一种地名识别方法与流程
本发明涉及一种地名识别方法,属于信息技术领域。
背景技术:
命名实体识别是信息抽取的一项子任务,其目的是从海量的文本数据中抽取出指定的实体。在自然语言处理应用领域中,命名实体识别是信息检索、机器翻译、情感分析等多项自然语言处理应用的基础任务,而地名识别是命名实体识别的一个子问题,因此,对它的研究具有重要意义和价值。
一般地,地名语义复杂,地名的用字又具有很大的任意性,所以传统的地名识别技术不能有效地识别出新词;同时,由于地名数量众多、没有形态上的特征、规律各异等特点,所以传统的基于规则的地名识别技术由于可移植性差,会使得对地名的识别会变得不够准确,以上所述都会给地名识别造成困难。
技术实现要素:
本发明要解决的技术问题是针对现有技术的局限和不足,提供一种地名识别方法,将统计模型和规则识别进行结合,解决了传统的地名识别技术规则的可移植性差,对地名的识别存在歧义,从而使得地名识别结果准确率低的现象,以提高地名识别的准确性。
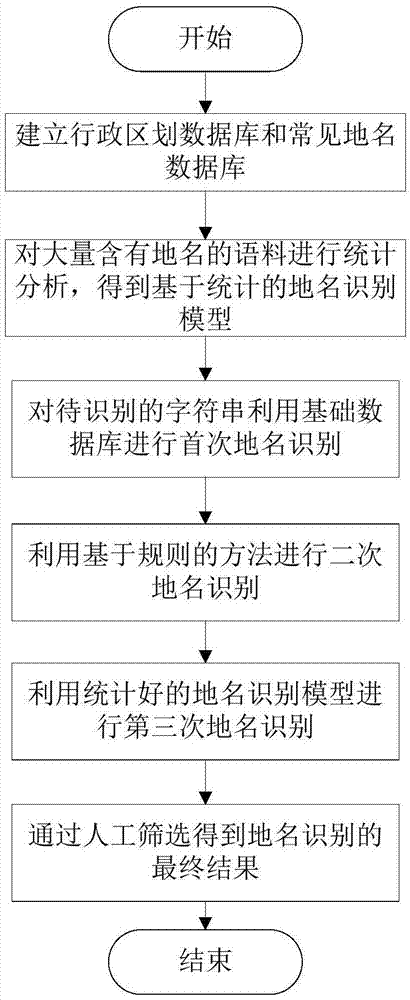
本发明的技术方案是:一种地名识别方法,首先建立行政区划数据库和常见地名数据库作为基础数据库;接着对大量含有地名的语料库进行统计分析,得到基于统计的地名识别模型;然后对待识别的字符串利用基础数据库进行首次地名识别;接着利用基于规则的方法进行二次地名识别;最后利用统计好的地名识别模型进行第三次地名识别,得到地名识别的最终结果。
具体步骤为:
①建立行政区划数据库和常见地名数据库。
②对大量含有地名的语料进行统计分析,得到基于统计的地名识别模型。
③对待识别的字符串利用基础数据库进行首次地名识别。
④利用基于规则的方法进行二次地名识别。
⑤利用统计好的地名识别模型进行第三次地名识别,得到地名识别的最终结果。
⑥通过人工筛选得到地名识别的最终结果。
进一步地,步骤②所述的基于统计的地名识别模型要提取的特征有:地名用字概率以及地名前后字或词的词性特征。
进一步地,所述的地名用字概率通过训练地名语料库后统计得到,具体实现为:将地名语料库中的地名按字切分,得到一个由字组成的集合a,再统计每个字出现的频率,即为概率,最后按照频率的大小进行排序,取前m个为地名用字概率大的字,作为后续地名识别的依据,所述地名用字概率的计算公式为:
其中,pi为第i个字出现的概率,n为集合a中的字的总个数,wi为地名语料库中第i个字出现的次数;所述的门限m通过大量实验后得到。
进一步地,提取所述的地名前后字或词的词性特征的具体实现为:首先对地名前后字或词进行词性标注,再分别计算地名前面的词的词性出现的概率p(q)、地名后面的词的词性出现的概率p(h)以及地名前后的词的词性出现的条件概率p(q|h),所述的p(q)、p(h)、p(q|h)可利用每个词性出现的频率表示,计算公式为:
其中,z为词性的总个数,q、h分别为地名前、后词性出现的次数,p(h|q)为在前一个词性确定的情况下前一个词性出现的概率,可通过训练样本用最大似然法得到。
进一步地,步骤③所述的首次地名识别的具体实现为:将待识别的字符串匹配所述行政区划数据库和常见地名数据库,判断待识别的字符串是否包含行政区划数据库和常见地名数据库中的地名,若包含,则提取出地名,再进行步骤④所述的基于规则的二次地名识别;若不包含,则直接进行二次地名识别。
进一步地,所述的基于规则的二次地名识别的具体实现为:首先统计出地名最后一个字出现概率大的字,作为地名特征字,再统计出地名前一个字出现概率大的字或词,作为地名指示词,然后判断待识别的字符串中是否含有地名特征字,若含有,则提取出地名特征字前六个字作为疑似地名等待下一步处理,若不含有,则进行步骤⑤所述的利用统计好的地名识别模型进行第三次地名识别。
进一步地,所述的下一步处理的具体实现为:判断这六个字中是否存在地名用字概率大的字,若不存在,则视为没有地名,若存在,则继续判断这六个字中是否存在地名指示词且指示词不为最后一个字,若存在,则将指示词后面的部分作为地名,若不存在,则视为没有地名。
进一步地,所述的利用统计好的地名识别模型进行第三次地名识别的具体实现为:将待识别的字符串作为输入,添加已经提取好的特征,利用统计模型实现地名自动识别。
进一步地,步骤⑥所述的人工筛选的具体实现为:在得到候选的地名后,通过人工进行最后的判定,若地名中存在不符合地名用字习惯的字眼,则过滤掉不作为地名,否则作为最终的地名识别结果。
本发明的有益效果是:通过将统计模型和规则识别进行结合,解决了传统的地名识别技术规则的可移植性差,对地名的识别存在歧义,从而使得地名识别结果准确率低的现象,以提高地名识别的准确性。
附图说明
图1是本发明步骤流程图;
图2是本发明步骤③~④流程示意图;
图3是本发明步骤⑤~⑥流程示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种地名识别方法,首先建立行政区划数据库和常见地名数据库作为基础数据库;接着对大量含有地名的语料库进行统计分析,得到基于统计的地名识别模型;然后对待识别的字符串利用基础数据库进行首次地名识别;接着利用基于规则的方法进行二次地名识别;最后利用统计好的地名识别模型进行第三次地名识别,得到地名识别的最终结果。
具体步骤为:
①建立行政区划数据库和常见地名数据库。
②对大量含有地名的语料进行统计分析,得到基于统计的地名识别模型。
③对待识别的字符串利用基础数据库进行首次地名识别。
④利用基于规则的方法进行二次地名识别。
⑤利用统计好的地名识别模型进行第三次地名识别,得到地名识别的最终结果。
⑥通过人工筛选得到地名识别的最终结果。
进一步地,步骤②所述的基于统计的地名识别模型要提取的特征有:地名用字概率以及地名前后字或词的词性特征。
进一步地,所述的地名用字概率通过训练地名语料库后统计得到,具体实现为:将地名语料库中的地名按字切分,得到一个由字组成的集合a,再统计每个字出现的频率,即为概率,最后按照频率的大小进行排序,取前m个为地名用字概率大的字,作为后续地名识别的依据,所述地名用字概率的计算公式为:
其中,pi为第i个字出现的概率,n为集合a中的字的总个数,wi为地名语料库中第i个字出现的次数;所述的门限m通过大量实验后得到。
进一步地,提取所述的地名前后字或词的词性特征的具体实现为:首先对地名前后字或词进行词性标注,再分别计算地名前面的词的词性出现的概率p(q)、地名后面的词的词性出现的概率p(h)以及地名前后的词的词性出现的条件概率p(q|h),所述的p(q)、p(h)、p(q|h)可利用每个词性出现的频率表示,计算公式为:
其中,z为词性的总个数,q、h分别为地名前、后词性出现的次数,p(h|q)为在前一个词性确定的情况下前一个词性出现的概率,可通过训练样本用最大似然法得到。
进一步地,步骤③所述的首次地名识别的具体实现为:将待识别的字符串匹配所述行政区划数据库和常见地名数据库,判断待识别的字符串是否包含行政区划数据库和常见地名数据库中的地名,若包含,则提取出地名,再进行步骤④所述的基于规则的二次地名识别;若不包含,则直接进行二次地名识别。
进一步地,所述的基于规则的二次地名识别的具体实现为:首先统计出地名最后一个字出现概率大的字,作为地名特征字,再统计出地名前一个字出现概率大的字或词,作为地名指示词,然后判断待识别的字符串中是否含有地名特征字,若含有,则提取出地名特征字前六个字作为疑似地名等待下一步处理,若不含有,则进行步骤⑤所述的利用统计好的地名识别模型进行第三次地名识别。
进一步地,所述的下一步处理的具体实现为:判断这六个字中是否存在地名用字概率大的字,若不存在,则视为没有地名,若存在,则继续判断这六个字中是否存在地名指示词且指示词不为最后一个字,若存在,则将指示词后面的部分作为地名,若不存在,则视为没有地名。
进一步地,所述的利用统计好的地名识别模型进行第三次地名识别的具体实现为:将待识别的字符串作为输入,添加已经提取好的特征,利用统计模型实现地名自动识别。
进一步地,步骤⑥所述的人工筛选的具体实现为:在得到候选的地名后,通过人工进行最后的判定,若地名中存在不符合地名用字习惯的字眼,则过滤掉不作为地名,否则作为最终的地名识别结果。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!