一种车窗标志物检测方法及装置与流程
背景技术:
随着计算机视觉技术的研究与应用,对目标进行跟踪检测以其智能性和可靠性可被用在政府管控、违章锁定、嫌疑人跟踪、个人信息解锁等现实场景,目前已经应用于交通、公安、银行、军队、能源等多个领域,更有进一步深入发展的趋势。
对车窗标志物进行检测识别主要是对车辆车窗内可被采集到的可辨识的物体进行分析,为交通管控、侦查办案等提供下一步处理依据。如年检标检测、安全带检测、打电话检测可以判断车辆是否违章;年检标、纸巾盒、挂饰可以作为以图搜车的关键信息;遮阳板检测、戴眼镜检测、口罩检测可以作为追踪犯罪嫌疑人的筛选信息。
现有对车窗标志物进行检测方案使用传统特征的目标检测算法,常用的特征图像特征有hog、lbp、haar。其中,hog(histogramoforientedgradient,方向梯度直方图)是一种用来计算和统计图像局部区域的梯度方向直方图的特征。lbp(localbinarypattern,局部二值模式)是用来描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性等优点。haar特征是由线性特征、边缘特征、中心特征和对角线特征组合成特征模板。常用的组合方式有hog+svm(supportvectormachines,支持向量机)、dpm(deformablepartmodel,可变形的组件模型)等。法国研究人员dalal在2005的cvpr上提出hog+svm进行行人检测的方法,这种组合是许多改进行人检测算法的基础。dpm算法由felzenszwalb于2008年提出,采用了改进后的hog特征、svm分类器和滑动窗口(slidingwindows)检测思想,对目标的形变具有很强的鲁棒性。paulviola和miachaeljones在2001年的cvpr上等提出了adaboost(adaptiveboosting,自适应增强)+haar的人脸检测算法,也取得很好的效果。
上述传统方法的优势在于速度快,易移植、在嵌入式平台上实时性较好,但是需要手工设计特征,鲁棒性不强。在对车标志物检测识别上通常是对车窗标志物的类别进行单类别检测,存在检测精度不高还有类别不够全面等问题。
技术实现要素:
本技术方案提出了一种车窗标志物检测方法及装置,检测精度高、鲁棒性强、对不同场景的适应性好,解决了现有技术存在的检测精度不高、类别不全面的技术问题。
本发明提供的一种车窗标志物的检测方法,包括,
预先训练用于检测车辆车窗内不同类型标志物的检测器,所述不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
预先设定不同类型标志物检测框的阈值;
获取包含待检测车辆的图像信息;
定位至所述待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
将所述待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
更进一步,对所述车窗内不同类型标志物区域检测框的选定为:所述安全带副系区域为副驾驶人员身上安全带可见的区域,所述安全带主系区域为驾驶人员身上安全带可见的区域,所述打电话区域为手机及手腕区域,所述纸巾盒区域为盒子加上纸巾被抽出的部分的最小外接矩形,所述挂饰区域不包括细线部分,所述安全带副未系区域为副驾驶人员的肩膀区域加人脸下半部分区域,所述安全带主未系区域为驾驶人员的肩膀区域,所述遮阳板区域、年检标区域、戴口罩区域、戴眼镜区域均为最小外接矩形。
更进一步,所述预先训练用于检测车辆车窗内不同类型标志物的检测器具体包括,基于ssd算法进行训练,对输入的图像样本同时进行检测和分类,预先建立的训练集包括所述不同类型标志物的类别信息及位置信度息。
更进一步,基于ssd算法进行训练,对输入的图像样本同时进行检测和分类,预先建立的训练集包括所述不同类型标志物的类别信息及位置信度息,具体流程包括,
获取车窗样本图像,并把图像归一化到300*300像素大小;
对所述归一化后的车窗样本图像上进行标注,标定出车窗标志物的坐标信息,并将所述坐标信息保存在与所述车窗样本图像名称一一对应的xml文件中,所述xml文件中记录有所述jpg图像中包含的标志物类别及所述标志物类别对应的坐标信息;
统计所述不同类型车窗标志物的宽高在300*300的二维坐标上的分布,获取所述不同类型车窗标志物的宽高分布规律;
设计适用于不同类型车窗标志物的defaultboxes。
更进一步,所述设计适用于不同类别标志物的defaultboxes计算方法如下:
其中,sk为第k个等分节点的尺度,smin为设计的附加网络最小尺度,smax为附加网络最大尺度,m是指在最小与最大之间等分出m个区间;
其中:
更进一步,ar={1,2,3,1/2,1/3}。
更进一步,当所述ar=1时,所述各类型车窗标志物增加一个defaultboxes,其计算公式为
其中:sk为第k个等分节点的尺度,sk+1为第k+1个等分节点的尺度。
更进一步,所述设计适用于不同类型车窗标志物的defaultboxes还包括对defaultboxes进行微调。
本发明还提供了一种车窗标志物检测装置,包括,
训练单元,用于预先训练用于检测车辆车窗内不同类型标志物的检测器,所述不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
预设单元,用于预先设定不同类型标志物检测框的阈值;
获取单元,用于获取包含待检测车辆的图像信息;
定位单元,用于定位至所述待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
比对单元,用于将所述待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
更进一步,所述训练单元具体包括,
获取模块,用于获取车窗样本图像,并把图像归一化到300*300像素大小;
标注模块,用于对所述归一化后的车窗样本图像上进行标注,标定出车窗标志物的坐标信息,并将所述坐标信息保存在与所述车窗样本图像名称一一对应的xml文件中,所述xml文件中记录有所述jpg图像中包含的标志物类别及所述标志物类别对应的坐标信息;
统计模块,用于统计所述不同类型车窗标志物的宽高在300*300的二维坐标上的分布,获取所述不同类型车窗标志物的宽高分布规律;
设计模块,用于设计适用于不同类型车窗标志物的defaultboxes;
所述设计模块设计适用于不同类别标志物的defaultboxes计算方法如下:
其中,sk为第k个等分节点的尺度,smin为设计的附加网络最小尺度,smax为附加网络最大尺度,m是指在最小与最大之间等分出m个区间;
其中:
其中:sk为第k个等分节点的尺度,sk+1为第k+1个等分节点的尺度。
上述技术方案提出的车窗标志物检测方法及装置,针对现有技术检测图片质量不稳定、车窗内环境比较复杂、检测目标类型多难以训练模型、检测精度与检测时间及显存占用难以兼顾的技术问题,通过预先训练用于检测车辆车窗内不同类型标志物的检测器,获取待检测车辆图片并定位至所述待检测车辆的车窗区域,生成标志物区域检测框再通过比对筛选最终标记出符合条件的车窗标志物区域,检测精度高、鲁棒性强、对不同场景的适应性好,解决了现有技术存在的检测精度不高、类别不全面的技术问题。
附图说明
图1为本发明实施例1的流程示意图;
图2为左座位未系安全带阈值设置过低示意图;
图3为提高左座位未系安全带阈值后示意图;
图4为右座位系安全带阈值设置过高示意图;
图5为降低右座位系安全带阈值后示意图;
图6为本发明实施例2的流程示意图;
图7为不同类别标签与类型值示意图;
图8为安全带副未系、安全带主系、遮阳板、年检标标注示意图;
图9为安全带主系、戴口罩、遮阳板、年检标标注示意图;
图10为安全带副未系、安全带主系、纸巾盒、年检标标注示意图;
图11为安全带副未系、安全带主未系、戴眼镜标注示意图;
图12为安全带主系、年检标标注示意图;
图13为安全带主未系、打电话、年检标标注示意图;
图14为挂饰的宽高分布规律示意图;
图15为不同类别标志物的分布规律示意图;
图16为不同类型的车窗标志物在300*300的二维坐标系上的整体分布示意图;
图17为defaultboxes在二维坐标中的映射分布示意图;
图18为安全带主系、年检标测试示意图;
图19为安全带主系、遮阳板、年检标测试示意图;
图20为安全带副未系、安全带主系测试示意图;
图21为安全带副系、安全带主系、遮阳板、年检标测试示意图;
图22为安全带主系、挂饰、纸巾盒、年检标测试示意图;
图23为安全带副未系、安全带主系、遮阳板、年检标测试示意图;
图24为安全带副未系、安全带主系、戴口罩、年检标测试示意图;
图25为安全带主未系、遮阳板、打电话、纸巾盒、年检标测试示意图;
图26为安全带主未系、戴眼镜测试示意图;
图27为本发明实施例3的结构示意图;
图28为本发明实施例4的结构示意图。
具体实施方式
为使得本申请实施例的发明目的、特征、优点能够更加的明显和易懂,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本申请实施例一部分实施例,而非全部的实施例。基于本申请实施例中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请实施例保护的范围。
1、本发明参考基于cnn的目标检测
1)基于rpn(regionproposalnetworks,区域建议网络)的思想
r-cnn(regionswithcnnfeatures,基于卷积神经网络特征的区域方法)通过selectivesearch(选择性搜索)算法在图片中提取出感兴趣区域,送入到卷积神经网络中进行特征提取,最后使用一个分类器进行类别预测。
但r-cnn的问题在于存在大量的重复计算,显存占用高。针对这个问题,rossgirshick于2015年发表《fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks》(基于区域建议网络的实时检测器),突破了先前一系列的产生目标框方法与检测网络相分离的旧模式,首次在一个网路中整合了rp和detection,使用rpn网络替代selectivesearch算法选择候选框,使得计算都在gpu内进行,结果表明算法的速度和精度都有了很大的提升。
2)基于回归的思想
虽然faster-r-cnn相对rcnn在计算速度方面取得了比较大的进步,但是仍然很难满足工业上实时性的要求,因此基于回归的思想直接从图片预测出目标物体的位置以及种类的方法被提出。具有代表性的算法有yolo、ssd。yolo(youonlylookonce)把目标判定和目标识别合二为一,在识别性能有了很大提升,达到45帧/每秒,而fastyolo可以达到155帧/每秒,yolo对小目标漏检较多,同时它的loss函数对不同大小的boundingbox(边界框)未做区分,因此较faster-r-cnn精度略低。ssd(singleshotmultiboxdetector)借鉴了fasterr-cnn中的anchor(锚点)机制,使用了多尺度的defaultbox(候选框),因此在保持yolo高速的同时效果也提升了精度。
基于上述深度学习的目标检测算法的优势在于检测精度高、鲁棒性强、对不同的场景适应性较好。
2、对车窗标志物进行检测的技术难点在于:
1)检测图片质量不稳定
由于卡口的摄像头的拍摄质量、安装角度、光照、天气等原因,拍摄的图片可能会出现模糊、暗淡、曝光、噪声等现象,导致算法的检测效果不稳定。
2)车窗内的环境比较复杂
车内摆放的纸张、毛巾、其它摆饰等容易对纸巾盒的检测造成干扰;挂饰形态多样,颜色不一导致检测比较困难。驾驶员与乘客的坐姿不稳定、方向盘与年检标等遮挡,衣服与安全带颜色非常相近,也容易导致安全带出现误检或者漏检。与打手机相近的干扰动作较多,而且手机目标较隐蔽,因此打手机误识别率与漏检率也较高。
3)检测目标的类别较多,训练的模型难以兼顾
年检标相对车窗的占比非常小,属于小目标检测,同时需要区分与年检标形状相似的通行证,行车仪等物体;挂饰的形态多样、长短不一;安全带会出现佩戴不规范、颜色与衣服相近;眼镜图像信息较少,在图片质量较差时难以区分是否有戴。口罩颜色比较多变,并且图片模糊的情况下会出现边缘不明显的情况;车窗标志物综合了小目标、细长物体、与背景区分度小等多个难点,需要模型具有较强的泛化性。传统的检测方法是针对每个模型单独训练出检测器,但是显存的占用与运行速度会成倍增加,难以满足实时性的要求。
4)检测精度、检测时间与显存占用难以兼顾
传统的检测模型速度快、易移植,但是检测精度低、鲁棒性不好。经典的深度学习网络有vgg(verydeepconvolutionalnetworksforlarge-scaleimagerecognition,针对大规模图像识别的深层网络),resnet(deepresiduallearningforimagerecognition,残差网络)等,这些网络检测精度高,但是存在显存占用较大和运行较慢等缺点。
综上,本方案主要针对车窗标志物的类别差异较大、检测环境复杂的情况提出以ssd模型框架对车窗标志物进行检测。实验结果表明,本发明对车窗标志物具有很好的检测效果。以下将详细介绍本发明具体实施例:
实施例1:
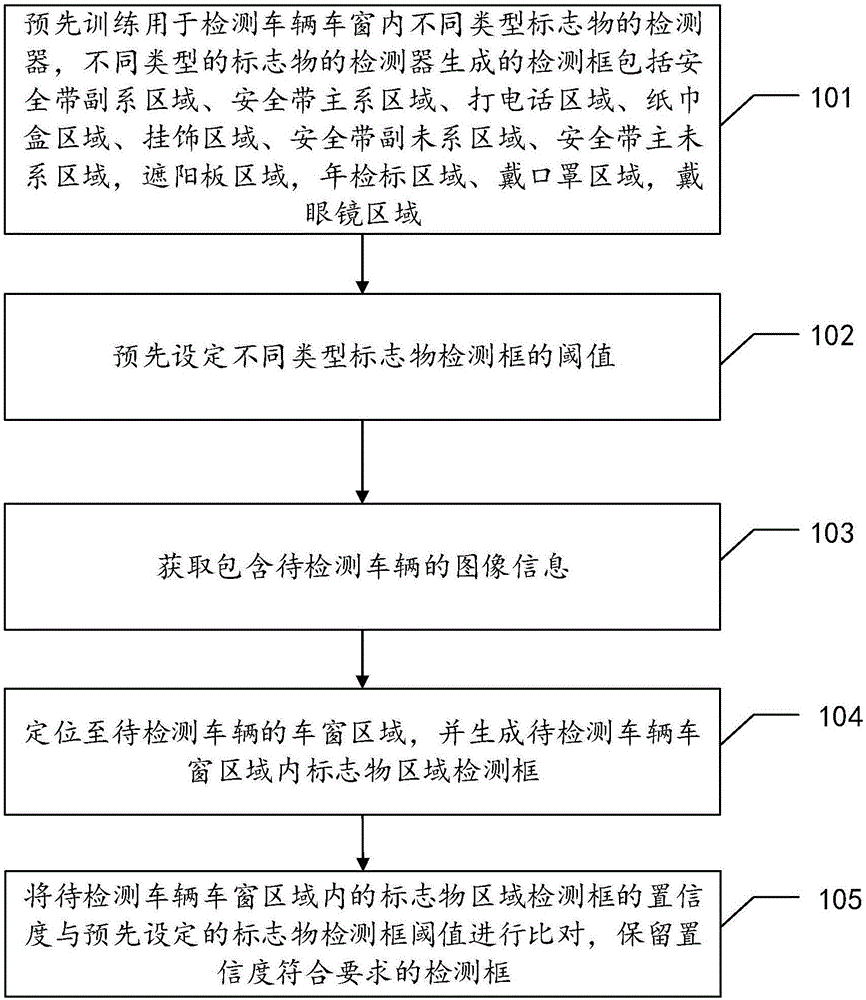
图1为本实施例流程示意图,一种车窗标志物的检测方法,包括,
步骤101,预先训练用于检测车辆车窗内不同类型标志物的检测器,不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
需要说明的是,这里的车窗指的是车辆前窗,标志物不仅仅包含在车窗上的年检标、遮阳板,还包括可以通过车窗看到的安全带副驾驶系区域、安全带主驾驶系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副驾驶未系区域、安全带主驾驶未系区域、戴口罩区域,戴眼镜区域。
还需要说明的是,现有的安全带检测的技术方案大都是把安全带检测器没有检测到的图片判别为安全带未系,当图片模糊时,安全带检测器性能下降时便会造成许多漏检,就会将模糊的系安全带的情形算作安全带未系,这种逻辑其实是有漏洞的。本实施例将安全带未系与安全带有系分别作为一种类别,并区分了驾驶人员和副驾驶人员,训练了安全带副系检测器、安全带主系检测器、安全带副未系检测器、安全带主未系检测器,当图片质量模糊时便会减少安全带未系的误检测率。
步骤102,预先设定不同类型标志物检测框的阈值;
需要说明的是,不同类型的标志物置信度是不同的,因此需要预先对不同类型的标志物的检测器生成的检测框设定相应的阈值,作为比对待检测车窗图片中的标志物置信度的基准。
步骤103,获取包含待检测车辆的图像信息;
需要说明的是,这里的待检测车辆的图像信息一般是是通过卡口、停车场等区域设置的的摄像机、照相机拍摄到的车辆图像信息。
步骤104,定位至待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
需要说明的是,这里获取的待检测车辆的车窗区域也就是目标车辆的图像信息,大小归一化后应同步骤101中用于训练检测器的图片大小一致。
步骤105,将待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
需要说明的是,不同类别的标志物的置信度都是不一样的,容易学习的类别置信度很高,比如年检标,打电话、戴眼镜这些置信度就小很多,因此每个类别的阈值都不一样。
还需要说明的是,这里保留的置信度符合要求的检测框,需要在实际测试过程中对不同类别的标志物预测置信度并不相同,为避免出现阈值设置过低出现误检及阈值设置过高出现漏检,需要根据实际情况进行相应的调整,如图2对副驾驶员未系安全带阈值设置过低,则如图3所示提高副驾驶员未系安全带阈值;如图4所示主驾驶员有系安全带阈值设置过高,则如图5所示降低主驾驶员有系安全带阈值。
综上,本实施例提出的车窗标志物检测方法,通过预先训练用于检测车辆车窗内不同类型标志物的检测器,获取待检测车辆图片并定位至所述待检测车辆的车窗区域,生成标志物区域检测框再通过比对筛选最终标记出符合条件的车窗标志物区域,检测精度高、鲁棒性强、对不同场景的适应性好,解决了现有技术存在的检测精度不高、类别不全面的技术问题。
实施例2:
图6为本实施例流程示意图,一种车窗标志物的检测方法,包括,
步骤201,预先训练用于检测车辆车窗内不同类型标志物的检测器,不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
需要说明的是,这里的车窗指的是车辆前窗,标志物不仅仅包含在车窗上的年检标、遮阳板,还包括可以通过车窗看到的安全带副驾驶系区域、安全带主驾驶系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副驾驶未系区域、安全带主驾驶未系区域、戴口罩区域,戴眼镜区域。
还需要说明的是,现有的安全带检测的技术方案大都是把安全带检测器没有检测到的图片判别为安全带未系,当图片模糊时,安全带检测器性能下降时便会造成许多漏检,就会将模糊的系安全带的情形算作安全带未系,这种逻辑其实是有漏洞的。本实施例将安全带未系与安全带有系分别作为一种类别,并区分了驾驶人员和副驾驶人员,训练了安全带副系检测器、安全带主系检测器、安全带副未系检测器、安全带主未系检测器,当图片质量模糊时便会减少安全带未系的误检测率。
作为本实施例一种具体的实现方式,不同类型的标志物的检测器生成的检测框的选定方式为,安全带副系区域为副驾驶人员身上安全带可见的区域,安全带主系区域为驾驶人员身上安全带可见的区域,打电话区域为手机及手腕区域,纸巾盒区域为盒子加上纸巾被抽出的部分的最小外接矩形,挂饰区域不包括细线部分,安全带副未系区域为副驾驶人员的肩膀区域加人脸下半部分区域,安全带副主未系区域为驾驶人员的肩膀区域加人脸下半部分区域,遮阳板区域、年检标区域、戴口罩区域、戴眼镜区域均为最小外接矩形。
具体地,对采集到的车窗图像的实际情况,本实施例对各类型标志物的标注进行了一些特定的标注方式,这里的标注相当于对标志物进行框选,一般通过矩形检测框来进行标注:对于安全带有系的情况,标注区域为驾驶人员或副驾驶人员身上可见安全带最小外接矩形;对于打电话检测,为为避免误检其它发亮的矩形物体,将标注的区域定为手机加手腕区域;在驾驶室内靠近车窗位置随意放置的纸盒、路线牌、出租车的证件牌都容易对纸巾盒识别造成干扰,本实施例中仅把纸巾抽出来的才算是纸巾盒;对于挂饰这种细长物体,标注最易辨识的区域,舍弃过长的细线部分;针对安全带未系的违法抓拍要求,本实施例增加了安全带未系的标注属性,即标注区域为肩膀区域加人脸下半部分区域,座椅跟肩膀相似度比较大,因此增加部分人脸区域信息进行区分,以避免没有检测到安全带就视为未系安全带的不稳定情况;对遮阳板区域、年检标区域、戴口罩区域、戴眼镜区域罩区域均为最小外接矩形。
在本实施例的标注过程中,对不同类型的标志物进行赋值,标注的类型里面分别为副驾驶员系安全带(安全带副系)、主驾驶员系安全带(安全带副系)、主驾驶员打电话(打电话)、纸巾盒、挂饰、副驾驶员未系安全带(安全带副未系)、主驾驶员未系安全带(安全带主未系)、遮阳板、年检标、戴口罩、戴眼镜,标签对应的类型值如图7所示。对不同类型的标志物的标注情况,请参阅图8至图13为不同类型标志物标注情况示意图。
在本实施例中,预先训练用于检测车辆车窗内不同类型标志物的检测器具体包括,基于ssd算法进行训练,对输入的图像样本同时进行检测和分类,预先建立的训练集包括不同类型标志物的类别信息及位置信息,具体的:
步骤2011,获取车窗样本图像,并把图像归一化到300*300像素大小;
步骤2012,对归一化后的车窗样本图像上进行标注,标定出车窗标志物的坐标信息,并将坐标信息保存在与车窗样本图像名称一一对应的xml文件中,xml文件中记录有所述jpg图像中包含的标志物类别及标志物类别对应的坐标信息;
需要说明的是,车辆车窗样本图像,把车窗图像大小归一化为300*300像素,按照规则对车窗里面的不同标志物进行标注,标注后的文件为jpg格式的车窗图像文件,及与所述jpg格式的图像文件名称一一对应的xml文件,所述xml文件中记录有所述jpg图像中包含的标志物类别及所述标志物类别对应的坐标信息。
具体的,如作为某一确定的样本图像1.jpg,有相对应的1.xml,假设1.xml中包含了挂饰和年检标两个标志物类别,其中挂饰的最小外接矩形的左上角和右下角坐标为(136,89)、(153,163),根据两点坐标便可知挂饰的宽和高分别为17和74。
步骤2013,统计不同类型车窗标志物的宽高在300*300的二维坐标上的分布,获取不同类型车窗标志物的宽高分布规律;
需要说明的是,采用本实施例对车窗标志物进行标注的方式,使得训练样本不同类别标志物在300*300的二维坐标系的分布向二维左边的对称线和原点更加靠拢,从而使得defaultboxes的设计更加容易。
还需要说明的是,具体的,假设训练集,也就是获取的车辆车窗样本图像中有多个宽高不一的挂饰,每个挂饰根据宽高在300*300的二维坐标上映射为一个点,那么把所有的挂饰都映射到二维坐标中,便可得到如图14所示挂饰的宽高分布规律,其中,横坐标表示宽、纵坐标表示高,挂饰整体细长,高:宽保持在一个相对较大的比例。同理,可得到其他标志物的分布规律,如图15所示的安全带副系、安全带主系、打电话、纸巾盒、挂饰、安全带副未系、安全带主未系,遮阳板,年检标、戴口罩,戴眼镜共计11种类别标志物的分布规律。图16所示为该11种不同类别的车窗标志物在300*300的二维坐标系上的整体分布情况,其中红色的区域为训练集中所有年检标宽和高值所分布的区域,青色的区域为挂饰所分布的区域,黑色的区域为安全带已系分布的区域;蓝色的区域为安全带未系分布的区域;紫色的区域为遮阳板的分布;黄色的区域代表纸巾盒的分布;绿色的点代表打电话的分布。
还需要说明的是,ssd检测算法在训练的过程中首先生成特定大小的defaultboxes(候选框),这些候选框在训练图片中进行扫描时,如果候选框与标定好的最小外接矩形框(groundtruthboxes)的重叠度(iou,intersectionoverunion)大于一定阈值时,那么被defaultboxes框到的目标类别的部分区域则会选定为正样本,从而参与到模型的训练中。但是,从图16中可以看到各个类别目标的宽高分布差异很大。defaultboxes如果采取随机方式,则不能保证每个类别的训练样本都可以被框定为正样本,从而导致实际测试过程中模型具有偏好性,而参与训练的某个类别样本数量越多,则该类别测试效果越好,因此,需要根据训练集中不同类型的车窗标志物的宽高分布规律,设计defaultboxes,使得训练集中各个类别的样本尽可能框定成正样本参与到模型训练中。
步骤2014,设计适用于不同类型车窗标志物的defaultboxes。
需要说明的是,在完成训练集样本的采集和各类型标志物映射在二维坐标中的分布规律后,根据车窗标志物的分布规律设计defaultboxes,而在实际操作中需要兼顾小目标与细长物体,使得defaultboxes与各类别的标注区域的iou(intersectionoverunion,重叠度)尽可能大,目的是使得各类别都产生足够的正样本,以便能够充分的训练。
具体的,计适用于不同类别标志物的defaultboxes计算方法如下:
其中,sk为第k个等分节点的尺度,smin为设计的附加网络最小尺度,smax为附加网络最大尺度,m是指在最小与最大之间等分出m个区间;
其中:
其中:sk为第k个等分节点的尺度,sk+1为第k+1个等分节点的尺度。
需要说明的是,比如设定smin=20,smax=120,m=6,则sk={20,40,60,80,100,120}。当sk=20时,根据公式得到的6个defaultboxes的宽高分别为{(20,20),(28.28,28.28),(14.14,28.28),(28.28,14.14,(11.54,34.64)),(34.64,11.54)}。因此,每个sk分别可以得到对应的6个defaultboxes,请参考如下表1:
表1每一层defaultboxes的计算结果
把每个sk得到的相应的defaultboxes根据宽高映射到300*300的二维坐标中(横坐标为宽,纵坐标为高),不同sk得到的defaultboxes用不同的颜色表示,得到如图17所示的映射的效果。
步骤2015,对defaultboxes进行微调。
需要说明的是,实际训练过程中defaultboxes的分布设计需要根据测试结果进行微调。同时,对于某些指标的定义比较重要,比如打电话、安全带未系、年检标,那么可以使得图16中的二维坐标上这几个类别的数据点簇附近的defaultboxes的点更加的靠拢。并且在ssd中{s1,s2,s3,s4,s5,s6}分别对应的6层特征图大小为{(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)},那么每层映射回原图产生的defaultboxes数量为{38*38*6,19*19*6,10*10*6,5*5*6,3*3*6,1*1*6}。
比如,通过计算可知ssd附加网络特征层38*38可以映射回原图得到38*38*6个宽高分布在[11.54,34.62]的defaultboxes。因此,这一特征层对于小目标(如年检标、带口罩、带眼镜)的学习效果具有较大的贡献度。
本实施例中通过统计训练集的分布规律设计相应的defaultboxes,这里的分布规律根据不同卡口场景会有些不同,所以需要根据测试结果进行微调。同时,也能根据指标的重要程度,调整模型的偏好。
步骤202,预先设定不同类型标志物检测框的阈值;
需要说明的是,不同类型的标志物置信度是不同的,因此需要预先对不同类型的标志物的检测器生成的检测框设定相应的阈值,作为比对待检测车窗图片中的标志物置信度的基准。
步骤203,获取包含待检测车辆的图像信息;
需要说明的是,这里的待检测车辆的图像信息一般是是通过卡口、停车场等区域设置的的摄像机、照相机拍摄到的车辆图像信息。
步骤204,定位至待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
需要说明的是,这里获取的待检测车辆的车窗区域也就是目标车辆的图像信息,大小归一化后应同步骤201中用于训练检测器的图片大小一致。
步骤205,将所述待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
需要说明的是,不同类别的标志物的置信度都是不一样的,容易学习的类别置信度很高,比如年检标,打电话、戴眼镜这些置信度就小很多,因此每个类别的阈值都不一样。
还需要说明的是,这里保留的置信度符合要求的检测框,需要在实际测试过程中对不同类别的标志物预测置信度并不相同,为避免出现阈值设置过低出现误检及阈值设置过高出现漏检,需要根据实际情况进行相应的调整,如图2对副驾驶人员未系安全带阈值设置过低,则如图3所示提高副驾驶人员未系安全带阈值;如图4所示主驾驶人员有系安全带阈值设置过高,则如图5所示降低主驾驶人员有系安全带阈值。
将本实施例的方法应用到实际场景中,测试车窗标志物样例检测框的字母标签对应的类别为:副驾驶员系安全带(fux)、主驾驶员系安全带(zhux)、主驾驶员打电话(dianh)、纸巾盒(zhij)、挂饰(guas)、副驾驶员未系安全带(fuwx)、主驾驶员未系安全带(zhuwx)、遮阳板(zheyb)、年检标(nianjb)、戴口罩(kouz)、戴眼镜(yanj)。同时,字母标签后数字代表置信度,图18-图26为具体测试示意图。
综上,本实施例提出的车窗标志物检测方法,通过预先训练用于检测车辆车窗内不同类型标志物的检测器,获取待检测车辆图片并定位至所述待检测车辆的车窗区域,生成标志物区域检测框再通过比对筛选最终标记出符合条件的车窗标志物区域,检测精度高、鲁棒性强、对不同场景的适应性好,解决了现有技术存在的检测精度不高、类别不全面的技术问题。根据测试结果表明,模型的性能能够同时满足检测精度与实时性的要求。
实施例3:
图27为本实施例结构示意图,一种车窗标志物的检测装置,包括,
训练单元301,用于预先训练用于检测车辆车窗内不同类型标志物的检测器,不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
预设单元302,用于预先设定不同类型标志物检测框的阈值;
获取单元303,用于获取包含待检测车辆的图像信息;
定位单元304,用于定位至待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
比对单元305,用于将所述待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
实施例4:
图28为本实施例结构示意图,一种车窗标志物的检测装置,包括,
训练单元401,用于预先训练用于检测车辆车窗内不同类型标志物的检测器,不同类型的标志物的检测器生成的检测框包括安全带副系区域、安全带主系区域、打电话区域、纸巾盒区域、挂饰区域、安全带副未系区域、安全带主未系区域,遮阳板区域,年检标区域、戴口罩区域,戴眼镜区域;
获取模块4011,用于获取车窗样本图像,并把图像归一化到300*300像素大小;
标注模块4012,用于对归一化后的车窗样本图像上进行标注,标定出车窗标志物的坐标信息,并将坐标信息保存在与所述车窗样本图像名称一一对应的xml文件中,xml文件中记录有jpg图像中包含的标志物类别及标志物类别对应的坐标信息;
统计模块4013,用于统计所述不同类型车窗标志物的宽高在300*300的二维坐标上的分布,获取所述不同类型车窗标志物的宽高分布规律;
设计模块4014,用于设计适用于不同类型车窗标志物的defaultboxes;
所述设计模块设计适用于不同类别标志物的defaultboxes计算方法如下:
其中,sk为第k个等分节点的尺度,smin为设计的附加网络最小尺度,smax为附加网络最大尺度,m是指在最小与最大之间等分出m个区间;
其中:
其中:sk为第k个等分节点的尺度,sk+1为第k+1个等分节点的尺度。
微调模块4015,用于对defaultboxes进行微调。
预设单元402,用于预先设定不同类型标志物检测框的阈值;
获取单元403,用于获取包含待检测车辆的图像信息;
定位单元404,用于定位至待检测车辆的车窗区域,并生成待检测车辆车窗区域内标志物区域检测框;
比对单元405,用于将所述待检测车辆车窗区域内的标志物区域检测框的置信度与预先设定的标志物检测框阈值进行比对,保留置信度符合要求的检测框。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所披露的方法、装置,可以通过其它的方式实现。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!