一种提高基于Hadoop大数据综合查询引擎效率的方法及系统与流程
本发明属于搜索引擎技术领域,具体涉及一种提高基于hadoop大数据综合查询引擎效率的方法及系统。
背景技术:
随着互联网的迅猛发展,人们已经越来越依赖网络来获取信息,搜索引擎的出现在人们与海量网络信息之间架起了一道桥梁;然而,随着网络用户的激增和网络信息呈指数性增长,网络流量急增,传统的集中式搜索引擎出现了瓶颈。以internet上产生的数据为例,在facebook公司,每天处理的新数据量超过20tb,随着facebook用户的不断增加以后要处理的数据会变的更加庞大,面对着如此海量传统的存储数据,分布式存储正是为解决这些问题。
hadoop是一种由apache软件基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs,用户可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速运算和存储。目前基于hadoop的大数据生态圈越来越繁荣,尤其是查询计算引擎的不断的更新迭代,针对不同场景和业务下的计算引擎出现许多的差异,导致各种计算的优势无法在一个平台和多种业务下融合应用。
例如mapreduce,是google提出的一个软件架构,用于大规模数据集(大于1tb)的并行运算,map(映射)和reduce(归纳)的概念是其主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性;mapreduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上,其编程模型实现是指定一个map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
但mapreduce只适合批处理,对于传统业务尤其是批量的离线业务,mapreduce无法满足oltp(on-linetransactionprocessing,联机事务处理过程)的业务计算需求,这个时候需要新的计算引擎的出现,提高计算性能、例如tez、spark等的出现;tez是apache最新的支持dag(databaseavailabilitygroup,数据库可用性组)作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升dag作业的性能;spark作为apache顶级的开源项目,是一个快速、通用的大规模数据处理引擎,与hadoop的mapreduce计算框架类似,但是相对于mapreduce,spark凭借其可伸缩、基于内存计算等特点以及可以直接读写hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟;这些有用的不同之处使spark在某些工作负载方面表现得更加优越,换句话说,spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
但如何发挥各自的优势,提高综合查询计算效率,这个需要根据具体的业务需求来进行智能选择,达到提高大数据综合查询的效率。
技术实现要素:
鉴于上述,本发明提供了一种提高基于hadoop大数据综合查询引擎效率的方法及系统,其采用计算智能选择的方式发挥大数据计算的综合效能,利用各计算引擎的优势和通过技术手段避开各引擎的劣势,从而达到大数据查询效率提升的效果。
一种提高基于hadoop大数据综合查询引擎效率的方法,包括如下步骤:
(1)在hadoop分布式服务器集群中对mapreduce、tez、spark三种计算引擎进行部署及测试;
(2)通过互联网与用户交互,获取用户提交的数据查询任务;
(3)根据任务的具体要求智能选择mapreduce、tez或spark来执行所述数据查询任务,并将执行后生成的任务结果重新整理汇总给业务端数据库后通过可视化配置使结果显示反馈给用户。
进一步地,所述步骤(1)的具体实现过程如下:
1.1部署基于hadoop的大数据分布式服务器集群,服务器中必须包含mapreduce、tez、spark三种计算引擎;
1.2分别对mapreduce、tez、spark三种计算引擎进行测试,保证各引擎运行状况正常;
1.3在yarn(yetanotherresourcenegotiator,另一种资源协调者)中增加mapreduce、tez、spark各自的调用接口。
进一步地,所述步骤(3)中对于任务结果延时要求较低、业务已经按照mapreduce设计的且计算量较大的数据查询任务选择mapreduce引擎来执行。
进一步地,所述步骤(3)中对于任务结果延时要求高、业务没有按照mapreduce设计的且计算量较大的数据查询任务选择spark引擎来执行。
进一步地,所述步骤(3)中对于任务结果延时要求较高、业务没有按照mapreduce设计的且计算量较小的数据查询任务选择tez引擎来执行。
进一步地,所述步骤(3)中当数据查询任务执行完成后,按照业务需要通过spark将任务结果整理汇总给业务端数据库。
一种提高基于hadoop大数据综合查询引擎效率的系统,包括:
获取模块,用于通过互联网获取用户提交的数据查询任务;
引擎智选模块,用于根据任务的具体要求调用yarn中的mapreduce、tez或spark接口将任务提交至hadoop分布式服务器集群中对应的计算引擎来执行;
汇总反馈模块,用于将执行生成的任务结果重新整理汇总给业务端数据库;
可视化显示模块,用于从业务端数据库中将任务结果通过可视化配置后显示反馈给用户。
进一步地,所述引擎智选模块对于任务结果延时要求较低、业务已经按照mapreduce设计的且计算量较大的数据查询任务选择mapreduce接口提交执行。
进一步地,所述引擎智选模块对于任务结果延时要求高、业务没有按照mapreduce设计的且计算量较大的数据查询任务选择spark接口提交执行。
进一步地,所述引擎智选模块对于任务结果延时要求较高、业务没有按照mapreduce设计的且计算量较小的数据查询任务选择tez接口提交执行。
本发明利用各计算引擎的优势和通过技术手段避开各引擎的劣势而达到大数据查询效率提升的效果;在实时流处理需要的接口中,本发明切换引擎到spark,再处理任务结束需要切换至批处理的任务,大大减轻新计算引擎对之前的计算引擎的排斥性影响,降低开发人员的业务代码重构,尤其是涉及在老的计算引擎上的复杂业务计算。本发明计算引擎的智能切换,提高了大数据综合查询效率,提高业务场景的适应能力。
附图说明
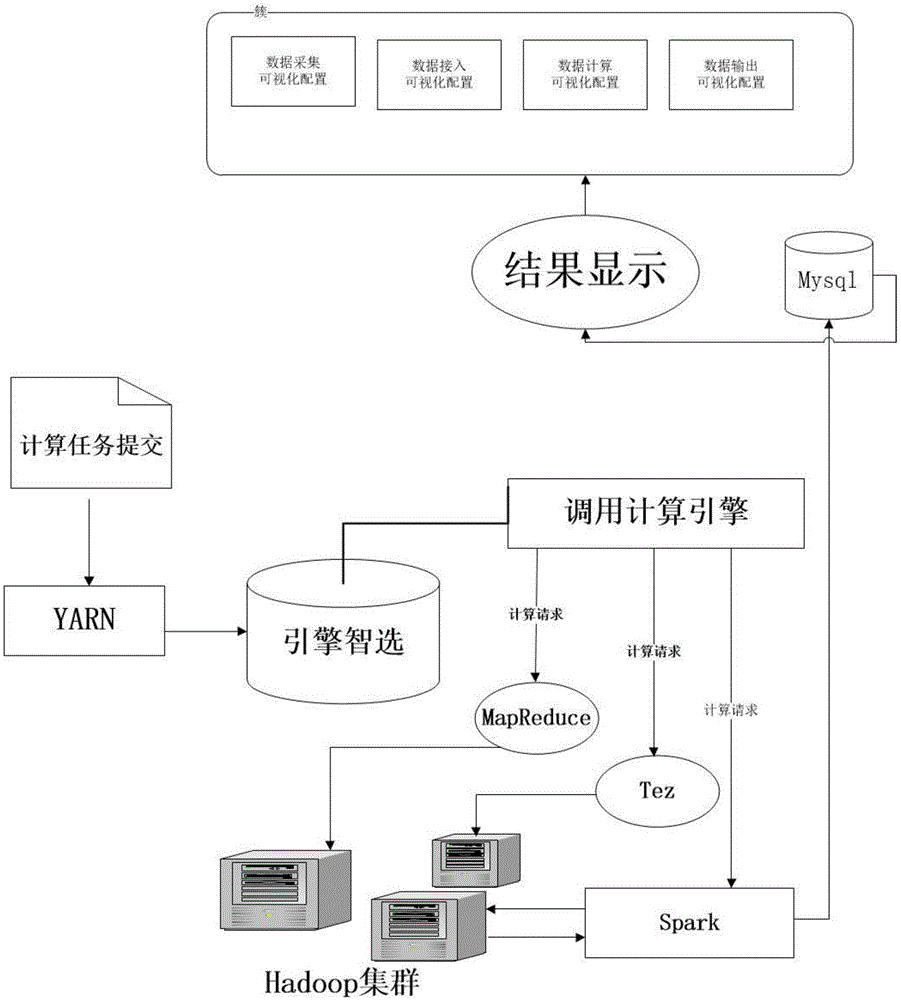
图1为本发明综合计算引擎的系统架构示意图。
图2为本发明引擎智选的逻辑实现框图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
随着大数据技术发展迅速,大数据的计算引擎层出不穷,最具有代表性包括mapreduce、tez、spark等,这些计算引擎各自优势明显,但为了兼容已有的计算引擎,本发明采用计算智能选择的方式发挥大数据计算的综合效能。
如图1所示,本发明的总体技术方案如下:
首先,部署基于hadoop的大数据的服务器集群,组件必须包括mapreduce、tez、spark等计算引擎;
然后,分别测试mapreduce、tez、spark的计算运行状况是否正常;
进而,在yarn的调度中增加mapreduce、tez、spark各自的调用接口,对提交的任务分类采用如图2所示的智选逻辑执行:
1.对任务结果要求延时大、业务已经按照mapreduce设计的,且计算量较大的选择mapreduce接口提交yarn任务;
2.对任务结果要求延时小、业务没有按照mapreduce设计的,且计算量较大的选择spark接口提交yarn任务;
3.对任务结果要求延时较小、业务没有按照mapreduce设计的,且计算量较小的选择tez接口提交yarn任务;
最后,将计算任务结果汇总至spark任务,按照业务需要结果重新整理汇总给业务端数据库。
以下为本发明的一个具体实施案例:
首先,预备14台centos6.5的机器,配置为8核32g4t硬盘,每台机器定要先查看linux系统中所有节点的映射文件,及注释掉127.0.0.1和::1且在其下添加:127.0.0.1localhost,hdp资源(上传到内部云资源机器,默认为ambari-server所在的机器)。
因为hdfs集群中namenode存在单点故障(spof),对于只有一个namenode的集群,如果namenode机器出现意外downtime,那么整个集群将无法使用,直到namenode重新启动。hdfs的ha功能通过配置active/standby两个namenodes实现在集群中对namenode的热备来解决上述问题,如果出现activenn的downtime,就会切换到standby使得nn服务不间断;hdfsha依赖zookeeper,所以需要编辑并配置zookeeper和修改hadoop配置。
hadoop的core-site中需要使用ha.zookeeper.quorum设置zookeeper服务器节点,另外fs.defaultfs需要设置成hdfs的逻辑服务名(需与hdfs-site.xml中的dfs.nameservices一致)。启动过程需要注意顺序:第一次启动格式化hdfs,格式化hdfs的过程中,ha会journalnode通讯,所以需要先把三个节点的journalnode启动;因为namenode记录了hdfs的目录文件等元数据,客户端每次对文件的增删改等操作,namenode都会记录一条日志,叫做editlog,而元数据存储在fsimage中。为了保持stadnby与active的状态一致,standby需要尽量实时获取每条editlog日志,并应用到fsimage中;这时需要一个共享存储,存放editlog,standby能实时获取日志。这有两个关键点需要保证,共享存储是高可用的,需要防止两个namenode同时向共享存储写数据导致数据损坏,所有namenodeha与resourcemanagerha分开装,保证namenodeha的独立性。
因为resourcemanagerha是通过active/standby冗余架构实现的,在任何时间点,其中一个rm处于active状态,其他rm处于standby状态,standby状态的rm就等着active扑街或被撤。通过管理员命令或自动故障转移(需要开启自动故障转移配置),standby就会转为active状态,对外提供服务;当启用resourcemanger重启状态恢复之后,新的active状态的rm会加载上一个rm状态,并根据状态尽可能的恢复之前的操作;应用程序会定期检查,以避免丢失数据,状态存储需要对active状态和standby状态的rm都可见。目前,rmstatestore有两个持久化实现:filesystemrmstatestore和zkrmstatestore,zkrmstatestore隐式的只允许一个rm写入操作,可以没有单独的防护机制就能够避免闹裂问题,所以是ha集群推荐的状态存储方式。
使用zkrmstatestore时,建议不要在zookeeper集群上设置zookeeper.digestauthenticationprovider.superdigest配置,以确保zk管理员无法访问yarn的信息。
在每台机器上必须安装ntp,使用ntp的目的是对网络内所有具有时钟的设备进行时钟同步,使网络内所有设备的时钟保持一致,从而使设备能够提供基于统一时间的多种应用。对于运行ntp的本地系统,既可以接受来自其他时钟源的同步,又可以作为时钟源同步其他的时钟,并且可以和其他设备互相同步。配置ntp,必须设置一台主服务器,ntp服务器提供准确时间,首先要有准确的时间来源,这一时间应该是国际标准时间utc,ntp获得utc的时间来源可以是原子钟、天文台、卫星,也可以从internet上获取,这样就有了准确而可靠的时间源。时间按ntp服务器的等级传播,按照离外部utc源的远近将所有服务器归入不同的stratum(层)中,stratum-1在顶层,有外部utc接入,而stratum-2则从stratum-1获取时间,stratum-3从stratum-2获取时间,以此类推,但stratum层的总数限制在15以内,所有这些服务器在逻辑上形成阶梯式的架构相互连接,而stratum-1的时间服务器是整个系统的基础。所以,配置的ntp的时钟同步,必须保证主服务器的时间是utc,且实时更新,保证同步的子节点的时间准确,以保证计算服务和消息的准确。
为了提供低延迟分析处理,需要找到一个替代直接与hdfsdatanode交互的长久守护进程和一个紧密集成的dag框架,本环境中需要安装hive的llap的相关配置。因为长久守护进程便于缓存和jit优化,并且为了消除大部分的启动成本,守护进程将在集群上的工作节点上运行,处理i/o、缓存和查询片段执行。对llap节点的任何请求都包含数据位置和元数据,包括本地和远程的,任何数据节点仍可用于处理输入数据的任何片段,故障恢复变得更简单,因此tezam可以轻易地重新运行集群上的故障碎片。llap节点能够共享数据(例如获取分区、广播片段),tez中也使用相同机制,llap在现有的基于过程的hive执行中工作,以保持hive的可扩展性和多功能性。llap不是执行引擎(如mapreduce或tez),总体执行由所有的llap节点以及常规容器透明地由现有的hive执行引擎(如tez)进行调度和监视。显然,llap的支持水平取决于每个执行引擎(从tez开始),mapreduce暂不支持,但是以后可能会添加其他引擎,如类似pig框架也可以选择使用llap守护进程。由llap守护程序执行的工作的结果可以构成hive查询结果的一部分,也可以根据查询传递到外部hive任务。llap的acid特性必须配置为启用,因为llap可以感知事务处理;在将数据放入高速缓存之前执行delta文件的合并以产生表的某一状态。
为了将map和reduce两个操作进一步拆分,即map被拆分成input、processor、sort、merge和output,reduce被拆分成input、shuffle、sort、merge、processor和output等;这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的dag作业,所以必须在yarn安装结束后,安装tez,解决现有mr框架在迭代计算(如pagerank计算)和交互式计算方面的不足。
为了满足实时和迭代数据计算的需求,急需一个基于内存计算的并行计算框架、使用内存来存储数据(rdd),用户可以指定存储策略,当内存不够用的时候放到磁盘上,可以满足轻量级快速处理(减少磁盘i/o,用rdd在内存中存储数据,需要持久化才用到磁盘)、支持多种语言、支持复杂查询(sql\流式查询、复杂查询)、实时流处理、图计算,所以安装yarn结束后,也需要部署spark。
以上的环境安装结束后,需要测试hadoop集群的主要的功能是否正常,主要的功能包括namenodeha、resourcemanagerha、mapreduce、hivellap、tez、spark等功能的正常,然后就要部署并测试引擎智选的程序。启动程序后,往flume的文件池传入日志类数据,测试spark的是否正常处理数据,等处理结束后往flume的文件池传入结构化数据并设置计算延时要求,如果是低延时,看看hive设置的llap的tez计算是否正常;如果是高延时,看看mapreduce的计算是否启动和正常计算,往flume的文件池传入结构化数据,看看mapreduce的计算是否启动和正常计算。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!