粒,进行排列组合,一共有八种组合方式,分别是{a1,b1,c1}、{a1,b2,c1}、{a1,b1,c2}、{a1,b2,c2}、{a2,b1,c1}、{a2,b2,c1}、{a2,b1,c2}、{a2,b1,c1};在三阶模糊逻辑关系中,计算八种组合出现的概率并找到每种组合对应的后件,如果某一种组合在三阶模糊逻辑关系中不存在便舍弃,对剩余的组合进行归一化处理;
步骤35:取出出现概率最大的组合,并求出组合与后件中每个信息粒之间的传递频率,记作权重ω
an+1是预测得到的an+1′中权重最大的信息粒;
其中,权值向量(ω1,ω2,...,ωn-3)与匹配程度[ω′1,ω′2,...,ω′n-3]呈成比例关系,被定义为如下形式:
其中,ω′i是观测序列(a‘n-2,a‘n-1,a‘n)和第i条规则的前因变量(ai,ai+1,ai+2)的匹配程度,i=1,2,...,n-3.
定义α(ai,aj)是ai和aj匹配程度的度量;α(ai,aj)表示为
其中权重指数m>1被称为模糊指数;模糊化系数m设为2。
观测序列(a‘n-2,a‘n-1,a‘n)和rulei的前因变量(ai,ai+1,ai+2)的匹配程度被表示为
复平面上两点ai=(α1,δα1)与aj=(α2,δα2)间的欧氏距离:
将不同类型的信息粒定义为传输网络模型的节点,节点的大小反映同一名称信息粒出现的次数,并将信息粒的传输定义为边缘,边缘的权重是两种名称的信息粒之间的传递频率,从而建立信息粒之间的传输网络模型。
进一步的,根据公式(2)求出观测序列an-2′与周围信息粒的隶属度f(x;μ,y,v,σ):
y(t)=kt+b,k≠0(3)
其中,k表示回归线的斜率,b表示回归线的截距,μ表示斜率在平面中对应的角度,y表示相邻角度之间的角度之差,σ表示标准差;
进一步的,步骤(4)的具体步骤为:
aforecast(t+1)=forecast(a(t),a(t-1),a(t-2))
预测集的数据作为测试数据,用来计算预测精度,表示为aforecasted(nt+i),i=1,2,...,nf。通过上式得到
aforecast(nt+1)=forecast(a(nt),a(nt-1),a(nt-2)),
aforecast(nt+2)=forecast(a(nt+1),a(nt),a(nt-1)),
aforecast(nt+nf)=forecast(a(nt+nf-1),a(nt+nf-2),a(nt+nf-3)),
预测出的信息粒包含了所预测的下一阶段数据的变化范围、变化趋势。
其中,aforecast(t+1)表示预测的t+1时刻的信息粒;a(t)表示t时刻的信息粒;a(t-1)表示t-1时刻的信息粒;a(t-2)表示t-2时刻的信息粒;aforecast(nt+1)表示预测的nt+1时刻的信息粒;a(nt)表示nt时刻的信息粒;a(nt-1)表示nt-1时刻的信息粒;a(nt-2)表示nt-2时刻的信息粒;aforecast(nt+nf)表示预测的nt+nf时刻的信息粒;a(nt+nf-1)表示nt+nf-1时刻的信息粒;a(nt+nf-2)表示nt+nf-2时刻的信息粒;a(nt+nf-3)表示nt+nf-3时刻的信息粒。
作为本发明的第二方面,提供了基于极坐标模糊信息粒的时间序列预测系统;
基于极坐标模糊信息粒的时间序列预测系统,包括:存储器、处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
作为本发明的第三方面,提供了一种计算机可读存储介质;
一种计算机可读存储介质,其上存储有计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
与现有技术相比,本发明的有益效果是:
本发明提出了一种基于滑动窗口思想等长划分数据,建立回归方程并在极坐标上划分信息粒的方法。这种方法的优势在于不仅考虑数据数值的变化而且考虑变化趋势的快慢,提高数据模糊化以后的可解释性和预测精度,能够弥补均匀划分论域、不重叠非等分划分论域和以人的生活经验划分论域所产生的预测精确度较低、语义信息较少的问题,同时弥补了使用优化算法(如粒子群算法、遗传算法、蝙蝠算法等)划分论域的不可解释性的不足,充分发挥了模糊理论在解决时间序列预测问题中的优势。
本发明中我们建立了一个扇形信息粒,与区间模糊信息粒不同的是,它的论域不是原始数值而是经过线性拟合转化为极坐标上相应的极角和极半径,它的区间不再是大小相同的区间,而呈随角度变化的带状,即区间大小由内向外依次增大。纵向观察可以发现在相同时间内数据波动幅度,横向观察可以直观反映波动速度的快慢。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1为本发明的流程图;
图2为数值型时间序列;
图3为使用滑动窗口划分时间序列;
图4为极坐标上扇形模糊信息粒示意图;
图5为基于扇形模糊信息粒的推理模型;
图6为定义回归模式的过程;
图7为基于加权平均的滑动窗口模糊推理机制;
图8为模糊信息粒间的传输网络图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本发明使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,我们首先定义滑动窗口的长度并将数值时间序列划分成若干时间间隔形同的时间窗口,通过对每个时间窗内的数据进行拟合,求出回归方程的斜率,并求出曲线相对于横轴的偏转角和相邻曲线之间的偏转角度差。在极坐标上表示时间序列,极角为平面直角坐标系上的求得的偏转角,极半径为偏转角度差,因此可以在极坐标上构造新的论域,划分区间建立信息粒。通过挖掘信息粒间的模糊关系,建立模糊关系组和传输网络,对传输网络进行训练,用训练好的模型对时间序列进行预测。
如图2所示,传统时间序列是基于数值起伏变化的。
如图3所示,使用滑动窗口划分目标时间序列,保留数据之间的内在规律和传输特性。
如图4所示,我们在极坐标上表示拟合后的数据信息,其中,极角θ的取值是由回归方程的斜率对应的偏转角度确定的,极半径ρ为相邻极角之差,根据极角和极半径的取值范围,在极坐标上建立扇形论域。在极坐标上构造新的论域,划分区间,根据时间序列的数据及其相应的变化(趋势)构造扇形模糊信息粒。
如图5所示,基于模糊信息粒的模糊关系建立的预测模型,三个输入,一个输出。
如图6所示,预先定义滑动窗口的数目以及每个窗口包含的数据量并对滑动窗口数据进行拟合建立回归方程,求出斜率和截距,并求出曲线相对于横轴的偏转角和相邻曲线之间的偏转角度差。
如图7所示,在实验中我们认为信息粒an+1与历史颗粒数据a1,a2,...an有关,因此在预测信息粒an+1时运用基于加权平均的模糊推理机制进行解释。在这种假设的基础上,利用建立的模糊逻辑关系进行预测。模糊预测机可以被认为是由一系列条件判断规则构建的。在实际生活中,一些数据在理论上将是无穷无尽的,因此将会使用大量的规则,从而增加算法复杂度和预测精度,并且相邻时间数据对接下来的数据的预测会带来一定的影响。因此,在我们的模糊推理机制中引入滑动时间窗口。模糊推理机制使用信息粒时间序列而不是直接使用原始数据进行预测,所以最后输出的将是一个考虑多步时间范畴的信息颗粒
如图8所示,时间序列中存在多种信息粒,信息粒之间相互传递形成模糊关系,因此,将不同类型的信息粒定义为传输网络模型的节点,节点的大小反映同一名称信息粒出现的次数,并将信息粒的传输定义为边缘,边缘的权重是两种名称的信息粒之间的传输频率。
1.1模糊时间序列
模糊时间序列的定义最初是由song和chissom(1993,1993,1994)提出的,设u={u1,u2,...,un}为论域,用论域中的元素ui与其隶属度fa(ui)对模糊集a进行表示:
其中fa是模糊集a的隶属函数,fa:u→[0,1],fa(ui)(1≤i≤n)是ui在模糊集a中的隶属度,
定义1:模糊时间序列.r1的子集y(t)(t=...,0,1,2,...)为定义在模糊集fi(t)(i=1,2,...)上的论域,如果f(t)是f1(t),f2(t)的集合,则f(t)可以称作定义在y(t)上的一个模糊时间序列.
根据定义1发现,传统的时间序列与模糊时间序列最大的不同是,模糊时间序列的值是模糊集,即语言学描述,而传统的时间序列的值为真实的数字。f(t)可以看作一个语言变量而fi(t)看作f(t)的可能的语言变量值.(regardas/viewaspossiblelinguisticvalueof)用模糊集表示fi(t)(i=1,2,...)。
值得注意的是,在不同的时间f(t)的值不同,即f(t)与时间t有关。如果f(t)只由f(t-1)确定,则它们之间存在一种模糊逻辑关系,其中f(t-1)表示模糊逻辑关系的前件,f(t)为模糊逻辑关系的后件。
2.预测模型
对时间序列进行建模和预测是一个被广泛研究的经典问题,经过长时间的探索,研究者建立了许多数值型时间序列模型,广泛使用在各个领域并在数值水平上取得了较好的预测效果,但由于这些模型在语义上解释性低所以模型很难被理解,而模糊集理论可以弥补这一缺点,基于模糊集理论,song和chissom为解决历史数据为语义值的时间序列的预测问题最早提出了模糊时间序列的概念。他们建立了两种时间序列模型——时变模型和时不变模型并预测阿达巴马大学的入学人数,而且提出了一套预测模糊时间序列的方法模型,主要包括五个步骤:(1)划分时间序列的论域为区间的集合,(2)根据划分区间定义模糊集,(3)将数字时间序列转化为模糊时间序列,即,模糊化时间序列的历史数据,实现数值到语义的转换(4)建立模糊逻辑关系(miningfuzzyrelationshipsfromfuzzytimeseries),(5)预测和去模糊化输出。
虽然song最早提出了模糊时间序列模型,但由于提出的模型计算复杂度较高,所以大部分的模糊时间序列模型都是以chen的模型为基础,chen提出的模型将建模过程分为四个关键步骤:(1)根据时间序列观测数据确定论域,并对其进行划分,(2)定义论域上的模糊集,然后将观测数据模糊化,(3)建立模糊逻辑关系和模糊逻辑关系群,(4)利用模糊关系进行预测。
根据模糊时间序列建立模型的一般步骤并且结合实际情况,本发明所提出的建立时间序列模型的步骤如下:
setp1:使用滑动窗口划分目标时间序列;
setp2:模糊化观测数据,构造信息粒;
step3:构建模糊预测系统(即建立模糊逻辑关系);
step4:预测信息粒;
2.1.划分目标时间序列
实际上,信息粒是以人的感知为基础,基于事物的主要特征建立的,是一种抽象的过程,而抽象的级别与信息粒度有关,换句话说,信息粒度能够帮助我们重点关注关键特征,尽可能的忽略那些增加计算复杂度的特征,简言之,信息粒可以根据数据的潜在语义使用区间集、模糊集、阴影集等一些精确表示方法对数据进行表示,但使用只包含数据振幅的模糊集比如“热”“非常冷”表示这些数据是不合适的,如果一个信息粒既包含某一时间内数据值范围又能反映数据的变化速度快慢就更加合理。
论域的划分对时间序列预测的结果有着重要的影响,同一个时间序列采用不同的论域划分方法将产生不同的预测结果,因此在此之前研究者进行大量实验就划分论域这一问题进行研究,不断优化预测模型,我们发现时间序列本身的数据能够反映数据的分布密度而变化趋势可以反映数据的波动。我们在建立模糊信息粒的时间序列模型时,不仅要考虑建立的模型的算法复杂度、预测精度和可解释性的问题还需要考虑建立的信息粒能否既反映数值又能体现数值的变化速率,这些问题很难做到均衡,比如论域的划分需要满足两个潜在(underlying)的要求:1.划分的区间能够客观合理的反映数据的分布特点;2.划分的语义较好。因此我们提出一种新的划分方法,预先定义滑动窗口的长度,对每个时间窗口的数据进行拟合求回归方程及其系数。其中,斜率,亦称″角系数″,表示一条直线相对于横轴的倾斜程度系数,是曲线关于(横)坐标轴倾斜程度的量。在极坐标上构造新的论域,划分区间,根据时间序列的数据及其相应的变化(趋势)构建信息粒,可以保证基于数值的模糊信息粒之间数据的记忆性和传输特性。
虽然如此,合理划分观测数据(选取合适的信息粒度)也是必不可少的,时间窗口的长度不仅可以影响信息粒的数目还会影响主要回归模式(信息粒)的确定。信息粒度的概念是由zadeh于1979年首次提出。一个数据集的信息粒,简单的概括即合理的信息粒度和恰当的语义解释。信息粒度通过计算落入信息粒数据进行判断,对于第一个要求,落入信息粒的数据越多越好。而对于第二个要求落入信息粒的数据越少语义越明确。综上所述,上述两个要求是矛盾的。在本发明中通过选择合适的区间长度,优化信息粒度,使得信息粒包含数据的数目恰当合理在此基础上就信息粒的长度对信息粒数目、主要信息粒类型和传输网络的影响展开讨论。
处理数值数据建立信息粒过程分为三个步骤:
step1:考虑给定时间序列的长度,确定时间窗口ω的长度。滑动窗口的长度ω可以根据需求进行设定,非常灵活。针对不同时间长度的时间序列,我们可以设定ω的值也不同,当数据量较大时,可以将时间窗口长度设置大一些,如果数据量较小,可以将时间窗口长度设置小一些,从而进一步对每个时间窗口进行量化。
step2:建立回归方程。对每个时间窗口建立一个回归方程。第i个时间窗口的回归方程可以表示为pti=ait+bi,其中pti表示第i个时间窗口的价格,ai和bi是回归方程的参数,
首先,测量每个时间窗口回归方程的参数ai和bi,由此可以求得参数ai和bi的集合{[a1,b1],[a2,b2],...[ai,b],...[am,bm]},然后根据每个时间窗口的参数ai求得对应的偏转角度αi,并且相邻两个时间窗口做差值可以求得偏转角度差δαi=αi+1-αi,则每个时间窗口都对应一组参数αi和δαi,进一步可以得到集合a={[α1,δα1],[α2,δα2],...[αi,δαi],...[αm,δαm]}。
αi表示将一段时间内的数据进行拟合求出斜率并进一步求出的偏转角,而δαi反映数据值在相邻等长度时间窗口上变化角度,在此基础上在极坐标上划分论域并建立扇形模糊信息粒
step3:划分论域和构造信息粒
step3.1:考虑到在骤2中,我们得到集合a={[α1,δα1],[α2,δα2],...[αi,δαi],...[αm,δαm]},现将集合a分为ai={α1,α2,...,αn}和δai={δα1,δα2,...δαn}两个集合,我们分别定义aimin=min{α1,α2,...,αn}和aimax=max{α1,α2,...,αn},δaimin=min{δα1,δα2,...δαn}和δaimax=max{δα1,δα2,...δαn},aimin和aimax分别表示时间序列拟合的偏转角度振幅的最小值和最大值。u=[u1,u2]表示偏转角度的值域,u=[u1,u2]=[aimin-l1,aimax+l2],其中l1,l2是修剪因子(trimfactors),同理δaimin和δaimax分别表示偏转角度差值的最小值和最大值。r=[r1,r2]表示偏转角度差的值域,r=[ri,r2]=[rimin-m1,rimax+m2],其中m1,m2是修剪因子(trimfactors),根据提前设定的划分数目h和i(h≥2,i≥2)分别横向与纵向划分论域,根据下面的步骤,如图4所示,我们将论域划分成h×i不等大小的区间。
step3.2:我们在极坐标上表示拟合后的数据信息,其中,极角θ的取值是由回归方程的斜率对应的偏转角度确定的,极半径ρ为相邻极角之差,根据极角和极半径的取值范围,在极坐标上建立扇形论域。
step3.3:划分论域,决定区间长度。根据偏转角的幅度,横向我们找到分割点s=[p1,p2,...,ph-1],则l1=[u1,p1],l2=[p1,p2],...,lj=[pj-1,pj],...,lh=[ph-1,u2],同理,纵向我们找到分割点t=[h1,h2,...,hi-1],则t1=[r1,h1],t2=[h1,h2],...,tj=[hj-1,hj],...th=[hi-1,r2].
值得注意的是,上述划分论域的方法是在极坐标上实现的。
2.2模糊化观测数据,构造信息粒
本发明提出了一种新型模糊信息粒,称为扇形模糊信息粒(英文缩写fsfig)。在设计这样的信息颗粒时,我们采用以弧状区间为核心的模糊信息粒的形式来表达趋势信息,同时以高斯分布计算隶属度。
definition.a扇形模糊信息粒
y(t)=kt+b(k≠0)(3)
其中k,b分别代表回归线的斜率和截距,μ表示斜率在平面中对应的角度,v表示相邻角度之间的角度之差,标准差σ决定了分布的密度,核心线y(t)=kt+b(k≠0)反映了当前时间区间内的线性变化趋势。通过将斜率转化为平面上对应的角度并进一步得到相邻角度之差,能够反映数据内在的波动起伏变化,标准差σ反映了数据与回归线μ(t)的离散程度,σ越大,代表该信息粒有越大的离散程度。
本发明中我们建立了一个扇形信息粒,与区间模糊信息粒不同的是,它的论域不是原始数值而是经过线性拟合转化为极坐标上相应的极角和极半径,它的区间不再是大小相同的区间,而呈随角度变化的带状,即区间大小由内向外依次增大。纵向观察可以发现在相同时间内数据波动幅度,横向观察可以直观反映波动速度的快慢。
确定扇形模糊信息粒共需7个参数,即k、b、σ、m、
xt=kt+b+∈(4)
其中,∈~n(0,σ2)。由此,我们得到参数k、b和σ。而m和
总的来说,扇形模糊信息粒在常见的区间信息粒的基础上做了进一步的改进,能够同时表示数据波动变化范围和波动变化速度,数据集的变化趋势(viak)以及数据波动(离散)情况(viaσ),较好的解决了我们提出的亟待解决的两个问题,是较为理想的信息粒形式。
2.3.构建模糊预测系统long-termpredictionwithfuzzyinferencesystem(fis)basedonweightedaverage
假设我们的颗粒时间序列由n个信息粒a1,a2,...,an组成,通过基于权重的模糊推理预测系统预测点n+1个信息粒an+1,在此研究背景下,这样的映射能够反映输入和输出信息粒之间的关系。我们使用信息粒时间序列而不是直接使用原始数据进行预测,这样做的好处在于,输出将是一个考虑多步时间范畴的信息颗粒(agranuleconcerningmulti-steptimehorizon).若使用像arima、svr的数字化模型预测相同数量的数值,需要对单步预测(one-stepprediction)结果进行一系列的迭代。由于不可避免的误差,将导致预测偏差连续累积,若预测范畴较大,预测结果将不再精确。
在实验中我们认为信息粒an+1与历史颗粒数据a1,a2,...,an有关,因此在预测信息粒an+1时运用基于加权平均的模糊推理机制进行解释。在这种假设的基础上,利用建立的模糊逻辑关系进行预测。在本发明中,为了使预测更准确更有说服力,我们建立了不同阶次的模糊逻辑关系,并分别对一阶、二阶和三阶的模糊逻辑关系进行如下定义,
定义a:ai,ai+1为时间序列上两个连续观测到的颗粒,则他们之间的关系可以用一个模糊逻辑关系表示,记作ai→ai+1.其中,ai称为模糊逻辑关系的左件(简称左件),ai+1称为模糊逻辑关系的右件(简称右件)
定义b:ai-1ai,ai+1为时间序列上三个连续观测到的颗粒,则他们之间的关系可以用一个模糊逻辑关系表示,记作ai-1,ai→ai-1.
定义c:ai-2,ai-1,ai,ai+1为时间序列上四个连续观测到的颗粒,则他们之间的关系可以用一个模糊逻辑关系表示,记作ai-2,ai-1,ai→ai+1.
模糊预测机可以被认为是由一系列条件判断规则构建的。如果规则的条件被满足,则可以认为对应的结果在一定程度上是正确的。对于一阶模糊逻辑关系,某些预测信息粒an+1′可以唯一确定,若无法满足唯一确定的条件可以判断根据二阶模糊逻辑关系确定an+1′,否则运用三阶模糊逻辑关系,目标预测信息粒an+1′可以由三个连续的历史信息粒an-2′,an-1′,an′通过算法确定。
模糊逻辑规则为:
根据定义c,这种(ensuing)逻辑关系的思想可以被简单的(schematically)表示成
at-2,at-1,at→at+1
这表示在t时刻进行t+1时刻的信息粒的预测。
我们注意到,规则条数随输入信息粒数目的增加而增加。若有n个信息粒输入,需要构造n-2条规则。在实际生活中,一些数据在理论上将是无穷无尽的,随时间源源不断的产生,因此将会使用大量的规则,从而增加算法复杂度和预测精度,并且某些数据往往呈现周期性阶段性的特点,相邻时间数据对接下来的数据的预测会带来一定的影响。因此,在我们的模糊推理机制中引入滑动时间窗口。由于我们建立的模糊逻辑关系后件并非是唯一值,比如,f8,f7.e7→f7,f8,g8,d6,e6,e7,g9,j10,d7,c6,h9,但前一个时间窗口到后一个时间窗口输出的信息粒由不同的权重,这就涉及到隶属度的计算。三个输入,单个输出,(n-3)条规则的基本结构在图7中展示。
模糊预测机的输入形式是颗粒序列的训练集的最后三个颗粒,即a‘n-2=an-2,a‘n-1=an-1,a‘n=an.对于模糊规则rulei(i=1,2,...,n-3),如果使前提
a‘n-2isan-2,
a‘n-1isan-1,
a‘nisan
保证一定程度的可信度(可靠性)(即发射强度,thefiringstrength)(istruetoacertaindegree),即观测序列(a‘n-2,a‘n-1,a‘n)和前因变量(antecedents)(ai,ai+1,ai+2)存在一定的匹配程度,记作
ω‘i=ω‘i(ai,ai+1,ai+2;an-2,an-1,an)
那么此前提对应的结论”an+1isai+3“也有相同的可信度。根据建立的三阶模糊逻辑关系,分别计算前因变量(antecedents)(ai,ai+1,ai+2)对应的观测序列(a‘n-2,a‘n-1,a‘n)及周围信息粒之间的隶属度,从而进行预测,提高预测信息粒的准确率。下面讲具体阐述使用模糊逻辑关系建立的模糊规则推理的步骤:
步骤1:根据一阶模糊逻辑关系组,首先判断观测序列an′对应的信息粒an在模糊逻辑关系组中的后件是否是唯一值,如果是唯一的,则可直接预测an+1,否则,根据二阶模糊逻辑关系组判断观测序列an-1′,,an′对应的信息粒an-1,an在二阶模糊逻辑关系组中对应的后件是否为唯一值,如果是唯一值,则可以直接预测an+1,否则,根据三阶模糊逻辑关系组判断信息粒an-2,an-1,an在模糊逻辑关系组中对应的后件是否为唯一值,如果是唯一的,则可直接预测an+1,否则进行步骤2;
步骤2:判断观测序列an-2′对应的信息粒an-2在扇形论域中的位置,如果an-2位于论域的最左侧或者最右侧边缘部分,比如图4中的{a0,a11,l0,l11},则需要找到信息粒包含自己在内的4个信息粒;如果an-2位于论域的最上侧或者最下侧边缘部分,比如图4中的{b0,c0,d0,e0,f0,g0,h0,i0,j0,k0};{l1,l2,l3,l4,l5,l6,l7,l8,l9,l10};{b11,c11,d11,e11,f11,g11,h11,i11,j11,k11},则需要找到信息粒包含自己在内的6个信息粒;如果如果an-2位于论域的中间部分,比如图4中的{b1,c1,d1,e1,f1,g1,h1,i1,j1,k1},则需要找到信息粒包含自己在内的9个信息粒.同样的操作分别确定观测序列an-1′和an′对应的信息粒an-1和an在扇形论域中的位置;
步骤3:根据公式(2)求出观测序列an-2′与周围信息粒的隶属度,并取出隶属度最大的两个信息粒,记作{a1,a2},同理,依次求出观测序列an-1′与周围信息粒的隶属度,观测序列an′与周围信息粒的隶属度,并取出隶属度最大的两个信息粒,分别记作{b1,b2}、{c1,c2}.
步骤4:由步骤3可知,共取出6个信息粒,依次分别从{a1,a2},{b1,b2},{c1,c2}中取出一个信息粒,进行排列组合,一共有八种组合方式,分别是{a1,b1,c1}、{a1,b2,c1}、{a1,b1,c2}、{a1,b2,c2}、{a2,b1,c1}、{a2,b2,c1}、{a2,b1,c2}、{a2,b1,c1}在三阶模糊逻辑关系组中,计算八种组合出现的概率并找到每种组合对应的后件,如果某一种组合在三阶模糊逻辑关系组中不存在便舍弃,对剩余的组合进行归一化处理。
步骤5:经过步骤4的处理,取出出现概率最大的组合并求出组合与后件中每个信息粒之间的传递概率,记作权重ωij
an+1是预测得到的an+1′中权重最大的信息粒
其中,权值向量(ω1,ω2,...,ωn-3)与匹配程度[ω’1,ω’2,...,ω’n-3]呈成比例关系(issettobeproportionaltothematchingdegree),被定义为如下形式:
其中,ω′i是观测序列(a‘n-2,a‘n-1,a‘n)和rulei的前因变量(ai,ai+1,ai+2)的匹配程度,i=1,2,...,n-3.
我们定义α(ai,aj)是ai和aj相似程度(匹配程度)的度量。显然,两颗粒之间的距离越小,其相似程度越大。因此,α(ai,aj)可以被表示为
类似于模糊c-均值算法,其中权重指数m>1被称为模糊指数。在本发明中,模糊化系数m设为2。因此,观测序列(a‘n-2,a‘n-1,a‘n)和rulei的前因变量(antecedents)(ai,ai+1,ai+2)的匹配程度被表示为
复平面上两点ai=(α1,δα1)与aj=(α2,δα2)间的欧氏距离:
3.预测信息粒
长度为n的颗粒时间序列a={a(i)},i=1,2,...,n,被划分为初始化为前nt个颗粒构成的、长度为nt的训练集和由接下来nf个颗粒构成的预测集。训练集的长度随时间而增加,最大等于滑动窗口长度+2。在接下来的实验中,训练集的长度最小等于总集y(颗粒时间序列a或数字时间序列x)的九分之八,即nt≥8n/9=8(nt+nf)/9
模型根据训练集数据构建,以预测预测集的数据,表示为
aforecast(t+1)=forecast(a(t),a(t-1),a(t-2))
预测集的数据作为测试数据,用来计算预测精度,表示为aforecasted(nt+i),i=1,2,...,nf。可通过上式得到
aforecast(nt+1)=forecast(a(nt),a(nt-1),a(nt-2)),
aforecast(nt+2)=forecast(a(nt+1),a(nt),a(nt-1)),
aforecast(nt+nf)=forecast(a(nt+nf-1),a(nt+nf-2),a(nt+nf-3)),
预测出的信息粒包含了所预测的下一阶段数据的变化范围、变化趋势。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!