基于ORB与U-net的花卉三维重建方法与流程
本发明涉及三维重建技术,具体涉及花卉三维重建方法。
背景技术:
目前三维重建技术过程中,针对小场景物体的三维重建主要是基于kinectfusion的稠密slam技术,通过利用kinect等深度相机围绕场景物体采集深度图像,进而针对深度图像进行处理从而得到小场景物体的三维重建模型。kinectfusion的技术流程如下:首先使用kinect相机围绕小场景物体采集深度图像,利用kinect相机内参将原始的2d深度图像转化为相机坐标系下的3d点云并计算法向量;利用icp迭代极小化点到平面的能量函数求出当前帧的相机位姿;根据相机的当前姿态将3d点云融合到tsdf体素模型当中;根据光线投影算法从tsdf模型中得出当前视角所能看到的场景表面,并得出投影得到的点云以及法向量,利用投影得到的点云与法向量与后一帧的数据进行icp迭代计算下一帧的位姿。
当前的三维重建方法,对于花卉类遮挡严重的物体扫描,由于kinect相机采用的tof或者结构光技术,导致被遮挡的部分没有深度数据而无法重建。在实践中,确保扫描能够覆盖花卉表面所有的点也是不可行的(花卉类物体经常摆放在墙角且花卉底部无法扫描),因而会导致利用现有的三维重建方法,花卉类物体的重建模型出现大量空洞。同时由于kinectfusion方法只是当前帧与上一帧之间的配准进行姿态估计,没有全局位姿优化以及回环检测和回环闭合,使得三维重建时针对于深度图的位姿估计十分不准确,与此同时针对于相机本身的快速移动鲁棒性很低,只能进行缓慢移动建模,容易丢失相机位姿。
技术实现要素:
针对当前花卉重建的模型出现空洞的缺陷,本发明提出一种基于orb与u-net的花卉三维重建方法。
本发明是采用以下的技术方案实现的:一种基于orb与u-net的花卉三维重建方法,包括:
a、基于orb的深度相机三维重建:
a1、跟踪线程track:利用提取orb算子进行帧与帧之间的粗匹配,计算位姿;
a2、帧集合内部局部优化线程localmap:在帧集合内部利用bundleadjustment进行位姿优化;
a3、帧集合间全局优化线程globalmap:对每个帧集合求出共视度最高的一帧作为关键帧,送入全局的关键帧集合检测是否出现回环以及进行全局的ba位姿优化;
a4、重定位:将追踪失败的帧利用字典得到自己的词袋向量,然后与所有的关键帧计算相似度得分,找到得分最高且超过阈值的关键帧k即认为重定位成功;
b、基于u-net的三维重建补全:
b1、获得训练集和测试集的作为网络输入的部分tsdf模型;
b2、生成花卉的部分三维模型:利用步骤a中的三维重建方法对现实中的花卉进行扫描的部分建模,并将最终生成部分tsdf模型导出;
b3、模型补全阶段:利用卷积神经网络(cnn)中的u-net网络结构训练出补全模型的深度学习网络,将前一步骤生成的部分tsdf模型导入网络得到补全后完整的tsdf模型;
b4、最终模型生成阶段:将补全后的tsdf模型转化为obj模型导出得到最终的花卉三维重建模型。
进一步地,所述步骤a1包括:
a11、对于深度相机读取的每一帧深度图提取orb特征描述子,记录下orb特征的像素坐标以及orb特征的描述子;
a12、若当前帧为第一帧,则初始化三维重建系统,并将第一帧定为世界坐标系,否则将当前帧与前一帧的orb特征进行匹配,计算当前帧到前一帧的相机姿态变换t,在求解t之前统计当前帧与前一帧的orb匹配对有多少,若匹配对太少则跟踪失败,进入重定位流程;
a13、将每一个跟踪到的帧融合进tsdf模型中。
进一步地,所述步骤a2包括:
a21、将一个帧集合内部的所有帧的orb特征根据跟踪线程track中得到的相机姿态投影到世界坐标系中;
a22、将帧集合中的所有orb特征根据空间位置以及描述子进行融合,并将融合后的mappoint与各个帧中的图像坐标系orb坐标匹配起来,优化帧集合内部的mappoint以及帧集合内各个帧的位姿,将优化后的各个帧首先根据跟踪线程track的位姿估计从tsdf模型中去除,然后得到的相机位姿将各个帧再重新融入到tsdf模型中;
a23、统计得到各个帧中与其他帧共视最多的帧作为关键帧,将该帧送入帧集合间全局优化线程globalmap。
进一步地,所述步骤a3中回环检测为:系统首先导入一个orb算子的字典,每个送来的关键帧根据字典得到自己的词袋向量,每个关键帧都与非自己前一关键帧的所有关键帧的词袋向量计算分数表达两帧相似度,当相似度超过阈值时则认为出现了回环;检测到回环则需要进行回环闭合,将当前关键帧向检测到回环的帧利用orb特征进行匹配,优化当前关键帧帧世界坐标系下的mappoint在检测到回环的帧上的重投影误差来优化当前帧的pose以及当前帧orb特征的世界坐标系位置,然后将优化后的当前帧的mappoint与检测到回环的帧的mappoint在世界坐标系下进行融合。
进一步地,所述步骤a4包括:将当前帧的orb特征与关键帧k的orb特征进行匹配,然后利用epnp将k在世界坐标系下的orb特征与当前帧图像坐标系下的像素坐标的匹配对进行求解得到位姿,然后将关键帧k作为帧集合的第一帧,重定位成功并继续回到追踪线程开始三维重建。
进一步地,根据步骤a22中localmap中的mappoint与各个帧图像的匹配关系,统计得到各个帧中与其他帧共视最多的帧作为关键帧。
进一步地,所述步骤b1中利用在maya下的大量三维花卉模型生成训练集和测试集groundtruth的tsdf模型,通过模拟出一条深度相机扫描的相机轨迹,得到训练集和测试集的作为网络输入的部分tsdf模型。
所述步骤b4中,利用matlab中的isosurface函数将tsdf模型转化为obj模型。
与现有技术相比,本发明的优点和积极效果在于:
本发明采用了深度学习与传统稠密slam相结合的方法来实现针对于花卉类遮挡严重的物体三维重建困难的问题,一方面,在kinectfusion的基础上加入了全局姿态优化以及回环检测和重定位,使得相机姿态估计的准确度大大提高,能够得到质量很高的花卉三维重建的部分模型;另一方面,由于花卉类物体的三维数据集较小因而采用u-net网络结构的cnn网络,可以在拥有较小数据集的情况下获得较好的效果。通过深度学习的方法可以很好的填充在传统稠密slam方法中存在大量空洞的问题,在填补空洞的网络实现了端到端的补全方法,能够大量节约补全空洞的时间。
附图说明
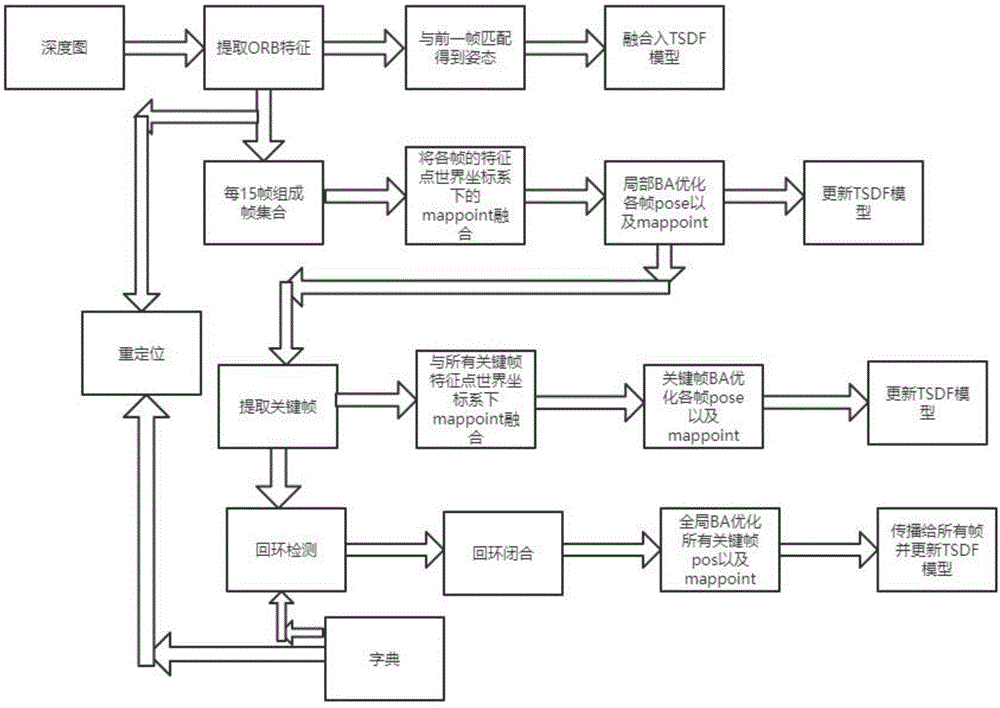
图1为本发明总体流程图;
图2为本发明实施例tsdf网络模型。
具体实施方式
本发明利用了u-net卷积神经网络,针对于深度相机扫描得到的tsdf体素模型数据训练,通过对tsdf体素数据的补全来完成对于三维模型的补全,创新性的将u-net网络与三维重建结合起来用来解决针对于遮挡严重的花卉三维重建问题,由于关于花卉类的三维数据集数据量较少,而u-net在针对于较小的训练数据集时能显现出很大的优势。在训练时所用的数据集来自于maya中建模好的大量花卉模型即groundtruth,通过模拟相机的扫描轨迹可以得到花卉模型的部分tsdf数据作为网络的输入。同时在深度相机三维重建部分,在kinectfusion的基础上加入了全局位姿优化以及回环检测和回环闭合,并且针对于移动的鲁棒性问题提出了重定位的解决方案。
下面结合附图和具体实施方式对本发明做进一步详细地说明。
一种基于orb与u-net的花卉三维重建方法,参考图1,包括:
一、基于orb的深度相机三维重建:
a.跟踪线程track:
1.对于深度相机读取的每一帧深度图提取orb特征描述子,记录下orb特征的像素坐标以及orb特征的描述子。
2.若当前帧为第一帧,则初始化三维重建系统,并将第一帧定为世界坐标系。否则将当前帧与前一帧的orb特征进行匹配,计算当前帧到前一帧的相机姿态变换t,这个过程需要将当前帧的初始姿态设置为前一帧姿态,然后将当前帧的orb特征变换到前一帧的图像坐标系得到投影误差,利用高斯-牛顿法最小化投影误差迭代优化位姿即可得到t。
在求解t之前需要统计当前帧与前一帧的orb匹配对有多少,若匹配对太少则跟踪失败,进入重定位流程。
3.利用kinectfusion中的tsdf模型以及raycast光线投影算法将每一个跟踪到的帧融合进tsdf模型中。
d’(v):融合后的tsdf值;
d(v):融合前的tsdf值;
di(v):要融入的tsdf值;
w(v):原有的tsdfd(v)权重;
wi(v):要融入的tsdfdi(v)的权重,为1;
w’(v):融合后d’(v)的权重。
本发明利用提取orb算子进行帧与帧之间的粗匹配,相对于sift算子而言orb算子计算速度非常快,针对于实时三维重建中对计算速度的要求十分适合。
b.帧集合内部局部优化线程localmap:
将一个帧集合内部的所有帧的orb特征根据跟踪线程track中得到的相机姿态投影到世界坐标系中。
5.将帧集合中的所有orb特征根据空间位置以及描述子进行融合得到mappoint,并将融合后的mappoint与各个帧中的图像坐标系orb坐标匹配起来,通过bundleadjustment优化帧集合内部的mappoint以及帧集合内各个帧的位姿。将优化后的各个帧首先根据跟踪线程track的位姿估计从tsdf模型中去除:
d’(v):去除后的tsdf值;
d(v):去除前的tsdf值;
di(v):要去除的tsdf值;
w(v):原有的tsdfd(v)权重;
wi(v):要去除的tsdfdi(v)的权重,为1;
w’(v):去除后d’(v)的权重。
然后根据帧集合内部局部优化线程localmap中ba后得到的相机位姿将各个帧再重新融入到tsdf模型中,将原来姿态的tsdf去除然后把优化后姿态的tsdf融入即为更新tsdf模型。
6.根据5中localmap中的mappoint与各个帧图像的匹配关系,每15帧组成一个帧集合,统计得到各个帧中与其他帧共视最多的帧作为关键帧,将该帧送入帧集合间全局优化线程globalmap。
c.帧集合间全局优化线程globalmap:
7.对于帧集合内部局部优化线程localmap送来的关键帧,将关键帧中的mappoint投影到世界坐标系中,并与整个关键帧集合的mappoint进行融合,然后根据融合后的mappoint与当前关键帧图像坐标系下orb特征进行匹配,之后通过bundleadjustment最小化重投影误差,优化该关键帧的位姿以及世界坐标系下的该帧mappoint的位置,然后根据该关键帧所在的帧集合中其他的帧与该帧的位姿变换,将该关键帧所在的帧集合中所有的帧对tsdf模型进行去除与再融合操作。
8.在进行全局优化之前,需要先将帧集合内部局部优化线程送来的关键帧进行回环检测,若检测到回环则需要进行回环闭合。对于回环检测,系统首先导入一个orb算子的字典,每个送来的关键帧根据字典得到自己的词袋向量,每个关键帧都与非自己前一关键帧的所有关键帧的词袋向量计算分数表达两帧相似度,当相似度超过阈值时则认为出现了回环。将当前关键帧向检测到回环的帧利用orb特征进行匹配,并利用bundleadjustment优化当前关键帧帧世界坐标系下的mappoint在检测到回环的帧上的重投影误差来优化当前帧的pose以及当前帧orb特征的世界坐标系位置。然后将优化后的当前帧的mappoint与检测到回环的帧的mappoint在世界坐标系下进行融合。然后将该优化后的关键帧pose根据其他帧与该帧的相机姿态变换传播给属于本关键帧所在的帧集合中的其他帧,当前关键帧前一个帧集合中的帧,检测到回环匹配的帧的帧集合以及其相邻的另外两个帧集合。然后进行全部所有关键帧和mappoint的全局bundleadjustment优化所有关键帧位姿以及mappoint,并将其传播给各个关键帧的帧集合,将所有帧对tsdf模型进行去除与再融合操作。
针对于传统的kinectfusion类三维重建方法本发明提出了一种新的完整的位姿优化、回环检测以及回环闭合的流程,在对于相机移动较快情况下的建模有了很好的适应。整个位姿优化、回环检测以及回环闭合的流程申请人的主要创新,通过提取关键帧利用关键帧代表15帧进行优化可以避免掉大量的帧优化计算,同时方便进行回环检测。通过局部以及全局的位姿优化使得针对于仅仅只有帧与帧匹配的位姿计算方法精确度有了很大提高,避免了三维重建中常见的重影等问题。
d.重定位:
9.当进行orb特征匹配时,若匹配对太少则会认为是追踪失败因此进入重定位。将追踪失败的帧利用字典得到自己的词袋向量,然后与所有的关键帧计算相似度得分,找到得分最高且超过阈值的关键帧k即认为重定位成功。将当前帧的orb特征与关键帧k的orb特征进行匹配,然后利用epnp将k在世界坐标系下的orb特征与当前帧图像坐标系下的像素坐标的匹配对进行求解得到位姿。然后将关键帧k作为帧集合的第一帧,重定位成功并继续回到追踪线程开始三维重建。
二、基于u-net的三维重建补全:
1.首先利用在maya下的大量三维花卉模型生成训练集和测试集groundtruth的tsdf模型,通过模拟出一条深度相机扫描的相机轨迹,得到训练集和测试集的作为网络输入的部分tsdf模型。
2.生成花卉的部分三维模型:利用上文中的三维重建方法对现实中的花卉进行扫描的部分建模,并将最终生成模型的tsdf模型导出,由于花卉类的物体遮挡严重以及kinect相机自身的限制,此时的tsdf模型为花卉的部分模型
3.模型补全阶段:利用卷积神经网络(cnn)中的u-net网络结构训练出补全模型的深度学习网络,将前一步骤生成的部分tsdf模型导入网络得到补全后完整的tsdf模型。网络模型参考图2,在训练网络时,输入的为32^3大小的tsdf模型,两个通道分别存储tsdf的数值以及当前位置是否为空洞的标记,网络第一层为卷积层,卷积核为4^3,卷积步长为2,输出通道数为80,激活函数为leakyrelu;网络第二层为卷积层,卷积核为4^3,卷积步长为2,输出通道数为160,经过batchnormalization后用leakyrelu函数激活;网络第三层为卷积层,参数与第二层相同,输出通道数为320;网络第四层为卷积层,卷积核为4^3,卷积步长为1,输出通道数为640,经过batchnormalization后用leakyrelu函数激活;第五层是全连接层,输入输出节点都是640,激活函数为relu;第六层也是全连接层参数与第五层相同,然后rehsape为640*1^3;第七层为反卷积层,输入为第六层的输出与第四层输出在通道维度上进行合并(即u-net结构),因而输入为1280*1^3,反卷积核为4^3,步长为1,输出通道为320,经过batchnormalization后用relu函数激活;第八层为反卷积层,输入为第七层输出与第三层输出在通道维度上合并,因而输入为640*4^3,反卷积核为4^3,步长为2,输出通道为160,经过batchnormalization后用relu函数激活;第九层为反卷积层,输入为第八层输出与第二层输出在通道维度上合并,因而输入为320*4^3,反卷积核为4^3,步长为2,输出通道为80,经过batchnormalization后用relu函数激活;第十层为反卷积层,输入为第九层输出与第一层输出在通道维度上合并,反卷积核为4^3,步长为2,输出通道为1。
groundtruth为32^3,单通道记录的为每个位置的真实tsdf的值。在计算loss的时候,只计算空洞位置的网络输出结果与groundtruth该位置的l1loss,这一步需要利用输入中第二通道所记录空洞位置标记来对网络输出结果以及groundtruth进行筛选。
利用adam算法进行反向传播。
4.最终模型生成阶段:利用matlab中的isosurface函数将上一步中补全后的tsdf模型转化为obj模型导出得到最终的花卉三维重建模型。
u-net网络主要是针对于二维图像的分割任务,本发明将其引入到三维重建完成后的补全任务。由于u-net网络有先卷积再反卷积的编码解码过程,针对于三维的tsdf体素网格可以最终预测出针对于每个体素的值,很适合补全任务。u-net网络的另一个优势在于针对于数据集很小的任务也可以有出色的表现,三维花卉数据集很少,针对于这样的任务u-net网络十分契合。据此选择将u-net网络加入到三维重建的后端处理。通过u-net网络的深度学习方法补充上三维重建方法中的空洞,首次将两者结合起来从而实现一套完整的建模整个完整花卉模型的流程。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!