网页内容自动提取方法与流程
本发明属于网页内容提取技术领域,具体涉及一种网页内容自动提取方法,特别是适用于期刊文献摘要页面内容的提取。
背景技术:
随着信息技术的发展,互联网在信息获取中的重要性正与日俱增。互联网也是科研工作者获取最新发表文献的有效途径。学术期刊出版商(elsevier、wiley、taylor&francis等)在主站提供期刊文献摘要页面。从这些摘要页面提取作者、发表时间、摘要等信息是建立整合数据库的要点,也是难题。
网页内容提取技术是信息提取(informationextraction)领域一直以来的热点问题。现有的方法大致可以分为三类:一是基于模板的方法,这种方法根据网页元素的xpath、css表达式进行提取,具有准确性强的优点,但创建模板需要消耗大量人力,大量模板难于维护,且对网页结构的改变鲁棒性差;二是基于dom树的方法,这类方法将网页解析为dom树,通过监督或半监督的学习方法,将目标网页与标注页面进行树结构匹配(alignment)或部分匹配(partialalignment),对目标页面进行标注,进而提取网页内容,这类方法效率不高(shing-ling算法时间复杂度与树的深度成正比),并且需要多个由同一模板生成的页面作为输入;三是基于视觉信息的方法,比如微软亚洲研究院提出的vips页面分割算法。这类方法将页面按照背景颜色、文字密度、字体等线索(cue)分割成若干视觉块(visualblock),通过支持向量机(svm)或神经网络模型学习得到各视觉块重要性指数,进而提取网页正文内容;这种方法时间、空间复杂度均较高,且依赖于人为制定的规则,对于新型网页模板鲁棒性差。
技术实现要素:
针对上述技术问题,本发明的目的在于提供一种网页内容自动提取方法,该方法采用快速傅里叶变换(fft)和对数盖伯滤波器取代传统视觉算法,降低了时间、空间复杂度,提高了算法的时间、空间效率。
为实现上述目的,本发明所采取的技术方案是:
一种网页内容自动提取方法,其特征在于,包括:
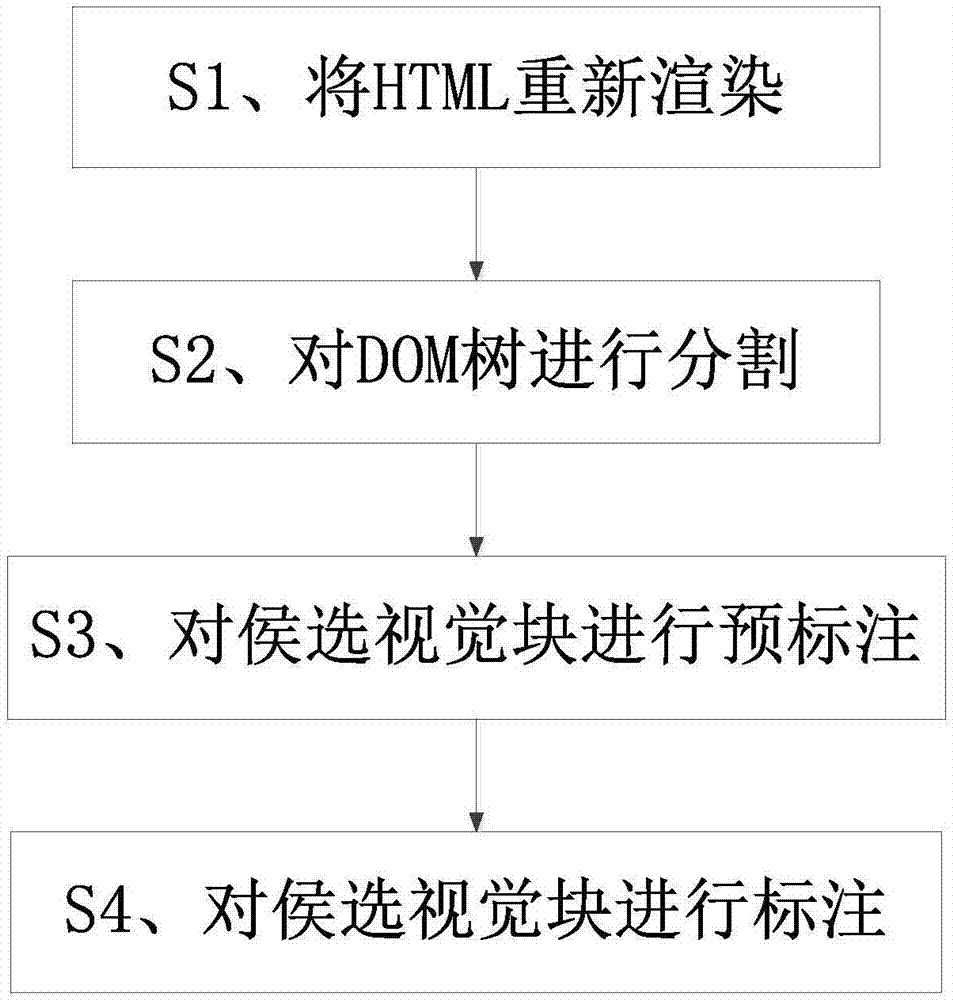
s1、将html重新渲染
首先建立html文档的dom树与渲染树,再根据所述dom树与渲染树对每个视觉块进行重新渲染,将img标签重新渲染成一个任意的几何图形,将p、div、a标签的每一行也重新渲染成一个任意的几何图形;
s2、对dom树进行分割
首先、按照广度优先顺序从根结点开始遍历dom树,直到找到子结点数大于1的结点;对该结点进行横向分割,然后选择该结点下的子结点中方向为纵向的结点;
其次、对所述方向为纵向的结点进行一次以上的纵向分割,然后选择该结点下的子结点中视觉块面积最大的结点;
最后、对所述视觉块面积最大的结点再进行横向分割,得到若干侯选视觉块;
s3、对侯选视觉块进行预标注
通过启发式算法或/和关键词频率算法给予每个侯选视觉块对应的预标注标签,所有的预标注标签组成一个预标注标签集合;
s4、对侯选视觉块进行标注
通过概率图模型对每个候选视觉块进行标注,得到对应的标注标签;将所有的标注标签一一与预标注标签集合匹配,筛选出落在预标注标签集合内的标注标签。
作为优选,所述dom树与渲染树只包含img、p、div、a标签。
作为优选,所述几何图形为一组纵横相交线段。
作为优选,所述几何图形为圆形或者椭圆形。
作为优选,所述几何图形为正多边形。
作为优选,所述结点的分割方法为:先通过快速傅里叶变换得到视觉块的频域表示,再采用一组正交的对数盖伯滤波分离视觉块频域表示的水平和垂直分量,最后对比视觉块的水平和垂直分量确定视觉块的方向。
本发明的有益效果为:本发明的方法采用快速傅里叶变换(fft)和对数盖伯滤波取代传统视觉算法,降低了时间、空间复杂度,提高了算法的时间、空间效率。另外,该方法采用概率图模型描述候选视觉块间的局部依赖关系,以适应不同站点与页面布局变化,对于页面布局的变化具有一定的鲁棒性。采用对数盖伯滤波判断页面元素方向性,结合条件向量场提高模型提取准确度,是网页内容自动提取的又一途径。所示几何图形为一组纵横相交线段,其中几何图形越简单计算就越简单,运算速度越快,一组纵横相交线段对应的运算速度就越快。
附图说明
图1是本发明的流程示意图。
图2是本发明实施例的示意图一。
图3是本发明实施例的示意图二。
图4是本发明实施例的示意图三。
图5是本发明实施例的示意图四。
具体实施方式
为了更好地理解本发明,下面结合实施例和附图对本发明的技术方案做进一步的说明(如图1、2、3、4、5所示)。
如图1所示,一种网页内容自动提取方法,包括:
s1、将html重新渲染
首先建立html文档的dom树与渲染树(rendertree),所述dom树与渲染树只包含img、p、div、a标签,再根据所述dom树与渲染树对每个视觉块(页面元素经由浏览器渲染引擎处理,表示为页面中面积不为零的矩形区域,称为视觉块。页面元素是由一组html标签包围的一段html代码,如<p>、<div>等。这里视觉块对应的是dom树中的结点)进行重新渲染,将img标签重新渲染成一个任意的几何图形(如一组纵横相交线段或多边形、圆、椭圆等规则的几何图形或者任意不规则的几何图形),将p、div、a标签的每一行(文字)也重新渲染成一个任意的几何图形;
如图2所示(图中每个十字形对应一个标签),下面以重新渲染成一组纵横相交线段(如十字形)为例:
img标签,将img标签重新渲染成一组纵横相交线段;
例如,img标签的视觉块对应页面中的一个矩形区域。矩形区域四个角点坐标从左上角点开始按逆时针方向排列分别为r1(x1,y1)、r2(x1,y2)、r3(x2,y2)、r4(x2,y1)。p(x1,(y1+y2)/2)、q((x1+x2)/2,y2)、r(x2,(y1+y2)/2)、s((x1+x2)/2,y1)分别为线段r1r2、r2r3、r3r4、和r4r1的中点。那么,可以将相互垂直平分的一组线段pr、qs(以下简称“十字形”)作为img标签重新渲染的结果。
p、div、a标签,将该类标签的每一行文字重新渲染成一组纵横相交线段;
例如,p标签的视觉块对应页面中的一个矩形区域。矩形四个角点坐标从左上角点开始按逆时针方向排列分别为r1(x1,y1)、r2(x1,y2)、r3(x2,y2)、r4(x2,y1)。矩形宽度(width)是w像素。p标签中包含的文字长度为c字节,字体大小(fontsize)为f像素。那么,通过估计可以得到p标签视觉块中文字行数n是
s2、对dom树进行分割(横向-纵向-横向分割)
如图3所示,首先、按照广度优先顺序从根结点开始遍历dom树,直到找到子结点数大于1的结点;对该结点进行横向分割(如图3中的vb1、vb2、vb3分成纵向三块),然后选择该结点下的子结点中方向为纵向的结点(即图3中的vb3);
如图4所示,其次、对所述方向为纵向的结点进行一次以上的纵向分割(如图4中的vb1、vb2、vb3分成横向三块),然后选择该结点下的子结点中视觉块面积最大的结点(即图4中的vb2);
当dom树出现嵌套结点时,需要多次的纵向分解以得到干净的结果;
如图5所示,最后、对所述视觉块面积最大的结点再进行横向分割(如图5中纵向分割的多个方框,所示方框从上至下分别代表期刊、doi、标题、作者、发布时间、摘要、关键词),得到若干侯选视觉块;
所述结点的分割(包括横向分割和纵向分割)方法为:先通过快速傅里叶变换(fft)得到视觉块的频域表示,再采用一组正交的对数盖伯滤波分离视觉块频域表示的水平和垂直分量,最后对比视觉块的水平和垂直分量确定视觉块的方向(若水平分量小于垂直分量,则视觉块方向为横向;若垂直分量小于水平分量,则视觉块方向为纵向);
(1)自顶而下遍历dom树
按照广度优先顺序从根结点开始遍历dom树,直到找到子结点数大于1的结点;若进行横向分解,则将该结点的n(n>1)个子结点按s2所述进行处理,选择排列方向为纵向的结点。若进行纵向分解,则选取子结点中视觉块面积最大的结点。
s3、对侯选视觉块进行预标注
通过启发式算法或/和关键词频率算法给予每个侯选视觉块对应的预标注标签,所有的预标注标签组成一个预标注标签集合;
所述启发式算法(heuristic)可参考extractingmultiplenewsattributesbasedonvisualfeatures。
所述关键词频率算法与搜索引擎中广泛使用的tf-idf算法类似。首先,对收集到的一组数据块中的文本片段进行词频统计,选择出现频率大于n的一组词作为关键词;统计这些关键词出现的频率,作为参考关键词频率;接着,对侯选视觉块中的文本片段进行词频统计,将侯选视觉块文本片段中出现的单词与关键词进行交集运算,将集合中的单词在候选文本片段中出现的频率与参考关键词频率相乘,再求和,即得到候选视觉块的关键词得分。若得分大于s,则给予相应标签(如期刊摘要页面中的标题、作者、摘要等;又如新闻页面中的新闻标题、新闻作者、发布时间等)。
s4、对侯选视觉块进行标注
通过概率图模型对每个候选视觉块进行标注,得到对应的标注标签;将所有的标注标签一一与预标注标签集合匹配,筛选出落在预标注标签集合内的标注标签。
所示概率图模型包括crf、mln等,可参考conditionalrandomfields:probabilisticmodelsforsegmentingandlabelingsequencedata。建立概率图模型选取的特征可参考template-independentnewsextractionbasedonvisualconsistency。
通过概率无向图模型对候选视觉块进行标注,得到页面关键信息(如图5)。关键信息是指页面中读者最为关心的部分信息,如期刊摘要页面中的标题、作者、摘要等。又如新闻页面中的新闻标题、新闻作者、发布时间等。
以crf为例。首先,收集200个页面,按照期刊、doi、标题、作者、发布时间、摘要、关键词、无效等八个标签进行人工标注。采用拟牛顿法训练crf模型。然后,计算各候选视觉块的特征向量。若仅考虑宽度-高度比ratio、字符数-面积比density、左上角点横坐标x、和左上角点纵坐标y四个特征,则候选视觉块的特征向量为(ratio,density,x,y)。将计算得到的特征向量按照候选视觉块的出现顺序依次输入crf模型,采用viterbi算法进行预测(inference)。至此,每个候选视觉块得到两种标签:一组预标注标签和一个标注标签。
以上说明仅为本发明的应用实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明申请专利范围所作的等效变化,仍属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!