基于自适应权重哈希循环对抗网络的零样本图像分类方法与流程
本发明涉及一种零样本图像分类方法。特别是涉及一种基于自适应权重哈希循环对抗网络的零样本图像分类方法。
背景技术:
自适应权重算法是一种基于格式塔互连(gestaltgrouping)的机制而产生的一套权值分配原则。它主要是用于解释人类视觉系统如何判别前景和背景的方法。当观察一张图像时,显著的物体人们就会给予较多的关注,也就自然而然地把它当作前景,而其余不关注的部分就被当作背景。一开始人们观察一张图像时,只能获得前景的一部分,然后是通过对这一部分进行不断扩展和更为细致的研究,运用该机制对这一部分图像的像素进行权值分配,与中心像素越接近、颜色越相似的像素分配较大的权重,相反相距越远的、颜色越相异的分配较小权重。本发明运用的自适应权重哈希同样运用了该机制,在视觉特征和语义特征中给予相同的类别图像的特征以较大权重,相差越大的类别权重分配越低。
根据先验知识,人类具有来推断未见类别事物的能力,例如:一开始从未见过“大象”,但能根据“大象”的文本描述信息“大鼻子,两边大牙,像河马一样体型硕大”,对大象进行类别分类。受该推断能力的启发,零样本图像分类的目标是通过大量样本的学习,能够对训练阶段从未出现过的类别进行分类和表征。为有效地得到训练图像更多的特征信息,使高维视觉特征转化为低维语义特征中特征信息利用最大化,故使用循环对抗网络(cyclegan)来训练权重哈希网络。
与传统的生成式对抗网络不同,cyclegan解决了模型训练数据不成对的问题,将一类图片转换成另一类图片,即想要获取一个数据集的特征,却转化为另一个数据集的特征。该网络实际的目标就是学习两个映射,样本空间x到样本空间y的映射f和样本空间y到样本空间x的映射g,并要求f(g(y))≈y以及g(f(x))≈x,这样空间x的图片转换到y空间后还可以转换回x空间,也杜绝了模型可以把所有x的图片都转换为y空间中的同一张图片的特殊情况。
因此,在该网络的两个映射过程中加入自适应权重哈希学习可减少哈希编码的冗余性,利用网络的两个映射被分解为二进制代码生成h和从二进制代码重新生成输入的逆过程p,将两个哈希码对源域和目标域进行映射,极大地提高了相近图像类别在汉明空间的距离相似度,而使不同图像类别距离相差更远。
针对某些特定情况,为了将训练的图像和文本信息利用最大化,提出了自适应权重哈希循环一致性对抗学习,以达到零样本图像分类效果的目的。
零样本情况下,给定可见类样本集合s={(xi,zi,yi),i=1,2,3,…,n},xi∈xs为可见类视觉特征,zi∈zs为可见类语义特征,yi∈ys为可见类类别,n为可见类实例样本的数目。零样本分类的目的是通过给定的未见类视觉特征和文本语义特征来预测的未见类的类别yj∈yu,j=1,…,m,其中
技术实现要素:
本发明所要解决的技术问题是,提供一种能够实现不同模态的特征和对应类别进行知识迁移的基于自适应权重哈希循环对抗网络的零样本图像分类方法。
本发明所采用的技术方案是:一种基于自适应权重哈希循环对抗网络的零样本图像分类方法,包括如下步骤:
1)将训练样本的视觉特征xi和文本语义类别特征xt分别采用如下公式进行循环对抗网络映射h*,得到对应的哈希码h(x):
其中x*是视觉特征或文本语义类别特征,wh,v是自适应权重哈希的网络参数;
2)将步骤1)所生成的各特征的哈希码进行权重分配,建立自适应权重哈希模型;
3)对自适应权重哈希模型进行训练和测试;
4)为拟合函数q(h/x),对编码函数p(h/x)进行重新参数化,
其中
5)将视觉特征xi和文本语义类别特征xt的哈希码分别采用如下公式进行p*映射,得到对应的编码p(h/x):
将伯努利变量变量hk(z),z∈(0,1)重新参数化:
其中ξ~μ(0,1)是任意变量,随机神经元被用于重新参数化二进制变量h,用
6)通过p*映射将哈希码转换为另一模态特征,
再由循环一致性对抗网络的生成器f或g,转换为原模态视觉或者语义特征,使得循环一致性损失达到最小,从而实现跨模态零样本分类。
步骤2)包括:
(1)定义自适应权重哈希模型的类元素权重层,生成自适应权重w;将步骤1)得到的哈希码h(x)和自适应权重w代入如下公式,得到类元素的权重ω(hx):
ω(hx)=w(cx,:)·hx,s.t.w≥0
其中hx是x*输出的哈希码,cx是x*的图像或者文本的类别索引,·指的是元素的内积;(2)定义权重汉明距离h(xi,xj):
其中k为码字;二进制码bk(x)=sgn(hk(x)-0.5),k=1,…,q;hk(x)表示各类别的哈希码;xi,xj表示不同的两个特征;
(3)定义三元权重排序损失函数
其中m是连续参数,该参数定义了这两个变量
(4)定义训练时各个类别softmax损失:
其中,
(5)用三元权重排序损失函数分别对
其中ic是指示函数,如果c为真,则ic=1,否则ic=0;
(6)用如下公式计算类元素权重层的梯度,从而更新自适应权重网络参数w
(7)由于softmax损失,计算θj的梯度为:
步骤3)所述的训练包括对自适应权重哈希模型输入:图像x,参数m后,进行如下过程:
(1)通过神经网络前向传播将图像x转变为h(x);
(2)计算三元权重排序损失函数
(3)计算softmax损失lc(θ);
(4)计算
(5)联合训练第(4)步得到的梯度,通过神经网络反向传播不断更新自适应权重网络参数w,直到
(6)输出自适应权重网络参数w。
步骤3)所述的测试包括对自适应权重哈希模型输入自适应权重网络参数w,测试图像xq,汉明空间数据库b后,进行如下过程:
(1)导入自适应权重w到类元素权重层;
(2)预测类别概率p(xq);
(3)生成对应哈希码h(xq);
(4)生成自适应权重w(xq),wq=wtp(xq);
(5)计算权重汉明距离h(xi,xq);
(6)通过权重汉明距离大小分类图像;
(7)输出分类图像的哈希码。
本发明的基于自适应权重哈希循环对抗网络的零样本图像分类方法,主要优势体现在:
(1)新颖性:提出了一种新的通过自适应权重哈希cyclegan的框架用于解决零样本分类问题。通过循环一致性对抗权重哈希网络,学习一种联合嵌入模型,从而实现了不同模态的特征和对应类别进行知识迁移。
(2)多模态性:本发明提出的自适应权重哈希cyclegan的框架将视觉模态特征和类别标签的语义文本模态特征联合嵌入到权重的汉明空间中,在对抗学习的过程中,将样本嵌入特征和类别嵌入特征与类别标签结合,实现不同模态特征到类别的知识迁移。
(3)有效性:与传统的对抗网络学习方法不同,本发明所提出的算法主要是通过自适应权重哈希循环一致性来体现的,对抗学习的方式上也有本质的不同,本发明是将模态经过一系列映射后还是会回到原模态,使模态特征学习后的信息损失到尽可能小,极大地保留了样本特征的低维语义信息,提高了信息嵌入特征的表征能力,有利于最终达到零样本分类的目的。
(4)实用性:简单可行,操作方便。可广泛应用于许多零样本分类任务以及图像的检索、目标检测、语义描述和识别等问题的相关领域中。
附图说明
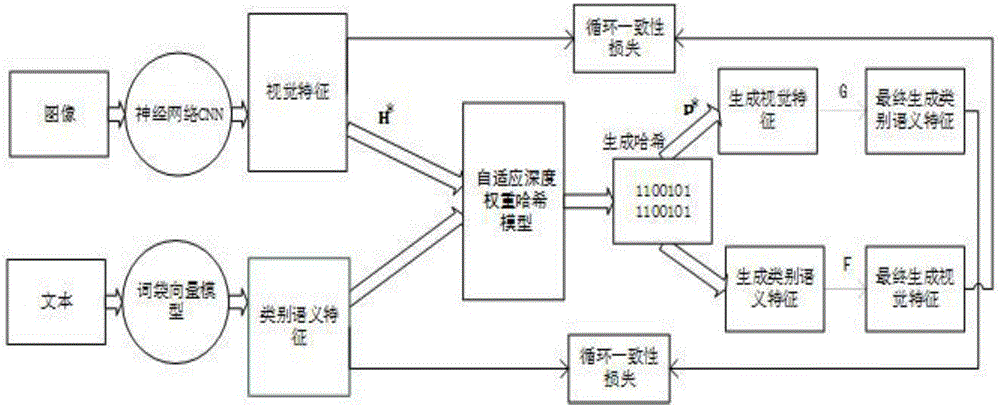
图1是本发明基于自适应权重哈希循环对抗网络的零样本图像分类方法的原理图;
图2是本发明使用的cyclegan网络的映射原理图;
图3是对图1自适应权重哈希模型的具体实现过程图。
具体实施方式
下面结合实施例和附图对本发明的基于自适应权重哈希循环对抗网络的零样本图像分类方法做出详细说明。
本发明的基于自适应权重哈希循环对抗网络的零样本图像分类方法,因为跨模态生成哈希是通过哈希码对不同模态的目标对象进行翻译转换,因此其语义一致性的实现没有数据成对的约束限制。利用对抗网络先将视觉特征和文本特征做两个映射,全部映射到汉明空间后,通过自适应权重哈希算法进行分配,生成自适应权重,经过权重汉明距离后生成分类图像的哈希码,最后由循环一致性损失计算映射到的预测视觉特征和文本特征,从而较大地提高了跨模态多媒体信息的利用率。在该模型中,图像各特征先进入二进制码生成器h*,之后引入了自适应深度权重哈希模型训练得到自适应权重w,通过权重w计算权重汉明距离h(xi,xj),生成二进制哈希hi,ht,运用二进制码生成输入的逆过程p*,由生成器f或g,返回原图像特征,最后通过循环一致性损失从而实现跨模态,达到零样本分类的目的。
如图1所示,本发明的基于自适应权重哈希循环对抗网络的零样本图像分类方法,包括如下步骤:
1)将训练样本的视觉特征xi和文本语义类别特征xt分别采用如下公式进行循环对抗网络映射h*,得到对应的哈希码h(x):
其中x*是视觉特征或文本语义类别特征,wh,v是自适应权重哈希的网络参数;
2)将步骤1)所生成的各特征的哈希码进行权重分配,建立自适应权重哈希模型;包括:
(1)定义自适应权重哈希模型的类元素权重层,生成自适应权重w;将步骤1)得到的哈希码h(x)和自适应权重w代入如下公式,得到类元素的权重ω(hx):
ω(hx)=w(cx,:)·hx,s.t.w≥0(2)
其中hx是x*输出的哈希码,cx是x*的图像或者文本的类别索引,·指的是元素的内积;即,通过类元素权重得到类元素权重层,每张图像的哈希码与所对应的自适应类别权重相乘得到各特征x*的类元素的权重ω(hx);
(2)定义权重汉明距离h(xi,xj):
其中k为码字;二进制码bk(x)=sgn(hk(x)-0.5),k=1,…,q;hk(x)表示各类别的哈希码;xi,xj表示不同的两个特征;
所得的汉明距离用权重欧几里得距离代替简化来计算量,
(3)定义三元权重排序损失函数
其中m是连续参数,该参数定义了这两个变量
(4)定义训练时各个类别softmax损失:
其中,
(5)用三元权重排序损失函数分别对
其中ic是指示函数,如果c为真,则ic=1,否则ic=0;
(6)用如下公式计算类元素权重层的梯度,从而更新自适应权重网络参数w
(7)由于softmax损失,计算θj的梯度为:
3)如图3所示,对自适应权重哈希模型进行训练和测试;使用bp神经网络反向传播更新权重网络参数w,并不断循环以上公式(19)(20)(21),直至lr和lc收敛,最终输出自适应哈希权重的类元素权重w。然后代入参数w计算权重汉明距离,生成对应分类库图像哈希码。其中,
所述的训练包括对自适应权重哈希模型输入:图像x,参数m后,进行如下过程:
(1)通过神经网络前向传播将图像x转变为h(x);
(2)计算三元权重排序损失函数
(3)计算softmax损失lc(θ);
(4)计算
(5)联合训练第(4)步得到的梯度,通过神经网络反向传播不断更新自适应权重网络参数w,直到
(6)输出自适应权重网络参数w。
所述的测试包括对自适应权重哈希模型输入自适应权重网络参数w,测试图像xq,汉明空间数据库b后,进行如下过程:
(1)导入自适应权重w到类元素权重层;
(2)预测类别概率p(xq);
(3)生成对应哈希码h(xq);
(4)生成自适应权重w(xq),wq=wtp(xq);
(5)计算权重汉明距离h(xi,xq);
(6)通过权重汉明距离大小分类图像;
(7)输出分类图像的哈希码。
4)定义最大似然生成的输入x与对应二进制码h
pi:hi→xt定义为p(xt/hi)
pt:ht→xi定义为p(xi/ht)
p(x,h)=p(x/h)p(h),p(x/h)=n(uh,ρ2i)满足简单高斯分布。
其中
先验概率
为拟合函数q(h/x),对编码函数p(h/x)进行重新参数化,
其中
5)将视觉特征xi和文本语义类别特征xt的哈希码分别采用如下公式进行p*映射,得到对应的编码p(h/x):
将伯努利变量变量hk(z),z∈(0,1)重新参数化:
其中ξ~μ(0,1)是任意变量,随机神经元被用于重新参数化二进制变量h,用
6)如图2通过p*映射将哈希码转换为另一模态特征,
再由循环一致性对抗网络的生成器f或g,转换为原模态视觉或者语义特征,使得循环一致性损失达到最小,从而实现跨模态零样本分类。
- 还没有人留言评论。精彩留言会获得点赞!