基于L2重新正则化Adam切换模拟回火SGD的深度学习方法与流程
本发明涉及三维图像标准数据库数据的模式识别技术领域,特别是指一种基于l2重新正则化adam切换模拟回火sgd的深度学习方法。
背景技术:
深度学习作为目前最前沿的计算机理论及人工智能领域研究领域,其网络结构的搭建以及梯度下降环节的优化器研究是目前研究的重点与热点。目前应用较广泛的梯度下降优化器算法主要是sgd和adam以及基于这两种算法的各类变体。
sgd算法是基于最典型的梯度下山算法而衍生出来的,即随机使用固定数目的样本(如128个)就更新一次,但sgd收敛的速度仍然偏慢,而且可能会在梯度几乎为0的鞍点或梯度比较差的局部最优点两侧持续震荡,没有足够的应对策略跳出局部最优。
diederikkingma和jimmyba在2015年的国际学习表征会议上提出了adam,它结合了前面算法的加速特点,使用一阶和二阶两种动量做偏置校正后进行权重更新,它不受梯度的伸缩变换影响,收敛速度明显优于sgd。但它同样存在之前算法的缺点,一是二阶动量的累积可能会对前期出现的特征过拟合,而后期出现的特征很难纠正前期的拟合效果,导致梯度变化时大时小,可能在训练后期引起梯度下降的震荡,模型无法收敛。二是仍旧存在局部最优问题,在某些空间产生的起伏性区间进入后无法跳出。
目前深度学习领域主流的观点认为,adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的sgd往往能够取得更好的最终结果。
danieljiwoongim所设计的著名的多个特定超平面空间的寻优实验,证明了在这种类似的条件下,每两种算法几乎总会搜寻完全不同的方向,尤其是在“波谷”分列在“波峰”两侧且最小值相差不大的时候。这充分证明不同算法需要进行筛选和切换的意义。
技术实现要素:
本发明要解决的技术问题是提供一种基于l2重新正则化adam切换模拟回火sgd的深度学习方法。
该方法包括步骤如下:
(1)将标准数据库中的数据进行特征提取以及数据增强,将信号输入到l2重新正则化的adam为初始优化器的深度学习网络;每次迭代中依据得到的梯度,计算得到假设在该次迭代下切换模拟回火sgd优化器的学习率,以及该次迭代完成后深度学习网络权重ωt矩阵at=(ωt)tωt的迹tr(at)与其特征值的平方和qs(at);
(2)在步骤(1)中经过一定的判断条件,得到下一次迭代是否进行切换,若是,则切换至模拟回火sgd优化器,并使用该优化器至迭代结束;若否,则不改变优化器类型,继续步骤(1)及步骤(2)中迭代与判断的过程。
其中,步骤(1)中l2重新正则化的adam权重更新方法为
步骤(1)中模拟回火sgd的学习率更新方法为
步骤(1)中求得的模拟回火sgd优化器的学习率为
步骤(2)中一定的判断条件,具体过程如下:
其中
本发明的上述技术方案的有益效果如下:
上述方案中,与现有的算法相比,成功结合了adam前期收敛速度快和sgd后期收敛效果好的特点,在100次迭代次数内新算法的收敛速度高于sgd,在后期新算法的收敛效果则超过了adam,尤其在迭代次数小于250次时新算法的效率明显更高,且去除正常学习率衰减因素外的误差震荡相对较小。在需要减少迭代次数的前提下,新算法可以尽快的达到需要的效果。
附图说明
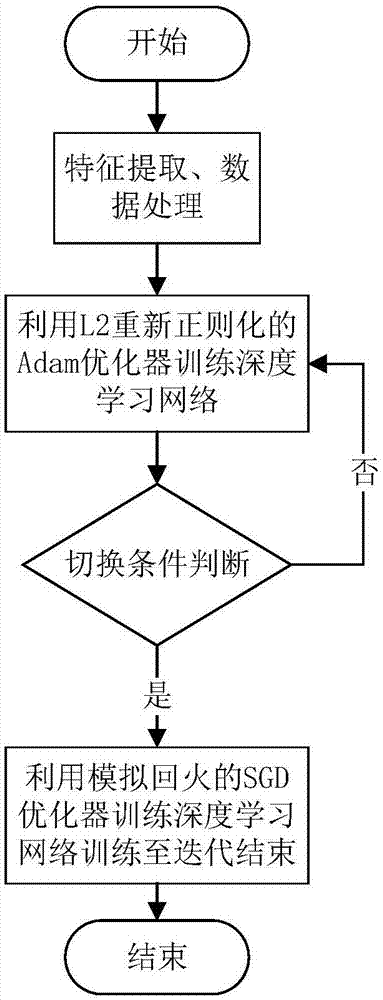
图1为本发明的基于l2重新正则化adam切换模拟回火sgd的深度学习方法流程图;
图2为本发明中l2重新正则化的adam与经典adam在不同标准数据集下的平均训练效果,其中,(a)为cifar-10数据集,(b)为fashion-mnist数据集;
图3为本发明中模拟回火sgd与经典sgd在不同标准数据集下的平均训练效果,其中,(a)为cifar-10数据集,(b)为fashion-mnist数据集;
图4为本发明提出的新算法算法与经典两种优化器在不同标准数据集下的平均训练效果,其中,(a)为cifar-10数据集,(b)为fashion-mnist数据集;
图5为本发明提出的新算法与经典两种优化器在imagenet标准数据集下的平均训练效果,其中,(a)为完整的训练集学习曲线,(b)为1-100次迭代学习曲线放大图,(c)为100-199次迭代学习曲线放大图,(d)为200-299次迭代学习曲线放大图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明提供一种基于l2重新正则化adam切换模拟回火sgd的深度学习方法。
如图1所示,该方法步骤为:
(1)将标准数据库中的数据进行特征提取以及数据增强,将信号输入到l2重新正则化的adam为初始优化器的深度学习网络;每次迭代中依据得到的梯度,计算得到假设在该次迭代下切换模拟回火sgd优化器的学习率,以及该次迭代完成后深度学习网络权重ωt矩阵at=(ωt)tωt的迹tr(at)与其特征值的平方和qs(at);
(2)在步骤(1)中经过一定的判断条件,得到下一次迭代是否进行切换,若是,则切换至模拟回火sgd优化器,并使用该优化器至迭代结束;若否,则不改变优化器类型,继续步骤(1)及步骤(2)中迭代与判断的过程。
其中,步骤(1)中l2重新正则化的adam方法如下:
权重更新方法为
步骤(1)中模拟回火sgd的学习率更新方法如下:
学习率更新方法为
步骤(1)中切换模拟回火sgd优化器的学习率如下:
求得的模拟回火sgd优化器的学习率为
步骤(2)中下一次迭代是否进行切换的判断条件如下:
其中
针对l2重新正则化adam与模拟回火sgd优化算法,本发明在cifar-10以及由xiao等人改进的fashion-mnist两个标准集上分别进行了基于不同深度学习网络结构的多次训练,讨论其在标准数据集上的实验效果。
首先在resnet的多层网络架构上以两种标准数据集进行多次含l2重新正则化与传统adam优化器的对比实验,结果如图2与表1所示。可以看出,l2重新正则化的adam相比未正则化的优化器在训练效果上总体略有提高,可以在本发明整体的算法中应用进行局部优化。
表1在不同的resnet网络结构下,传统adam在两种标准数据集中的训练情况汇总对比
表2在不同的resnet网络结构下,l2重新正则化adam在两种不同数据集中的训练情况汇总对比
然后在同样的resnet的多层网络架构上以两种标准库进行多次模拟回火(其中tmul=2,mmul=1.5)优化的sgd与传统sgd优化器的对比实验,结果如图3与表3、表4所示。可以看出,在一定的迭代次数之前(250次迭代左右),加入sa的sgd在收敛效果和收敛速度上均有比较明显的加强,这在需要效率或者设备配置不高的场合是很有意义。
表3在不同的resnet网络结构下,传统sgd在两种不同数据集中的训练情况汇总对比
表4在不同的resnet网络结构下,模拟回火sgd在两种不同数据集中的训练情况汇总对比
最后使用完整的本发明算法分析大型数据集imagenet,imagenet中含有超过1500万张也就是带标签的图片,标签说明了图片中的内容,包含超过2.2万个不同类别。在resnet的多层网络架构上以两种标准数据集以及imagenet为输入进行多次以l2a-sas优化器与传统优化器的深度学习训练对比实验,结果如图4、图5与表5、表6所示,可以看见本发明算法成功结合了adam前期收敛速度快和sgd后期收敛效果好的特点,在100次迭代次数内新算法的收敛速度高于sgd,在后期新算法的收敛效果则超过了adam,尤其在迭代次数小于250次时新算法的效率明显更高,且去除正常学习率衰减因素外的误差震荡相对较小。在需要减少迭代次数的前提下,新算法可以尽快的达到需要的效果。
表5在不同的resnet网络结构下,l2a-sas优化器在两个标准数据集下的训练汇总对比(迭代次数300次)
表6在不同的resnet网络结构下,l2a-sas对比传统优化器在imagenet数据集合下的训练汇总对比(迭代次数300次)
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!