一种基于深度学习的微博用户情感影响力分析方法与流程
本发明涉及自然语言处理
技术领域:
,具体涉及一种基于深度学习的微博用户情感影响力分析方法。
背景技术:
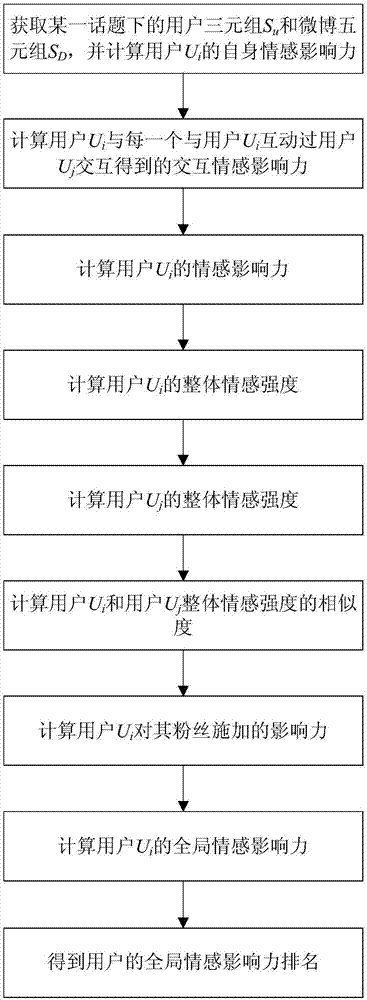
:随着互联网技术的不断进步,由用户主导而生成的内容互联网模式更加符合当代人们对自我表达的需求,人类社会已经全面进入web2.0时代,其中,微博的诞生是中国网络用户交互模式的一次重大变革。由于微博亲民、便捷、自主等特点,各种行业的微博账号覆盖面积逐渐扩大,越来越多的用户在微博上发表自己的所见所闻所想,而且一般都带有主观情感,这些情感类微博包含了许多可用信息,所以本文使用新浪微博作为数据来源。微博情感影响力分析是目前的研究热门,情感影响力分析的基础是微博文本的情感倾向性分析。针对微博文本的情感倾向性分析,目前主流的情感分析分为粗粒度的和细粒度的。其中,粗粒度的有2分类、3分类等,细粒度的有6分类、23分类等。目前的中文文本极性二分类算法主要包括基于机器学习和基于词典的方法,但是这些方法由于无法综合考虑文本的上下文语境,准确率并不高。卷积神经网络(cnn)能够高效地提取句子特征,其卷积层能够保证一次性扫描多个单词,这在考虑文本上下文语境任务中具有一定的优势。极限学习机(elm)是一种单隐层前馈神经网络,能够保证在不损失学习精度的情况下比传统分类器训练时间更短。传统的社交网络影响力定义是具有一定导向能力的用户,也被称为“意见领袖”。但目前的相关研究主要考虑社交网络的拓扑结构和交互信息,这种分析方式是不全面的,因为在类似微博的社交网络中,用户会发表具有某些情感的博文来获取他人的兴趣,从而与之产生互动,这说明微博文本信息也是衡量微博用户影响力的关键因素,然而目前的研究工作却忽略了这一因素。本申请研究微博用户情感影响力,并将其定义为微博用户通过发布带有情感倾向的微博,对其他用户产生情感变化或使其他用户与自己情感趋于一致的能力。这种能力可以通过微博的网络结构、微博用户的交互行为以及用户发表的微博内容来综合衡量。基于网络结构的方法包括度中心性、中介中心性、紧密中心性以及特征向量中心性等。基于微博用户的交互行为方法考虑用户间的点赞、评论、转发以及提及(“@”)等。基于文本内容的分析方法目前的研究较少,但是它是用户表达情感的载体,因此对于情感影响力分析有着重要作用。现有的情感排名方法emotionrank是由北京邮电大学的朱江等人提出的一种用于寻找微博用户中情感影响者的模型,该算法的缺点是,在局部情感影响力分析中,衡量因素不全面的缺点,在全局情感影响力分析中,时间复杂度过高。技术实现要素:针对现有技术存在的问题,本发明提供一种基于深度学习的微博用户情感影响力分析方法,侧重研究情感分析中粗粒度的2分类方式,根据卷积神经网络(cnn)和单隐层前馈神经网络极限学习机(elm)的优势,提出cnn+elm模型来解决文本情感极性二分类问题,将微博用户的情感影响力划分为局部影响力和全局影响力,提出了能够计算上述两种影响力的情感影响力排名方法emointrank,在局部情感影响力分析中,该方法结合拓扑结构、交互行为和文本内容三个因素,在某一个话题下进行影响力计算,找到该话题下的影响者,在全局情感影响力分析中,该方法综合拓扑结构和文本内容分析两个因素,找到全局情感影响者。为了实现上述目的,一种基于深度学习的微博用户情感影响力分析方法,包括以下步骤:步骤1:获取某一话题下的用户三元组su和微博五元组sd,并计算用户三元组su中每个近15天发表过不少于10篇微博用户ui的自身情感影响力eitopic-zs(ui);所述情感影响力包括用户ui的受欢迎度doup(ui)和用户ui所发微博的受欢迎度dowp(ui);所述用户ui的受欢迎度doup(ui)由用户ui的粉丝数决定,粉丝数越多,用户ui的受欢迎度越高;所述用户ui所发微博的受欢迎度dowp(ui)由该微博的转发数和评论数决定,转发数和评论数越高,用户ui所发微博的受欢迎度越高;步骤2:计算用户ui与每一个与用户ui互动过的近15天发表过不少于10篇微博的用户uj交互得到的交互情感影响力eitopic-jh(ui);步骤3:根据用户ui的自身情感影响力和交互情感影响力计算用户ui的情感影响力eitopic(ui);步骤4:计算用户ui的整体情感强度emodi-int;所述情感强度为用户发布的带有情感倾向的微博或评论d所具有的强烈程度,由用户发布的带有情感倾向的微博或评论d的情感得分scored-emo决定;所述情感得分scored-emo是根据boson工具对用户发布的带有情感倾向的微博或评论d进行情感分析后得到的,其值在0到1之间;所述整体情感强度emodi-int为用户ui在时间tg内发表微博的情感强度均值;步骤5:计算用户uj的整体情感强度emodj-int;步骤6:计算用户ui和用户uj整体情感强度的相似度distance(uj,ui);步骤7:根据用户ui和用户uj整体情感强度的相似度计算用户ui对其粉丝施加的影响力fei(ui);步骤8:根据用户ui的情感影响力eitopic(ui)和用户ui对其粉丝施加的影响力计算用户ui的全局情感影响力eiglobal(ui);所述用户ui的全局情感影响力eiglobal(ui)为用户ui在跨话题状态下通过其自身的受欢迎度doup(ui)以及与其互动用户uj的整体情感强度的相似度distance(uj,ui)共同决定的影响力;步骤9:将每个用户ui的全局情感影响力eiglobal进行降序排列,即得到用户的全局情感影响力排名。进一步地,所述步骤1中计算用户ui的自身情感影响力的公式如下:eitopic-zs(ui)=(1-d)+doup(ui)+∑dowp(ui);其中,d为区间[0,1]内的常数,用户ui受欢迎度doup(ui)和用户ui所发微博的受欢迎度dowp(ui)的计算公式如下:doup=lgnfans;dowp=lg|ncm+nre|;其中,nfans为用户信息三元组su中的粉丝数,ncm为微博的评论数,nre为微博的转发数。进一步地,所述步骤2中计算用户ui与用户uj交互得到的交互情感影响力eitopic-jh(ui)的公式如下:eitopic-jh(ui)=∑(emowj-int+eir(uj));其中,emowj-int为微博中词语的情感强度,eir(ui)为用户ui的emointrank算法值。进一步地,所述步骤4和步骤5中计算用户ui和uj的整体情感强度emoui-int和emouj-int的公式如下:其中,和分别为用户ui和uj在时间tg内发表的所有微博数,edi和edi分别为用户ui所发微博di和uj所发微博dj的情感极性,emodi-int和emodj-int分别为用户ui所发微博di和uj所发微博dj的情感强度。进一步地,所述步骤6中计算用户ui和用户uj整体情感强度的相似度的公式如下:distance(uj,ui)=1+|emoui-int-emouj-int|;其中,|emoui-int-emouj-int|为用户ui和uj之间的整体情感影响强度的差值。进一步地,所述步骤7中计算用户ui对其粉丝施加的影响力fei(ui)的公式如下:其中,d为区间[0,1]内的常数,follower(ui)为用户ui的粉丝集合,为用户ui的关注数。进一步地,所述步骤8中计算用户ui的全局情感影响力eiglobal(ui)的公式如下:eiglobal(ui)=doup(ui)+fei(ui);本发明的有益效果:本发明提出一种基于深度学习的微博用户情感影响力分析方法,根据微博用户情感影响力分析找到情感影响者,利用这些影响者具有的改变其他用户情感的能力,可以用于目前受到越来越多社会关注公共的心理健康问题,通过数据获取平台分析某一个心理健康话题的方式,找到话题影响者,从而帮助心理研究人员对这些用户进行后续的评估与诊断,也可以用于帮助商品推广、引领舆论导向、帮助有关部门决策等问题上。附图说明图1为本发明实施例中基于深度学习的微博用户情感影响力分析方法的流程图;图1为本发明实施例中基于深度学习的微博用户情感影响力分析方法的流程图;图2为本发明实施例中使用word2vec将单词转换为200词向量并计算两个词的距离;图3为本发明实施例中elm训练数据格式;图4为本发明实施例中采用emointrank算法与emotionrank算法进行全局影响力分析的时间对比图。具体实施方式为了使本发明的目的、技术方案及优势更加清晰,下面结合附图和具体实施例对本发明做进一步详细说明。此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。一种基于深度学习的微博用户情感影响力分析方法,流程如图1所示,具体方法如下所述:步骤1:获取某一话题下的用户三元组su和微博五元组sd,并计算用户三元组su中每个近15天发表过不少于10篇微博用户ui的自身情感影响力eitopic-zs(ui);所述情感影响力包括用户ui的受欢迎度doup(ui)和用户ui所发微博的受欢迎度dowp(ui);所述用户ui的受欢迎度doup(ui)由用户ui的粉丝数决定,粉丝数越多,用户ui的受欢迎度越高;所述用户ui所发微博的受欢迎度dowp(ui)由该微博的转发数和评论数决定,转发数和评论数越高,用户ui所发微博的受欢迎度越高;所述计算用户ui的自身情感影响力的公式如下:eitopic-zs(ui)=(1-d)+doup(ui)+∑dowp(ui);其中,d为区间[0,1]内的常数,用户ui受欢迎度doup(ui)和用户ui所发微博的受欢迎度dowp(ui)的计算公式如下:doup=lgnfans;dowp=lg|ncm+nre|;其中,nfans为用户信息三元组su中的粉丝数,ncm为微博的评论数,nre为微博的转发数。步骤2:计算用户ui与每一个与用户ui互动过的近15天发表过不少于10篇微博的用户uj交互得到的交互情感影响力eitopic-jh(ui);所述计算用户ui与用户uj交互得到的交互情感影响力eitopic-jh(ui)的公式如下:eitopic-jh(ui)=∑(emowj-int+eir(uj));其中,emowj-int为微博中词语的情感强度,eir(ui)为用户ui的emointrank算法值。步骤3:根据用户ui的自身情感影响力和交互情感影响力计算用户ui的情感影响力eitopic(ui);步骤4:计算用户ui的整体情感强度emodi-int;所述情感强度为用户发布的带有情感倾向的微博或评论d所具有的强烈程度,由用户发布的带有情感倾向的微博或评论d的情感得分scored-emo决定;所述情感得分scored-emo是根据boson工具对用户发布的带有情感倾向的微博或评论d进行情感分析后得到的,其值在0到1之间;所述整体情感强度emodi-int为用户ui在时间tg内发表微博的情感强度均值;所述计算用户ui和uj的整体情感强度emoui-int和emouj-int的公式如下:其中,和分别为用户ui和uj在时间tg内发表的所有微博数,edi和edi分别为用户ui所发微博di和uj所发微博dj的情感极性,emodi-int和emodj-int分别为用户ui所发微博di和uj所发微博dj的情感强度。本实施例中,将微博文本的情感强度分为正向(emodi-int-pos)4级与负向(emodi-int-neg)4级,划分规则如表1所示。表1情感强度划分规则步骤5:计算用户uj的整体情感强度emodj-int;步骤6:计算用户ui和用户uj整体情感强度的相似度distance(uj,ui);所述计算用户ui和用户uj整体情感强度的相似度的公式如下:distance(uj,ui)=1+|emoui-int-emouj-int|;其中,|emoui-int-emouj-int|为用户ui和uj之间的整体情感影响强度的差值。步骤7:根据用户ui和用户uj整体情感强度的相似度计算用户ui对其粉丝施加的影响力fei(ui);所述计算用户ui对其粉丝施加的影响力fei(ui)的公式如下:其中,d为区间[0,1]内的常数,follower(ui)为用户ui的粉丝集合,为用户ui的关注数。步骤8:根据用户ui的情感影响力eitopic(ui)和用户ui对其粉丝施加的影响力计算用户ui的全局情感影响力eiglobal(ui);所述用户ui的全局情感影响力eiglobal(ui)为用户ui在跨话题状态下通过其自身的受欢迎度doup(ui)以及与其互动用户uj的整体情感强度的相似度distance(uj,ui)共同决定的影响力;所述计算用户ui的全局情感影响力eiglobal(ui)的公式如下:eiglobal(ui)=doup(ui)+fei(ui);步骤9:将每个用户ui的全局情感影响力eiglobal进行降序排列,即得到用户的全局情感影响力排名。本实施例中,使用网络爬虫抓取微博数据如表2所示,用户信息数据如表3所示。表2抓取的微博数据(表名为‘weibo’)格式说明表3抓取的用户数据(表名为‘userinfo’)格式说明使用ictclas对抓取微博数据中重复文本和垃圾文本进行清洗,得到微博进行中文分词后的部分。使用word2vec的skip-gram模型进行汉语词向量的转换,输入某个单词即可得到相应的200维的词向量,而且可以计算两个单词之间的距离。本实施例中,分别输入汉语词“中国”与“美国”,word2vec工具即可计算出两个单词对应的200维连续型实值向量,并且在最后计算出两个单词的距离,如图2所示。使用cnn进行特征提取并整合训练cnn+elm模型,获得elm分类器。使用cnn进行文本的特征提取,并在使用抽取的特征值之前,使用人工标注训练集训练cnn。本实施例中,使用人工标注的微博数据作为训练集,用straincnn表示,straincnn={(m1,e1),...,(mi,ei),...},其中,(mi,ei)表示第i篇微博的词向量矩阵和人工标注的情感极性。elm训练数据格式如图3所示。使用emointrank算法计算得出的“a”话题下的用户影响力排名,如表2所示。表2“a”话题下的用户影响力排名uid昵称粉丝数转发总数评论总数交互总数总情感强度1665256992主演av239376544289921846647451186461197191492主演bv359958792012545535656601603731378010100主演cv1158568211655774419399292491567875513主演dv470035136831318216865430931227368500主演ev2383772426581165714315357452111083372主演fv415965820641070912773104961615743184公众人物av77161223135569370465521617902267公众人物bv43519621687153632238319由表2可以看出,“a”话题下,获得高影响力的大多为加“v”认证的用户,可以将此解释为加v认证的用户由于其自身的吸引力,能够让更多的粉丝参与到他们的微博交互(转发和评论)当中。前6位都是电视剧“a”的主演,是该话题的“引导者”。然而主要演员并非只有这6名用户,而其他几位之所以并不在排名当中,是因为在抓取期间,其他主演没有发表关于“a”的微博。第7和8位不是电视剧的演员或者参与者,但是他们也是经过加v认证的公众人物,而且在5月2日到16日期间发表了若干篇与该剧有关的微博,且与其粉丝的总交互量在3000条以上,产生的情感强度总和在4000以上,这说明他们在“a”话题下成功地引起了其他用户的兴趣,并通过他们发布的微博对其他用户的情感强度产生了影响。使用emointrank算法计算得出的“b”话题下的用户影响力排名,如表3所示。表3“b”话题下的用户影响力排名uid昵称粉丝数转发总数评论总数交互总数总情感强度1618051664传统媒体av52375089212902092242212-524271642088277传统媒体bv233259648886790016786-133512803301701传统媒体cv54609769417444908664-89771642634100互联网公司av221393510044926619310-249955044281310传统媒体dv52902126522429610818-250731653689003传统媒体ev15317444330517555060-62501807715644自媒体用户av1172458246519014366-51961217330363自媒体用户bv69035819057092614-2867由表3可以看出,“b”话题下,最具有影响力的前8名用户都是加v认证的,这说明对于“b”这样的社会热点新闻,公众人物或团体往往具有引领普通用户情感变化的能力,人们更愿意浏览公众人物或团体的微博来了解事件,更加倾向于对这些用户发表的微博进行转发或评论。在这8名用户中,“传统媒体a”、“传统媒体b、“传统媒体c”、“传统媒体d”和“传统媒体e”都是传统媒体行业,之所以他们的排名如此靠前是因为这些媒体在抓取期间,都发表了3篇以上有关“b”的新闻,且每一篇微博都能获得上千条的评论和转发。“互联网公司a”的排名在第4位。本实施例中认为,“b”不仅仅是一个社会话题,也是一个搜索引擎行业的技术问题,该事件暴露出了恶意“竞价排名”机制。“互联网公司a”在此期间发布了16篇与“b”有关的微博,其中7篇是涉及“互联网公司b”,4篇涉及其他互联网公司,如“互联网公司c”、“互联网公司d”等,这些微博都吸引了众多科技爱好者参与讨论,且转发和评论的内容都有比较强的情感倾向。第7和8位都是认证的自媒体用户,他们在抓取期间都发表了至少3篇与“b”有关的微博。通过以上实验结果可得,本申请提出的基于深度学习的微博用户情感影响力分析方法是综合考虑用户自身的受欢迎度、发表微博的受欢迎度以及获得的交互用户的总情感强度,本方法考虑因素全面,从而最终得到的具有高影响力的用户列表是合理的。本实施例中,分别就本申请提出的emointrank算法和现有技术中的emotionrank算法对全局影响力分析结果进行实验结果对比,如图4所示。从图4可以看出,在节点数相同的情况下,本申请提出的emointrank算法相较于现有技术中的emotionrank算法具有运行时间更快的优势。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;因而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1