一种基于深度融合神经网络的中文社交文本情绪识别模型构造方法与流程
本发明涉及自然语言处理技术领域,具体涉及一种基于深度融合神经网络的中文社交文本情绪识别模型构造方法。
背景技术:
情绪分析属于情感分析类问题。情感分析(sa)又称为倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。情感分析可应用于电子商务,品牌声誉管理、舆情分析等众多领域。随着微博等社交媒体的普及,用户讨论自己使用的产品和服务,或表达自己的政治和宗教观点,微博网站已经成为人们评论与情感信息的宝贵来源。现在对此类数据做情感分析已经受到研究者的广泛关注。
目前为止,大部分微博情感分析研究都只关注于如何对英文文本信息进行分析,并且以情感极性分析为主。现有技术中缺少更加细化的分析中文文本情绪特征,分析卷积神经网络与长短时记忆网络的特点,因此,目前亟待研究如何采用深度学习融合模型,实现较好的中文情绪分类效果。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于深度融合神经网络的中文社交文本情绪识别模型构造方法。本方法的特点是融合了双向长短时记忆网络与卷积神经网络的特点,使用双向长短时记忆网络完成文本的全局特征表示,再利用卷积神经网络的局部特征抽取表征文本的情绪特征,此方法在情绪分类数据集上取得了较高的准确率。
本发明的目的可以通过采取如下技术方案达到:
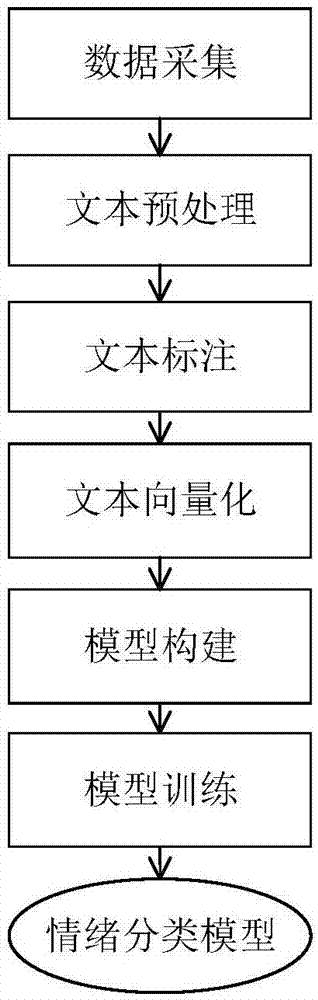
一种基于深度融合神经网络的中文社交文本情绪识别模型构造方法,所述的构造方法包括:
数据采集步骤,用于从社交网络数据源采集中文文本数据;
文本预处理步骤,处理采集到的原始文本数据;
文本情绪标注步骤,对预处理后的数据进行情绪多分类标记;
文本向量化步骤,通过分布式词向量表示方法word2vec进行中文词向量的训练;
模型构建步骤,初始化模型结构,构建基于神经网络融合模型的多分类结构;
模型训练步骤,训练用于多分类情绪分析的cnn-bilstm融合网络模型,得到最终的情绪分类模型。
进一步地,所述的数据采集步骤中,采用面向多主题的爬虫抓取网络情绪文本,并对其中的中文文本进行存储。
进一步地,所述的文本预处理步骤过程如下:
去除文本中的英文数据;
去除文本中emoji和超链接,将文本中emoji替换为其简单的中文文本,将文本中超链接替换为中文“链接”;
根据中文停用词典去除文本停用词。
进一步地,所述的文本情绪标注步骤中,采用部分人工标注的数据和部分公开的数据,在人工标注过程中,将情绪分为喜好、恐惧、愤怒、厌恶、悲伤、高兴、惊讶七个情绪类别,各类数据各取2500条,最后将训练集和测试集分别取80%和20%的数据,所采用的函数为train_test_split,参数test_size为0.2。
进一步地,所述的文本向量化步骤中,利用分布式词向量表示方法word2vec构建词向量模型,将输出词向量维度设置为350,其训练数据由中文维基语料与采集到的情绪语料一同作为训练样本。
进一步地,所述的模型构建步骤中,构建融合模型,抽取文本情绪特征,、采用cnn(卷积神经网络)与bilstm(双向长短时记忆网络)融合,提取情感特征。
进一步地,所述的模型构建步骤中,采用keras搭建cnn(卷积神经网络)与bilstm(双向长短时记忆网络)融合深度神经网络,该cnn(卷积神经网络)与bilstm(双向长短时记忆网络)融合深度神经网络结构如下:
第一层是嵌入层,此层的输入为训练好的词向量序列,本发明将文本序列长度(词向量序列个数)设定为100,不足100的用0填充,超过100的截断。设定嵌入层采用预训练的词向量;
第二层是双向lstm层,此层输出为100*200;
第三层是第一卷积层,输入的二维矩阵大小为100*200,有大小为4×4像素的32个过滤器,步长为1,激活函数设置为relu函数;
第四层是第一池化层,采用最大池模型为maxpooling2d,参数poolsize为(3,3);
第五层是第二卷积层,采用大小为3×3像素的32个过滤器,使用的激活函数是relu函数;
第六层是第二池化层,采用最大池maxpooling2d,参数poolsize为(2,2);
第七层是dropout层,参数rate设为0.3,防止过拟合;
第八层是flatten层,把多维的输入一维化;
第九层是第一全连接层,输入上一神经网络层的输出展开后的向量,输出500维的向量,使用的激活函数是relu;
第十层是第二全连接层,输入是500维的输入向量,此层为两个神经元,即输出二维数据,采用的激活函数是relu;
第十一层是分类器softmax层,通过softmax分类器产生分类结果。此层输出为情绪分类的类别数为7。
进一步地,所述的模型训练步骤中,在训练中文情绪文本数据集时采用的损失函数为categorical_crossentropy,优化器为adam,批量大小batch_size为100,迭代次数epoch为15。
本发明相对于现有技术具有如下的优点及效果:
1、本发明将预训练word2vec用于文本分布式词向量表示,训练数据结合了大量情绪预料以及中文维基预料,更好的表示文本的语义特性。
2、本发明融合了双向长短时记忆网络才序列表示上的优点,以及卷积神经网络在局部特征提取上的优势,提出了一种用于中文情绪识别的深度神经网络模型。
附图说明
图1是本发明中公开的基于深度融合神经网络的中文社交文本情绪识别模型构造方法的流程示意图;
图2是本发明中的数据采集方法逻辑图;
图3是本发明中的用于全局特征表示的双向lstm图;
图4是本发明中的局部特征抽取的cnn模型结构图;
图5是本发明中的中文情绪识别模型图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
情感计算的方法主要基于词典/规则的方法以及基于统计学习/深度学习的方法,本发明实施例通过基于深度学习的方法进行情感分析,利用word2vec技术训练词向量,利用bilstm-cnn融合网络进行情感的分析计算。深度融合情绪分析模型挖掘以及学习文本情绪表示的特点,进而深度抽取文本的情绪语义,提高情绪识别的准确率。
根据附图1所示的基于深度融合神经网络的中文社交文本情绪识别模型构造方法的流程示意图,本发明实施例公开的基于深度融合神经网络的中文社交文本情绪识别模型构造方法包括以下步骤:
数据采集步骤,用于从微博等社交网络数据源采集中文文本数据;
文本预处理步骤,处理采集到的原始文本数据;
文本情绪标注步骤,对预处理后的数据进行情绪多分类标记;
文本向量化步骤,通过分布式词向量表示方法word2vec进行中文词向量的训练;
模型构建步骤,初始化模型结构,构建基于神经网络融合模型的多分类结构;
模型训练步骤,训练用于多分类情绪分析的cnn-bilstm融合网络模型,得到最终的情绪分类模型。
在数据采集步骤中,具体方案为使用python2.7版本下爬虫框架scrapy,scrapy使用了twisted异步网络库来处理网络通讯。如附图2中的数据采集方法逻辑图,本爬虫用控制器管理爬虫的各步骤,用字典数据结构管理待爬取的url,对于持久化步骤,直接存储于mysql数据库中。解析器采用的是scrapy的查询语法,scrapy内部支持更简单的查询语法,帮助在html中查询需要的标签和标签内容以及标签属性。
在文本预处理步骤中,本发明额外下载部分网络公开的文本情绪分析数据(如nlpcc2013数据集)。对于文本数据的处理,首先去除文本中的英文数据。然后是对于emoji和超链接的处理,本实施例具体方法是将emoji替换为其简单的中文文本如(笑哭,尴尬等),将超链接删除仅仅表示为中文“链接”。最后根据中文停用词典去除文本停用词。
在文本情绪标注步骤中,本发明采用了部分人工标注的数据和部分公开的数据。标注过程中,将情绪分为喜好、恐惧、愤怒、厌恶、悲伤、高兴、惊讶等七个情绪类别,各类数据各取2500条。最后将训练集和测试集分别取80%和20%的数据,所采用的函数为train_test_split,参数test_size为0.2。
在文本向量化步骤中,采用的是word2vec方法,本实施例采用采集到的文本数据、网络公开的微博语料库以及中文维基语料训练词向量,并设置输出词向量的的维度size与前面的cnn特征维度一致,设置为350。具体过程是首先利用分词工具进行分词,如jieba分词,得到分词语料corpsw2v.txt然后importword2vec,分词之后使用其中的word2vec函数将数据集中的文本表示成词向量保存。
本方法中的bilstm模型,如图3所示,通过训练分布式向量表示的中文文本,构建双向长短时记忆网络模型,在bilstm网络之前,使用嵌入层embedding过滤掉0向量的时间步,因为输入的句子长度不一,通过pad_sequences处理成了相同长度。本层处理之后,对文本词序列已经做了一定程度的特征表达,此网络层所抽象的向量序列,既考虑了文本词语的相关特性,也考虑了词语的语序关系,这也是bilstm神经网络的重要优点。
在卷积过程中,本发明采用如图4所示的cnn卷积神经网络,本发明的卷积层部分共九层网络,分别为卷积层、最大池化层、卷积层、最大池化层、dropout层、flatten层、全连接层、全连接层和softmax分类层按照图4依次连接。
通过下载的数据集与自己标注的训练数据集训练模型,得到本特征提取的cnn网络。卷积后即可进行分类,此实施例选用了softmax激活函数分类,本模型输出图文媒体的正负类特征。这里损失函数用交叉熵损失函数categorical_crossentropy,优化方法用adam。通过调整其他超参数的值,得到较好模型后保存,用于对未知数据的情绪分析,以及测试等。
图5即为本方法所建立的中文情绪识别模型,图中,输入x等为嵌入的文本词向量,通过bilstm编码之后经过两层卷积网络提取特征,最后通过全连接和分类器进行分类。在本模型中,双向bilstm层用于对原始文本序列进行编码,卷积层提取编码后序列中各层次特征。处理过程中,需按本发明的步骤对中文情绪文本进行预处理,以及进行分词,向量化等操作,然后输入到模型中识别情绪类别。测试过程中,可通过准确率,召回率,f1值等参数评判模型能力。
综上所述,针对现今微博、微信朋友圈等媒体中图文媒体的特点,本方法重点通过bilstm初步表征文本特征,双向长短时记忆网络能够较好的处理长时依赖信息,在对文本进行特征表示的过程中,既考虑了过去的上下文信息,也考虑了未来的上下文信息。然后经过cnn卷积神经网络通过不同卷积核,更好的抽象出数据在各层次上的局部特征。以此让情绪分析模型更加充分的挖掘数据特征,提高情绪分类的效果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!