基于深度学习和RPCA的太赫兹图像目标识别方法与流程
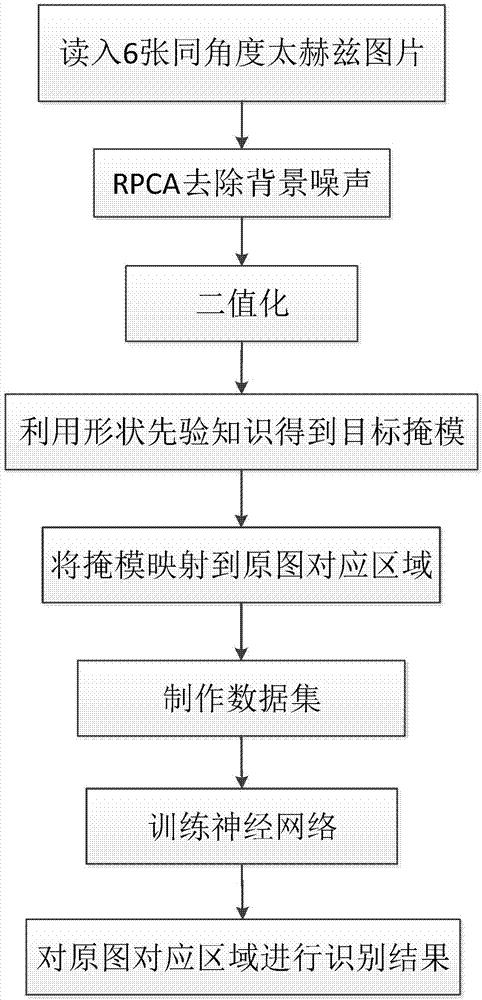
本发明属于图像处理
技术领域:
,更进一步涉及图像识别
技术领域:
中的一种基于深度学习和稳健主成分分析rpca(robustprinciplecomponentanalysis)的太赫兹图像目标识别方法。本发明可用于公共安全领域中的对太赫兹安检图像进行目标检测和识别。
背景技术:
:太赫兹波(thz波)包含了频率为0.1到10thz的电磁波。该术语适用于从电磁辐射的毫米波波段的高频边缘(300ghz)和低频率的远红外光谱带边缘(3000ghz)之间的频率,对应的波长的辐射在该频带范围从0.03mm到3mm。简单的说,太赫兹波是一种非接触的、非破坏性的检测手段,而且能穿透许多成像技术(如超声波和热成像技术)穿透不了的高密度分子结构。在公共安全领域中,太赫兹波作为一种有效的检测手段已经开始进入大众视野,太赫兹安检仪也已经开始大规模商用。由于太赫兹安检仪设备的图像采集技术尚未成熟,太赫兹图像的像素比较低。太赫兹图像角度仅限于几个固定角度,因此同一角度获得的太赫兹图像具有相似的背景。目前还没有针对太赫兹图像的目标识别算法,对太赫兹图像目标的识别方式仍停留在人眼辨别,不仅需要耗费大量的人力资源,而且由于人眼的疲劳性,会导致误检率上升,降低检测效率。如果不结合太赫兹图像的特点,直接采用经典的目标识别算法,识别效果很差。felzenszwalb等人在其发表的论文“adiscriminativelytrained,multiscale,deformablepartmodel”(ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2008)中提出可变形部件模型dpm(deformablepartmodel)中公开了一种基于组件的目标识别方法。该方法先计算梯度方向直方图,然后利用支持向量机svm(surpportvectormachine)训练得到物体的梯度模型,使用得到的模型和目标进行匹配。可变形部件模型dpm将传统目标检测方法中对目标整体的检测问题拆分并转化为对模型各个部件的检测问题,但是该方法仍然存在的不足之处在于,模型和目标的匹配计算量很大,导致识别时间大大增加,不能用于太赫兹图像的实时检测。shaoqingren等人在其发表的论文“fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks”(ieeetransactionsonpatternanalysis&machineintelligence,2015)中公开了一种基于深度学习的目标识别方法。该方法主要思路是:利用区域建议网络rpn(regionproposalnetwork),快速生成候选区域,通过候选区域生成建议框,对建议框进行分类和回归得到识别结果。但是该方法存在的不足之处在于,没有利用太赫兹图像背景相似性的特点去除大量背景噪声,区域建议网络rpn直接对整张太赫兹图像生成候选区域,在实时检测的应用上准确率不高、检测时间较长,不能用于太赫兹图像的实时检测。技术实现要素:本发明的目的是针对现有技术存在的不足,提供一种基于深度学习和rpca太赫兹图像的目标识别方法。实现本发明目的的思路是,通过采用稳健主成分分析rpca方法对太赫兹图像进行分解,去除背景噪声干扰;结合形状先验的知识进一步将兴趣目标区域缩小,得到太赫兹目标掩模图像;构建训练集,使用人工标记信息训练基于深度学习的目标识别网络fasterr-cnn;将太赫兹目标掩模图像映射到原图像对应的区域;将原图像对应的区域输入训练好的目标识别网络faster-rcnn进行智能目标识别。本发明实现的具体步骤包括如下:(1)使用稳健主成分分析rpca方法去除背景噪声:(1a)依次输入由相同角度获取的6张大小为200×380×3像素的太赫兹图像,将每张图像拉为列向量,按照图像输入次序组成矩阵xi;(1b)对矩阵xi在满足约束条件||xi-li-si||f<d的条件下,使目标函数||li||*+m||si||1的值最小,得到满足约束条件的低秩的背景噪声矩阵li和稀疏的去除背景噪声的矩阵si,其中,||||f表示求f-范数操作,xi表示图片大小为200×380×3个像素的太赫兹图像矩阵,li表示低秩的背景噪声矩阵,si表示稀疏的去除背景噪声的矩阵,d表示取值为10-3的常数,||||*表示求核范数操作,m表示大于零的权因子,||||1表示求1-范数操作;(1c)将稀疏矩阵si按照输入次序依次还原为6张图像;(2)使用形状先验知识缩小兴趣目标区域:(2a)对还原后的每张图像进行二值化操作,得到二值化后的图像;(2b)连通每张二值化后图像中满足上下左右四个方向的相邻像素值均为1的像素,得到每张二值化后图像中所有的连通区域;(2c)删除所有二值化后图像连通区域中的像素总数小于350个的连通区域,利用形状先验知识保存长宽比范围在1.0~5.0的矩形连通域,将剩余的连通区域组成目标掩模图像;(3)生成太赫兹图像数据集:(3a)将包含太赫兹图像中的目标位置信息的txt文件生成xml文件;(3b)将xml文件内容按照8:2的比例,生成训练验证集和测试集;将训练验证集的内容按照8:2的比例,生成训练集和验证集;(3c)将太赫兹图像、xml文件、训练集、验证集、测试集输入到imagenet文件夹中;(4)训练深度学习网络faster-rcnn:(4a)使用预训练模型初始化深度学习网络faster-rcnn中的特征提取网络参数、区域建议网络rpn参数和识别网络rcnn参数;(4b)将训练集中的图像依次输入特征提取网络,更新特征提取网络的参数,输出每张图像的特征图;(4c)将每张图像的特征图依次输入区域建议网络rpn,更新区域建议网络rpn的参数,区域建议网络rpn输出训练集中的每张图像对应的矩形候选框;(4d)将每张图像的每个矩形候选框和特征图分别输入识别网络rcnn,更新识别网络rcnn的参数,识别网络rcnn输出修正的目标位置和类别;(4e)保持特征提取网络参数不变,将每张图像的特征图依次输入区域建议网络rpn,第二次更新区域建议网络rpn参数,区域建议网络rpn输出第二次更新后每张图像对应的矩形候选框;(4f)将特征图和更新后每张图像对应的矩形候选框分别输入识别网络rcnn,第二次更新识别网络rcnn参数,识别网络rcnn输出第二次更新后的修正目标位置和类别;(4g)判断网络rcnn是否收敛,若是,则得到训练好的深度学习网络faster-rcnn后执行步骤(5),否则,执行步骤(4c);(5)利用深度学习网络识别太赫兹图像目标:(5a)将目标掩模图像中的每个连通区域映射到原图像对应的区域,将原图像对应的区域像素输入到训练好的神经网络faster-rcnn中的特征提取网络,输出原图像对应区域的特征图;(5b)将原图像对应区域的特征图输入到训练好的神经网络faster-rcnn中的区域建议网络rpn,输出建议窗口;(5c)将建议窗口与原图像对应区域的特征图输入到训练好的神经网络faster-rcnn中的识别网络rcnn,输出识别结果。与现有技术相比,本发明有以下优点:第一,由于本发明使用了稳健主成分分析rpca方法去除背景噪声,克服了现有技术直接对太赫兹图像进行目标检测时容易受图像背景噪声影响大的问题,使得本发明具有了去除背景噪声后检测准确率高的优点。第二,由于本发明使用了形状先验知识缩小兴趣目标区域,克服了现有技术直接对所有兴趣目标图像区域进行目标检测容易受兴趣目标区域不确定影响大的问题,使得本发明具有缩小兴趣目标区域后检测时间短的优点。第三,由于本发明使用了深度学习网络对太赫兹图像进行目标识别,克服了现有技术使用的人眼识别太赫兹图像目标的不足,受人眼疲劳性影响大的问题,使得本发明具有智能检测的优点。附图说明图1为本发明流程图;图2为本发明仿真实验所使用的太赫兹图像;图3为本发明使用三种方法的仿真图;图4为本发明的仿真实验的效果图。具体实施方式下面结合附图对本发明作进一步描述。参照图1,本发明的具体实现步骤如下:步骤1,使用稳健主成分分析rpca方法去除背景噪声。第1步,依次输入由相同角度获取的6张大小为200×380×3像素的太赫兹图像,将每张图像拉为列向量,按照图像输入次序组成矩阵xi。第2步,对矩阵xi在满足约束条件||xi-li-si||f<d的条件下,使目标函数||li||*+m||si||1的值最小,得到满足约束条件的低秩的背景噪声矩阵li和稀疏的去除背景噪声的矩阵si,其中,||||f表示求f-范数操作,xi表示图片大小为200×380×3个像素的太赫兹图像矩阵,li表示低秩的背景噪声矩阵,si表示稀疏的去除背景噪声的矩阵,d表示取值为10-3的常数,||||*表示求核范数操作,m表示大于零的权因子,||||1表示求1-范数操作。第3步,将稀疏矩阵si按照输入次序依次还原为6张图像。步骤2,使用形状先验知识缩小兴趣目标区域。第1步,对还原后的每张图像进行二值化操作,得到二值化后的图像。所述二值化操作的具体步骤为:设置门限为tm=130,将灰度值大于等于门限值的像素点设定1,将灰度值小于门限值的像素点设定为0。第2步,连通每张二值化后图像中满足上下左右四个方向的相邻像素值均为1的像素,得到每张二值化后图像中所有的连通区域。第3步,删除所有二值化后图像连通区域中的像素总数小于350个的连通区域,利用形状先验知识保存长宽比范围在1.0~5.0的矩形连通域,将剩余的连通区域组成目标掩模图像。步骤3,生成太赫兹图像数据集。第1步,将包含太赫兹图像中的目标位置信息的txt文件生成xml文件。第2步,将xml文件内容按照8:2的比例,生成训练验证集和测试集;将训练验证集的内容按照8:2的比例,生成训练集和验证集。第3步,将太赫兹图像、xml文件、训练集、验证集、测试集输入到imagenet文件夹中。步骤4,训练深度学习网络faster-rcnn。第1步,使用预训练模型初始化深度学习网络faster-rcnn中的特征提取网络参数、区域建议网络rpn参数和识别网络rcnn参数。第2步,将训练集中的图像依次输入特征提取网络,更新特征提取网络的参数,输出每张图像的特征图。第3步,将每张图像的特征图依次输入区域建议网络rpn,更新区域建议网络rpn的参数,区域建议网络rpn输出训练集中的每张图像对应的矩形候选框。第4步,将每张图像的每个矩形候选框和特征图分别输入识别网络rcnn,更新识别网络rcnn的参数,识别网络rcnn输出修正的目标位置和类别。第5步,保持特征提取网络参数不变,将每张图像的特征图依次输入区域建议网络rpn,第二次更新区域建议网络rpn参数,区域建议网络rpn输出第二次更新后每张图像对应的矩形候选框。第6步,将特征图和更新后每张图像对应的矩形候选框分别输入识别网络rcnn,第二次更新识别网络rcnn参数,识别网络rcnn输出第二次更新后的修正目标位置和类别。第7步,判断网络rcnn是否收敛,若是,则得到训练好的深度学习网络faster-rcnn后执行步骤5,否则,执行步骤第3步。所述的网络fast-rcnn收敛是指,识别网络fast-rcnn的代价函数loss小于0.01,所述代价函数为:loss=loss_cls+λloss_bbox其中,loss表示识别网络fast-rcnn的代价函数,loss_cls表示真实类别值和预测类别值的误差,λ表示真实矩形框坐标和预测矩形框坐标误差的权重,loss_bbox表示真实矩形框坐标值和预测矩形框坐标值的误差。步骤5,利用深度学习网络识别太赫兹图像目标。第1步,将目标掩模图像中的每个连通区域映射到原图像对应的区域,将原图像对应的区域像素输入到训练好的神经网络faster-rcnn中的特征提取网络,输出原图像对应区域的特征图。第2步,将原图像对应区域的特征图输入到训练好的神经网络faster-rcnn中的区域建议网络rpn,输出建议窗口。第3步,将建议窗口与原图像对应区域的特征图输入到训练好的神经网络faster-rcnn中的识别网络rcnn,输出识别结果。本发明的效果通过以下仿真实验进一步说明。1.仿真实验条件:本发明仿真实验的计算机配置环境为intelxeon(r)cpue5-2609v22.5ghz、内存125.9g、linux操作系统,编程语言使用python,数据库采用太赫兹图像数据库。2.仿真实验内容:本发明仿真实验采用本发明的方法以及现有技术的基于深度学习的目标识别方法,分别对太赫兹图像进行目标识别。所采用的太赫兹图像如附图2所示。本发明仿真实验所采用的测试样本集由太赫兹图像数据库中随机抽取的10%太赫兹图像组成,其中,图2(a)是从测试样本集中标签为“b”(水瓶,bottle)的太赫兹图像中任意抽取的一张图像,图2(b)是从测试样本集中标签为“g”(枪,gun)任意取出的一张测试图像,图2(c)是从测试样本集中标签为“k”(刀,knife)任意取出的一张测试图像,图像大小为200×380×3。本发明的方法的仿真实验过程包括对图2中所抽取的3幅图像经过稳健主成分分析rpca、二值化操作、利用形状先验知识得到目标掩模,其中图3(a)是对测试样本2(a)进行稳健主成分分析rpca方法后的效果图,图3(b)是对测试样本2(b)进行稳健主成分分析rpca方法后的效果图,图3(c)是对测试样本2(c)进行稳健主成分分析rpca方法后的效果图,图3(d)是对图像3(a)进行二值化操作后的效果图,图3(e)是对图像3(b)进行二值化操作后的效果图,图3(f)是对图像3(c)进行二值化操作后的效果图,图3(g)是对图像3(d)通过形状先验知识缩小兴趣区域后的效果图,图3(h)是对图像3(e)通过形状先验知识缩小兴趣区域后的效果图,图3(i)是对图像3(f)通过形状先验知识缩小兴趣区域后的效果图。本发明仿真实验采用的现有技术是使用基于深度学习的方法。详见参考文献为“shaoqingren,kaiminghe,rossgirshick”(fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks,ieeetransactionsonpatternanalysis&machineintelligence,2015)。3.仿真实验结果分析:本发明的方法的仿真实验图像结果如附图4所示,其中图4(a)是对图像3(g)映射到图像2(a)进行目标识别的结果图,矩形框中文字的意思是识别目标为‘b’(瓶子)的置信度水平为0.994,图4(b)是对图像3(h)映射到图像2(b)进行目标识别的结果图,矩形框中文字的意思是识别目标为‘g’(枪)的置信度水平为0.999,图4(c)是对图像3(i)映射到图像2(c)进行目标识别的结果图,红色框中文字的意思是识别目标为‘k’(刀)的置信度水平为0.998。置信度水平是用于判断图像中目标属于具体类别的概率,也就是可相信程度的指标。本发明的仿真实验设置置信度阈值为0.4,即只显示置信度大于等于0.4的检测框。由图4可以看出,由于本发明采用了基于深度学习的目标识别方法,已经可以实现对太赫兹图像中的3种目标(瓶子、枪、刀)进行智能识别,与传统的人眼检测相比,节省了大量的人力资源。下面通过数据对本发明仿真实验的结果做进一步的描述。所述的数据包括精确度ap、平均精确度map、识别时间。精确度ap(averageprecision)是指每一类别预测正确的个数/测试总个数的平均值。平均精确度map(meanaverageprecision)是指对所有类别的ap取均值。识别时间是指对一张图片识别出目标的平均耗时。表1是本发明的方法和基于深度学习的方法的识别精确度ap结果对比表。表1.本发明仿真结果的识别准确率ap对比表类别基于深度学习的方法本发明“b”(瓶子)73.775.0“k”(刀)89.290.3“g”(枪)90.891.4map84.585.6表2是本发明的方法和基于深度学习的方法的识别时间的结果对比。表2.本发明仿真结果的识别时间对比表平均检测时间基于深度学习的方法本发明second(秒)0.042s0.007s由表1和表2可以看出,由于本发明的方法使用稳健主成分分析rpca方法去除背景噪声,利用形状先验知识缩小兴趣区域生成目标掩模图像,将目标掩模图像映射到原太赫兹图像对应的区域,使用本发明中基于深度学习的识别网络faster-rcnn对原太赫兹图像对应的区域进行目标识别,实现了对太赫兹图像目标的智能检测,并在基于深度学习的方法基础上,缩短了检测时间,提升了识别准确率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1