基于相关向量机的配比变量施肥离散元模型参数标定方法与流程
本发明涉及变量施肥农机具设计技术领域,特别是涉及到一种基于相关向量机的配比变量施肥离散元模型参数标定方法。
背景技术:
智能化的配比变量施肥农机考虑土壤肥力的不均匀性,可以实时配比调整不同种类肥料的施肥量,实现各种肥料的均匀掺混,最大程度的满足各类农作物的实际需求,最大限度的减少肥料浪费以及过度施肥造成的环境污染。
采用离散元技术建立的配比变量排肥模型,可以实施与耗时、费力的施肥试验相匹配的排肥仿真,有效分析试验无法揭示的排肥过程中肥料颗粒的微观动力学行为,厘清不同种类肥料颗粒之间的动态掺混机理及排肥时滞特性,真正从微观层面提出最优设计方案,实现施肥机具的设计优化,大幅度减少设计时间及成本。
农业散粒体物料离散元模型中的参数标定是建模过程中的重点、难点问题,不恰当的参数值会导致离散元模型不能正确反映真实颗粒的流动行为,对于配比变量施肥离散元模型来说,会造成仿真施肥与真实施肥过程及结果的不相吻合,导致模型失真。
目前,离散元模型参数标定方法主要有物理试验测量法和间接标定法。物理试验测量法通过开展试验,直接测量参数值,但是配比变量施肥离散元模型中的某些参数值很难通过试验测量的方式精确获得,具体讲,目前尚未有成熟的测量设备测量肥料颗粒之间的滚动摩擦系数,采用颗粒板法测量肥料颗粒之间的静摩擦系数时,肥料颗粒会出现弹跳、碰撞等无法避免的现象,无法持续滚动,测量起来十分困难,测量精度难以保证。即使可以通过试验较为精确的测量参数值,但是由于真实颗粒肥料的几何形状不是标准的球形,而为近球形,离散元技术在细节上无法精准模拟不规则的近球形肥料颗粒,一般以标准的球形颗粒代替,使得建立的肥料颗粒模型与真实肥料颗粒存在几何特征上的差异,若采用物理测量得到的参数值,实际上形成了离散元仿真与实际施肥过程的同参数值、不同肥料颗粒形状的差异性特征,这种差异性会造成建立的模型存在较大的排肥误差。所以,通过物理试验测量获得的参数值,不能直接用于配比变量施肥离散元模型,还需要做进一步的参数标定。
最为常用的离散元模型参数间接标定方法,将模型参数,作为宏观层面上颗粒团特定动力学行为的调整参数,开展试验后,实施与真实试验相同的离散元虚拟试验,在待标定参数经验取值域中反复取值,直到离散元虚拟试验得到的颗粒团动力学行为的表征物理属性参数值,在一定精度要求下与真实试验值一致,完成模型参数标定。然而,这种间接标定方法受限于待标定参数的数量,当待标定参数较多时标定无法进行,以采用颗粒系统仿真分析软件(edem软件)建立的3种肥料的配比变量施肥离散元模型为例,如果模型中待标定的参数大于等于3个,就需要手动调节3个及以上的参数值,使得仿真后的3种肥料的掺混均匀度值与试验值一致,这是非常难以实现的。所以,上述这种间接标定方法不适用于多参数值待标定的配比变量施肥离散元模型。
除了上述方法外,离散元模型中的待标定参数值,还可以由建模者依据其工程经验给出,但是这种方法完全依赖于主观经验,给出的模型参数值,并不能一定确保离散元模型颗粒的动力学行为与实际相符,这种方法标定精度较差,最多只能给出待标定参数的次优值。所以,上述这种依靠经验的标定方法标定后的参数值,易导致配比变量施肥离散元模型较大的排肥误差。
综上所述,针对待标定参数较多、参数不易准确测定、颗粒模型与真实肥料存在几何差异且非线性程度较高的配比变量施肥离散元模型,亟需一种标定效果良好的参数标定方法,为施肥机具的设计优化,提供精准的离散元模型。为此我们发明了一种全新的基于相关向量机的配比变量施肥离散元模型参数标定方法,解决了以上技术问题。
技术实现要素:
本发明的目的是提供一种解决了待标定参数较多、参数不易准确测定、颗粒模型与真实肥料存在几何差异且非线性程度较高的问题,为施肥机具的设计优化,提供精准的离散元模型的基于相关向量机的配比变量施肥离散元模型参数标定方法。
本发明的目的可通过如下技术措施来实现:基于相关向量机的配比变量施肥离散元模型参数标定方法,该基于相关向量机的配比变量施肥离散元模型参数标定方法包括:步骤1,根据特定种类的配比变量施肥机具的排肥过程,建立配比变量施肥离散元模型;步骤2,分析离散元模型参数的敏感度;步骤3,采用离散元仿真生成训练样本及测试样本;步骤4,建立肥料掺混均匀度回归模型;步骤5,构建主因参数适应度函数;步骤6,建立最优主因参数值计算数学模型并求解。
本发明的目的还可通过如下技术措施来实现:
在步骤1中,根据特定种类的配比变量施肥机具的排肥过程,建立与其结构参数及工况参数相同的配比变量施肥离散元模型,模型中的各种参数包括物理本征参数和接触参数,通过查阅材料摩擦系数表这些相关参考文献,或者开展物理试验测量,或者依据建模者的工程经验,确定其经验取值域及其初始值。
在步骤2中,将配比变量施肥离散元模型中各个参数的经验取值区域m等分,得到各个取值域的取值步长,将取值域下限值作为参数的第1个取值,参数取值域的下限值加上取值域对应的取值步长,得到参数的第2个取值,以此类推,生成参数的m+1个值后,采用单因素离散元仿真实验,实施单个参数的敏感度分析,即在固定其它参数初始值的同时,仿真某一参数m+1个取值下的排肥过程,统计排肥后各种肥料的掺混均匀度值,计算每一个参数的平均敏感度值及最大敏感度值,对比敏感度计算结果,选取取值变化对肥料掺混均匀度影响较大的参数,即选取平均敏感度值较大,或者最大敏感度值较大,或者两值均较大的参数,作为主因参数。
在步骤2中,实施某一参数单因素离散元仿真试验后,得到该参数对应的各种肥料掺混均匀度值的集合,计算该参数经验取值域内的任意一个取值对应的敏感度值υi,计算公式为:
κ=0,1,2,....,ni=1,2,....,m+1
该参数的敏感度平均值
该参数的敏感度最大值υmax,计算公式为:
υmax=maxυii=1,2,...,m+1
上述各式中,i为该参数在经验取值域内的任意一个取值的代号;κ为肥料种类;χ为该参数的初始值;δχi为该参数在其经验取值域内的任意一个取值相对于初始值的变化量;
在步骤3中,在配比变量施肥离散元模型主因参数的经验取值域内随机抽样,生成肥料掺混均匀度回归模型输入端训练样本,将输入端训练样本中的各个个体作为配比变量施肥离散元模型的主因参数值,进行离散元仿真后,统计各种肥料掺混均匀度值,将特定种类肥料的掺混均匀度值的集合,作为该种肥料掺混均匀度回归模型输出端训练样本,最终形成训练样本。
在步骤3中,在主因参数经验取值域内,随机生成肥料掺混均匀度回归模型输入端测试样本,进行配比变量施肥离散元仿真后,统计各种肥料掺混均匀度值,将特定种类肥料的掺混均匀度值的集合作为该种肥料掺混均匀度回归模型输出端测试样本,最终形成测试样本。
在步骤4中,采用生成的肥料掺混均匀度回归模型训练样本,应用相关向量机机器学习方法,使用高斯核函数构造非线性相关向量机回归,其表达式为:φi(x,xi)=exp{-||x-xi||2/γ2},其中xi为训练样本中的输入向量,x为输入向量,γ为核参数,训练每一种肥料的掺混均匀度回归模型;使用训练完成的肥料掺混均匀度回归模型,预测输入端测试样本下各种肥料的掺混均匀度值,通过与输出端测试样本比较,计算模型预测平均相对误差和决定系数,评价模型性能;若训练后的模型达不到根据实际需要确定的性能要求,采用步骤3所述方法,扩大训练样本规模后,再次进行肥料掺混均匀度回归模型训练并分析模型性能,重复上述步骤,直到肥料掺混均匀度回归模型性能达到要求。
在步骤5中,首先构建肥料掺混均匀度目标函数,基于最优的主因参数值对应的仿真排肥后的各种肥料掺混均匀度值应与排肥试验值一致,将特定种类肥料掺混均匀度回归模型预测的掺混均匀度值与该种肥料的掺混均匀度试验值作差,将上述差值除以试验掺混均匀度值后取绝对值,此绝对值减去允许的误差后的值再取绝对值作为逼近项,表征主因参数任意一组参数值对应的特定肥料掺混均匀度值与试验值的逼近程度,由于配比变量施肥的掺混均匀度由不同种类肥料的掺混均匀度综合表征,因此肥料掺混均匀度目标函数中应为所有种类肥料的掺混均匀度逼近项之和,并且根据实际配比变量施肥需要,对不同肥料的逼近项设置权重要求,构建肥料掺混均匀度目标函数;将目标函数的倒数作为主因参数适应度函数,每一组主因参数值对应一个适应度函数值,适应度函数值越大,表明与其对应的那组主因参数值越优。
在步骤5中,所述适用度函数定义如下:
π=1/θ
上式中,π为主因参数适用度函数,θ为肥料掺混均匀度目标函数;
所述肥料掺混均匀度目标函数为:
κ=0,1,2,...,ni=1,2,3,...,m
上式中,i为主因参数某一组参数值的代号;κ为肥料种类;
在步骤6中,基于约束最优的数学思想,构建最优主因参数值计算数学模型:
minθ
κ=0,1,2,...,ni=1,2,3,...,mj=1,2,3,...,q
上式中,xj为主因参数,
在步骤6中,在求解最优主因参数值计算数学模型时,首先在各主因参数经验取值域内随机生成主因参数初始种群后,开始第一次迭代计算,训练好的各种肥料的掺混均匀度回归模型,预测初始种群中每一组主因参数值对应的各种类肥料的掺混均匀度值,采用建立的主因参数适应度函数,计算初始种群中每一组主因参数值的适应度值,并记录初始种群中的最大适应度值及其对应的那组主因参数值,初始种群经过选择、交叉、变异后,生成下一代种群,重复以上的迭代计算过程,经过若干次迭代后,最大适应度值趋于稳定,最大适应度值对应的那组主因参数值即为主因参数的最优值。
本发明中的基于相关向量机的配比变量施肥离散元模型参数标定方法,首先确定离散元模型中在经验取值域内取值变化对排肥后的肥料掺混均匀度影响较大的参数,将上述参数作为主因参数;采用相关向量机机器学习方法,揭示主因参数与肥料掺混均匀度之间的非线性函数关系,建立回归模型;采用建立的回归模型,基于最优主因参数值对应的肥料掺混均匀度值应与试验值一致,构建适应度函数,建立最优主因参数值计算数学模型,通过遗传算法迭代计算,生成主因参数最优值。本发明能够实现配比变量施肥离散元模型参数的精确标定。
本发明中的基于相关向量机的配比变量施肥离散元模型参数标定方法,通过确保配比变量施肥离散元模型排肥后的肥料掺混均匀度与试验值一致,进行离散元模型参数标定,通过算法寻优计算得到的最优待标定参数值,可使仿真肥料颗粒流的动力学行为与试验一致,可确保仿真排肥后的肥料掺混均匀度值与试验值一致。有效避免了与真实肥料颗粒存在几何差异的仿真肥料颗粒,直接采用物理试验测量获得的待标定参数值后,造成的仿真失真现象。
本发明中的基于相关向量机的配比变量施肥离散元模型参数标定方法,考虑肥料掺混均匀度回归模型的预测值与试验值的偏离程度,构建了适应度函数,建立了最优主因参数值计算数学模型,以遗传算法为框架,开发了基于回归模型的最优参数值算法,该方法能够快速、准确的计算得到模型中多个待标定参数的最优值。有效克服了配比变量施肥离散元模型待标定参数数量较多时,手动同时调整多个参数值进行标定的盲目性和复杂性,使得这种多参数待标定的离散元模型的标定得以顺利实施。
附图说明
图1是本发明一具体实施例中配比变量施肥试验系统图;
图2是本发明一具体实施例中配比变量施肥试验样机采用的a型掺混腔的示意图;
图3是本发明一具体实施例中配比变量施肥试验样机采用的b型掺混腔的示意图;
图4是本发明一具体实施例中配比变量施肥试验样机采用的c型掺混腔的示意图;
图5是本发明一具体实施例中配比变量施肥离散元模型图;
图6是本发明一具体实施例中氮肥掺混均匀度相关向量机回归模型训练图;
图7是本发明一具体实施例中磷肥掺混均匀度相关向量机回归模型训练图;
图8是本发明一具体实施例中钾肥掺混均匀度相关向量机回归模型训练图;
图9是本发明一具体实施例中氮肥掺混均匀度相关向量机回归模型测试图;
图10是本发明一具体实施例中磷肥掺混均匀度相关向量机回归模型测试图;
图11是本发明一具体实施例中钾肥掺混均匀度相关向量机回归模型测试图;
图12是本发明一具体实施例中配比变量施肥离散元模型最优主因参数值计算流程图;
图13是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用a型掺混腔排肥后的氮肥掺混均匀度值与试验值的对比图;
图14是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用a型掺混腔排肥后的磷肥掺混均匀度值与试验值的对比图;
图15是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用a型掺混腔排肥后的钾肥掺混均匀度值与试验值的对比图;
图16是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用b型掺混腔排肥后的氮肥掺混均匀度值与试验值的对比图;
图17是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用b型掺混腔排肥后的磷肥掺混均匀度值与试验值的对比图;
图18是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用b型掺混腔排肥后的钾肥掺混均匀度值与试验值的对比图;
图19是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用c型掺混腔排肥后的氮肥掺混均匀度值与试验值的对比图;
图20是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用c型掺混腔排肥后的磷肥掺混均匀度值与试验值的对比图;
图21是本发明一具体实施例中主因参数标定后的配比变量施肥离散元模型采用c型掺混腔排肥后的钾肥掺混均匀度值与试验值的对比图;
图22是本发明基于相关向量机的配比变量施肥离散元模型参数标定方法的流程图。
具体实施方式
为使本发明的上述和其他目的、特征和优点能更明显易懂,下文特举出较佳实施例,并配合附图所示,作详细说明如下。
如图22所示,图22为本发明的基于相关向量机的配比变量施肥离散元模型参数标定方法的流程图。
步骤101,配比变量施肥离散元的建模。
根据特定种类的配比变量施肥机具的排肥过程,采用edem建立与其结构参数及工况参数相同的配比变量施肥离散元模型,模型中的各种参数(包括:物理本征参数和接触参数)通过查阅材料摩擦系数表等相关参考文献,或者开展物理试验测量,或者依据建模者的工程经验,确定其经验取值域及其初始值。
步骤102,离散元模型参数的敏感度分析。
将配比变量施肥离散元模型中各个参数的经验取值区域m等分,一般取m≥10,得到各个取值域的取值步长,将取值域下限值作为参数的第1个取值,参数取值域的下限值加上取值域对应的取值步长,得到参数的第2个取值,以此类推,生成参数的m+1个值后,采用单因素离散元仿真实验,实施单个参数的敏感度分析,即在固定其它参数初始值的同时,仿真某一参数m+1个取值下的排肥过程,统计排肥后各种肥料的掺混均匀度值,计算每一个参数的平均敏感度值及最大敏感度值,对比敏感度计算结果,选取取值变化对肥料掺混均匀度影响较大的参数(一般为一组参数),即选取平均敏感度值较大,或者最大敏感度值较大,或者两值均较大的参数,作为主因参数。
实施某一参数单因素离散元仿真试验后,得到该参数对应的各种肥料掺混均匀度值的集合,计算该参数经验取值域内的任意一个取值对应的敏感度值υi,计算公式为:
κ=0,1,2,....,ni=1,2,....,m+1
该参数的敏感度平均值
该参数的敏感度最大值υmax,计算公式为:
υmax=maxυii=1,2,...,m+1
上述各式中,i为该参数在经验取值域内的任意一个取值的代号;κ为肥料种类;χ为该参数的初始值;δχi该参数在其经验取值域内的任意一个取值相对于初始值的变化量;
步骤103,采用离散元仿真的训练样本及测试样本生成。
在配比变量施肥离散元模型主因参数的经验取值域内,在matlab环境中,采用谢菲尔德(sheffield)遗传算法工具箱中的fieldd函数在主因参数取值域内随机抽样,生成肥料掺混均匀度回归模型输入端训练样本,将输入端训练样本中的各个个体作为配比变量施肥离散元模型的主因参数值,进行离散元仿真后,统计各种肥料掺混均匀度值,将特定种类肥料的掺混均匀度值的集合,作为该种肥料掺混均匀度回归模型输出端训练样本,最终形成训练样本。在主因参数经验取值域内,随机生成肥料掺混均匀度回归模型输入端测试样本,进行配比变量施肥离散元仿真后,统计各种肥料掺混均匀度值,将特定种类肥料的掺混均匀度值的集合作为该种肥料掺混均匀度回归模型输出端测试样本,最终形成测试样本。
步骤104,肥料掺混均匀度回归模型的建立。
采用生成的肥料掺混均匀度回归模型训练样本,应用相关向量机机器学习方法(使用高斯核函数构造非线性相关向量机回归,其表达式为:φi(x,xi)=exp{-||x-xi||2/γ2},其中xi为训练样本中的输入向量,x为输入向量,γ为核参数)训练每一种肥料的掺混均匀度回归模型;使用训练完成的肥料掺混均匀度回归模型,预测输入端测试样本下各种肥料的掺混均匀度值,通过与输出端测试样本比较,计算模型预测平均相对误差和决定系数,评价模型性能;若训练后的模型达不到根据实际需要确定的性能要求,采用步骤3所述方法,扩大训练样本规模后,再次进行肥料掺混均匀度回归模型训练并分析模型性能,重复上述步骤,直到肥料掺混均匀度回归模型性能达到要求。
步骤105,主因参数适应度函数的构建。
首先构建肥料掺混均匀度目标函数,基于最优的主因参数值对应的仿真排肥后的各种肥料掺混均匀度值应与排肥试验值一致,将特定种类肥料掺混均匀度回归模型预测的掺混均匀度值与该种肥料的掺混均匀度试验值作差,将上述差值除以试验掺混均匀度值后取绝对值,此绝对值减去允许的误差后的值再取绝对值作为逼近项,表征主因参数任意一组参数值对应的特定肥料掺混均匀度值与试验值的逼近程度,由于配比变量施肥的掺混均匀度由不同种类肥料的掺混均匀度综合表征,所以肥料掺混均匀度目标函数中应为所有种类肥料的掺混均匀度逼近项之和,并且根据实际配比变量施肥需要,对不同肥料的逼近项设置权重要求,构建肥料掺混均匀度目标函数;将目标函数的倒数作为主因参数适应度函数,每一组主因参数值对应一个适应度函数值,适应度函数值越大,表明与其对应的那组主因参数值越优。
所述适用度函数定义如下:
π=1/θ
上式中,π为主因参数适用度函数,θ为肥料掺混均匀度目标函数。
所述肥料掺混均匀度目标函数为:
κ=0,1,2,...,ni=1,2,3,...,m
上式中,i为主因参数某一组参数值的代号;κ为肥料种类;
步骤106,最优主因参数值计算数学模型建立及求解。
基于约束最优的数学思想,构建最优主因参数值计算数学模型:
minθ
κ=0,1,2,...,ni=1,2,3,...,mj=1,2,3,...,q
上式中,xj为主因参数,
采用matlab软件,应用谢菲尔德(sheffield)遗传算法工具箱实现最优主因参数值计算数学模型的求解,计算最优主因参数值,首先使用fieldd函数在各主因参数经验取值域内随机生成主因参数初始种群后,开始第一次迭代计算,训练好的各种肥料的掺混均匀度回归模型,预测初始种群中每一组主因参数值对应的各种类肥料的掺混均匀度值,采用建立的主因参数适应度函数,计算初始种群中每一组主因参数值的适应度值,并记录初始种群中的最大适应度值及其对应的那组主因参数值,初始种群经过选择、交叉、变异后,生成下一代种群,重复以上的迭代计算过程,经过若干次迭代后,最大适应度值趋于稳定,最大适应度值对应的那组主因参数值即为主因参数的最优值。
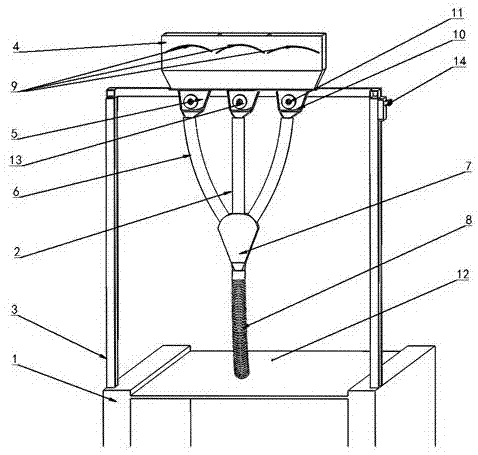
在应用本发明的一具体实施例中,基于山东农业大学排肥综合试验台1,结合某型配比变量施肥装置试验样机2,构建了配比变量施肥试验系统,如图1所示。
本实施例中,采用的配比变量施肥装置试验样机2,由机架3、三个肥箱4、三个外槽轮排肥器5、三根落肥管6、一个掺混腔7与一个排肥管8组成。三种肥料颗粒9分别放置于三个肥箱4中,通过外槽轮排肥器5排肥后,三种肥料颗粒9经落肥管6下落到达掺混腔7中,在掺混腔7中碰撞、掺混后,三种肥料颗粒9的混合体进入排肥管8后,沿排肥管8下落到传送带12。
本实施例中,配比变量施肥装置试验样机2选用的排肥电机为直流减速电机13,试验过程中,通过转速控制器14控制三个直流减速电机13独立工作,电机分别控制三个外槽轮11的转速,结合调整三个外槽轮排肥器5各自的肥舌10的开度,以控制三种肥料颗粒9的排肥量,实现变量排肥。
研究发现,掺混腔7的结构是影响多种肥料掺混均匀性的重要因素之一,本实施例中,配比变量施肥试验分别采用3种不同结构的掺混腔,如图2-4所示,a型掺混腔15的碰撞侧壁为外凸曲线形,b型掺混腔16的碰撞侧壁为直线形,c型掺混腔17的碰撞侧壁为内凹曲线形,3种掺混腔的厚度均为40mm。
本实施例中,以山东农业大学研制的氮(n)、磷(p)、钾(k)固体球形包膜控释肥作为试验用肥料。
本实施例中,用于主因参数标定的试验设计为:三个外槽轮排肥器5的外槽轮11转速均为300deg/s,三个外槽轮排肥器5的肥舌10的开度为最小,肥料传送带12的速度设定为0.6m/s,掺混腔7选用b型掺混腔16,三根落肥管6居中一根的长度均为450cm,落肥管6的内径为36cm,排肥管8为波纹管,轴向截面为三角形波浪纹,排肥管8的外径为45mm,排肥管8的三角波纹高度为8mm,排肥管8的内径为36mm,排肥管8长度为480cm。
本实施例中,用于主因参数标定效果验证的试验设计为:分别采用a型、b型、c型3种掺混腔,每一种掺混腔下,实施三个外槽轮排肥器5的外槽轮11转速相同,且分别为180deg/s、240deg/s、300deg/s、360deg/s、420deg/s的5组试验,每一组试验中三个外槽轮排肥器5的肥舌10开度均设置为最小,肥料传送带12的速度设定为0.6m/s,三根落肥管6居中一根的长度均为850cm,落肥管6的内径为36cm,排肥管8为波纹管,轴向截面为三角形波浪纹,排肥管8的外径为45mm,排肥管8的三角纹高度为2mm,排肥管8内径为42mm,排肥管8长度为480cm。
本实施例中,采用三维建模软件solidworks建立与配比变量施肥装置试验样机结构参数相同的模型,导入到edem软件中,从试验用3种肥料中各随机取样100粒,测量得到3种肥料颗粒的直径分布为氮肥2.87~4.43mm、磷肥3.86~5.41mm、钾肥3.52~5.18mm,采用edem软件设置3种肥料颗粒模型为球形,3种肥料颗粒直径尺寸设置为随机分布,直径及其分布系数为:氮肥3.63mm(0.79~1.22)、磷肥4.65mm(0.83~1.16)、钾肥4.34mm(0.81~1.19),采用edem软件中的颗粒工厂功能,在三个肥箱中分别生成3种肥料颗粒,每个肥箱中生成30000粒肥料颗粒。在edem软件中设置一长为2000mm,宽为700mm的几何平面模拟传送带,此平面相对于配比变量施肥装置试验样机模型的空间位置,与试验系统中传送带相对于配比变量施肥装置试验样机的空间位置相同,建立的配比变量施肥离散元模型如图5所示。
本实施例中,采用edem软件设置配比变量施肥离散元模型的工况参数,为本实施例中主因参数标定试验中的参数,实施主因参数值标定仿真。
本实施例中,采用edem软件设置配比变量施肥离散元模型的工况参数,为本实施例中主因参数标定效果验证试验中的参数,采用标定后的主因参数值,实施排肥仿真,通过将仿真后的肥料掺混均匀度值与主因参数标定效果验证试验的结果比较,验证参数标定效果。
本实施例中,肥料颗粒之间的接触模型、肥料颗粒与排肥机具之间的接触模型以及肥料颗粒与传送带之间的接触模型均采用hertz-mindlin无滑动接触力学模型。
本实施例中,以20%的rayleigh时间步长作为仿真计算时间步长。
本实施例中,肥料掺混均匀度计算方法为:将配比变量排肥后肥料散布区域作为统计区域,将统计区域划分为大小相同的若干统计单元格,统计区域按9行20列划分单元格,设置单元网格尺寸为70mm×50mm的矩形,计算统计单元格内某一种肥料颗粒数与总颗粒数的比值,作为此种肥料当前统计单元格配比,计算统计区域内某一种肥料颗粒数与总颗粒数的比值,作为此种肥料的目标配比,计算某一种肥料各个统计单元格配比与此种肥料目标配比的比值,作为统计单元格配比偏离度,计算配比偏离度集的标准差,称为肥料掺混标准差,即为此种肥料的掺混均匀度值,掺混均匀度值越小,表征肥料的掺混均匀度越好。
本实施例中,肥箱、外槽轮排肥器、掺混腔均为亚克力材质,落肥管和排肥管为pvc材质,传送带的材质为橡胶。
本实施例中,参考文献([1]苑进,刘勤华,刘雪美,张疼,张晓辉.多肥料变比变量施肥过程模拟与排落肥结构优化[j].农业机械学报,2014,45(11):81-87.[2]苑进,刘勤华,刘雪美,张疼,张晓辉.配比变量施肥中多肥料掺混模拟与掺混腔结构优化[j].农业机械学报,2014,45(06):125-132.)中给出的参数取值范围和参数值,参考材料摩擦系数表等资料,并结合工程经验给出了离散元模型中参数的初始值和经验取值域,如表1所示。需要说明的是:本实施例中三种肥料颗粒使用同样的包膜材料,所以三种肥料颗粒两两之间以及三种肥料颗粒与其它材料之间的接触参数(动摩擦系数、静摩擦系数、恢复系数)可认为是相同的,这样可大大减少离散元模型中参数的数量,减少标定工作量。
表1配比变量排肥离散元模型参数初始值及其取值域
本实施例中,将各个参数经验取值区域10等分,得到各个取值域的取值步长,将取值域下限值作为参数的第1个取值,参数取值域的下限值加上取值域对应的取值步长,得到参数的第2个取值,以此类推,生成各个参数的11个取值后,采用单因素离散元仿真实验,固定其它参数值为初始值的同时,仿真此参数11个取值下的排肥过程,仿真工况为上文中用于主因参数标定的试验设计中的工况,统计各种肥料的掺混均匀度值,完成模型中所有参数敏感度分析后,对比分析结果,选取取值变化对肥料掺混均匀度影响较大的参数,即选取平均敏感度值较大,或者最大敏感度值较大,或者两值均较大的参数,作为主因参数。
某一参数经验取值域内的任意一个取值对应的敏感度值υi的计算公式为:
κ=0,1,2i=1,2,....,11
参数的敏感度平均值
参数的敏感度最大值υmax,计算公式为:
υmax=maxυii=1,2,...,11
上述各式中,i为该参数在经验取值域内的任意一个取值的代号;κ为肥料种类,本实施例κ=0代表氮肥,κ=1代表磷肥,κ=2代表钾肥;χ为该参数的初始值;δχi为该参数在其经验取值域内的任意一个取值相对于初始值的变化量;
计算得到的各个参数敏感度值如表2所示,根据计算结果,本实施例中的主因参数选定为3个,分别为:肥料与传输带之间的动摩擦系数、肥料与传输带之间的静摩擦系数、肥料颗粒之间的动摩擦系数。
表2配比变量施肥离散元模型参数敏感度表
本实施例中,在选定的3个主因参数取值域内,采用matlab软件,使用谢菲尔德(sheffield)遗传算法工具箱中的fieldd函数随机抽样,生成的输入端训练样本中个体数为72个,以输入端训练样本中的个体作为配比变量施肥edem模型主因参数值,其它非主因参数值仍为表1中的初始值,进行72组离散元仿真,仿真工况为上文中用于主因参数标定的试验设计中的工况,统计仿真排肥后每一组主因参数值对应的每一种肥料的掺混均匀度值,将特定种类肥料的掺混均匀度值的集合,作为该种肥料掺混均匀度回归模型输出端训练样本。
本实施例中,输入端测试样本依然采用fieldd函数在主因参数取值域内随机生成,生成的输入端测试样本中个体数为24个,进行24组配比变量施肥仿真,仿真工况为上文中用于主因参数标定的试验设计中的工况,统计得到各种肥料的掺混均匀度值的集合,将特定种类肥料的掺混均匀度值的集合,作为该种肥料掺混均匀度回归模型输出端测试样本。
本实施例中,采用生成的肥料掺混均匀度回归模型训练样本,使用相关向量机机器学习方法(使用高斯核函数构造非线性相关向量机回归,其表达式为:φi(x,xi)=exp{-||x-xi||2/γ2}),训练每一种肥料掺混均匀度回归模型,共计3个肥料掺混均匀度回归模型,训练结果如图6-8所示。
本实施例中,采用生成的肥料掺混均匀度回归模型输入端测试样本,使用训练完成的回归模型进行预测,预测结果如图9-11所示,通过与输出端测试样本比较,计算模型预测平均相对误差(mre)和决定系数(r2),评价模型性能,模型性能分析见表3所示。平均相对误差(mre)和决定系数(r2)采用如下公式计算:
上式中,i为测试样本数;κ为肥料种类;
本实施例中,肥料掺混均匀度回归模型性能满足本实施例要求的mre≤7%,r2≥0.8。针对具体实施要求,若模型性能达不到要求,采用扩大训练样本规模的方法,进行回归模型训练、测试,并分析模型性能,重复上述步骤,直到肥料掺混均匀度回归模型性能达到要求,模型训练完成。
本实施例中,采用相关向量机回归主因参数与肥料掺混均匀度之间的函数关系是可行有效的,回归后的模型具有较高的性能。
表3肥料掺混均匀度回归模型性能分析表
本实施例中,基于最优的主因参数值对应的仿真排肥后的各种肥料的掺混均匀度值应与试验值一致,将特定种类肥料掺混均匀度回归模型预测的掺混均匀度值与该种肥料的掺混均匀度试验值作差,将上述差值除以试验掺混均匀度值后取绝对值,此绝对值减去允许的误差后的值再取绝对值作为逼近项,表征主因参数任意一组参数值对应的特定种类肥料掺混均匀度值与试验值的逼近程度,本实施例由于配比变量施肥的掺混均匀度由3种肥料的掺混均匀度综合表征,所以肥料掺混均匀度目标函数中应为3种肥料的掺混均匀度逼近项之和,并且根据实际配比变量施肥需要,对3种肥料的逼近项设置权重要求,构建肥料掺混均匀度目标函数;将目标函数的倒数作为主因参数适应度函数,每一组主因参数值对应一个适应度函数值,适应度函数值越大,表明与其对应的那组主因参数值越优。
本实施例中,将3种肥料的掺混均匀度逼近项的权重系数设定为ω0=0.33,ω1=0.33,ω2=0.33,允许的误差设定为ε=0.05。
所述适应度函数定义如下:
π=1/θ
所述肥料掺混均匀度目标函数为:
i=1,2,3,...,m
其中:氮肥掺混均匀度实验值δexp(0)=0.431,磷肥掺混均匀度实验值δexp(1)=0.758,钾肥掺混均匀度实验值δexp(2)=0.542
所述最优主因参数值计算数学模型为:
minθ
i=1,2,3,...,m
上式中,x1为肥料颗粒与传送带间的动摩擦系数,x2为肥料颗粒与传送带间的静摩擦系数,x3为肥料颗粒间的动摩擦系数。
本实施例中,最优主因参数值计算数学模型在matlab软件中,采用谢菲尔德(sheffield)遗传算法工具箱求解,先在各主因参数经验取值域中,采用fieldd函数随机生成主因参数初始种群,本实施例中种群大小为60,每一次迭代过程中,已训练好的3种肥料掺混均匀度回归模型,预测种群中每一组主因参数值对应的3种肥料的掺混均匀度值,采用建立的主因参数适应度函数,计算每一组主因参数值的适应度,并记录每一代种群中的最大适应度值及其对应的主因参数值,经过80多次迭代,最大适应度值趋于稳定后,最大适应度值对应的主因参数值即为主因参数最优值。配比变量施肥离散元模型最优主因参数值计算流程如图12所示,计算得到的最优主因参数值为:肥料颗粒之间的动摩擦系数为0.261,肥料颗粒与传送带之间的静摩擦系数为0.478,肥料颗粒与传送带之间的动摩擦系数为0.553。
本实施例中,为了验证本发明所述方法的有效性,进行了标定后的配比变量施肥离散元仿真排肥试验,仿真试验设计与本实施例中用于主因参数标定效果验证的试验设计相同。
本实施例中,主因参数标定后的配比变量施肥离散元模型排肥后的肥料掺混均匀度值与试验值的比较,如图13到图21所示。计算每种肥料5种排肥转速下的肥料掺混均匀度误差的平均值,具体为:采用a型掺混腔时,氮肥为6.4%,磷肥为4.1%,钾肥为5.9%;采用b型掺混腔时,氮肥为5.8%,磷肥为5.6%,钾肥为4.9%;采用c型掺混腔时,氮肥为5.0%,磷肥为3.7%,钾肥为8.7%。结果表明,标定后的模型在一定精度下能够正确反映配比变量排肥后的肥料掺混均匀度,进一步说明了本发明的正确性。
- 还没有人留言评论。精彩留言会获得点赞!