基于词向量模型的法条推荐方法与流程
本发明属于推荐系统技术领域,尤其是推荐系统技术领域中的协同过滤推荐技术,是用于根据诉讼案件的案件基本情况进行推荐法条的技术。
背景技术:
近年来,最高人民法院以“大数据、大格局、大服务”理念为指导,积极推进和落实全面依法治国战略部署,大力推进人民法院信息化建设。裁判文书作为法律审判活动记录的载体,完整反映了当事人主张、举证和质证的客观过程,并全面阐述了裁判结果形成的法律依据、事实证据和推理过程。裁判文书是一类重要的司法数据,截至2018年9月,已有超过5200万份裁判文书被收录并公布于中国裁判文书网。
基于海量裁判文书的文本挖掘,将有助于挖掘司法规律,并指导司法实践,因此,面向司法大数据的研究工作,以及“人工智能+法律”的概念成为热点研究话题。基于自然语言处理和机器学习的语义检索,法律问答,法律援助,在线法院等都将使法律行业的运行方式变得更加智能与高效。
在案件审判过程中,法官需要结合当事人的诉求以及案件的证据与事实,阅读大量的法律法规来选择合适的法律法条作为依据,从而确定案件判决结果。由于成文法繁多,同一个问题可能会出现在不同的法律规范中,因此法官需要阅读大量的法律法规,这一过程通常需要耗费大量的时间和精力。由于这个原因,法院工作中的一些矛盾和问题逐渐显现,其中“同案不同判、法律适用的不统一”便是其中之一,同案同判成为广大公众对法律的诉求。对于案件的当事人,在案件咨询与诉讼过程中,他们往往需要支付高昂的律师咨询费来了解案件的情况以及可能的判决结果。
法条推荐的价值正体现在这两方面:一方面法条推荐可以为法官推荐案件可能适用的法条,提高法官的工作效率,帮助法官实现同案同判,确保公平正义,另一方面法条推荐可以帮助当事人了解同类案件的诉讼结果和相关法条,形成最佳的诉讼策略,节约法律咨询和诉讼的成本。
本发明提出了一种基于词向量模型的法条推荐方法,词向量模型是文本语义建模的一种,它使用神经网络等机器学习技术将自然语言的词语转换成低维度的数据。词向量模型不仅避免了传统自然语言处理过程中面临的高维度引发的一系列问题,如计算量庞大、存储空间受限等问题,而且能够充分地保留词语的信息。
词向量模型优于其它自然语言处理模型还在于其模糊表达的能力,词向量在向量空间的位置信息蕴含了一定的语义信息。在词向量模型中,通过向量空间的计算可以获得词语之间的上下义关系、总分关系、类义关系(相近关系、相反关系等)词语对之间的对应关系等,极大地扩展了语言处理的能力,是传统自然语言模型难以简单完成的。
借助词向量模型强大的文本语义表达能力,基于词向量模型的文本处理度量方法如词移动距离(wordmover’sdistance,简称wmd)、松弛词移动距离(relaxedwmd,简称rwmd)、词矩心距离(wordcentroiddistance,简称wcd)产生,相比于传统方法如词袋模型(bagofwords)词频及逆文本频率指数统计方法(termfrequency-inversedocumentfrequency,简称tf-idf)、隐狄利克雷文档主题生成模型(latentdirichletallocation,简称lda)的优势在于,它们在处理文档相似程度这一类问题上,借助词向量模型的模糊表达能力和向量空间的计算,可以更好地度量文档之间的相似程度。
同时,wmd和rwmd或者wmd和wcd之间拥有高度相关的特性,所以可以借助rwmd和wcd的计算,对海量数据进行预剪枝。这样,即避免了wmd运算较慢的劣势,同时最大限度地使用了wmd在度量文档之间相似程度上面的优势。
在推荐系统中,推荐方法是推荐系统中最重要的部分,推荐方法的好坏往往决定了推荐系统的好坏,主要的推荐方法包括基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐和基于知识推荐和组合推荐。协同过滤推荐技术是推荐系统最早以及最成功的推荐技术之一,协同过滤基于假设:相似的事物蕴含相似的结果信息,所以它可以通过借助相似的事物来为事物推荐或者筛选信息。
传统的协同过滤应用通过其他相似事物的结果信息和部分目标事物结果信息补全目标结果信息缺值的方式来得到推荐结果,即使用结果信息来描述和比较事物之间的相似度。本发明中使用的协同过滤技术符合其更广义的定义,针对裁判文书中事物特征(案件基本情况等描述信息)和结果信息(引用法条)分离的情况,使用词移动距离(wmd)度量文书案件基本情况特征的相似程度,然后使用多种推荐策略向目标文书推荐法条。
技术实现要素:
本发明要解决的技术问题是:提供一种基于词向量模型的法条推荐方法,该方法能够更准确地表达两段案件基本情况的相似程度,并且可以采取多种协同过滤推荐策略,获得更准确的推荐结果。
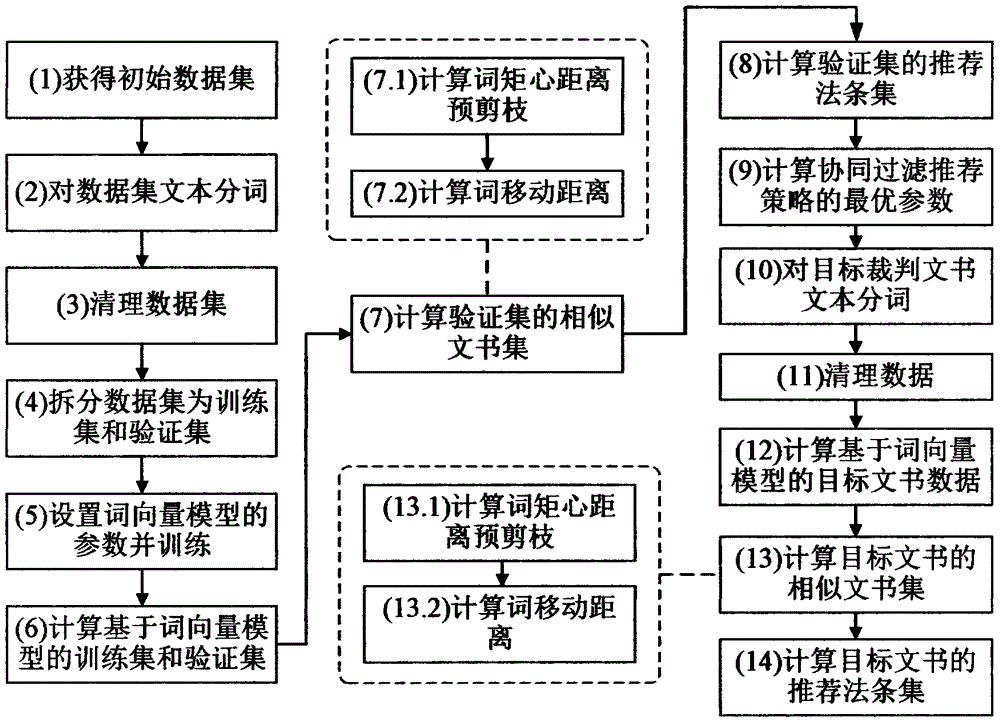
本发明的技术方案为:基于词向量模型的协同过滤推荐技术,首先对案件基本情况文本进行预处理,包括对文本分词、去除停用词。然后训练词向量模型以获得案件基本情况的词向量表示,使用词移动距离(wmd)度量案件基本情况之问的距离,获得相似文书集合,根据协同过滤推荐策略向文书推荐法条,该推荐方法整体流程如图1所示。包含以下步骤(如图2所示):
步骤(1)获取已经成文的裁判文书集的案件基本情况集合a1={a1,a2,...,an}和引用的法条集合f1={f1,f2,...,fn};
步骤(2)根据集合a1,获得分词后的案件基本情况集合a2={a′1,a′2,...,a′n};
步骤(3)根据集合a2,获得清理后的案件基本情况集合a3={a″1,a″2,...,a″n};
步骤(4)将集合a3和f1拆分为训练集a3,t、f1,t和验证集a3,v、f1,v;
步骤(5)设置窗口大小、词最小出现频数、词向量长度,根掘训练集a3,t,获得词向量模型m;
步骤(6)根据词向量模型m,计算集合a3,t、a3,v中每个a″i的词频,获得词频集合p3,t、p3,v,并将词替换为词向量形式的a″′i,获得集合a4,t、a4,v;
步骤(7)根据验证集中的每个a″′i和训练集中的a″′i,获得和a″′i的相似文书集a5,i;
步骤(8)根据集合a5,i、f1,t和协同过滤推荐策略(如图3所示),推荐法条f′i,获得推荐法条集合f2,v;
步骤(9)根据集合f1,v和f2,v,获得最优的推荐策略参数;
步骤(10)对目标文书的案件基本情况ag进行分词,获得分词后的案件基本情况a′g;
步骤(11)根据a′g,获得清理后的案件基本情况a″g;
步骤(12)根据词向量模型m,计算a″g的词频,获得词频pg,并将词替换为词向量形式的a″′g;
步骤(13)根据a″′g和训练集中的a″′i,获得和a″′g的相似文书集a5,g;
步骤(14)根据集合a5,g、f1,t和协同过滤推荐策略,推荐法条f′g。
在以上的流程中,步骤(7)和步骤(13)中使用到词矩心距离(wcd)和词移动距离(wmd)计算出裁判文书的相似文书集a5,i,计算的步骤如下:
步骤(7.1)或者步骤(13.1):根据验证集中的每个a″′i、pi和训练集中的a″′i、pj,计算词矩心距离,获得awcd,i;
步骤(7.2)或者步骤(13.2):根据验证集中的每个a″′i、pi和awcd,i中的a″′i、pj,计算词移动距离,获得a5,i。
在该方法的第(7)步和第(13)步中,计算验证集中的每个a″′i和训练集中的a″′i的相似度是通过计算a″′i和a″′j的距离来完成的。虽然词矩心距离(wcd)的准确度不如词移动距离(wmd),但是因为词矩心距离和词移动距离有很好的相关性,并且词矩心距离计算速度快,所以使用词矩心距离对训练集中进行预剪枝。然后计算验证集中的a″′i对训练集中预剪枝后的a″′i之间的词移动距离,最终选取词移动距离前m小的案件基本情况,得到与a″′i最相似的m个案件基本情况a5,i。
随后通过协同过滤的方式,分析a5,i中的案件基本情况在f1,t对应的法条,采取一定的策略(如图3所示),作为推荐给a″′i的法条f′i,综合推荐给验证集的法条得到推荐法条集合f2,v。通过分析验证集中真实引用的法条集合f1,v和推荐法条集合f2,v,计算精确度、召回率和f值,选取f值最优情况下的协同过滤策略参数,作为目标文书法条推荐时协同过滤策略的参数。
本发明的有益效果是:该方法不仅基于词向量模型,更好地计算出裁判文书之间的相似度,同时通过预剪枝的方式,在保持精度的同时大幅提高了计算速度。并且,协同过滤的方式让目标裁判文书能够借助已经成文的裁判文书的法条引用结果,提升法条推荐的效果。
附图说明
图1为基于词向量模型的法条推荐方法的流程图。
图2为基于词向量模型的法条推荐方法流程。
图3为协同过滤推荐策略。
图4为裁判文书案件基本情况a1038962。
图5为引用法条fi。
图6为清理后的案件基本情况a″1038962。
图7为词频p1038962。
图8为词向量形式的案件基本情况a″′1038962。
具体实施方式
本发明主要是使用词向量模型来度量裁判文书之间的相似程度,以及通过协同过滤推荐策略向裁判文书推荐法条。该推荐方法整体流程如图1所示。其具体实施如下:
1.该方法的主要流程如图2上半部分所示。
(1)第1步,获取已经成文的裁判文书集的案件基本情况集合a1={a1,a2,...,an}和引用的法条集合f1={f1,f2,...,fn}。
(2)第2步,使用分词工具对a1中的每一个案件基本情况ai进行分词,获得分词后的案件基本情况集合a2={a′1,a′2,...,a′n}。
(3)第3步,对a2中的每一个案件基本情况a″i去除停用词,获得清理后的案件基本情况集合a3={a″1,a″2,...,a″n}。
(4)第4步,将案件基本情况集合a3和法条集合f1按照一定比例拆分为训练集a3,t、f1,t和验证集a3,v、f1,v两部分。
(5)第5步,设置窗口大小、词最小出现频数、词向量长度,使用词向量模型训练案件基本情况集合a3,t,获得训练好的词向量模型m。
(6)第6步,根据词向量模型m,计算a3,t、a3,v中每个案件基本情况a″i的词频,获得词频集合p3,t、p3,v,并将词替换为词向量形式的案件基本情况a″′i,获得a4,t、a4,v。
(7)第7步,根据验证集中的每个案件基本情况a″′i和训练集中的案件基本情况a″′i,获得和a″′i距离最近的m个案件基本情况a5,i。
(8)第8步,根据a5,i、f1,t和协同过滤推荐策略(如图3所示),推荐法条f′i,获得推荐法条集合f2,v。
(9)第9步,根据f1,v和f2,v计算验证集的在协同过滤推荐策略不同参数下的精确率、召回率和f值(准确度和召回率的调和平均数),确定f值取值最优的协同过滤推荐策略的参数。
(10)第10步,对目标裁判文书文本分词:对目标文书的案件基本情况ag进行分词,获得a′g。
(11)第11步,对a′g去除停用词,获得a″g。
(12)第12步,根据词向量模型m,计算a″g的词频,获得词频pg,并将词替换为词向量形式的案件基本情况a″′g。
(13)第13步,根据a″′g和训练集中的案件基本情况a″′j,获得和a″′g距离最近的m个案件基本情况a5,g。
(14)第14步,计算目标文书的推荐法条集:根据a5,g、f1,t和协同过滤推荐策略,推荐法条f′g。
2.该方法的第7步和第13步如图2下半部分,该步骤根据案件基本情况之间的距离计算其相似度。
(1)第7.1步或者第13.1步:计算验证集中的每个案件基本情况a″′i、pi和训练集中的案件基本情况a″′i、pj之间的词矩心距离,在训练集a4,t选取wcd前2m~10m小的,获得awcd,i。
(2)第7.2步或者第13.2步:计算验证集中的每个案件基本情况a″′i、pi和awcd,i中的案件基本情况a″′i、pj之间的词移动距离,在awcd,i选取wmd前m小的,获得a5,i。
下面通过具体的实例来说明本发明的实施。
本发明的实例将从已经成文的裁判文书集训练词向量模型,然后根据目标文书的案件基本情况,为其推荐法条,数据集来自盗窃罪的实际裁判文书。
对于该实例,我们将采用如下步骤实施该方法:
1.获取已经成文2400篇裁判文书集的案件基本情况集合a1={a1,a2,...,a2400}和引用的法条集合f1={f1,f2,...,f2400},ai和fi的示例如分别如图4和图5所示。
2.使用分词工具对a1中的每一个案件基本情况ai进行分词,获得分词后的案件基本情况集合a2={a′1,a′2,...,a′2400}。
3.对a2中的每一个案件基本情况a′i去除停用词,获得清理后的案件基本情况集合a3={a″1,a″2,...,a″2400},a″i的示例如图6所示。
4.将案件基本情况集合a3和法条集合f1按照一定比例拆分为训练集a3,t={a″1,a″2,...,a″1800}、f1,t={f1,f2,...,f1800}和验证集a3,v={a″1801,a″1802,...,a″2400}、f1,v={f1801,f1802,...,f2400}。
5.设置窗口大小为5、词最小出现频数为5、词向量长度为100,使用词向量模型训练案件基本情况集合a3,t,获得训练好的词向量模型m。
6.根据词向量模型m,计算a3,t、a3,v中每个案件基本情况a″i的词频,获得词频集合p3,t={p1,p2,...,p1800}、p3,v={p1801,p1802,...,p2400},并将词替换为词向量形式的案件基本情况a″′i,获得a4,t={a″′1,a″′2,...,a″′1800}、a4,v={a″′1801,a″′1802,...,a″′2400},pi的示例如图7所示,a″′i的示例如图8所示。
7.根据验证集中的每个案件基本情况a″′i和训练集中的案件基本情况a″′j,获得和a″′i距离最近的m=10个案件基本情况a5,i,其具体子步骤如下:
(1)第7.1步:计算验证集中的每个案件基本情况a″′i、pi和训练集中的案件基本情况a″′j、pj之间的词矩心距离(wcd),在训练集a4,t选取wcd前2m小的,获得awcd,i。
(2)第7.2步:计算验证集中的每个案件基本情况a″′i、pi和awcd,i中的案件基本情况a″′j、pj之间的词移动距离(wmd),在awcd,i选取wmd前m小的,获得a5,i。
8.根据a5,i、f1,t和协同过滤推荐策略中的阈值推荐策略,推荐法条f′i,获得推荐法条集合f2,v=[f′1801,f′1802,...,f′2400}。
9.根据f1,v和f2,v计算验证集的在中的阈值推荐策略的参数s和t不同取值下下的精确率、召回率和f值(准确度和召回率的调和平均数),确定f值取值最优的中的阈值推荐策略的参数s=6,t=0.5,此时f值最优为0.67。
10.对目标文书的案件基本情况a1038962进行分词,获得a′1038962,a1038962如图4所示。
11.对a′1038962去除停用词,获得a″1038962,a″1038962如图6所示。
12.根据词向量模型m,计算a″1038962的词频,获得词频p1038962,并将词替换为词向量形式的案件基本情况a″′1038962,p1038962和a″′1038962分别如图7和图8所示。
13.根据a″′1038962和训练集中的案件基本情况a″′j,获得和a″′1038962距离最近的m个案件基本情况a5,1038962。
(1)第13.1步:计算验证集中的每个案件基本情况a″′i、pi和训练集中的案件基本情况a″′j、pj之间的词矩心距离(wcd),在训练集a4,t选取wcd前2m小的,获得awcd,1038962={a″′1008722,a″′1009190,a″′1017386,a″′1005287,a″′1003512,a″′1007626,a″′1011983,a″′1000993,a″′1005718,a″′1008355,a″′1013217,a″′1007743,a″′1006964,a″′100194,a″′1018096,a″′1014153,a″′1020045,a″′1006959,a″′1010631,a″′1012251}。
(2)第13.2步:计算a″′1038962、p1038962和awcd,1030962中的案件基本情况a″′j、pj之间的词移动距离(wmd),在awcd,1038962选取wmd前m小的,获得a5,1038962={a″′1017386,a″′1008722,a″′100194,a″′1011983,a″′1003512,a″′1005287,a″′1009190,a″′1006984,a″′1007743,a″′1014153}。
14.计算目标文书的推荐法条集:根据a5,1038962、f1,t和协同过滤推荐策略中的阈值推荐策略,推荐法条f′1038962={《中华人民共和国刑法》第二百六十四条,《中华人民共和国刑法》第六十七条,《中华人民共和国刑法》第五十三条}。
以上步骤为案件基本情况a1038962推荐了法条f′1038962,应该正确引用的法条为f′correct={《中华人民共和国刑法》第二百六十四条,《中华人民共和国刑法》第六十七条},准确度为66.6%,召回率为100%,很好地完成了法条推荐任务。
- 还没有人留言评论。精彩留言会获得点赞!