一种基于多层检测的网络攻击类型识别方法与流程
本发明涉及一种基于多层检测的网络攻击类型识别方法,属于信息安全
技术领域:
。
背景技术:
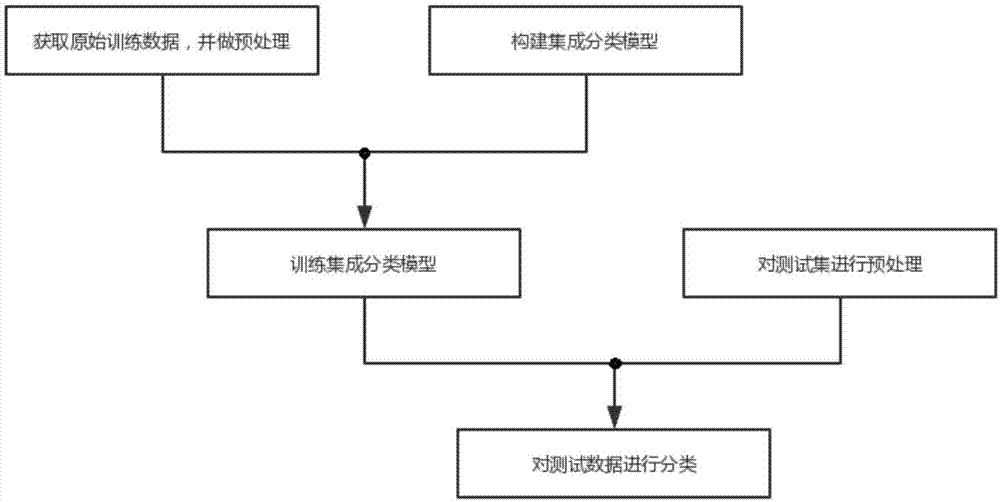
:在网络空间中,近年来的网络攻击数量和规模上都急剧增加,基本的主要网络攻击类型包括拒绝服务(denialofservice,dos)、未授权的远程主机访问(remote-to-login,r2l)、未经授权获取超级用户访问(user-to-root,u2r)、监听探测(probing)等,上述每一类攻击又包括多个子攻击类型。有效的检测这些网络攻击,部署高效的入侵检测系统已成为刻不容缓的当务之急。目前比较常用的网络攻击检测方法有:①基于规则的检测方法,缺点是难以检测新的入侵,而且编辑这些规则非常耗时,高度依赖已知的入侵知识库。②依赖于网络流特征分布的熵值检测方法,缺点是熵表示随机性,不会扰乱随机性的异常流不会被检测到。③基于机器学习的检测方法,如神经网络,支持向量机,聚类算法等。基于机器学习的检测方法可以检测新的入侵,普遍应用于当前的入侵检测中,但是数据的不平衡性和算法模型的参数对检测结果的影响很大。技术实现要素:本发明的目的是解决网络攻击检测数据集不平衡,网络攻击分类算法精确率和召回率低的问题,提出一种基于多层检测的网络攻击类型识别方法。本发明是通过以下技术方案实现的。本发明提出的一种基于多层检测的网络攻击类型识别方法,其具体操作步骤如下:步骤一、获取原始训练数据,并做预处理。步骤1.1:获取网络攻击数据,组成原始训练数据集。所述网络攻击数据包括数值型特征和字符离散型特征。所述字符离散型特征包括:协议类型、服务类型和连接错误标识。步骤1.2:将原始训练数据集中的每条原始训练数据转换成一个数值型的原始训练数据特征向量。具体为:步骤1.2.1:从每条数据中抽取出字符离散型特征,分别以one-hot向量形式进行编码,一个字符离散型特征对应得到一个one-hot向量。步骤1.2.2:利用每条数据中的数值型特征的值,构建一个数值型的特征向量;步骤1.2.3:将步骤1.2.2中所述数值型的特征向量与步骤1.2.1得到的全部one-hot向量进行合并。经过上述步骤的操作,对应一条原始训练数据,得到一个数值型的原始训练数据特征向量。步骤1.3:通过数据降采样和数据升采样,解决原始训练数据集的各类型数据的数量不平衡问题。具体为:情况1:如果原始训练数据集中某种类型(用符号a表示)的数据数量远多于其它类型的数据数量,则采用数据降采样方法减少a类型的数量,具体为:从a类型的数据中随机抽取出一部分数据,以减少a类型数据。情况2:如果原始训练数据集中某种类型(用符号b表示)的数量远低于其它类型数据的数量,则采用数据升采样方法,增加b类型数据的数量。所述数据升采样的算法为smote(syntheticminorityoversamplingtechnique,合成少数过采样技术)算法。经过one-hot编码、数据降采样、数据升采样处理之后的原始训练数据集称为基础训练数据集,用符号x表示;用符号xij表示基础训练数据集x的第i条数据的第j个特征,i∈[1,n],n为基础训练数据集x中的数据数量;步骤1.4:通过公式(1)对基础训练数据集x中的数据进行标准化处理。其中,xi′j为数据xij经过标准化处理之后得到的数据;avgj为基础训练数据集x中所有数据的第j个特征的平均值,通过公式(2)计算得到;stdj为基础训练数据集x中所有数据的第j个特征的标准差,通过公式(3)计算得到。经过步骤一的操作,对基础训练数据集进行预处理后,得到训练数据集,用符号x′表示。步骤二、构建集成分类模型。所述集成分类模型包括gbdt(gradientboostdecisiontree,梯度提升树)分类器、knn分类器和stacking分类器。所述gbdt分类器是通过迭代构建分类回归树(classificationandregressiontree,cart)进行增强(boosting)的思想来学习的。用符号ft-1(x)表示第(t-1)轮迭代得到的gbdt分类器,t为正整数;用符号ft(x)表示第t轮迭代得到的gbdt分类器;用符号l(y,ft-1(x))表示第(t-1)轮迭代得到的gbdt分类器的损失函数;用符号l(y,ft(x))表示第t轮迭代得到的gbdt分类器的损失函数;用符号ht(x)表示在第t轮学习得到的拟合函数。在gbdt分类器的学习过程中,第(t-1)轮迭代就是寻找使得公式(4)中l(y,ft(x))取值最小的ht(x)。寻找最小的ht(x)的过程采用的是损失函数负梯度拟合的方法。l(y,ft(x))=l(y,ft-1(x)+ht(x))(4)所述knn分类器用于对dos(denialofservice,拒绝服务)类型数据进行分类,预测出dos类型数据的子类型。设置knn分类器的参数k=3。所述stacking分类器用于对非dos类型数据进行分类。stacking分类器分为初级分类模型和次级分类模型两层。所述初级模型分为上、下两层,初级模型的上层由3个xgboost(extremegradientboosting,极端梯度提升)分类模块组、1个svm(supportvectormachines,支持向量机)分类模块组、1个gbdt(gradientboostingdecisontree,梯度提升树)分类模块组和1个rf(randomforest,随机森林)分类模块组并联而成。其中每个xgboost分类模块组由m个xgboost分类模块并联而成,每个svm分类模块组由m个svm分类模块并联而成,每个gbdt分类模块组由m个gbdt分类模块并联而成,每个rf分类模块组由m个rf分类模块并联而成;m为人为设定值,m∈[3,8]。初级模块的下层为拼接与投票模块。所述初级模型上层的3个xgboost分类模块组、1个svm分类模块组、1个gbdt分类模块组和1个rf分类模块组的输出端分别与初级模型下层的拼接与投票模块的输入端连接。在训练阶段,所述拼接与投票模块的作用是:将初级模型上层的每个xgboost分类模块组、svm分类模块组、gbdt分类模块组和rf分类模块组的输出结果进行合并,得到一个向量矩阵,称为stacking向量矩阵。在测试阶段,所述拼接与投票模块的作用是:对应一条测试数据,将初级模型上层的每个xgboost分类模块组、svm分类模块组、gbdt分类模块组和rf分类模块组的输出结果分别进行投票,每个分类模块组得到一个分类结果,然后对分类结果进行合并,得到一个1×6的stacking特征向量。所述次级模型为svm分类器,其输入为初级模型生成的stacking特征向量。所述svm分类器中采用果蝇优化算法foa,对svm核函数参数(用符号γ表示)和惩罚参数(用符号c表示)表示进行最优化选择,具体操作步骤为:步骤2.1:初始化svm核函数参数γ和惩罚参数c,γ∈[0.001,5],c∈[0.001,5]。设置果蝇的起始位置为(cbegin,γbegin),其中cbegin=c,γbegin=γ。步骤2.2:设定种群大小(用符号popsize表示)、迭代次数(用符号epoch表示)、惩罚参数c的搜索距离(用符号valc表示)和核函数参数γ的搜索距离(用符号valγ表示)。popsize∈[8,15],epoch≥5,valc∈[0.05,0.5],valγ∈[0.001,0.01]。步骤2.3:按公式(6)至公式(7)计算下一时刻第p只果蝇的位置,用符号(cp,γp)表示,p∈[1,popsize]。cp=cbegin+valc×ε(6)γp=γbegin+valγ×ε(7)其中,ε为[-1,1]范围内的随机值。步骤2.4:如果此时惩罚参数c<0.001,则c=0.001;如果c>5,则c=5。如果γ<0.001,则γ=0.001;γ>5,则γ=5。步骤2.5:按公式(8)计算步骤2.3得到的所有果蝇所在位置的适应度函数值。fit(cp,γp)=accuracy(cp,γp)(8)其中,fit(cp,γp)表示第p只果蝇所在位置的适应度函数值;accuracy(cp,γp)表示svm分类器在参数(cq,γq)上交叉验证产生的准确率,cq=cp,γq=γp。步骤2.6找到当前时刻所有果蝇所在位置对应的适应度函数值中的最大值(用符号fitmax表示),以及fitmax对应的位置,判断此时的fitmax是否比起始位置的适应度函数值高,如果高,则用fitmax对应的位置代替初始位置,同时保存fitmax,然后进行下一次迭代。如果此时的fitmax比起始位置的适应度函数值低,则重复执行步骤2.3至步骤2.6,直到迭代次数达到epoch次,结束操作。所述集成分类模型的连接关系为:外部数据通过gbdt分类器的输入端进入所述集成分类模型;gbdt分类器的输出端分别与knn分类器和stacking分类器的输入端连接;knn分类器和stacking分类器的输出作为集成分类模型的外部输出。步骤三、训练集成分类模型。在步骤一和步骤二操作的基础上,训练集成分类模型。具体为:步骤3.1:训练gbdt分类器。具体为:步骤3.1.1:对训练数据集x′中的数据做类别标记。将训练数据集x′中的数据标记为dos类型和其它类型2种。步骤3.1.2:使用标记好的训练数据集x′训练gbdt分类器。经过步骤3.1的操作,得到训练好的gbdt分类器。步骤3.2:训练knn分类器。具体为:步骤3.2.1:对训练数据集x′中标记为dos类型的数据构建dos类型数据集,用符号x′1表示。步骤3.2.2:对dos类型数据集x′1中的数据进行细分类标记。所述dos类型数据集,用符号x′1中的数据细分为:smurf攻击、neptune攻击、back攻击、teardrop攻击、pod攻击和other攻击。步骤3.2.3:对dos类型数据集x′1按照细分类型进行数据降采样处理,解决dos类型数据集x′1中各细分类型数据的数量不平衡问题;经过数据降采样处理后的数据集,称为knn训练数据集,用符号x1表示。步骤3.2.4:使用knn训练数据集x1训练knn分类器。经过步骤3.2的操作,得到训练好的knn分类器。步骤3.3:训练stacking分类器。具体为:步骤3.3.1:使用训练数据集x′中标记为其它类型的数据构建stacking训练数据集,用符号x2表示,然后对stacking训练数据集中的数据进行细分类标记,所述stacking训练数据集x2中细分为:normal(正常)、probe(探测和扫描)、u2l(user-to-root,未经授权获取超级用户访问)、r2l(remote-to-login,未授权的远程主机访问)。步骤3.3.2:将stacking训练数据集x2的数据均匀分为m个子集,分别称为第1子集、第2子集、……、第m子集。每个子集的数据数量用符号m表示,m为正整数。步骤3.3.3:训练rf分类模块组。具体为:步骤3.3.3.1:用符号h表示临时变量,h∈[1,m]。设置h的初始值为1。步骤3.3.3.2:将stacking训练数据集x2的第h子集作为验证数据。然后,使用stacking训练数据集x2的其它数据作为训练数据,对rf分类模块组里的一个没有训练过的rf分类模块进行训练。步骤3.3.3.3:将第h子集的数据输入到步骤3.3.3.2训练好的rf分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.3.4:如果h<m,使h的值自增1,重复步骤3.3.3.2至步骤3.3.3.4。否则,执行步骤3.3.3.5的操作。步骤3.3.3.5:将步骤3.3.3.2得到的第1子集到第m子集的分类结果进行合并,得到一个stacking训练数据集的数据在rf分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.3.1至步骤3.3.3.5的操作,完成对rf分类模块组的训练,并得到一个stacking训练数据集x2的数据在rf分类模块组的分类结果。步骤3.3.4:训练svm分类模块组。具体为:步骤3.3.4.1:用符号h表示临时变量,h∈[1,m]。设置h的初始值为1。步骤3.3.4.2:将stacking训练数据集x2的第h子集作为验证数据。然后,使用stacking训练数据集x2的其它数据作为训练数据,对svm分类模块组里的一个没有训练过的svm分类模块进行训练。步骤3.3.4.3:将第h子集的数据输入到步骤3.3.4.2训练好的svm分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.4.4:如果h<m,使h的值自增1,重复步骤3.3.4.2至步骤3.3.4.4。否则,执行步骤3.3.4.5的操作。步骤3.3.4.5:将步骤3.3.4.2得到的第1子集到第m子集的分类结果进行合并,得到stacking训练数据集x2的数据在svm分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.4.1至步骤3.3.4.5的操作,完成对svm分类模块组的训练,并得到一个stacking训练数据集的数据在svm分类模块组的分类结果。步骤3.3.5:训练gbdt分类模块组。具体为:步骤3.3.5.1:用符号h表示临时变量,h∈[1,m]。设置h的初始值为1。步骤3.3.5.2:将stacking训练数据集x2的第h子集作为验证数据。然后,使用stacking训练数据集x2的其它数据作为训练数据,对gbdt分类模块组里的一个没有训练过的gbdt分类模块进行训练。步骤3.3.5.3:将第h子集的数据输入到步骤3.3.5.2训练好的gbdt分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.5.4:如果h<m,使h的值自增1,重复步骤3.3.5.2至步骤3.3.5.4。否则,执行步骤3.3.5.5的操作。步骤3.3.5.5:将步骤3.3.5.2得到的第1子集到第m子集的分类结果进行合并,得到stacking训练数据集x2的数据在gbdt分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.5.1至步骤3.3.5.5的操作,完成对gbdt分类模块组的训练,并得到stacking训练数据集的数据在gbdt分类模块组的分类结果。步骤3.3.6:训练一个xgboost分类模块组。具体为:步骤3.3.6.1:用符号h表示临时变量,h∈[1,m]。设置h的初始值为1。步骤3.3.6.2:将stacking训练数据集x2的第h子集作为验证数据。然后,使用stacking训练数据集x2的其它数据作为训练数据,对xgboost分类模块组里的一个没有训练过的xgboost分类模块进行训练。步骤3.3.6.3:将第h子集的数据输入到步骤3.3.6.2训练好的xgboost分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.6.4:如果h<m,使h的值自增1,重复步骤3.3.6.2至步骤3.3.6.4。否则,执行步骤3.3.6.5的操作。步骤3.3.6.5:将步骤3.3.6.2得到的第1子集到第m子集的分类结果进行合并,得到stacking训练数据集的数据在xgboost分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.6.1至步骤3.3.6.5的操作,完成对xgboost分类模块组的训练,并得到stacking训练数据集x2的数据在xgboost分类模块组的分类结果。步骤3.3.7:将步骤3.3.6重复执行2次,完成对另外2个xgboost分类模块组的训练,并得到stacking训练数据集x2的数据在另外2个xgboost分类模块组的分类结果,并发送到拼接与投票模块。步骤3.3.8:拼接与投票模块将步骤3.3.3至步骤3.3.7得到的stacking训练数据集x2在各分类模块组的分类结果进行合并,得到一个p×6的向量矩阵,即stacking向量矩阵;其中,p表示stacking训练数据集x2的数据数量。步骤3.3.9:将步骤3.3.8得到的stacking向量矩阵输入到stacking分类器的次级模型svm分类器中,经过训练操作,得到训练好的stacking分类器。经过上述步骤的操作,完成stacking分类器的训练,得到训练好的集成分类模型。步骤四、对测试数据进行预处理。具体为:步骤4.1:获取网络攻击数据,组成原始测试数据集。所述网络攻击数据包括数值型特征和字符离散型特征。所述字符离散型特征为:协议类型、服务类型和连接错误标识。步骤4.2:将原始测试数据集中的每条原始测试数据转换成一个数值型的原始测试数据特征向量。具体为:步骤4.2.1:从每条数据中抽取出字符离散型特征,分别以one-hot向量形式进行编码,一个字符离散型特征对应得到一个one-hot向量。步骤4.2.2:利用每条数据中的数值型特征的值,构建一个数值型的特征向量;步骤4.2.3:将步骤4.2.2中所述数值型的特征向量与步骤4.2.1中所述得到one-hot向量进行合并。经过上述步骤的操作,对应一条原始测试数据,得到一个数值型的原始测试数据特征向量。将经过one-hot编码的原始测试数据集称为基础测试数据集,用符号xtest表示;用符号xtest,ij表示基础测试数据集xtest的第i条数据的第j个特征。步骤4.3:通过公式(5)对基础测试数据集xtest中的数据进行标准化处理。其中,x′test,ij为数据xtest,ij经过标准化处理之后得到的数据;avgj为步骤1.4得到的基础训练数据集x中所有数据的第j个特征的平均值;stdj为步骤1.4得到的基础训练数据集x中所有数据的第j个特征的标准差。经过步骤4的操作,对基础测试数据集进行预处理后,得到测试数据集,用符号x′test表示。步骤五、对测试数据进行分类。将经过步骤四预处理得到的测试数据,输入到步骤三训练好的集成分类模型中进行分类。具体步骤为:步骤5.1:将一条将经过步骤四预处理得到的测试数据,输入到gbdt分类器,如果分类结果为dos类型,则执行步骤5.2的操作;如果分类结果为非dos类型,则执行步骤5.3的操作。步骤5.2:将所述测试数据输入到knn分类器进行分类,得到最终分类结果并输出,结束操作。步骤5.3:将所述测试数据分别输入到rf分类模块组里的每个rf分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将rf分类模块组的输出结果进行投票,确定分类结果。步骤5.4:将所述测试数据分别输入到gbdt分类模块组里的每个gbdt分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将gbdt分类模块组的输出结果进行投票,确定分类结果。步骤5.5:将所述测试数据分别输入到svm分类模块组里的每个svm分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将svm分类模块组的输出结果进行投票,确定分类结果。步骤5.6:将所述测试数据分别输入到一个xgboost分类模块组里的每个xgboost分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将xgboost分类模块组的输出结果进行投票,确定分类结果。步骤5.7:重复2次步骤5.6的操作,得到另外2个xgboost分类模块组的分类结果。步骤5.8:将步骤5.3至5.7的结果进行合并,得到一个1×6的stacking向量。步骤5.9:将步骤5.8得到的1×6的stacking向量输入到stacking分类器的次级模型svm分类器中,经过分类操作,得到一条测试数据的分类结果并输出,结束操作。有益效果本专利提出的一种基于多层检测的网络攻击类型识别方法与已有技术相比较,有如下有点:①采用smote算法对少数样本升采样,对多数样本降采样,解决数据集样本不平衡问题。②采用集成分类模型,提高了检测的精确率与召回率。③将果蝇优化算法(foa)与支持向量机(svm)结合,实现svm中参数c和gamma的最优和自适应选择。附图说明图1为本发明具体实施方式中基于多层检测的网络攻击类型识别方法的操作流程图。图2为本发明具体实施方式中集成分类模型的结构图。具体实施方式根据上述技术方案,下面结合附图和实施实例对本发明进行详细说明。使用本发明提出的一种基于多层检测的网络攻击类型识别方法,其操作流程如图1所示,具体操作步骤如下。步骤一、获取原始训练数据,并做预处理。步骤1.1:获取网络攻击数据,组成原始训练数据集。本实验采用kdd99数据集,原始训练数据集中的数据分布如表1所示,包括normal(正常)、dos(拒绝服务)、probe(探测和扫描)、u2l(非法获取超级用户权限)、r2l(未授权的远程主机访问),五种类型数据。其中dos类数据的子类型的分布如表2所示。每条正常数据或攻击数据有41项特征组成,如表3所示,其中的三个离散特征“protocol_type”,“service”,“flag”的值为字符标签,其余特征的值均为数值。表1kdd99原始训练数据集的数据分布类别normaldosprobeu2lr2l原始训练集972783914854107521126表2kdd99原始训练数据集dos攻击子类型数据分布类别backneptunepodsmurfteardropother原始训练集220310720126428079097921表3kdd99数据集的41项特征组成步骤1.2:将原始训练数据集中的每条原始训练数据转换成一个数值型的原始训练数据特征向量。具体为:步骤1.2.1:从每条数据中抽取出“protocol_type”,“service”,“flag”三个字符离散型特征,分别以one-hot向量形式进行编码,一个字符离散型特征对应得到一个one-hot向量。步骤1.2.2:利用每条数据中的数值型特征的值,构建一个数值型的特征向量;步骤1.2.3:将步骤1.2.2中所述数值型的特征向量与步骤1.2.1得到的全部one-hot向量进行合并。经过上述步骤的操作,对应一条原始训练数据,得到一个数值型的原始训练数据特征向量。步骤1.3:通过数据降采样和数据升采样,解决原始训练数据集的各类型数据的数量不平衡问题。具体为:normal数据类型的样本数量和dos类型远多于其他类型数量。从normal类型数据中随机抽取10000条数据,减少normal类型数据的数量。dos类型数据由多个子类型组成,smurf攻击和neptune攻击数据的样本远多于其他子类型的数量,对这两个子类型数据降采样,随机抽取smurf样本14000条,随机抽取neptune样本8533条。原始训练数据中probe、u2l、r2l类型数据量较dos和normal数据量少,对这三类数据采用smote算法进行升采样。本发明中,我们对probe样本扩大2倍采样,对应smote算法中的近邻数设置为3;对r2l样本扩大4倍采样,对应smote算法中的近邻数设置为3;u2l样本扩大40倍采样,对应smote算法中的近邻数设置为10。升采样之后probe样本有8214个,r2l样本有4504个,u2l样本有2080个。经过one-hot编码、数据降采样、数据升采样处理之后的原始训练数据集称为基础训练数据集,用符号x表示;用符号xij表示基础训练数据集x的第i条数据的第j个特征,i∈[1,n],n=54798。得到的基础训练数据集的数据分布和其中dos子类型的数据分布如表4和表5所示。表4基础训练数据集x的数据分布类别normaldosprobeu2lr2l基础训练集1000030000821420804504表5基础训练数据集x中dos攻击子类型数据分布类别backneptunepodsmurfteardropother基础训练集220385332641400097921步骤1.4:通过公式(1)对基础训练数据集x中的数据进行标准化处理。其中,xi′j为数据xij经过标准化处理之后得到的数据;avgj为基础训练数据集x中所有数据的第j个特征的平均值,通过公式(2)计算得到;stdj为基础训练数据集x中所有数据的第j个特征的标准差,通过公式(3)计算得到。经过步骤一的操作,对基础训练数据集进行预处理后,得到训练数据集,用符号x′表示。步骤二、构建集成分类模型。所述集成分类模型包括gbdt(gradientboostdecisiontree,梯度提升树)分类器、knn分类器和stacking分类器。所述gbdt分类器是通过迭代构建分类回归树(classificationandregressiontree,cart)进行增强(boosting)的思想来学习的。用符号ft-1(x)表示第(t-1)轮迭代得到的gbdt分类器,t为正整数;用符号ft(x)表示第t轮迭代得到的gbdt分类器;用符号l(y,ft-1(x))表示第(t-1)轮迭代得到的gbdt分类器的损失函数;用符号l(y,ft(x))表示第t轮迭代得到的gbdt分类器的损失函数;用符号ht(x)表示在第t轮学习得到的拟合函数。在gbdt分类器的学习过程中,第(t-1)轮迭代就是寻找使得公式(4)中l(y,ft(x))取值最小的ht(x)。寻找最小的ht(x)的过程采用的是损失函数负梯度拟合的方法。l(y,ft(x))=l(y,ft-1(x)+ht(x))(4)所述knn分类器用于对dos(denialofservice,拒绝服务)类型数据进行分类,预测出dos类型数据的子类型。设置knn分类器的参数k=3。所述stacking分类器用于对非dos类型数据进行分类。stacking分类器分为初级分类模型和次级分类模型两层。所述初级模型分为上、下两层,初级模型的上层由3个xgboost分类模块组、1个svm分类模块组、1个gbdt分类模块组和1个rf分类模块组并联而成。其中每个xgboost分类模块组由m个xgboost分类模块并联而成,每个svm分类模块组由m个svm分类模块并联而成,每个gbdt分类模块组由m个gbdt分类模块并联而成,每个rf分类模块组由m个rf分类模块并联而成。本专利中,设置m=5。初级模块的下层为拼接与投票模块。所述初级模型上层的3个xgboost分类模块组、1个svm分类模块组、1个gbdt分类模块组和1个rf分类模块组的输出端分别与初级模型下层的拼接与投票模块的输入端连接。在训练阶段,所述拼接与投票模块的作用是:将初级模型上层的每个xgboost分类模块组、svm分类模块组、gbdt分类模块组和rf分类模块组的输出结果进行合并,得到一个向量矩阵,称为stacking向量矩阵。集成分类模型的结构如图2所示。在测试阶段,所述拼接与投票模块的作用是:对应一条测试数据,将初级模型上层的每个xgboost分类模块组、svm分类模块组、gbdt分类模块组和rf分类模块组的输出结果分别进行投票,每个分类模块组得到一个分类结果,然后对分类结果进行合并,得到一个1×6的stacking特征向量。所述次级模型为svm分类器,其输入为初级模型生成的stacking特征向量。所述svm分类器中采用foa(flyoptimizationalgorithm,果蝇优化算法)优化算法,对svm核函数参数(用符号γ表示)和惩罚参数(用符号c表示)进行最优化选择,具体操作步骤为:步骤2.1:初始化svm核函数参数γ和惩罚参数c,γ∈[0.001,5],c∈[0.001,5]。实施例中,设置γ=0.01,c=0.5,即果蝇的起始位置为(cbegin,γbegin),其中cbegin=c,γbegin=γ。步骤2.2:设定种群大小(用符号popsize表示)、迭代次数(用符号epoch表示)、惩罚参数c的搜索距离(用符号valc表示)和核函数参数γ的搜索距离(用符号valγ表示)。popsize=10,epoch=5,valc=0.1,valγ=0.001。步骤2.3:按公式(6)至公式(7)计算下一时刻第p只果蝇的位置,用符号(cp,γp)表示,p∈[1,popsize]。cp=cbegin+valc×ε(6)γp=γbegin+valγ×ε(7)其中,ε为[-1,1]范围内的随机值。步骤2.4:如果此时惩罚参数c<0.001,则c=0.001;如果c>5,则c=5。如果γ<0.001,则γ=0.001;γ>5,则γ=5。步骤2.5:按公式(8)计算步骤2.3得到的所有果蝇所在位置的适应度函数值。fit(cp,γp)=accuracy(cp,γp)(8)其中,fit(cp,γp)表示第p只果蝇所在位置的适应度函数值;accuracy(cp,γp)表示svm分类器在参数(cq,γq)上交叉验证产生的准确率,cq=cp,γq=γp。步骤2.6找到当前时刻所有果蝇所在位置对应的适应度函数值中的最大值(用符号fitmax表示),以及fitmax对应的位置,判断此时的fitmax是否比起始位置的适应度函数值高,如果高,则用fitmax对应的位置代替初始位置,同时保存fitmax,然后进行下一次迭代。如果此时的fitmax比起始位置的适应度函数值低,则重复执行步骤2.3至步骤2.6,直到迭代次数达到epoch次,结束操作。所述集成分类模型的连接关系为:外部数据通过gbdt分类器的输入端进入所述集成分类模型;gbdt分类器的输出端分别与knn分类器和stacking分类器的输入端连接;knn分类器和stacking分类器的输出作为集成分类模型的外部输出。步骤三、训练集成分类模型。在步骤一和步骤二操作的基础上,训练集成分类模型。具体为:步骤3.1:训练gbdt分类器。具体为:步骤3.1.1:对训练数据集x′中的数据做类别标记。将训练数据集x′中的数据标记为dos(denialofservice,拒绝服务)类型和其它类型2种。其数据分布如表6所示。表6gbdt分类器训练集的数据分布数据类型dos非dos(u2l,r2l,normal,probe)数量3000024798步骤3.1.2:使用标记好的训练数据集x′训练gbdt分类器。经过步骤3.1的操作,得到训练好的gbdt分类器。步骤3.2:训练knn分类器。具体为:步骤3.2.1:对训练数据集x′中标记为dos类型的数据构建dos类型数据集,用符号x′1表示。步骤3.2.2:对dos类型数据集x′1中的数据进行细分类标记。所述dos类型数据集,用符号x′1中的数据细分为:smurf攻击、neptune攻击、back攻击、teardrop攻击,pod攻击和other。步骤3.2.3:对dos类型数据集x1′按照细分类型进行数据降采样处理;smurf,neptune类型数据数量远多于其他类型数据,随机抽取smurf数据5000条,neptune数据4000条。经过数据降采样处理后的数据集,称为knn训练数据集,用符号x1表示。其数据分布如表7所示。表7knn分类器的训练数据分布dos子类型backneptunepodsmurfteardropother数量22034000264500097921步骤3.2.4:使用knn训练数据集x1训练knn分类器。经过步骤3.2的操作,得到训练好的knn分类器。步骤3.3:训练stacking分类器。具体为:步骤3.3.1:使用训练数据集x′中标记为其它类型的数据构建stacking训练数据集,用符号x2表示,然后对stacking训练数据集中的数据进行细分类标记,所述stacking训练数据集x2中细分为:normal、probe、u2l、r2l。其数据分布如表8所示。表8stacking模型的训练数据分布数据类型normalprobeu2lr2l数量10000821420804504步骤3.3.2:将stacking训练数据集x2的数据均匀分为5个子集,分别称为第1子集、第2子集、……、第5子集。每个子集的数据数量用符号m表示,m为正整数。步骤3.3.3:训练rf分类模块组。具体为:步骤3.3.3.1:用符号t表示临时变量,t∈[1,5]。设置t的初始值为1。步骤3.3.3.2:将stacking训练数据集x2的第t子集作为验证数据,t∈[1,5]。然后,使用stacking训练数据集x2的其它数据作为训练数据,对rf分类模块组里的一个没有训练过的rf分类模块进行训练。步骤3.3.3.3:将第t子集的数据输入到步骤3.3.3.2训练好的rf分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.3.4:如果t<5,使t的值自增1,重复步骤3.3.3.2至步骤3.3.3.4。否则,执行步骤3.3.3.5的操作。步骤3.3.3.5:将步骤3.3.3.2得到的第1子集到第5子集的分类结果进行合并,得到一个stacking训练数据集的数据在rf分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.3.1至步骤3.3.3.5的操作,完成对rf分类模块组的训练,并得到一个stacking训练数据集x2的数据在rf分类模块组的分类结果。步骤3.3.4:训练svm分类模块组。具体为:步骤3.3.4.1:用符号t表示临时变量,t∈[1,5]。设置t的初始值为1。步骤3.3.4.2:将stacking训练数据集x2的第t子集作为验证数据,t∈[1,5]。然后,使用stacking训练数据集x2的其它数据作为训练数据,对svm分类模块组里的一个没有训练过的svm分类模块进行训练。步骤3.3.4.3:将第t子集的数据输入到步骤3.3.4.2训练好的svm分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.4.4:如果t<5,使t的值自增1,重复步骤3.3.4.2至步骤3.3.4.4。否则,执行步骤3.3.4.5的操作。步骤3.3.4.5:将步骤3.3.4.2得到的第1子集到第5子集的分类结果进行合并,得到stacking训练数据集x2的数据在svm分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.4.1至步骤3.3.4.5的操作,完成对svm分类模块组的训练,并得到一个stacking训练数据集的数据在svm分类模块组的分类结果。步骤3.3.5:训练gbdt分类模块组。具体为:步骤3.3.5.1:用符号t表示临时变量,t∈[1,5]。设置t的初始值为1。步骤3.3.5.2:将stacking训练数据集x2的第t子集作为验证数据,t∈[1,5]。然后,使用stacking训练数据集x2的其它数据作为训练数据,对gbdt分类模块组里的一个没有训练过的gbdt分类模块进行训练。步骤3.3.5.3:将第t子集的数据输入到步骤3.3.5.2训练好的gbdt分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.5.4:如果t<5,使t的值自增1,重复步骤3.3.5.2至步骤3.3.5.4。否则,执行步骤3.3.5.5的操作。步骤3.3.5.5:将步骤3.3.5.2得到的第1子集到第5子集的分类结果进行合并,得到stacking训练数据集x2的数据在gbdt分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.5.1至步骤3.3.5.5的操作,完成对gbdt分类模块组的训练,并得到stacking训练数据集的数据在gbdt分类模块组的分类结果。步骤3.3.6:训练一个xgboost分类模块组。具体为:步骤3.3.6.1:用符号t表示临时变量,t∈[1,5]。设置t的初始值为1。步骤3.3.6.2:将stacking训练数据集x2的第t子集作为验证数据,t∈[1,5]。然后,使用stacking训练数据集x2的其它数据作为训练数据,对xgboost分类模块组里的一个没有训练过的xgboost分类模块进行训练。步骤3.3.6.3:将第t子集的数据输入到步骤3.3.6.2训练好的xgboost分类模块中进行分类,得到一个m×1的向量矩阵。步骤3.3.6.4:如果t<5,使t的值自增1,重复步骤3.3.6.2至步骤3.3.6.4。否则,执行步骤3.3.6.5的操作。步骤3.3.6.5:将步骤3.3.6.2得到的第1子集到第5子集的分类结果进行合并,得到stacking训练数据集的数据在xgboost分类模块组的分类结果,并发送到拼接与投票模块。经过步骤3.3.6.1至步骤3.3.6.5的操作,完成对xgboost分类模块组的训练,并得到stacking训练数据集x2的数据在xgboost分类模块组的分类结果。步骤3.3.7:将步骤3.3.6重复执行2次,完成对另外2个xgboost分类模块组的训练,并得到stacking训练数据集x2的数据在另外2个xgboost分类模块组的分类结果,并发送到拼接与投票模块。步骤3.3.8:拼接与投票模块将步骤3.3.3至步骤3.3.7得到的stacking训练数据集x2在各分类模块组的分类结果进行合并,得到一个p×6的向量矩阵,即stacking向量矩阵;其中,p表示stacking训练数据集x2的数据数量。步骤3.3.9:将步骤3.3.8得到的stacking向量矩阵输入到stacking分类器的次级模型svm分类器中,经过训练操作,得到训练好的stacking分类器。经过上述步骤的操作,完成stacking分类器的训练,得到训练好的集成分类模型。步骤四、对测试数据进行预处理。步骤4.1:获取网络攻击数据,组成原始测试数据集。如步骤1.1所述,本实验采用kdd99数据集,每条测试数据有41项特征组成,如表3所示。其中的三个离散特征“protocol_type”,“service”,“flag”的值为字符标签,其余特征的值均为数值。原始测试数据集中的数据分布和dos子类型分布如表9和表10所示。表9原始测试数据集的数据分布类型normaldosprobeu2lr2l数量60593229853416622816189表10原始测试数据集dos攻击子类型数据分布步骤4.2:将原始测试数据集中的每条原始测试数据转换成一个数值型的原始测试数据特征向量。具体为:步骤4.2.1:从每条数据中抽取出字符离散型特征,分别以one-hot向量形式进行编码,一个字符离散型特征对应得到一个one-hot向量。步骤4.2.2:利用每条数据中的数值型特征的值,构建一个数值型的特征向量;步骤4.2.3:将步骤4.2.2中所述数值型的特征向量与步骤4.2.1中所述得到one-hot向量进行合并。经过上述步骤的操作,对应一条原始测试数据,得到一个数值型的原始测试数据特征向量。将经过one-hot编码的原始测试数据集称为基础测试数据集,用符号xtest表示;用符号xtest,ij表示基础测试数据集xtest的第i条数据的第j个特征。步骤4.3:通过公式(5)对基础测试数据集xtest中的数据进行标准化处理。其中,x′test,ij为数据xtest,ij经过标准化处理之后得到的数据;avgj为步骤1.4得到的基础训练数据集x中所有数据的第j个特征的平均值;stdj为步骤1.4得到的基础训练数据集x中所有数据的第j个特征的标准差。经过步骤4的操作,对基础测试数据集进行预处理后,得到测试数据集,用符号x′test表示。步骤五、对测试数据进行分类。将经过步骤四预处理得到的测试数据,输入到步骤三训练好的集成分类模型中进行分类。具体步骤为:步骤5.1:对每条经过步骤四预处理得到的测试数据,输入到gbdt分类器,如果分类结果为dos类型,则执行步骤5.2的操作;如果分类结果为非dos类型,则执行步骤5.3的操作。步骤5.2:将所述测试数据输入到knn分类器进行分类,得到最终分类结果并输出,结束操作。步骤5.3:将所述测试数据分别输入到rf分类模块组里的每个rf分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将rf分类模块组的输出结果进行投票,确定分类结果。步骤5.4:将所述测试数据分别输入到gbdt分类模块组里的每个gbdt分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将gbdt分类模块组的输出结果进行投票,确定分类结果。步骤5.5:将所述测试数据分别输入到svm分类模块组里的每个svm分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将svm分类模块组的输出结果进行投票,确定分类结果。步骤5.6:将所述测试数据分别输入到一个xgboost分类模块组里的每个xgboost分类模块中,经过分类操作,分类结果输出到拼接与投票模块。拼接与投票模块将xgboost分类模块组的输出结果进行投票,确定分类结果。步骤5.7:重复2次步骤5.6的操作,得到另外2个xgboost分类模块组的分类结果。步骤5.8:将步骤5.3至5.7的结果进行合并,得到一个1×6的stacking向量。步骤5.9:将步骤5.8得到的1×6的stacking向量输入到stacking分类器的次级模型svm分类器中,经过分类操作,得到一条测试数据的分类结果并输出。最后,对预测结果评价。将步骤五得到的对测试集的预测结果,在准确率和召回率两个指标上对其进行考量。结果如表11和表12所示。表11测试集中dos,probe,u2l,r2l,normal数据的预测结果类型normaldosprobeu2lr2l精确率75.67%99.89%83.59%7.54%84.63%召回率99.23%97.41%93.11%23.24%10.91%表12dos攻击子类型的数据的预测结果类型smurfneptunebackpodteardrop精确率99.99%99.40%68.49%51.50%29.27%召回率99.98%99.85%100%99.85%100%表11显示了本方法对normal、probe、dos、u2l和r2l这五种数据类型的分类的准确率和召回率。表11展示了本方法对dos攻击子类型数据的分类精确率和召回率。实验结果表明本方法在这种数据极度不平衡,数据分布不一致的数据集上,测试集的精确率和召回率上均取得了不错的效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1